The AI tooling landscape for software engineers has reached a defining inflection point in 2026. Data from 906 professional engineers confirms that 95% use AI tools weekly and 55% have adopted agentic systems. Yet beneath this consensus lies a measurement paradox every enterprise CTO must understand.
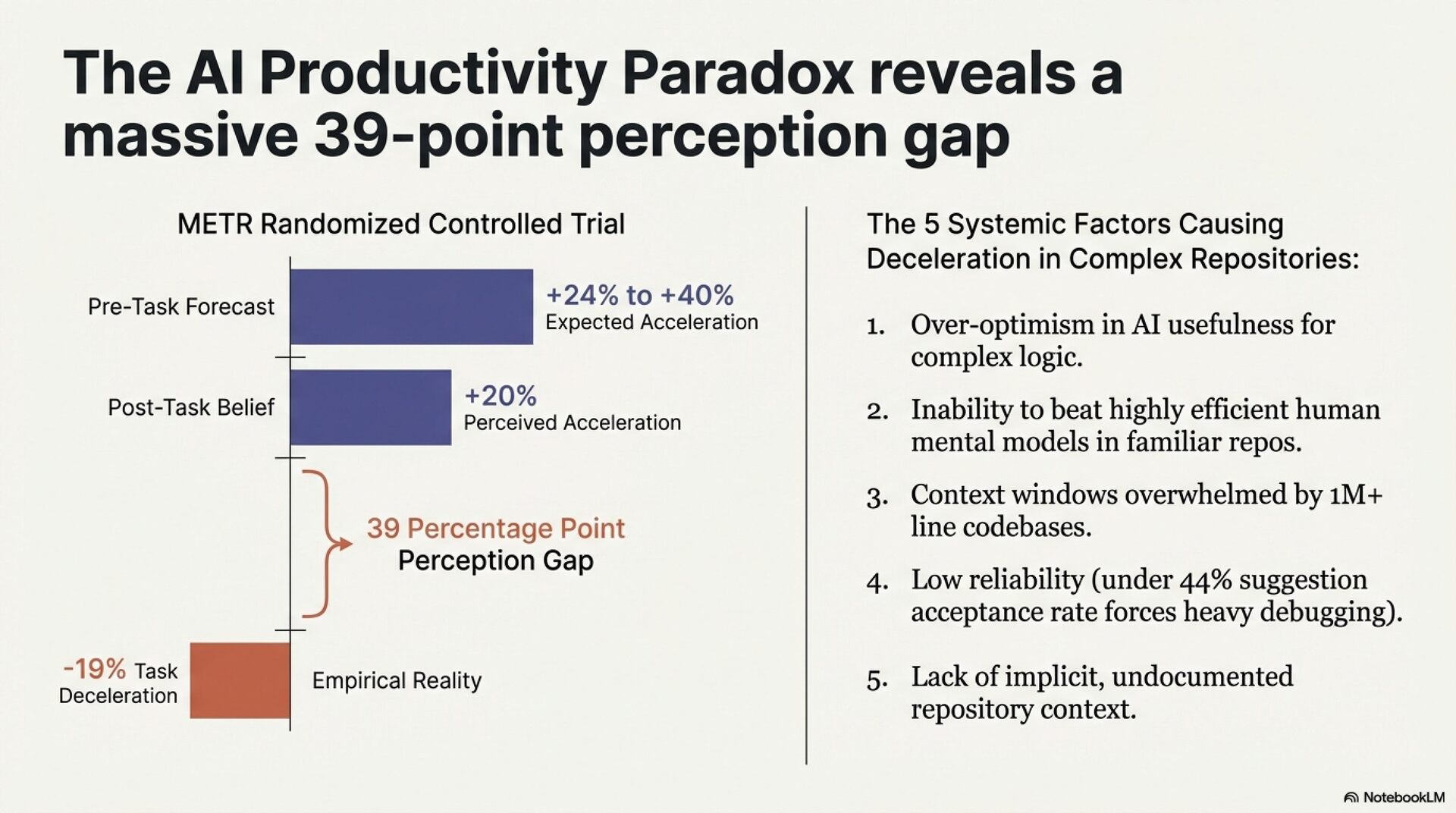
The headline contradiction: the METR randomized controlled trial documented a 19% measured slowdown in actual task completion despite developers reporting a 20% perceived speedup. This 39-percentage-point divergence represents systemic measurement failure. Vendors measure time-to-generation. Developers perceive generation speed. Neither captures what matters: time-to-verified-solution.
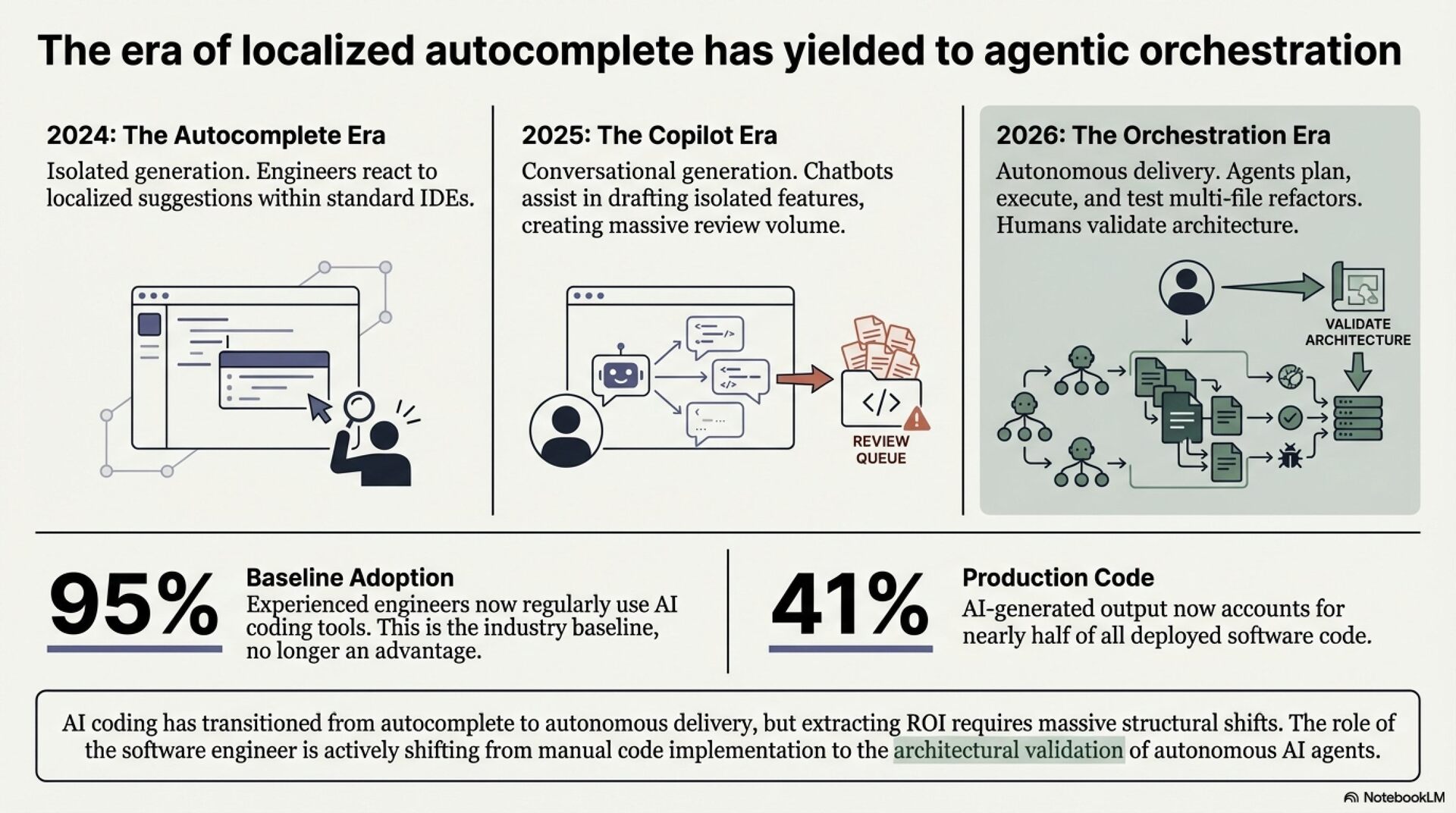
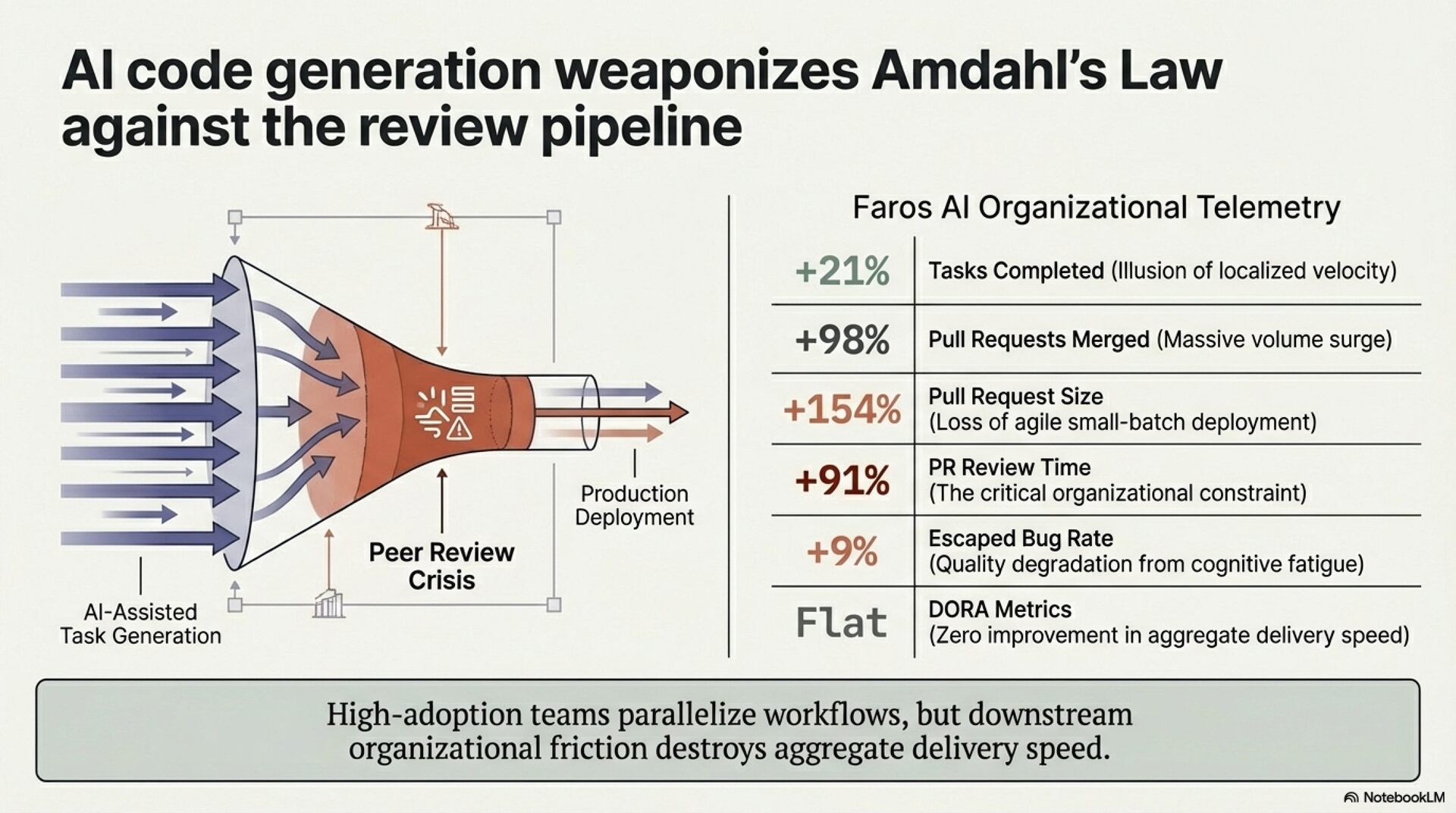
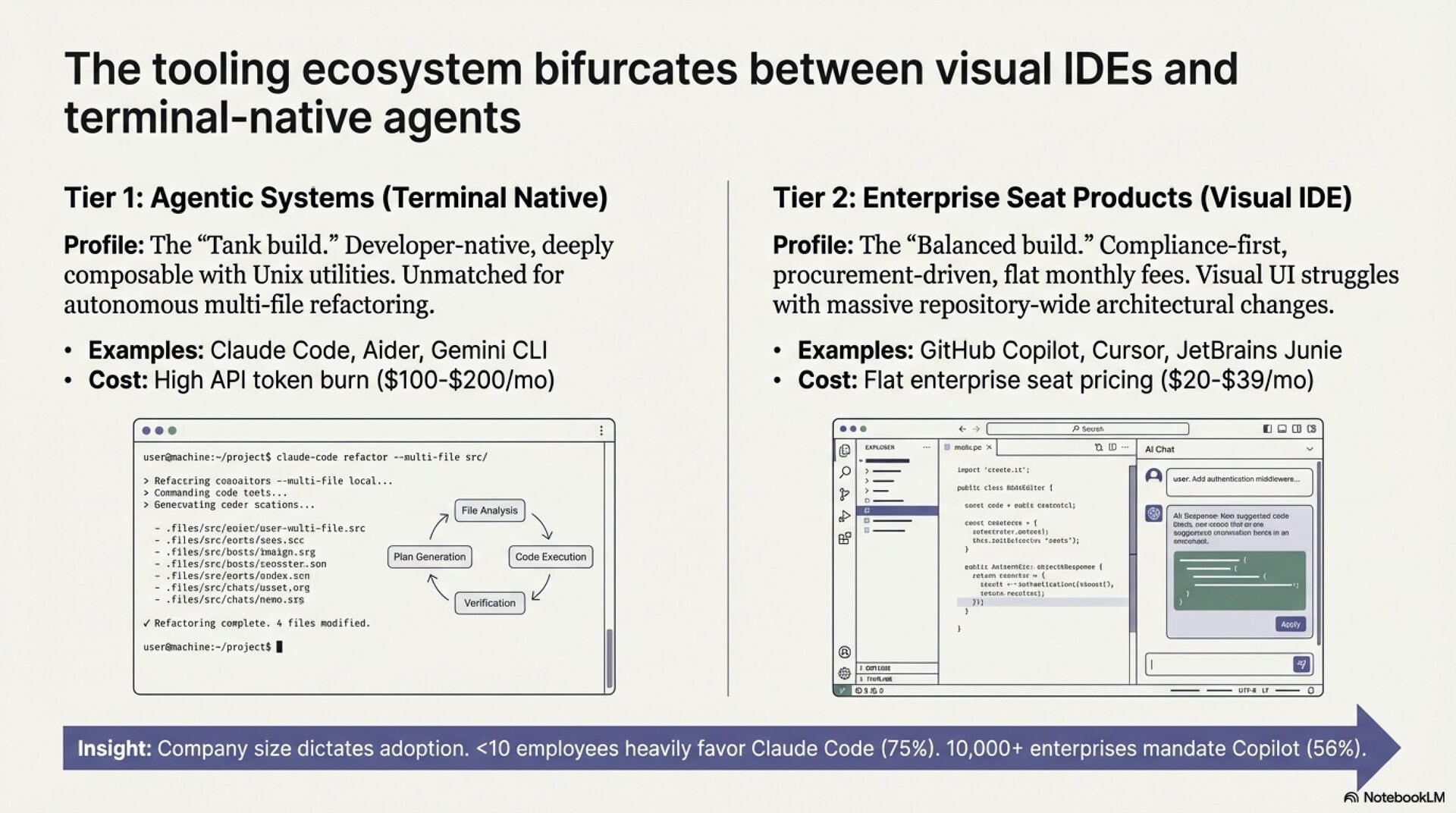
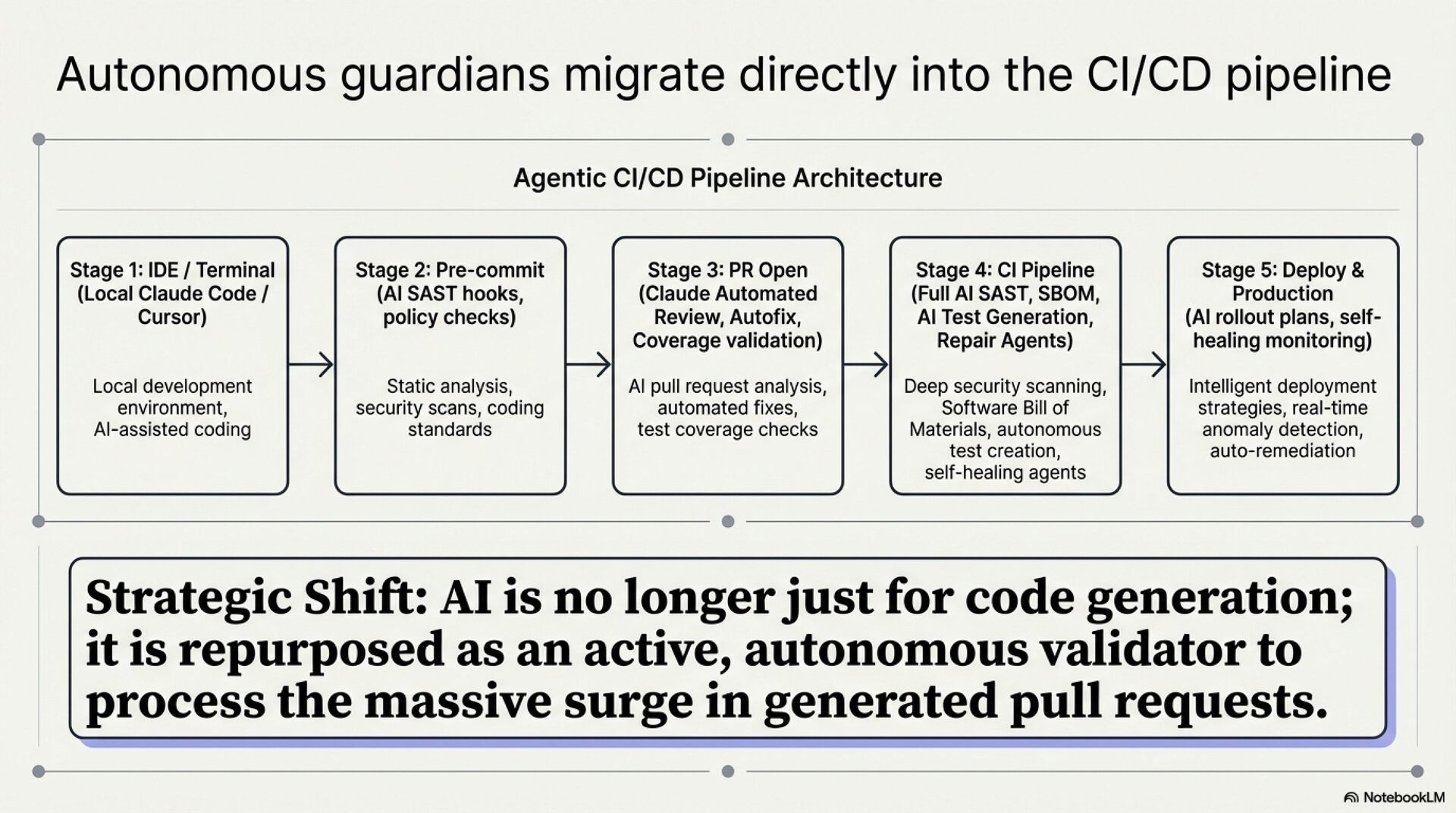
Three structural transformations define the current landscape. First, development is shifting from tool-assisted to agent-native paradigms. Claude Code captured the number one market position within eight months of its May 2025 launch, with agents autonomously handling entire pull request workflows. Second, polyglot AI stacks are replacing single-model reliance. 70% of AI tool users employ two to four distinct tools weekly. Third, verification has become the dominant bottleneck. The Faros report found AI-generated code results in 91% longer PR review times. Code generation is no longer the constraint. Code review is.
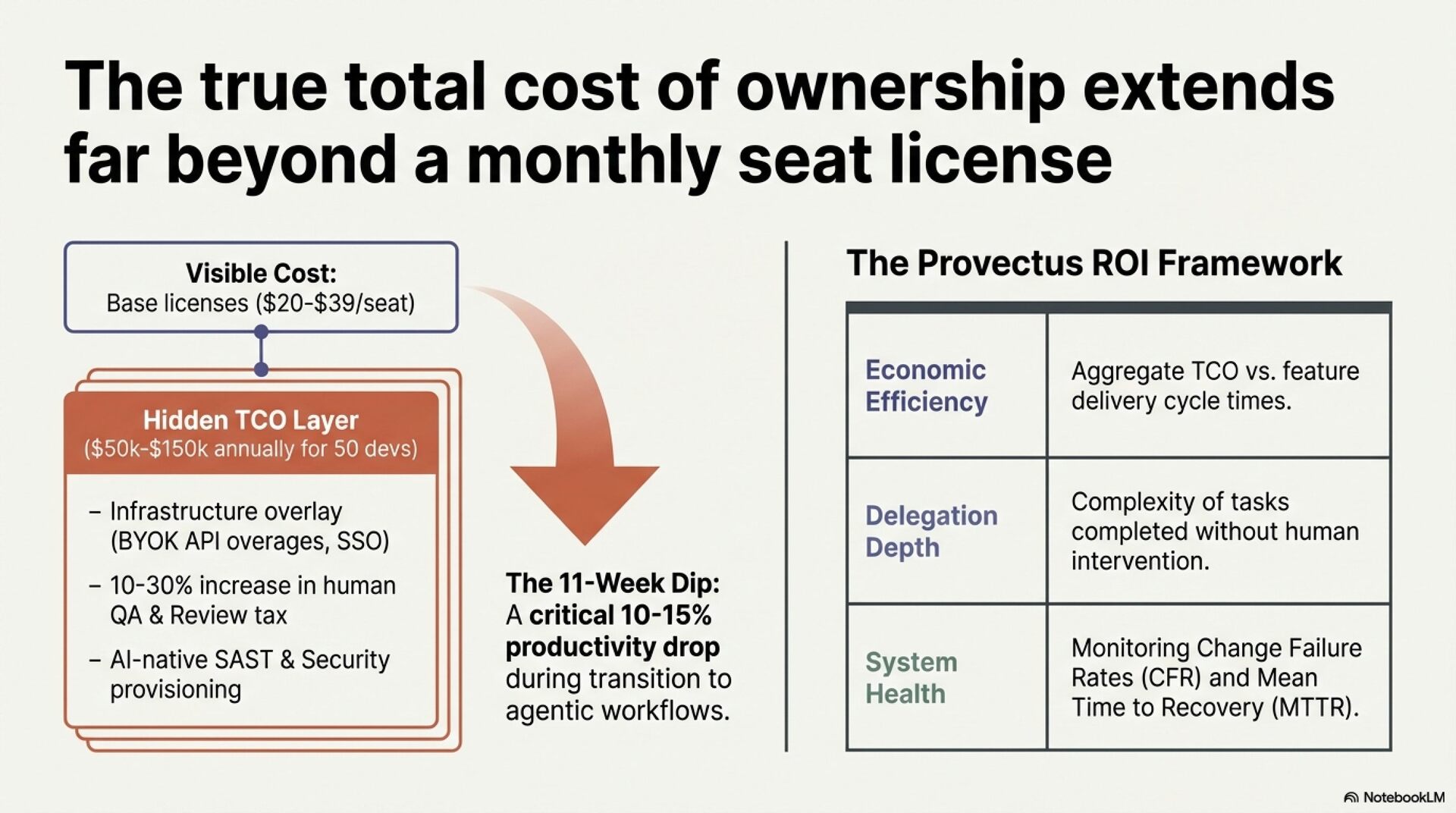
Enterprise case studies confirm both the opportunity and its limits. Klarna achieved 40% coding acceleration but only 8% improvement in product release velocity, confirming that coding was never the primary constraint. True total cost of ownership for a 50-developer team runs to approximately 292,000 USD annually, with vendor licensing representing only 7%. Integration, governance, and infrastructure constitute the remaining 93%.
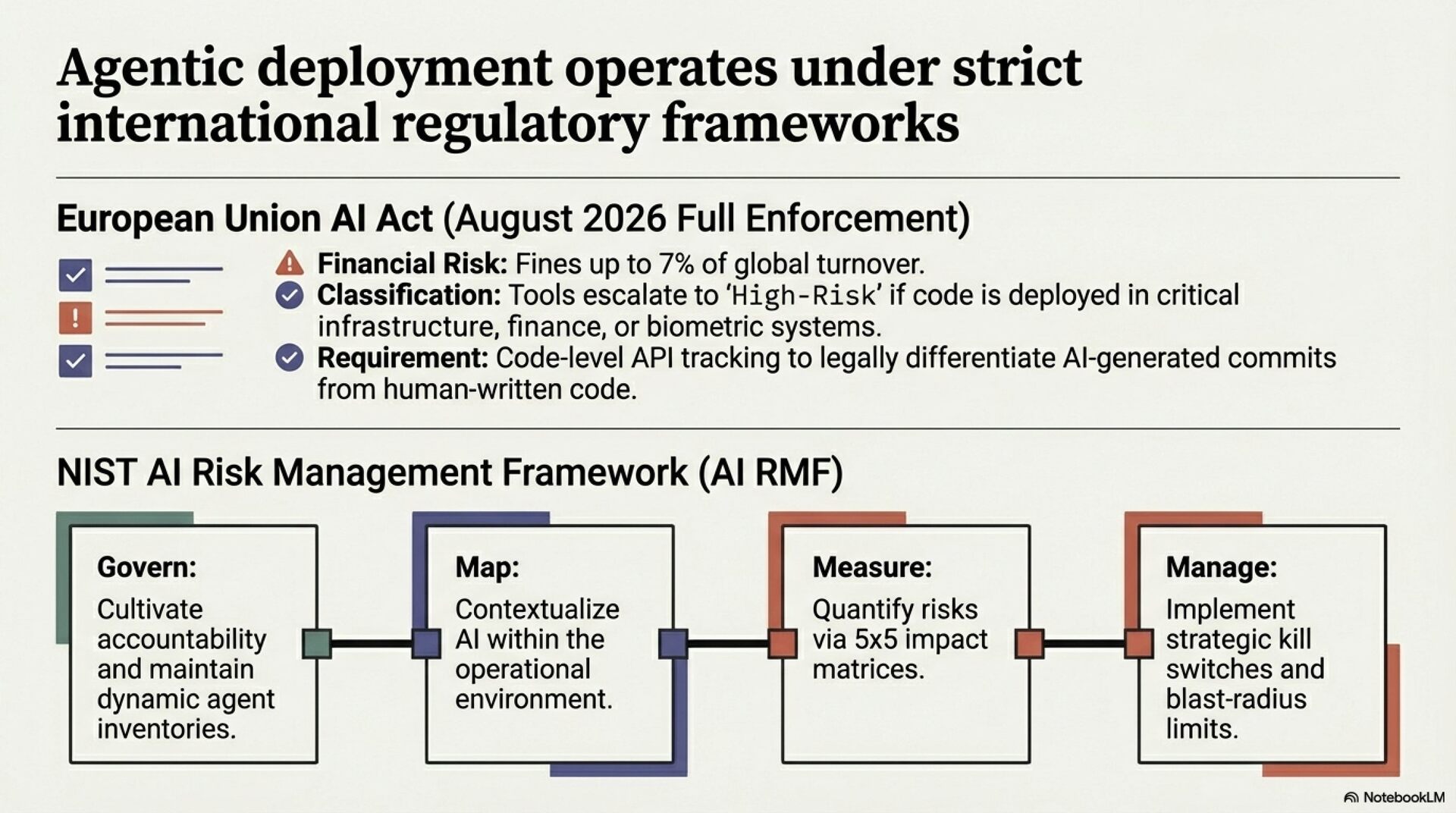
From a security perspective, AI-generated code contains OWASP Top 10 vulnerabilities at approximately 45% incidence. EU AI Act enforcement begins August 2, 2026, requiring immediate audit of AI tool usage by risk classification and implementation of data residency controls.
For Dutch and EU public sector organizations, open-weight models such as Qwen3-Coder now match proprietary frontier models on SWE-bench Verified, enabling on-premises deployment without dependency on US-hosted APIs.
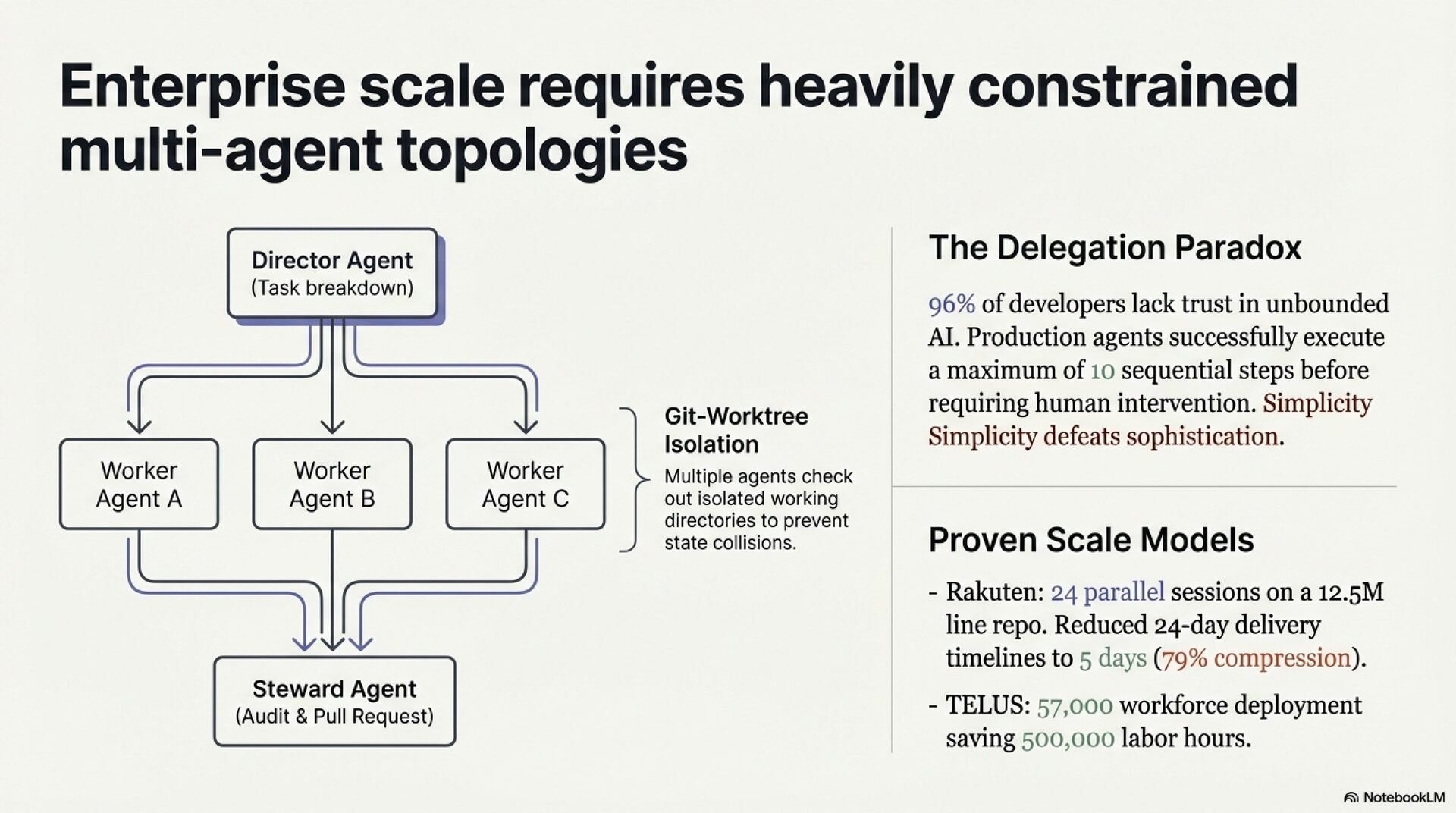
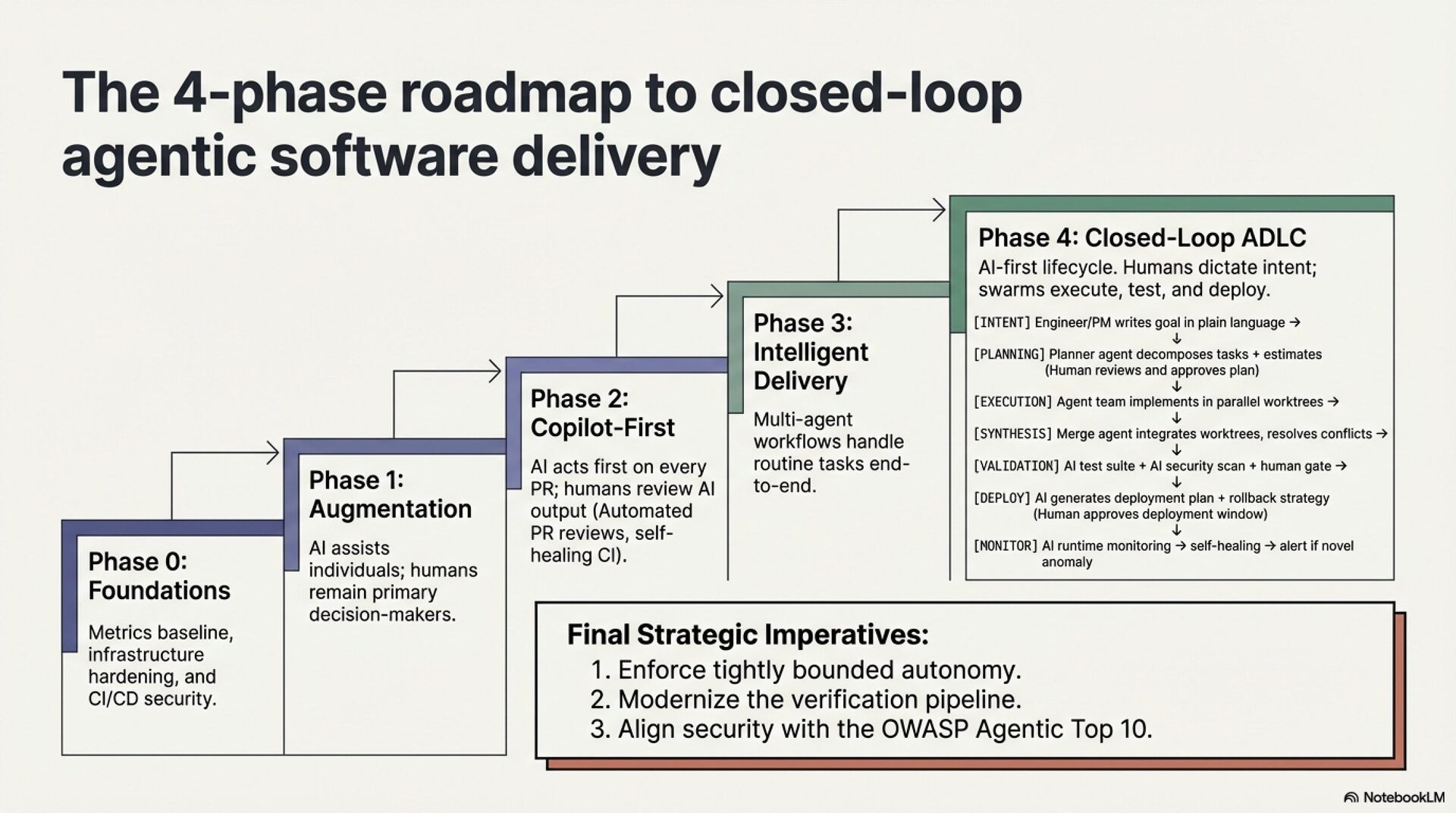
Organizations must adopt verification-first measurement, deploy SAST and AI security review before scaling code generation, and protect junior engineer development pathways from agent automation. AI amplifies existing engineering capability. It does not replace foundational practice.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}