A practical overview of using Elasticsearch within a Hadoop environment to perform real-time indexing, search and data-analysis.
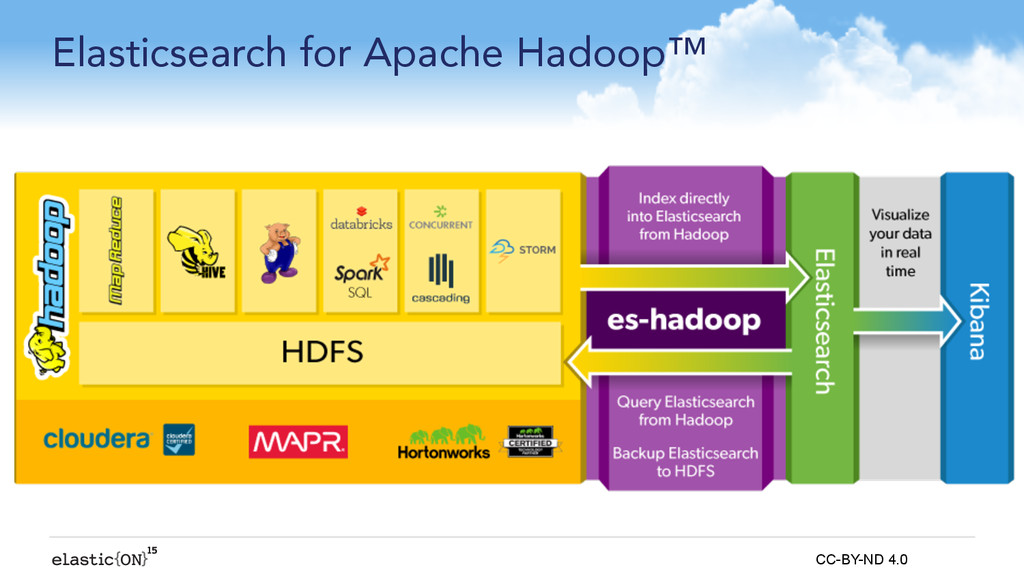
In this session, Costin will deep dive into Elasticsearch for Apache Hadoop, showing off our rich integrations between the various Hadoop libraries, whether batch (Map/Reduce, Pig, Hive) or stream oriented (such as Apache Spark). He'll also touch on YARN support and the HDFS snapshot/restore plugin.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
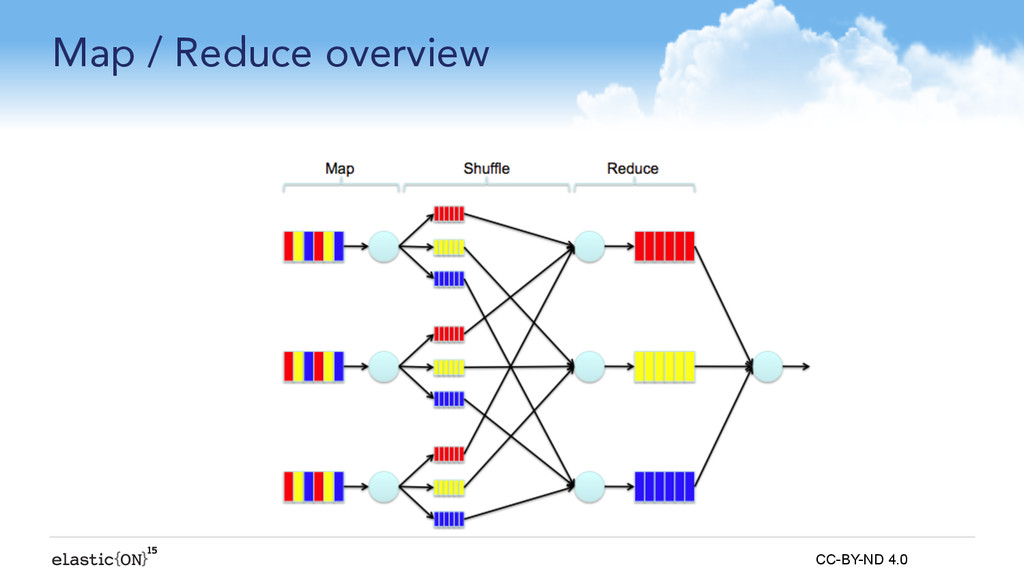{kind=link}
{kind=link}
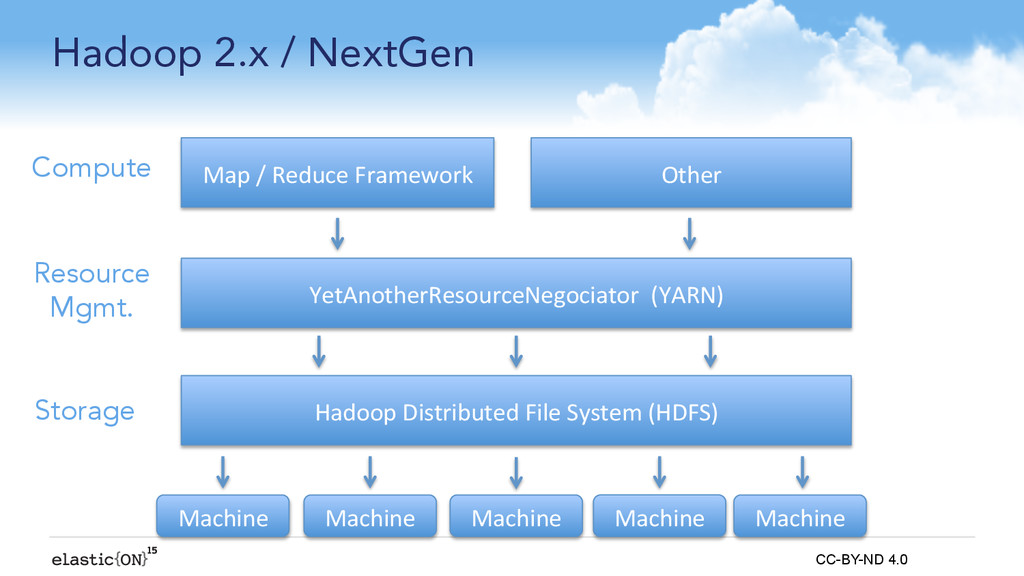{kind=link}
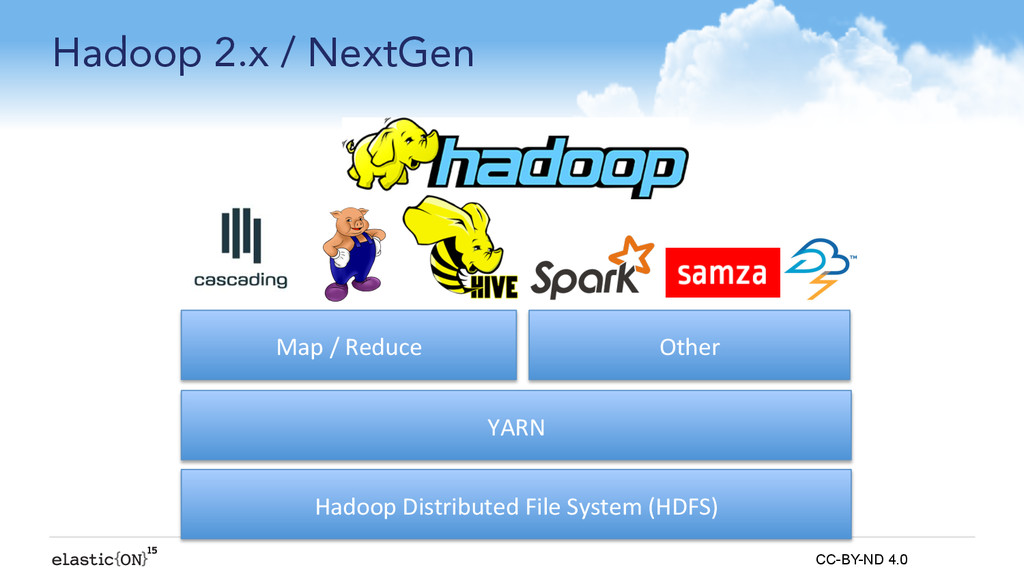{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}