Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Model_Choice_and_Decision_Theory.pdf
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
ディップ株式会社
PRO
October 29, 2025
Technology
67
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Model_Choice_and_Decision_Theory.pdf
ディップ株式会社
PRO
October 29, 2025
More Decks by ディップ株式会社
See All by ディップ株式会社
はじめての環境構築!デプロイ〜Docker基礎を学べるワークショップ!
dip_tech
PRO
0
36
【TSKaigi2026登壇資料】決定論的な型チェックへ Go 製コンパイラによる10倍速の裏側で stableTypeOrdering から見える並列化への挑戦
dip_tech
PRO
2
380
【TSKaigi2026登壇資料】バイトル」のTypeScriptリニューアル — 積み上がったレガシーとパフォーマンスに挑む現在地
dip_tech
PRO
1
350
【新卒研修】ライブデモ + compose.yaml読解_講義資料
dip_tech
PRO
0
240
【ディップ|26年新卒研修資料】OpenAPI/Swagger REST API研修
dip_tech
PRO
0
380
【ディップ|26年新卒研修資料】Docker_ハンズオン研修
dip_tech
PRO
0
350
【ディップ|26年新卒研修資料】TDD実装演習
dip_tech
PRO
0
400
ハッカソンや個人開発で何作る? テーマ発見〜アイデア発想ハンズオン! 技育CAMPアカデミア
dip_tech
PRO
0
87
技育祭登壇|「AIを使える」は、勘違いだった。 コードが書けてもプロになれなかった僕の1年戦記
dip_tech
PRO
0
140
Other Decks in Technology
See All in Technology
Amazon Bedrock AgentCore ワークショップ JAWS UG TOHOKU / amazon-bedrock-agentcore-workshop-jawsug-tohoku-2026
gawa
9
490
なぜ Platform Engineering の土台に Kubernetes を選ぶのか
r4ynode
0
230
美味しいスイスチーズを作ろう🧀🐭
taigamikami
1
270
Agentic ERPをどう設計するか ー 受発注エージェントを動かす、現場の知見と設計思想ー
recerqainc
1
2k
AIの性能が向上しても未解決な組織の重大問題は何か?/An Unsolved Organizational Problem in the Age of AI
moriyuya
2
450
LLMにもCAP定理があるという話
harukasakihara
0
250
Microsoft Build Keynoteふりかえり
tomokusaba
0
110
AI Testing Talks: Challenges of Applying AI in Software Testing: From Hype to Practical Use
exactpro
PRO
1
140
ITエンジニアを取り巻く環境とキャリアパス / A career path for Japanese IT engineers
takatama
4
1.8k
非定型業務をAI slackbotで自動化する ~ 社内要望を自動壁打ちするbotを作った ~/automating-ad-hoc-work-with-ai-slackbot
shibayu36
0
520
タクシーアプリ『GO』の実践的データ活用
mot_techtalk
3
180
noUncheckedIndexedAccess、3時間、1万円。 / noUncheckedIndexedAccess, 3 Hours, 10,000 JPY.
kaonavi
1
340
Featured
See All Featured
First, design no harm
axbom
PRO
2
1.2k
Mind Mapping
helmedeiros
PRO
1
240
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Embracing the Ebb and Flow
colly
88
5.1k
Documentation Writing (for coders)
carmenintech
77
5.4k
Mobile First: as difficult as doing things right
swwweet
225
10k
Tell your own story through comics
letsgokoyo
1
950
Measuring & Analyzing Core Web Vitals
bluesmoon
9
860
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
Bayesian Statistics and Marketing §6 Model Choice and Decision Theory
久保知生 事業計画統括部/データドリブン経営推進課 2025-07-18
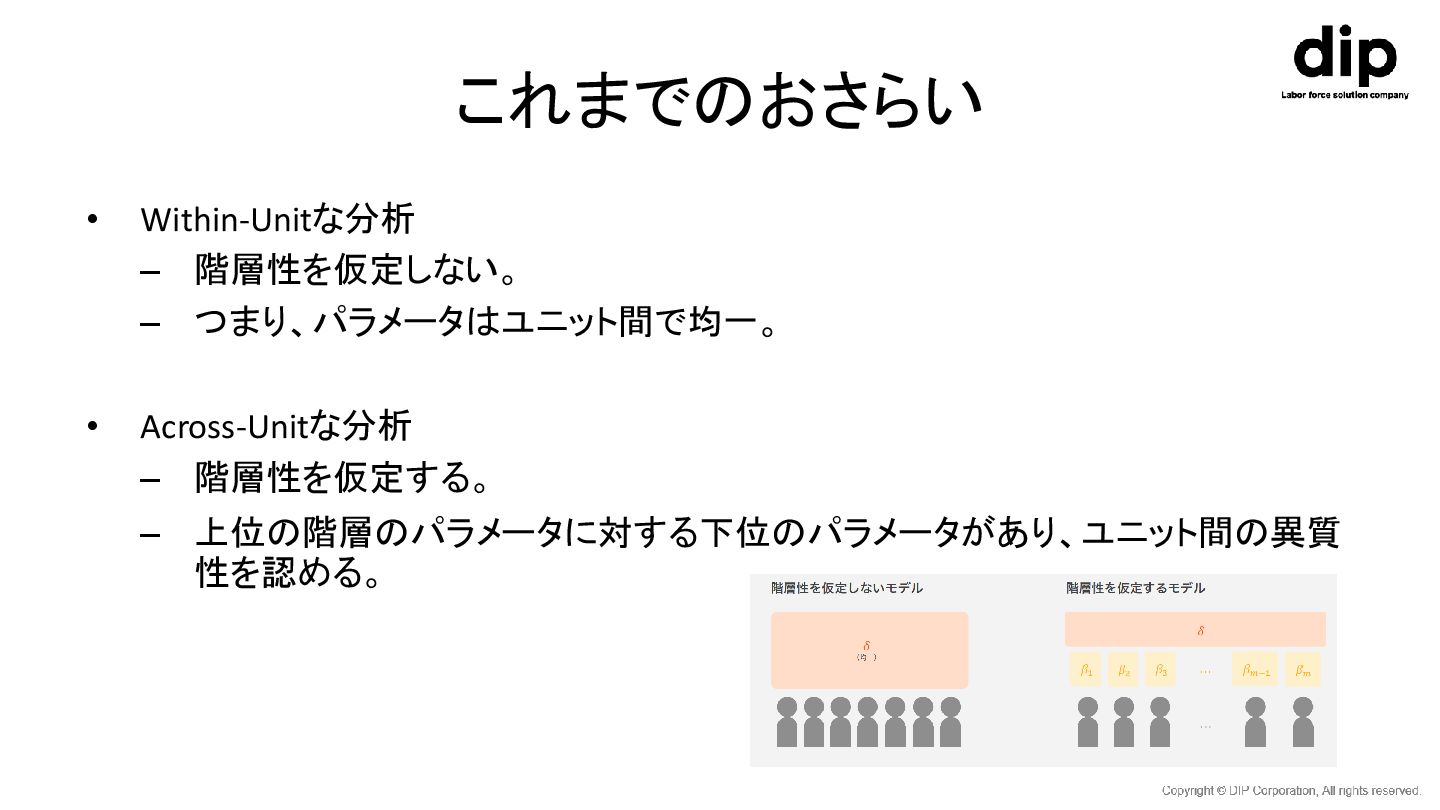
これまでのおさらい • Within-Unitな分析 – 階層性を仮定しない。 – つまり、パラメータはユニット間で均一。 • Across-Unitな分析 –
階層性を仮定する。 – 上位の階層のパラメータに対する下位のパラメータがあり、ユニット間の異質 性を認める。
このスライドの内容 • 統計的決定理論の紹介 – 統計的決定理論 – ベイズ決定理論 • ベイズ決定理論のある形態としてのモデル選択 –
ベイズファクターの紹介 – ベイズファクターの求め方 • Appendix:AICとBIC
統計的決定理論 • わたしの所感「めっちゃ抽象的」 • 竹村数理統計「かなり抽象的な 理論」
統計的決定理論:用語と定義 • 𝑋:大きさ𝑛の標本 • 𝔛:標本空間 – 𝑋の実現値の属する集合。𝑛次元の確率変数𝑋 = 𝑋1 ,
⋯ , 𝑋𝑛 の 場合は𝑛次元ユークリッド空間を考えていることになる。
統計的決定理論:用語と定義 • 𝜃:分布族の母数(パラメータ) • 𝛩:母数空間 – 𝜃のとりうる値の集合。 – e.g.正規分布の場合 •
𝜃 = 𝜇, 𝜎2 • 𝛩 = { 𝜇, 𝜎2 | − ∞ < 𝜇 < ∞, 0 < 𝜎2 < ∞} – 簡便のため、母数を既知or所与と考える場合もある。 • e.g. 正規分布の母分散𝜎2を既知とすると、𝛩 = {𝜇| − ∞ < 𝜇 < ∞}
統計的決定理論:用語と定義 • 𝑑:決定 – データに基づいて分析者が行う判断や行動のこと。 • 𝐷:決定空間 – 決定𝑑の集合。 –
e.g. 点推定 • 𝐷 = 𝛩 • 𝑑 ∈ 𝛩 – e.g. 検定 • 𝐷 = {0,1} • 0は受容、1は棄却を表す。
損失関数 • 𝐿 𝜃, 𝑑 :損失関数 – 真のパラメータが𝜃のとき、分析者が𝑑という決定をしたとき の損失の大きさ。 –
e.g. 点推定 • 𝐿 𝜃, 𝑑 = 𝜃 − 𝑑 2, where 𝑑 ∈ 𝛩 • 損失を距離の二乗誤差で評価するのは、あくまで計算上の取り扱い が簡単になるため。
0-1の損失関数 • e.g. 検定問題 – 母数空間𝛩が互いに背反なふたつの部分集合の和で表現され るとする。 • 𝛩 =
𝛩0 ∩ 𝛩1 – 決定空間𝐷は𝐷 = {0,1} • 真のパラメータが𝛩0 に属するとき、正しい決定は𝑑 = 0. • 真のパラメータが𝛩1 に属するとき、正しい決定は𝑑 = 1.
0-1の損失関数 • 以上のような設定の下で、正しい決定をした場合は0の 損失を、誤った決定をした場合は1の損失を被る。 • 𝐿 𝜃, 0 = ቊ
0 𝜃 ∈ 𝛩0 のとき 1 𝜃 ∈ 𝛩1 のとき • 𝐿 𝜃, 1 = 1 − 𝐿 𝜃, 0 = ቊ 1 𝜃 ∈ 𝛩0 のとき 0 𝜃 ∈ 𝛩1 のとき
決定関数 • 分析者は観測値𝑋を見て決定𝑑を選ぶ。 – つまり、𝑑は𝑋の関数(𝑑 = 𝛿 𝑋 ) –
関数𝛿を決定関数という。 • 𝑋は確率変数なので、𝛿 𝑋 の値も確率変数であり、𝐿 𝜃, 𝛿 𝑋 の値もまた確率 変数。 • したがって、損失関数の値は𝑋に依存して確率的に変動する。 • よって、損失関数の期待値(リスク関数)をとって平均的な損失を考える。 – 𝑅 𝜃, 𝛿 = 𝐸 𝐿 𝜃, 𝛿 𝑋
決定関数 • e.g. 検定問題 – 真のパラメータが𝛩0 に属するとき、正しい決定は𝑑 = 0. –
真のパラメータが𝛩1 に属するとき、正しい決定は𝑑 = 1. – よって𝐸 𝐿 = 0 × 𝑃 𝐿 = 0 + 1 × 𝑃 𝐿 = 1 – 𝜃 ∈ 𝛩0 と𝜃 ∈ 𝛩1 のときをそれぞれ考えると • 𝑅 𝜃, 𝛿 = ቊ 𝑃 𝛿 𝑋 = 1 𝜃 ∈ 𝛩0 のとき 𝑃 𝛿 𝑋 = 0 ) 𝜃 ∈ 𝛩1 のとき
決定関数 • リスクの小さい決定関数が望ましい決定関数。 • リスクを最小にする決定関数を求めることが統計的決定 理論の目的。
ベイズ決定理論 • ベイズ決定理論は2つの要素からなる。 – 損失関数 𝐿 𝜃, 𝑑 • 𝜃:パラメータ
• 𝑑:決定 – 事後分布 𝑝 𝜃|𝐷𝑎𝑡𝑎 • 期待損失は以下で定義される。 – ∫ 𝐿 𝜃, 𝑑 𝑝 𝜃|𝐷𝑎𝑡𝑎 𝑑𝜃 – これを最小化するような𝑑を選ぶ。
(準備)期待値 • 期待値計算 – 確率分布𝑝 𝑥 を持って、ある関数𝑓 𝑥 の加重平均を計算する 操作のこと
• 𝐸{𝑓 𝑥 } = ∫ ∞ ∞ 𝑝 𝑥 ⋅ 𝑓 𝑥 𝑑𝑥 – 𝑝 𝑥 に従うデータ{𝑥1 , ⋯ , 𝑥𝑛 }を用いて近似できる。 • 𝐸{𝑓 𝑥 } ≈ 1 𝑁 𝛴𝑛=1 𝑁 𝑓 𝑥𝑛
(準備)ベイズの定理 • ベイズの定理 – パラメータ𝜃主観的な事前分布に観測値を与えることで、客観 的な事後分布をえること – 𝑝 𝜃|𝑦 ∝
𝑝 𝑦|𝜃 𝑝 𝜃 • 𝑝 𝜃|𝑦 :事後分布 • 𝑝 𝑦|𝜃 :尤度 • 𝑝 𝜃 :事前分布
モデル選択:事後確率 • ベイズ決定理論において、行動は複数のモデルから最良のモ デルを選ぶこと。 • 𝑘個のモデルを𝑀1 , ⋯ , 𝑀𝑘
で定義する。 • 以下、観察されるデータは𝑦で表す。 • モデル𝑀𝑖 について – 事前分布:𝑝 𝜃𝑖 |𝑀𝑖 – 尤度:𝑝 𝑦|𝜃𝑖 , 𝑀𝑖
モデル選択:ベイズファクター • モデル𝑖とモデル𝑗(𝑖 ≠ 𝑗)の事後オッズ比を以下で定義する。 – 𝑝 𝑀𝑖|𝑦 𝑝 𝑀𝑗|𝑦
= 𝑝 𝑦|𝑀𝑖 𝑝 𝑦|𝑀𝑗 ⋅ 𝑝 𝑀𝑖 𝑝 𝑀𝑗 • 𝑝 𝑦|𝑀𝑖 𝑝 𝑦|𝑀𝑗 :ベイズファクター ⋚ 1 • 𝑝 𝑀𝑖 𝑝 𝑀𝑗 :事前オッズ • 事後オッズ比は事前分布の影響を多分に受ける。 – ベイズファクターを使えば、事前分布の影響を受けずにモデル選択 できるのでは?
モデル選択:ベイズファクター • 周辺尤度は以下で定義される。 – 𝑝 𝑦|𝑀𝑖 = ∫ 𝑝 𝑦|𝜃𝑖
, 𝑀𝑖 ⋅ 𝑝 𝜃𝑖 |𝑀𝑖 𝑑𝜃 • 𝑝 𝑦|𝜃𝑖 , 𝑀𝑖 :モデル𝑀𝑖 のもとでデータがどれくらいもっともらしい か • 𝑝 𝜃𝑖 |𝑀𝑖 :重み • よって、ベイズファクター(=周辺尤度の比率)は以下 のように再定義できる。 – 𝑝 𝑦|𝑀𝑖 𝑝 𝑦|𝑀𝑗 = ∫ 𝑝 𝑦|𝜃𝑖,𝑀𝑖 ⋅𝑝 𝜃𝑖|𝑀𝑖 𝑑𝜃 ∫ 𝑝 𝑦|𝜃𝑗,𝑀𝑗 ⋅𝑝 𝜃𝑗|𝑀𝑗 𝑑𝜃
モデル選択:ベイズファクター • 前スライドの再定義より、3つのことがわかる。 – ベイズファクターは(事前にデータを観察することなく)それぞれ のモデルがデータをどれだけうまく予測できたかを測る指標 • AICやBICは事後的にデータを観察して、いかにモデルがデータにフィッ トしているかを測る指標。 –
周辺尤度の積分が入るので、計算が大変そう。 – 情報の少ない事前分布を設定すると周辺尤度が小さくなるというペナ ルティが発生する。
ベイズファクターの計算法 • MCMC(マルコフ連鎖モンテカルロ)を用いた計算法 • 重点サンプリングを用いた計算法 • ブリッジサンプリングを用いた計算法
MCMCを用いた計算法 • パラメータが4~5個のシンプルなモデルでは、モンテカルロ法を用 いてベイズファクターを近似できる。 • ∫ 𝑝 𝑦|𝜃𝑖 , 𝑀𝑖
⋅ 𝑝 𝜃𝑖 |𝑀𝑖 𝑑𝜃 ≈ 1 𝑁 Σ𝑗=1 𝑁 𝑝 𝑦| ෨ 𝜃𝑗 , 𝑀𝑖 – 𝜃 の事前分布から抽出したN個のサンプル( ෩ 𝜃𝑖 ∼ 𝑝(𝜃) )で置き換えている。 • ただし、この方法が使えるのは事前分布と事後分布の形が似てい てオーバーラップがあるときのみ。
重点サンプリングを用いた計算法 • MCMCでは事後分布と似ていない事前分布を使っている可能性がある。 • そこで、密度の高い𝜃(=重点密度𝑔𝑖𝑠 𝜃 )を重点的にサンプリングする • ∫ 𝑝
𝑦|𝜃𝑖 ⋅ 𝑝 𝜃𝑖 𝑑𝜃 = ∫ 𝑝 𝑦|𝜃𝑖 ⋅𝑝 𝜃𝑖 𝑔𝑖𝑠 𝜃 𝑔𝑖𝑠 𝜃 𝑑𝜃 = 𝐸 𝑝 𝑦|𝜃𝑖 ⋅𝑝 𝜃𝑖 𝑔𝑖𝑠 𝜃 ≈ 1 𝑁 𝛴𝑖=1 𝑁 𝑝 𝑦|෩ 𝜃𝑖 ⋅𝑝 ෩ 𝜃𝑖 𝑔𝑖𝑠 ෩ 𝜃 , ෩ 𝜃𝑖 ∼ 𝑔𝑖𝑠 (𝜃)
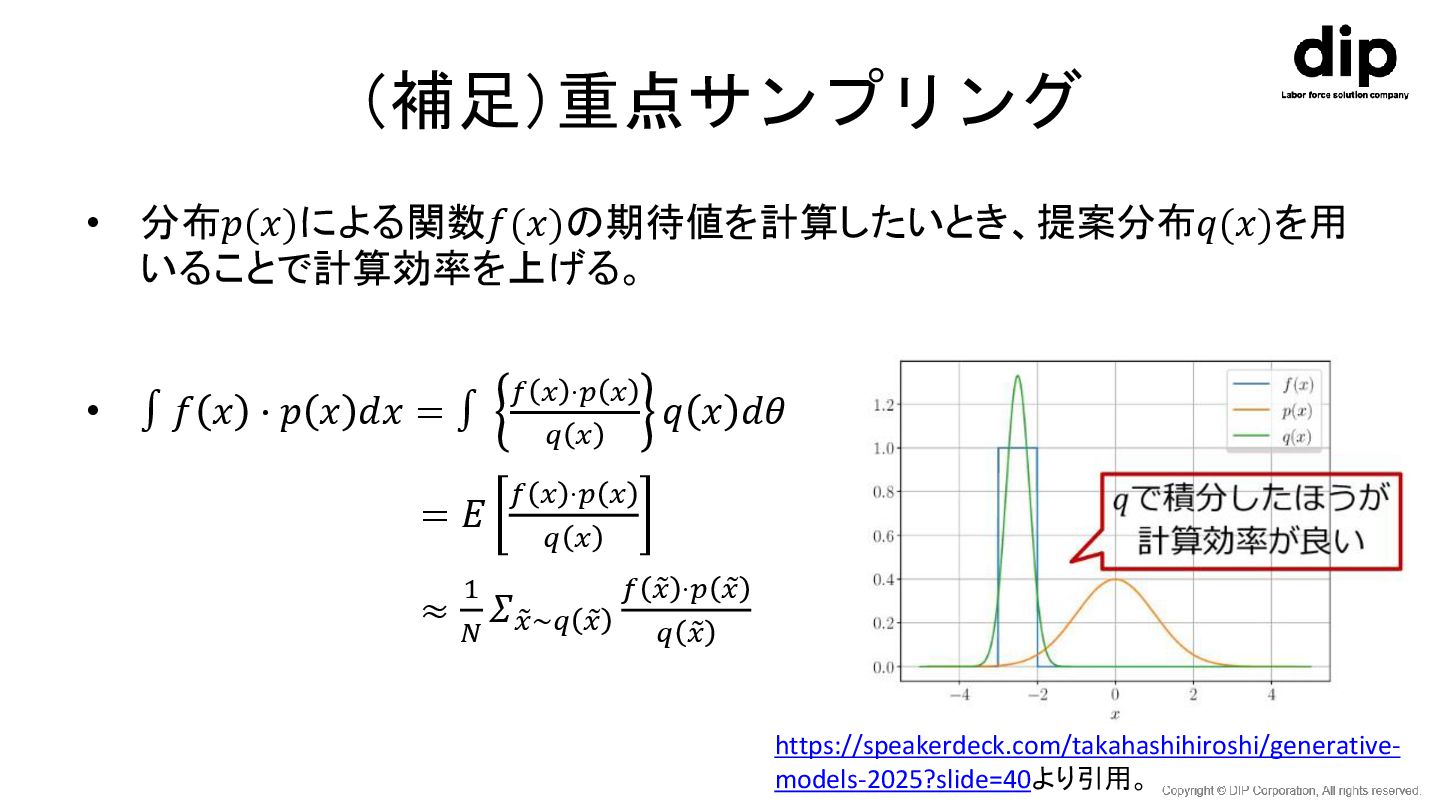
(補足)重点サンプリング • 分布𝑝(𝑥)による関数𝑓(𝑥)の期待値を計算したいとき、提案分布𝑞(𝑥)を用 いることで計算効率を上げる。 • ∫ 𝑓 𝑥 ⋅ 𝑝
𝑥 𝑑𝑥 = ∫ 𝑓 𝑥 ⋅𝑝 𝑥 𝑞 𝑥 𝑞 𝑥 𝑑𝜃 = 𝐸 𝑓 𝑥 ⋅𝑝 𝑥 𝑞 𝑥 ≈ 1 𝑁 𝛴 𝑥∼𝑞 𝑥 𝑓 𝑥 ⋅𝑝 𝑥 𝑞 𝑥 https://speakerdeck.com/takahashihiroshi/generative- models-2025?slide=40より引用。
重点サンプリングを用いた計算法 • ただし、重点密度は以下を満たす必要がある。 – 事後分布と同一の定義域をもつ。 – 事後分布とよく似ている。 – 事後分布を裾が厚いこと。
ブリッジサンプリングを用いた計算法 • ブリッジ関数ℎ 𝜃 と提案分布(重点密度)𝑔 𝜃 について、以下が成 立。 – 1
= ∫ 𝑝 𝑦|𝜃 𝑝 𝜃 ℎ 𝜃 𝑔 𝜃 𝑑𝜃 ∫ 𝑝 𝑦|𝜃 𝑝 𝜃 ℎ 𝜃 𝑔 𝜃 𝑑𝜃 – 両辺に𝑝 𝑦 をかけると • 𝑝 𝑦 = ∫ 𝑝 𝑦|𝜃 𝑝 𝜃 ℎ 𝜃 𝑔 𝜃 𝑑𝜃 ∫ 𝑝 𝑦|𝜃 𝑝 𝜃 𝑝 𝑦 ℎ 𝜃 𝑔 𝜃 𝑑𝜃
ブリッジサンプリングを用いた計算法 • 𝑝 𝑦 = ∫ {𝑝 𝑦|𝜃 𝑝 𝜃
ℎ 𝜃 }𝑔 𝜃 𝑑𝜃 ∫ {ℎ 𝜃 𝑔 𝜃 }𝑝 𝜃|𝑦 𝑑𝜃 = 𝐸 𝑝 𝑦|𝜃 𝑝 𝜃 ℎ 𝜃 𝐸 ℎ 𝜃 𝑔 𝜃 ≈ 1 𝑁1 𝛴 𝑖=1 N1 𝑝 𝑦|෩ 𝜃𝑖 𝑝 ෩ 𝜃𝑖 ℎ ෩ 𝜃𝑖 1 𝑁2 𝛴 𝑖=1 N2 ℎ 𝜃𝑗 ∗ 𝑔 𝜃𝑗 ∗ – ෨ 𝜃𝑖 ∼ 𝑔 𝜃 :提案分布からのサンプル – 𝜃𝑗 ∗ ∼ 𝑝 𝜃|𝑦 :事後分布からのサンプル
ブリッジサンプリングを用いた計算法 • ブリッジサンプリングを使うことにより、重点密度に課せられ るような分布の裾に対する厳しい条件を外せる。 • 最適なブリッジ関数ℎ 𝜃 を求めるアルゴリズムもあるが、ここ では省略。 •
詳細はMeng and Wong, 1996を参照。
APPENDIX
AICとBIC(※) • 以下のモデルMを考える。 – 𝑌 = 𝑋𝑀 𝛽𝑀 + 𝑢𝑀
, 𝑢𝑚 |𝑋𝑚 ∼ 𝑁 0, 𝜎𝑚 2 𝐼 • このとき、モデルMの対数尤度𝑙𝑛 𝜃𝑀 は𝜃𝑀 = 𝛽𝑀 ′ , 𝜎𝑀 2 と すると、以下で与えられる。 – 𝑙𝑛 𝜃𝑀 = − 𝑛 2 log 2𝜋𝜎𝑚 2 − 1 2𝜎𝑀 2 ∥ 𝑌 − 𝑋𝑀 𝛽𝑀 ∥2 ※以下の議論は末石(2024), 『データ駆動型回帰分析 計量経済学と機械学習の融合』, 日本評論社に基づく。
AICとBIC • AIC(赤池情報量基準) – 𝐴𝐼𝐶 = −2𝑙𝑛 𝜃 +
2𝑑𝑖𝑚 𝜃 • 第1項が対数尤度 • 第2項が罰則項(𝑑𝑖𝑚 𝜃 はパラメータ𝜃の次元数) • AICはデータを発生させた真の分布と最尤法で推定された分布 を比較し、分布間のKLダイバージェンスを最小にするモデル の選択を意図している。 • よって、最も良い予測をもたらすモデルが選ばれる。
AICとBIC • BIC(ベイズ情報量基準) – 𝐵𝐼𝐶 = −2𝑙𝑛 𝜃 +
𝑙𝑜𝑔 𝑛 𝑑𝑖𝑚 𝜃 • 第1項が対数尤度 • 第2項が罰則項(𝑑𝑖𝑚 𝜃 はパラメータ𝜃の次元数) • BICはモデルの事後確率を最大化するようなモデルの選択を意 図している。 • よって、最も簡潔なモデルが選ばれる。 – 簡潔とは、係数を0にすれば真の回帰関数を表現できるような冗長 な変数を含まない、ということ。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}