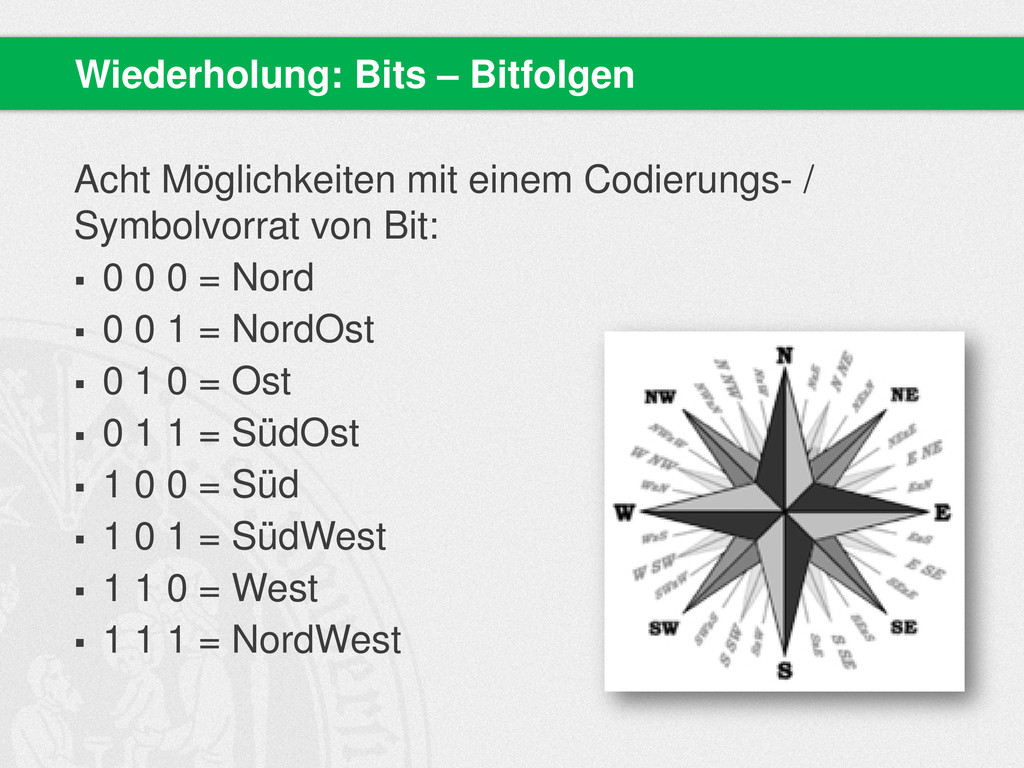
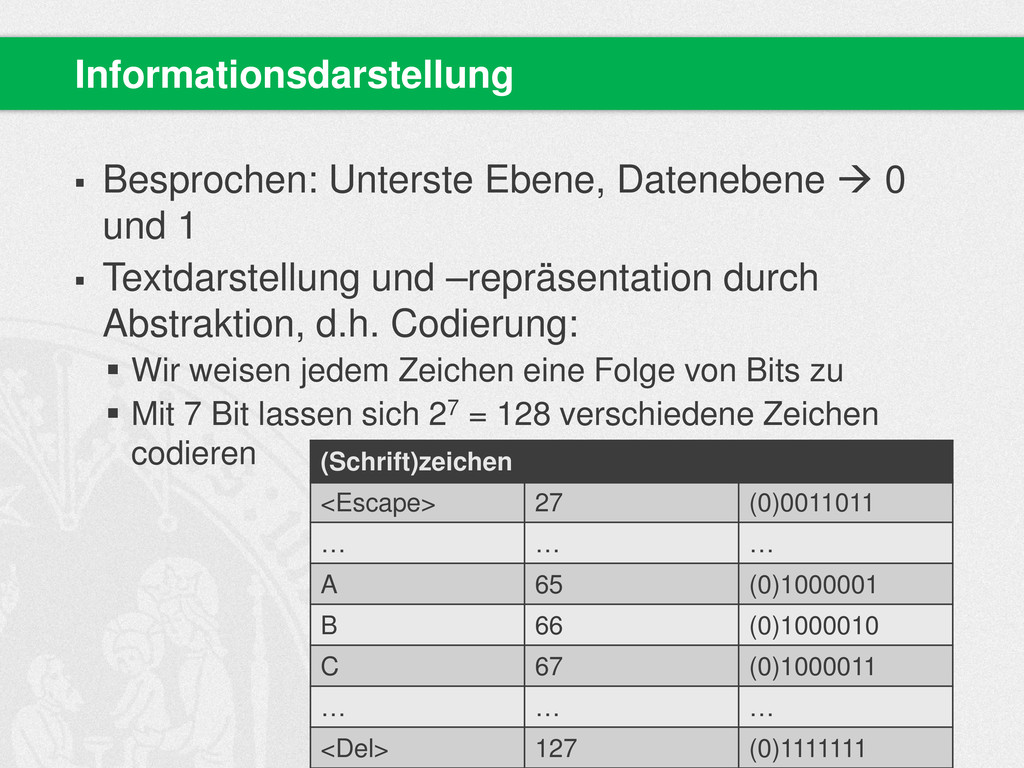
des Alphabets zu codieren? A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z 1 Bit = 2 Symbole 2 Bit = 4 3 Bit = 8 4 Bit = 16 5 Bit = 32 Symbole Plus Kleinbuchstaben: 52 Symbole zu codieren: 6 Bit = 64 Symbole Hausaufgaben
![Universität zu Köln. Historisch-Kulturwissenschaftliche Informationsverarbeitung Jan G. Wieners // [email protected]](https://files.speakerdeck.com/presentations/507d8362a2a40300020576e8/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
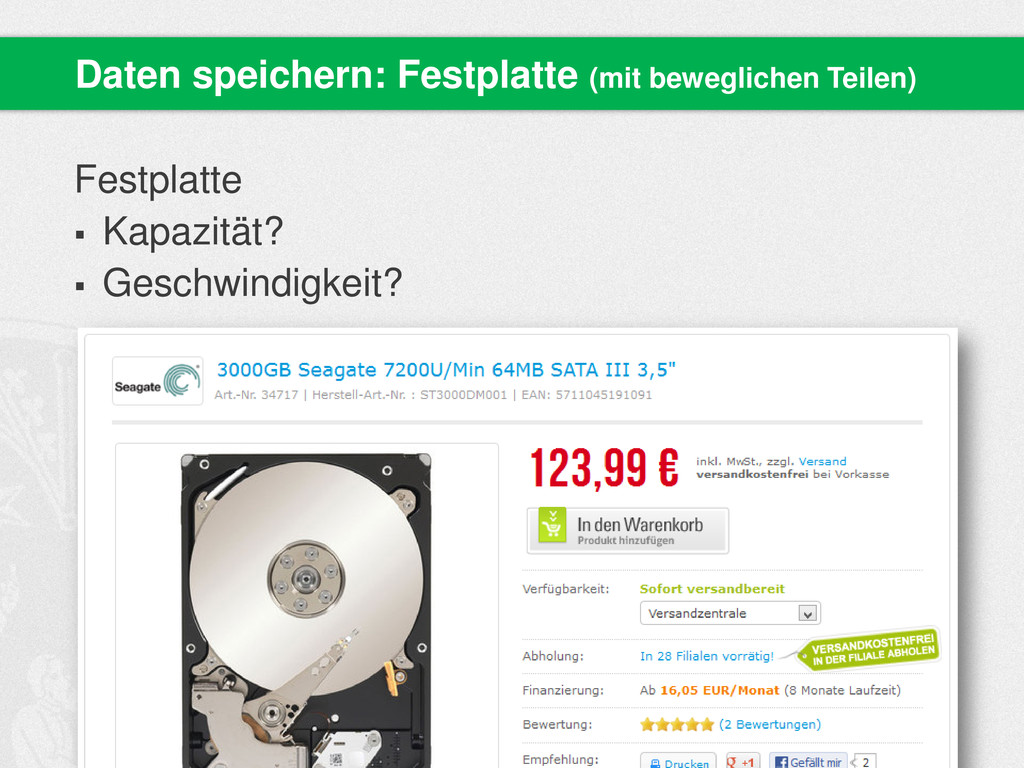{kind=link}
{kind=link}
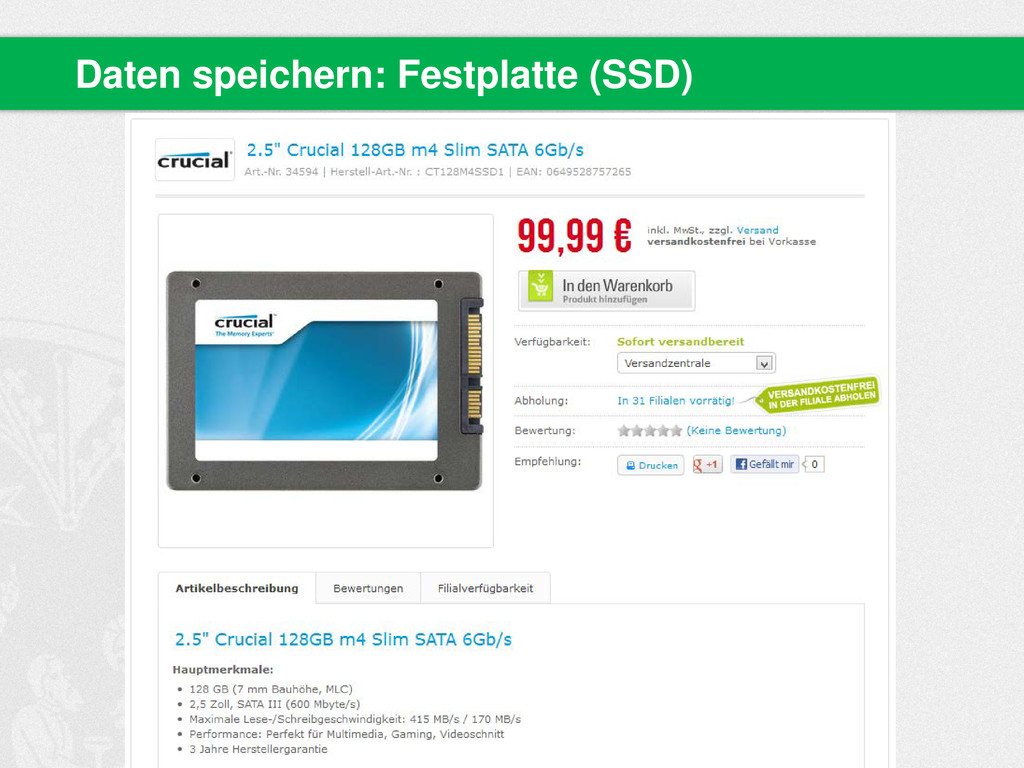{kind=link}
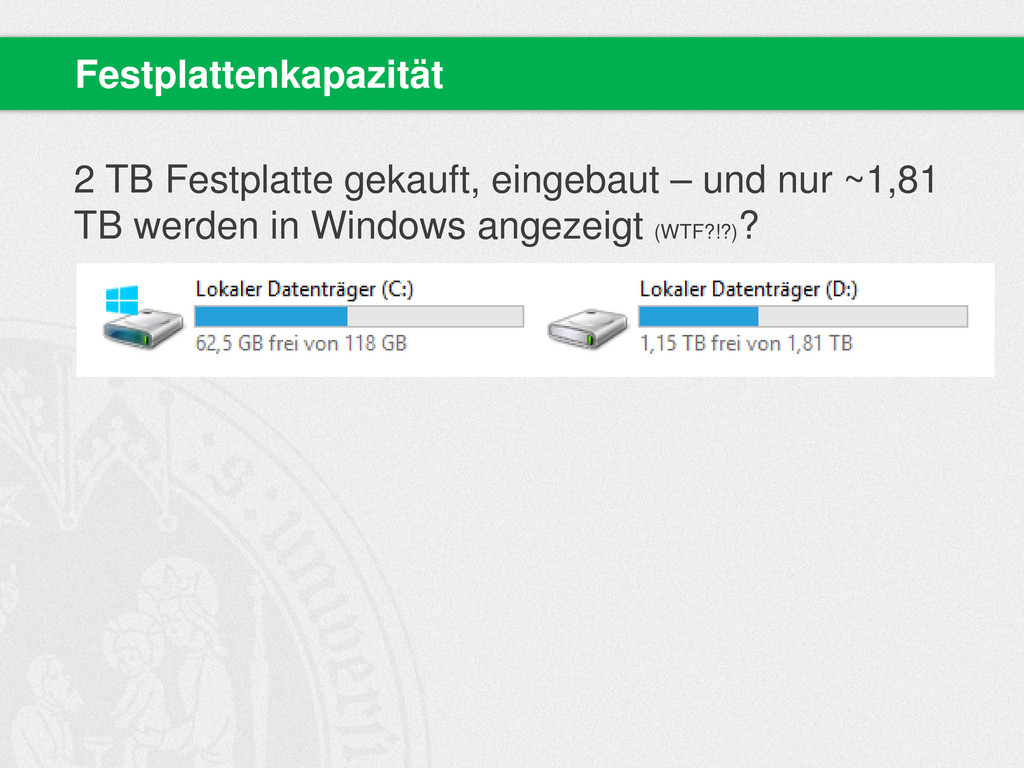{kind=link}
{kind=link}
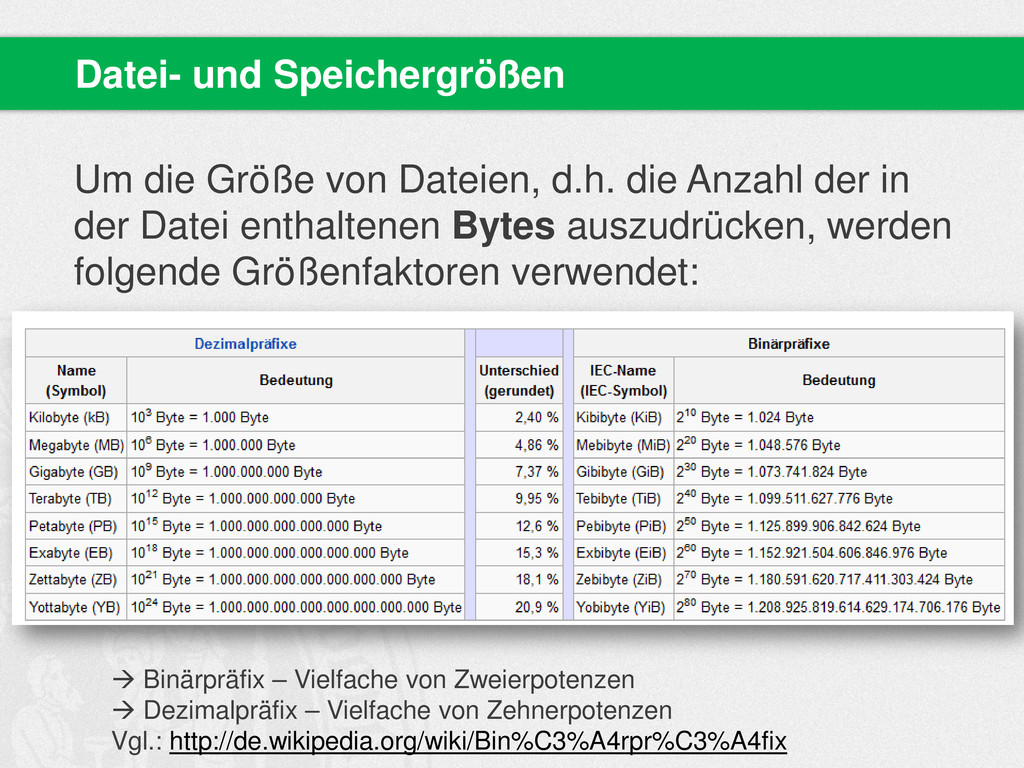{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}