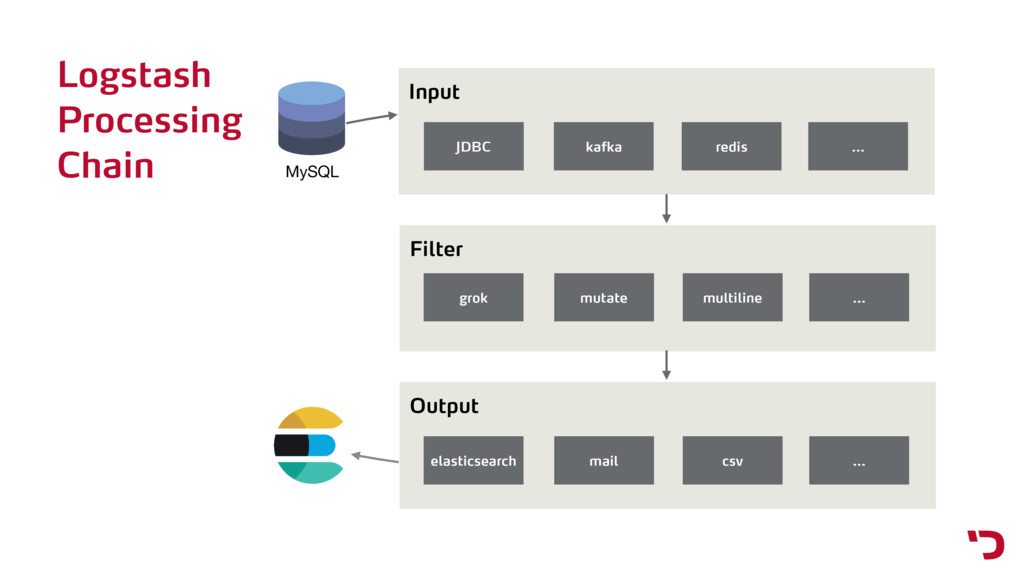
Analyze any kind of data with the Elasticsearch ELK stack. The talk describes how to import data from MySQL using Logstash, set up the mappings in Elasticsearch and visualize the data with Kibana.
full text search engine with real-time search an analytics capabilities. Based on Apache Lucene. Combines search and powerful analytics. Provides a HTTP REST and a Java interface.
allows you to interact with your data through powerful graphics. Visualizations that also act as filters can be combined into custom dashboards that help you gain and insights from your data.
growing set of beats cover inputs from network packets to log files or infrastructure data. Beats is also a platform to building a variety of lightweight custom shippers to leverage any type of data you like.
Records never get deleted • Every record has an unique incremented identifier • Comparable to log files Evolving • Records are created, updated and deleted (typical CRUD model) • Every record has its unique identifier • Changes are detected by updated timestamp vs. record_last_run => true use_column_value => true tracking_column => „uid" record_last_run => true tracking_column => „uid"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}