Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Dirichlet_Process_Models.pdf
Search
ディップ株式会社
PRO
October 29, 2025
Technology
75
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Dirichlet_Process_Models.pdf
ディップ株式会社
PRO
October 29, 2025
More Decks by ディップ株式会社
See All by ディップ株式会社
はじめての環境構築!デプロイ〜Docker基礎を学べるワークショップ!
dip_tech
PRO
0
36
【TSKaigi2026登壇資料】決定論的な型チェックへ Go 製コンパイラによる10倍速の裏側で stableTypeOrdering から見える並列化への挑戦
dip_tech
PRO
2
380
【TSKaigi2026登壇資料】バイトル」のTypeScriptリニューアル — 積み上がったレガシーとパフォーマンスに挑む現在地
dip_tech
PRO
1
350
【新卒研修】ライブデモ + compose.yaml読解_講義資料
dip_tech
PRO
0
240
【ディップ|26年新卒研修資料】OpenAPI/Swagger REST API研修
dip_tech
PRO
0
380
【ディップ|26年新卒研修資料】Docker_ハンズオン研修
dip_tech
PRO
0
350
【ディップ|26年新卒研修資料】TDD実装演習
dip_tech
PRO
0
400
ハッカソンや個人開発で何作る? テーマ発見〜アイデア発想ハンズオン! 技育CAMPアカデミア
dip_tech
PRO
0
87
技育祭登壇|「AIを使える」は、勘違いだった。 コードが書けてもプロになれなかった僕の1年戦記
dip_tech
PRO
0
140
Other Decks in Technology
See All in Technology
AIの性能が向上しても未解決な組織の重大問題は何か?/An Unsolved Organizational Problem in the Age of AI
moriyuya
2
450
社内 AI エージェント Synapse と セマンティックレイヤーの育て方
hiroakis
0
930
Dynamic Workersについて
yusukebe
2
640
LLMにもCAP定理があるという話
harukasakihara
0
250
PHP と TypeScript の型システム比較:AI 時代の「型」は誰のためにあるのか? #frontend_phpcon_do / frontend_phpcon_do_2026
shogogg
1
270
非エンジニアがClaudeと挑んだ「1ヶ月間プロダクト30本ノック」
askokc
0
140
AI Adaptable なテストを整える工夫 / Ways to Make Your Tests AI-Adaptable
bitkey
PRO
3
230
AI活用を推進するために ファインディが下した、一つの小さな決断
starfish719
0
280
Microsoft Build Keynoteふりかえり
tomokusaba
0
110
AIにフローを作らせようとして挫折した話
hamatsutaichi
0
240
Djangoユーザが知っ得なPostgreSQL機能 - 設計の選択肢を増やす / Djang-use-PostgreSQL
soudai
PRO
0
210
個人最適 から 全体最適 へ AI情報共有会・AIギルド・AI-DLC で進める カンリーの組織展開
rfdnxbro
0
2k
Featured
See All Featured
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.7k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Building an army of robots
kneath
306
46k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Heart Work Chapter 1 - Part 1
lfama
PRO
7
36k
Building AI with AI
inesmontani
PRO
1
1.1k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.8k
Mobile First: as difficult as doing things right
swwweet
225
10k
エンジニアに許された特別な時間の終わり
watany
107
250k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Transcript
Bayesian Data Analysis §23 Dirichlet Process Models 久保知生 商品開発本部 DataBrain課
2025-01-07
(復習)パラメトリックモデル • 以下のパラメトリックな設定を考える。 – 𝑦𝑖 ∈ 𝒴 – 𝑦𝑖 |𝐹
∼ 𝑖𝑖𝑑 𝐹 – 𝐹 ∈ ℱ∗, 𝑤ℎ𝑒𝑟𝑒 ℱ∗ = 𝑁 𝑦|𝜇, 𝜏2 • ℱ∗はℱ = {𝒴上のすべての分布}に比べて小さいことがわか る。
(復習)ノンパラメトリックモデル • ノンパラメトリックベイズでは、より大きなℱの部分集合を 考える。 • そこで、2つのアプローチが考えられる。 – 基底関数によるアプローチ • 𝑔
𝑥; 𝜃 = σ𝑘=1 𝐾 𝜃𝑘 ℎ𝑘 𝑥 • ただし、ℎ𝑘 𝑥 は基底関数。 – process realizationによるアプローチ • {𝑔 𝑥 : 𝑥 ∈ 𝒳} • 例えば、𝑔 𝑥 はガウス過程からの観測結果。
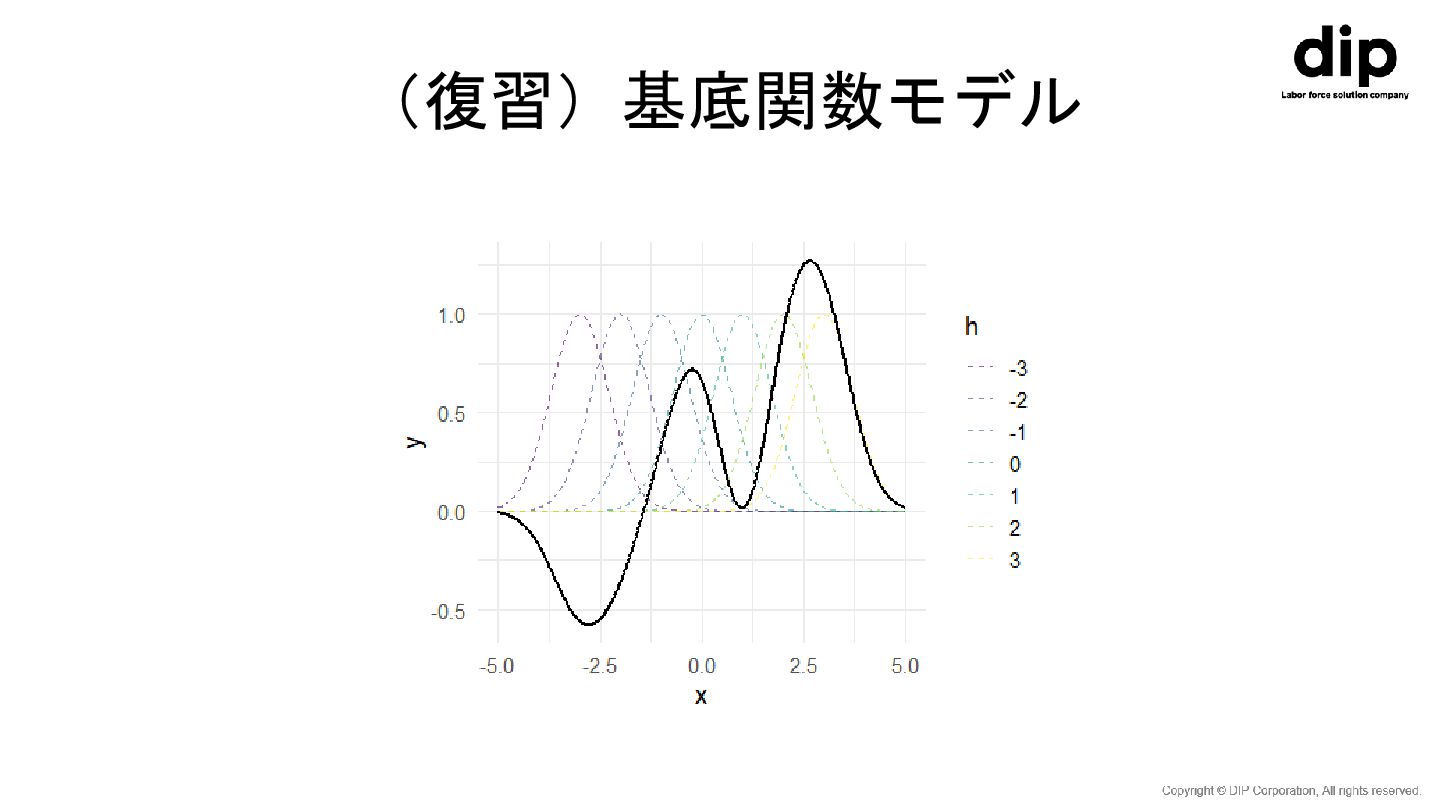
(復習)基底関数モデル • ガウス分布の形をした基底関数を用意する。 – 𝜙ℎ 𝑥 = exp{− 𝑥−𝑥ℎ 2
𝑙2 } – 𝑥ℎ ∈ {−𝐻, ⋯ , −2, −1,0,1,2, ⋯ , 𝐻} • この基底関数を𝑥ℎ 上にグリッド状に多数配置し、𝑤ℎ ∈ 𝑅で適 当に重みづける。 – 𝑦 = 𝛴ℎ=−𝐻 𝐻 𝑤ℎ ⋅ exp{− 𝑥−𝑥ℎ 2 𝜎2 } • これにより、ほとんど任意の形の関数を表すことができる。
(復習)基底関数モデル
(復習)基底関数モデル • ノットの数(ℎ)が多すぎると計算が大変。 – 入力𝑥の次元が増えてパラメータ𝑤の次元が指数的に増える現 象を「次元の呪い」という。 • ノットの数(ℎ)が少なすぎると柔軟な回帰モデルを表 現ができない。
(復習)ガウス過程 • 入力𝑥が高次元でも柔軟な回帰モデルを表現するため、 パラメータ𝑤について期待値をとってモデルから積分消 去することを考える。
(復習)ガウス過程 • 簡単のため、誤差なく𝑦を𝑥の特徴ベクトル𝜙 𝑥 = 𝜙0 𝑥 , ⋯ ,
𝜙𝐻 𝑥 ′に回帰することを考える。 – 𝑦 = 𝑤0 𝜙0 𝑥 + ⋯ + 𝑤𝐻 𝜙𝐻 𝑥 – 行列形式では:𝑦 = 𝛷𝑤 • 𝑤 ∼ 𝑁 0, 𝜆2𝐼 • このとき、𝑦の期待値と分散はそれぞれ – 𝐸 𝑦 = 𝐸 𝛷𝑤 = 𝛷𝐸 𝑤 = 0 – 𝑉 𝑦 = 𝐸 𝑦𝑦′ − 𝐸 𝑦 𝐸 𝑦 ′ = 𝐸{ 𝛷𝑤 𝛷𝑤 ′} = 𝛷 𝑤𝑤′ 𝛷′ = 𝜆2𝛷𝛷′
(復習)ガウス過程 • したがって、𝑦 ∼ 𝑁 0, 𝜆2𝛷𝛷′ – 𝑦の分布を考えるにあたり、𝑤が消去されていることに注意。 •
𝐾 = 𝜆2𝛷𝛷′とおくと、𝐾の 𝑛, 𝑛′ 要素は以下で与えられる。 – 𝐾𝑛𝑛′ = 𝜆2𝜙 𝑥𝑛 ′𝜙 𝑥𝑛′ – つまり、𝐾はあらゆる入力𝜙0 𝑥 , ⋯ , 𝜙𝐻 𝑥 の共分散。 • 𝐾𝑛𝑛′ の値を与える関数をカーネル関数という。 – 𝐾𝑛𝑛′ = 𝑘 𝑥𝑛 , 𝑥𝑛′ = 𝜆2𝜙 𝑥𝑛 ′𝜙 𝑥𝑛′
(復習)ガウス過程 • 無限個の入力𝑥 = 𝑥1 , 𝑥2 , ⋯ に対応する出力𝑓
= 𝑓 𝑥1 , 𝑓 𝑥2 , ⋯ の同時分布が多変量ガウス過程に従 うとき、以下のように表現する。 – 𝑓 ∼ 𝐺𝑃 𝑚, 𝐾 • 入力𝑥間の類似度は、以下で表される。 – 𝑘 𝑥, 𝑥′ = 𝜏exp{− 𝑥−𝑥ℎ 2 2𝑙2 }
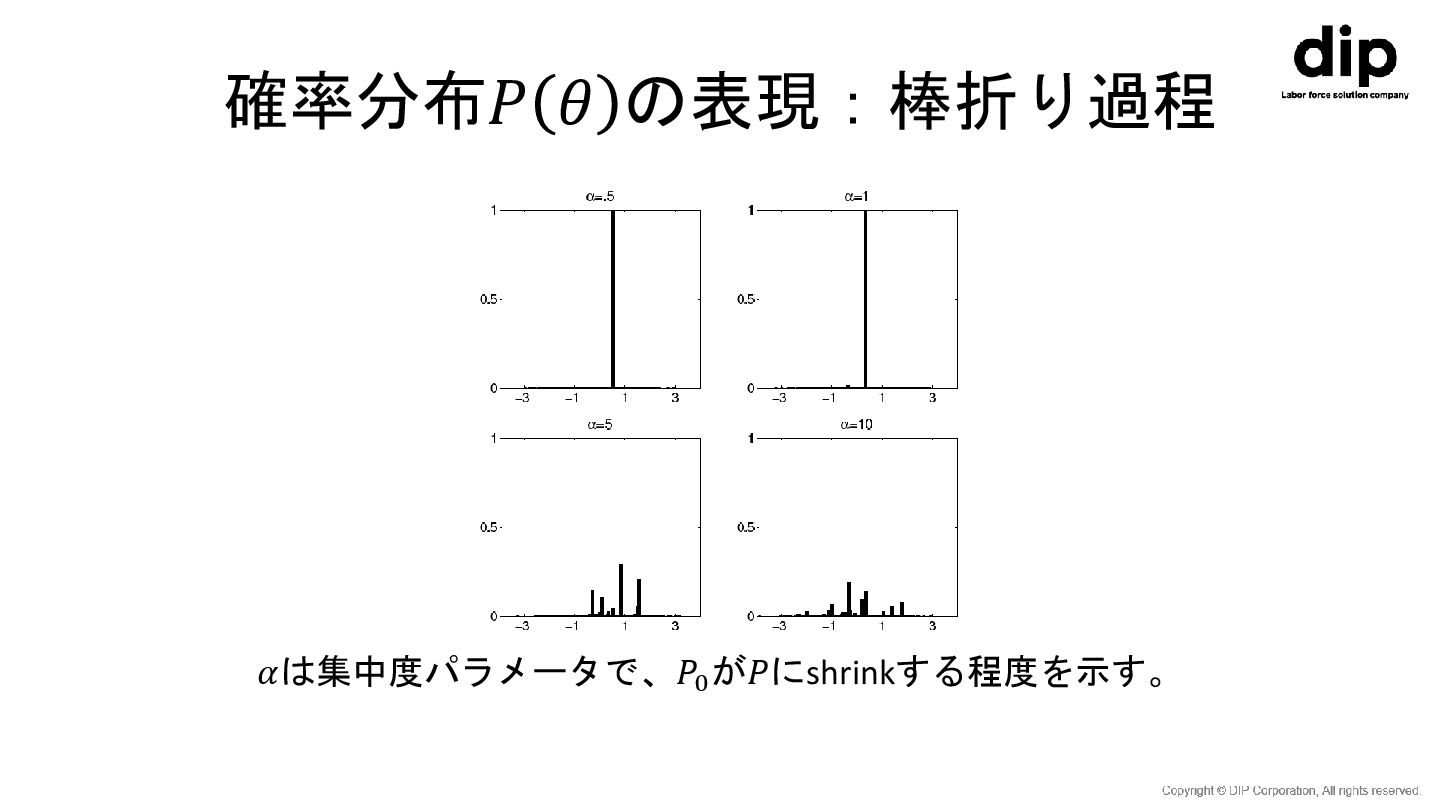
ディリクレ過程の定義と性質 • 標本空間𝛺 = 𝑅は𝑘個の部分集合𝐵1 , 𝐵2 , ⋯ ,
𝐵𝑘 に分割することができ 、お互いに重ならないものとする。 • 𝛺, 𝔅 上の確率測度を𝑃で表す。 – 𝔅は標本空間𝛺の取りうるすべての部分集合からなる集合。 • このとき、各ビン𝐵1 , 𝐵2 , ⋯ , 𝐵𝑘 の確率がディリクレ過程に従う。 – 𝑃 𝐵1 , ⋯ , 𝑃 𝐵𝑘 ∼ 𝐷𝑖𝑟𝑖𝑐ℎ𝑙𝑒𝑡 𝛼𝑃0 𝐵1 , ⋯ , 𝛼𝑃0 𝐵𝑘 – 𝑃0 は基底分布で、𝑃を推定するためのinitial guess – 𝛼は集中度パラメータで、𝑃0 が𝑃にshrinkする程度を示す。
ディリクレ過程の定義と性質 • いかなる𝐵 ∈ 𝔅についても、以下が成立。 – 𝑃 𝐵 ∼ 𝐵𝑒𝑡𝑎
𝛼𝑃0 𝐵 , 𝛼 1 − 𝑃0 𝐵 • よって𝑃 𝐵 の期待値と分散はそれぞれ – 𝐸{𝑃 𝐵 } = 𝑃0 𝐵 – 𝑉{𝑃 𝐵 } = 𝑃0 𝐵 {1−𝑃0 𝐵 } 𝛼+1
ディリクレ過程の定義と性質 • 確率分布𝑃 𝜃 を生成する確率過程をディリクレ過程とい う。 • 𝑃 𝜃 ∼
𝐷𝑃 𝛼, 𝑃0 𝜃 で表す。 – 𝜃は基底分布𝑃0 から生成されるものと考える。 – 𝜃は連続的な値を取りうるが、𝑃 𝜃 自体は離散分布。
事後分布の推論 • ディリクレ過程は共役事前分布である。 – 𝑦𝑖 |𝑃 ∼ 𝑖𝑖𝑑 𝑃, 𝑤ℎ𝑒𝑟𝑒
𝑖 = 1, … , 𝑛, 𝑃 ∼ 𝐷𝑃 𝛼, 𝑃0 を考える。 – このとき、𝑃の事後分布は𝐷𝑃 𝛼, ෨ 𝑃0 である。 • 𝛼 = 𝛼 + 𝑛 • ෪ 𝑃0 𝐵 = 𝛼 𝛼+𝑛 𝑃0 𝐵 + 1 𝛼+𝑛 σ 𝑖=1 𝑛 1[𝑦,∞) 𝐵 – 集中度パラメータが𝛼から𝛼 + 𝑛にアップデートされているこ とが分かる。 – 𝛼はある意味で事前のサンプルサイズともいえる。
事後分布の推論 • 𝑃の事後期待値は以下で与えられる。 – 𝐸 𝑃 𝐵 = 𝛼 𝛼+𝑛
𝑃0 𝐵 + 𝑛 𝛼+𝑛 𝑃𝑛 𝐵 – ただし、𝑃𝑛 𝐵 = 1 𝑛 σ𝑖=1 𝑛 1[𝑦,∞) 𝐵 で、データの経験分布を表す。 • 𝑛に対して小さな𝛼はprior guessたる𝑃0 に対する重みが小さい ことを意味する。 • 𝑛に対して大きな𝛼はデータたる𝑃𝑛 に対する重みが小さいこと を意味する。
確率分布𝑃 𝜃 の表現:棒折り過程 • 𝑃 𝜃 は𝑃0 𝜃 から生成されたアトム𝜃ℎ の重み付き和で表現で
きる(棒折り過程)。 • 𝑃 ⋅ = 𝛴ℎ=1 ∞ 𝜋ℎ 𝛿𝜃ℎ – 𝜋ℎ = 𝑣ℎ 𝛱𝑙<ℎ 1 − 𝑣ℎ – 𝑣ℎ ∼ 𝐵𝑒𝑡𝑎 1, 𝛼 – 𝜃ℎ ∼ 𝑃0
確率分布𝑃 𝜃 の表現:棒折り過程 • 一般に以下が成立 – 𝜋1 = 𝑣1 –
𝜋𝑖 = 𝑣𝑖 𝜋𝑗=1 𝑖−1 1 − 𝑣𝑖 𝑖 ≥ 2 • 𝑣𝑖 は0 < 𝑣𝑖 < 1を満たす必要があるため、ベータ分布 𝐵𝑒𝑡𝑎 1, 𝛼 から生成する
確率分布𝑃 𝜃 の表現:棒折り過程 • 𝑃 ⋅ は𝛴ℎ=1 ∞ 𝜋ℎ 𝛿𝜃ℎ
で表すことができる。 • 𝜃𝑖 は𝑃0 𝜃 から生成される。 • 𝑣𝑖 は𝐵𝑒𝑡𝑎 1, 𝛼 から生成される。 • 𝜋 ∼ 𝑆𝐵𝑃 𝛼 – 𝑆𝐵𝑃は棒折り過程であることを示す。
確率分布𝑃 𝜃 の表現:棒折り過程 𝛼は集中度パラメータで、𝑃0 が𝑃にshrinkする程度を示す。
有限混合モデル • ディリクレ過程モデルからの事後分布は(ほとんど確実 に)離散分布となる。 • 連続分布を扱いたいとき、この性質は望ましくない。 • そこで、ディリクレ過程混合モデルを導入する。
有限混合モデル • 𝐾個の要素を伴う有限混合モデルを考える。 – 例:𝐾 = 2 – 𝑦𝑖 |𝑤,
𝜇1 , 𝜇2 , 𝜎1 2, 𝜎2 2 ∼ 𝑖𝑛𝑑 𝑤𝑁 𝑦𝑖 |𝜇1 , 𝜎1 2 + 1 − 𝑤 𝑁 𝑦𝑖 |𝜇2 , 𝜎2 2 – ここで、𝑤𝑁 𝑦𝑖 |𝜇1 , 𝜎1 2 + 1 − 𝑤 𝑁 𝑦𝑖 |𝜇2 , 𝜎2 2 = ∫ 𝑁 𝑦𝑖 |𝜇, 𝜎2 𝑑𝑃 𝜇, 𝜎2 • 𝑃 ⋅ = 𝑤𝛿 𝜇1,𝜎1 2 ⋅ + 1 − 𝑤 𝛿 𝜇2,𝜎2 2 ⋅ • 𝑃は離散分布。 • 以上のことは、一般の𝐾についても成立。
ディリクレ過程混合モデルの定義 • 𝑃に対してディリクレ過程事前分布を用いる。 • 𝐹 𝑦|𝑃 = ∫ 𝐾 𝑦|𝜃
𝑑𝑃 𝜃 , 𝑃 ∼ 𝐷𝑃 𝛼, 𝑃0 – 𝐾 ⋅ |𝜃 は分布関数。 • 対応する密度関数は𝑓 𝑦|𝑃 = ∫ 𝑘 𝑦|𝜃 𝑑𝑃 𝜃 – 𝑘 ⋅ |𝜃 は𝐾 ⋅ |𝜃 の密度関数。
ディリクレ過程混合モデルの定義 • 𝑃が𝑃 = σℎ=1 ∞ 𝑤ℎ 𝛿𝜃ℎ で構成できることから、以下をえる。 –
𝑓 𝑦|𝑃 = σℎ=1 ∞ 𝑤ℎ 𝑘 𝑦|𝜃ℎ • 𝑤1 = 𝑧1 • 𝑤ℎ = 𝑧ℎ 𝛱𝑟=1 ℎ−1 1 − 𝑧𝑟 , ℎ ≥ 2, 𝑧𝑟 ∼ 𝑖𝑖𝑑 𝐵𝑒𝑡𝑎 1, 𝛼 • 𝜃ℎ ∼ 𝑖𝑖𝑑 𝑃0
事後分布の推論 • 以下の階層的なディリクレ過程混合モデルを考える。 – 𝑦𝑖 ∼ 𝑘 𝜃𝑖 – 𝜃𝑖
∼ 𝑃 – 𝑃 ∼ 𝐷𝑃 𝛼, 𝛼𝑃0 • 上記の表現は、𝑦𝑖 |𝑃を𝑓 𝑦|𝑃 からサンプリングするのと 同等。 – 𝑦𝑖 ∼ 𝑖𝑖𝑑 𝑓 𝑦|𝑃
事後分布の推論 • データが与えられたもとで、同時事後分布は以下のよう になる。 – 𝑝 𝑃, 𝜃|𝑑𝑎𝑡𝑎 = 𝑝
𝑃|𝜃 ⋅ 𝑝 𝜃|𝑑𝑎𝑡𝑎 – 𝑝 𝜃|𝑑𝑎𝑡𝑎 は周辺事後分布。 • 条件付き事前分布は、Polya urnで表現できる。 – 𝑝 𝜃𝑖 |𝜃−𝑖 ∼ 𝛼 𝛼+𝑛−1 𝑃0 𝜃𝑖 + 1 𝛼+𝑛−1 σ 𝑗=1 𝑛−1 𝛿𝜃𝑗 𝜃𝑖 , 𝑖 = 1, ⋯ , 𝑛
ギブスサンプリング • 𝑝 𝜃𝑖 |𝜃−𝑖 , 𝑖 = 1, ⋯
, 𝑛からのギブスサンプリング(=𝜃𝑖 のク ラスタリング) を考える。 – 𝑛∗:ベクトル 𝜃1 , ⋯ , 𝜃𝑛 内のクラスターの数 – 𝜃𝑗 ∗, 𝑗 = 1, ⋯ , 𝑛∗:クラスター – 𝑤 = 𝑤1 , ⋯ , 𝑤𝑛 :𝜃𝑖 = 𝜃𝑗 ∗, 𝑖 = 1, ⋯ , 𝑛ならばそのときにかぎり 𝑤𝑖 = 𝑗となるベクトル
ギブスサンプリング • 𝑛∗−で{𝜃𝑖′ : 𝑖′ ≠ 𝑖}内のクラスターの個数を表すとき、 𝑝 𝜃𝑖 |𝜃−𝑖
, 𝑖 = 1, ⋯ , 𝑛は以下の重み付き和で表される。 – 𝛼𝑞0 𝛼𝑞0+σ 𝑗=1 𝑛∗− 𝑛𝑗 −𝑞𝑗 ℎ 𝜃𝑖 |𝑦𝑖 + σ 𝑗=1 𝑛∗− 𝑛𝑗 −𝑞𝑗 𝛼𝑞0+σ 𝑗=1 𝑛∗− 𝑛𝑗 −𝑞𝑗 𝛿𝜃𝑗∗− 𝜃𝑖 • 𝑞𝑗 = 𝑘 𝑦𝑖 |𝜃𝑗 ∗− • 𝑞0 = ∫ 𝑘 𝑦𝑖 |𝜃 𝑝0 𝜃 𝑑𝜃 • ℎ 𝜃𝑖 |𝑦𝑖 ∝ 𝑘 𝑦𝑖 |𝜃𝑖 𝑝0 𝜃𝑖 • 𝑝0 は𝑃0 の密度
ギブスサンプリング • 𝜃𝑖 のアップデートは𝑤𝑖 , 𝑖 = 1, ⋯ ,
𝑛のアップデートも伴う。 • 𝜃𝑖+1 のアップデートの前に、𝑛∗, 𝜃𝑗 ∗ 𝑗 = 1, ⋯ , 𝑛∗ , 𝑤𝑖 ሺ ) 𝑖 = 1, ⋯ , 𝑛 , 𝑛𝑗 𝑗 = 1, ⋯ , 𝑛∗ を再定義する必要がある。
固定化ギブスサンプリング • 無限次元のディリクレ過程を有限次元で近似(有限個のクラスタで 近似) することで、𝑝 𝑃, 𝜃|𝑑𝑎𝑡𝑎 の周辺化を避けることができる。 – クラスタ数𝑁を十分大きく選ぶ必要がある。
• 𝑃𝑁 ⋅ = σℎ=1 𝑁 𝜋ℎ 𝛿𝑧ℎ ⋅ – 𝜋1 = 𝑣1 – 𝜋ℎ = 𝑣ℎ ς𝑟=1 𝑙−1 1 − 𝑣𝑟 , ℎ = 2, ⋯ , 𝑁 − 1 – 𝜋𝑁 = Π𝑟=1 𝑁−1ሺ1 − 𝑣𝑟 ) – 𝑣ℎ ∼ Beta 1, 𝛼 , ℎ = 1, ⋯ , 𝑁 − 1
従属ディリクレ過程 • これまでノンパラメトリックな事前分布として単一の分布を考えて きた。 • ここでは、従属的な確率測度の集合{𝑃1 , ⋯ , 𝑃𝑇
}を考える。 – 𝑃𝑗 ∼ 𝐷𝑃 𝛼𝑗 , 𝑃0𝑗 , 𝑗 = 1, ⋯ , 𝑇 • 棒折り過程に基づいて従属ディリクレ過程を定義する。 – 𝑃𝑗 = σℎ=1 ∞ 𝜋𝑗ℎ 𝛿𝜃𝑗ℎ ∗ – 𝜋 = {𝜋𝑗ℎ } ∼ 𝑄 – 𝜃ℎ ∗ = {𝜃𝑗ℎ ∗ } ∼ 𝑃0
従属ディリクレ過程 • 𝑄を構成するのは計算上複雑なため、𝑗に依存しない重み (common-weights)が使われることが多い。 – 𝑃𝑗 = σℎ=1 ∞ 𝜋ℎ
𝛿𝜃𝑗ℎ ∗ – 𝜋 ∼ 𝑠𝑡𝑖𝑐𝑘 𝛼 – 𝜃ℎ ∗ ∼ 𝑃0 • 事後推論は固定化ギブスサンプリングを用いれば、その ステップはディリクレ過程混合モデルと本質的に同じ。
階層ディリクレ過程 • 𝑗に依存しない従属ディリクレ過程は柔軟性を欠くので、代わりに階 層DPなるものを考える。 • 𝑃𝑗 ∼ 𝐷𝑃 𝛼𝑃0 ,
𝑃0 ∼ 𝐷𝑃 𝛽𝑃00 – 𝑃 ∼ 𝐻𝐷𝑃 𝛼, 𝛽, 𝑃00 とも書ける。 • 棒折り過程に基づけば、以下のように表現できる(common-atoms)。 – 𝑃𝑗 = σℎ=1 ∞ 𝜋𝑗ℎ 𝛿𝜃ℎ ∗ – 𝑃0 = σℎ=1 ∞ 𝜆ℎ 𝛿𝜃ℎ ∗ – 𝜃ℎ ∗ ∼ 𝑃00
入れ子型ディリクレ過程 • 階層ディリクレ過程ではグループをまたいでユニットをクラスタリン グできるが、分布が同一であるグループをクラスタリングした方が好 ましいこともある。 • そこで以下のような入れ子型のディリクレ過程を考える。 – 𝑃𝑗 ∼
𝑃, 𝑃 ∼ 𝐷𝑃 𝛼𝑃0 , 𝑃0 ≡ 𝐷𝑃 𝛽𝑃00 • 棒折り過程に基づけば、以下のように表現できる。 – 𝑃𝑗 ∼ 𝑃 = σℎ=1 ∞ 𝜋ℎ 𝛿𝑃ℎ ∗ – 𝜋 ∼ 𝑠𝑡𝑖𝑐𝑘 𝛼 – 𝑃ℎ ∗ ∼ 𝐷𝑃 𝛽𝑃00
階層ディリクレ過程と 入れ子型ディリクレ過程の比較 • 階層ディリクレ過程ではcommon-atomsを使って𝑃𝑗 を構成 するが、重みはグループごとに違う。 – 𝑃𝑟 𝑝𝑗 =
𝑝𝑗 ′ = 0 • 入れ子型ディリクレ過程では𝑃が通常の棒折り過程から 構成されるため、𝑃そのものがクラスタリングされる。 – 𝑃𝑟 𝑝𝑗 = 𝑝𝑗 ′ = 1 1+𝛼 – これはPolya urn表現からきているもの。
APPENDIX
回帰分析への利用 • 𝑦𝑖 = 𝑋𝑖 𝛽 + 𝜖𝑖 , 𝜖𝑖
∼ 𝑓 – 𝑋𝑖 は説明変数で、𝜖は誤差項 • ディリクレ過程を使って𝜖の分布を柔軟に表現したい – 𝜖 ∼ 𝑁 0, 𝜙𝑖 −1 – 𝜙𝑖 ∼ 𝑃 – 𝑃 ∼ 𝐷𝑃 𝛼𝑃0
グループごとに異なる パラメータのモデリング • 𝑦𝑖𝑗 = 𝜇𝑖 + 𝜖𝑖𝑗 – 𝜇𝑖
∼ 𝑓 – 𝜖𝑖𝑗 ∼ 𝑔 • ディリクレ過程を使って𝜇𝑖 の分布を柔軟に表現したい – 𝜇𝑖 ∼ 𝑃 – 𝑃 ∼ 𝐷𝑃 𝛼𝑃0
functionalデータの分析 • 𝑦𝑖𝑗 ∼ 𝑁 𝑓𝑖 𝑡𝑖𝑗 , 𝜎2 –
𝑡は時間 – 𝑓𝑖 𝑡𝑖𝑗 = 𝛴ℎ=1 𝐻 𝜃𝑖ℎ 𝑏ℎ 𝑡 – 𝜃𝑖 = 𝜃𝑖1 , ⋯ , 𝜃𝑖𝐻 • ディリクレ過程を使って𝜃𝑖 の分布を柔軟に表現したい – 𝜃𝑖 ∼ 𝑃
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}