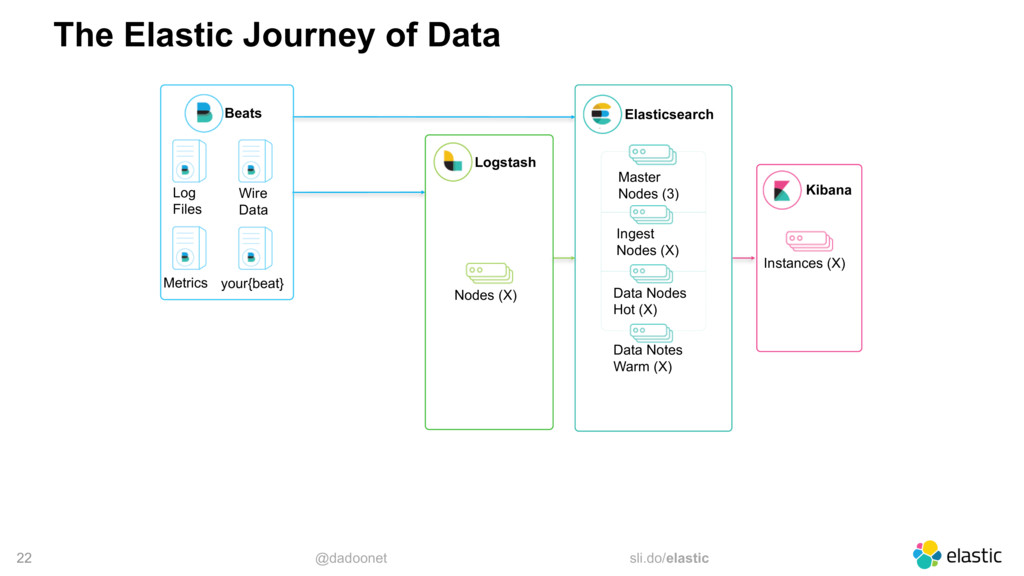
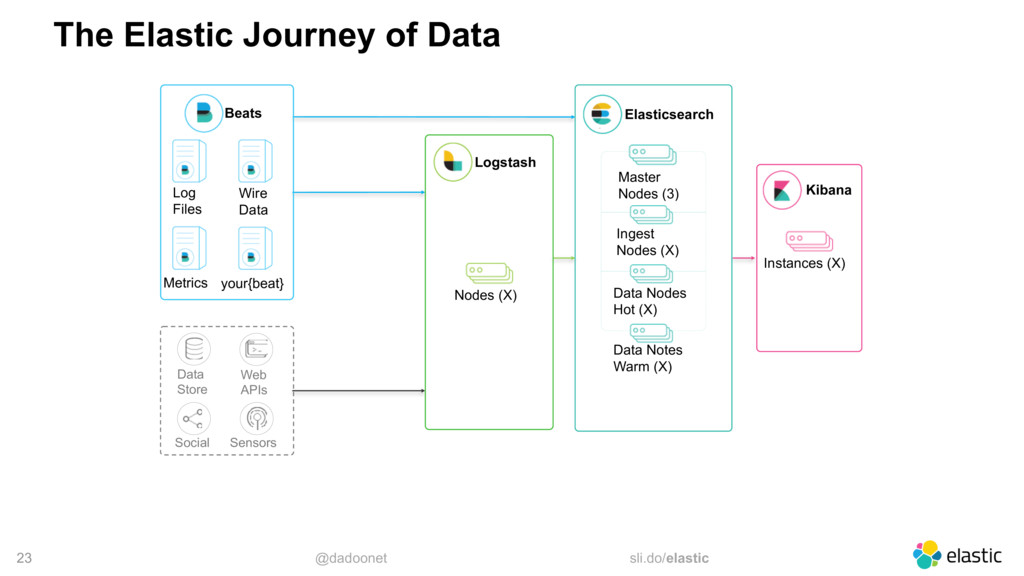
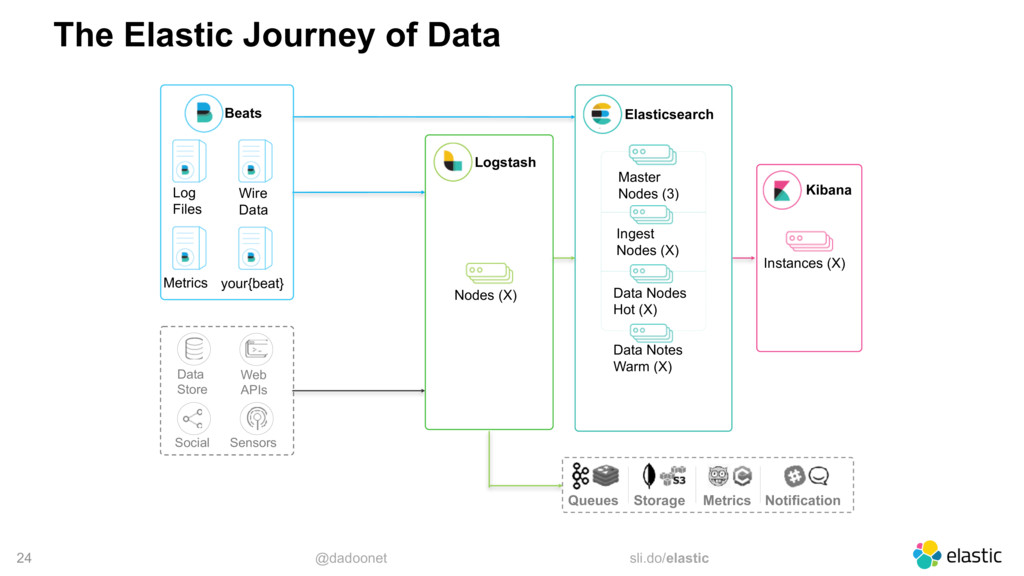
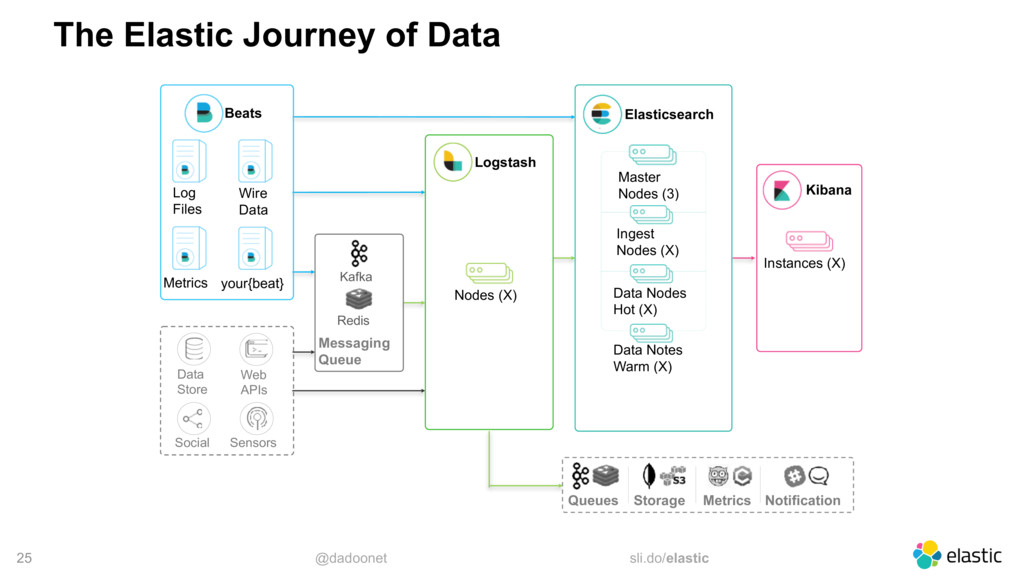
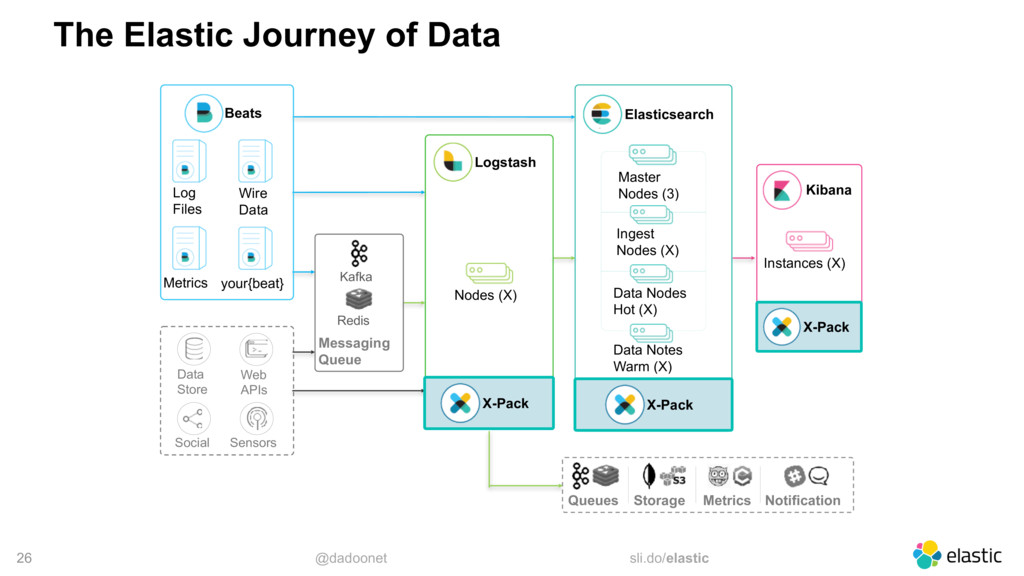
Monitoring an entire application is not a simple task, but with the right tools, it is not a hard task either. However, events like Black Friday can push your application to the limit, and even cause crashes. As the system is stressed, it generates a lot more logs, which may crash the monitoring system as well. In this talk, I will walk through the best practices when using the Elastic Stack to centralize and monitor your logs. I will also share some tricks to help you with the huge increase of traffic typical in Black Fridays.
* monitoring architectures
* optimal bulk size
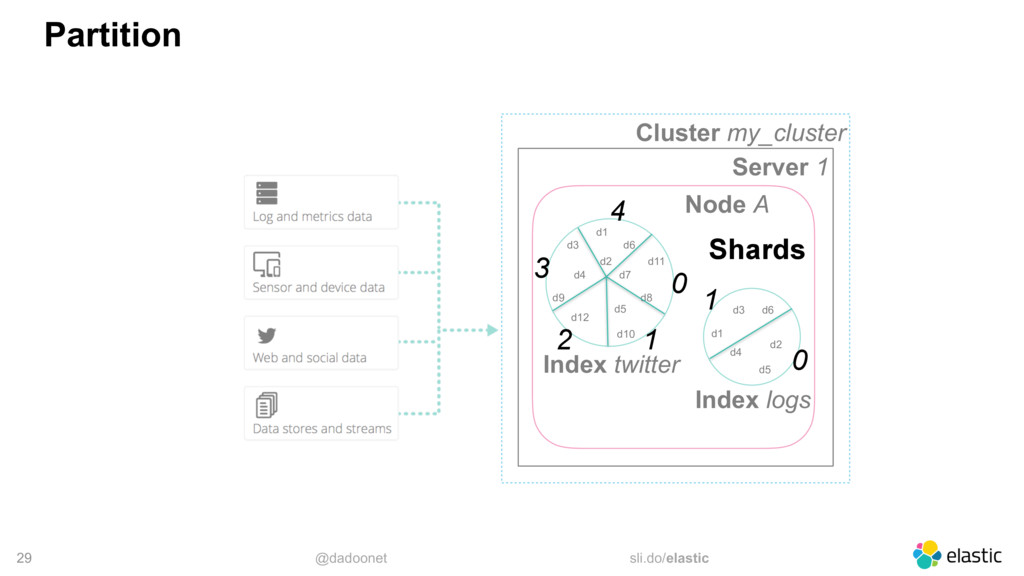
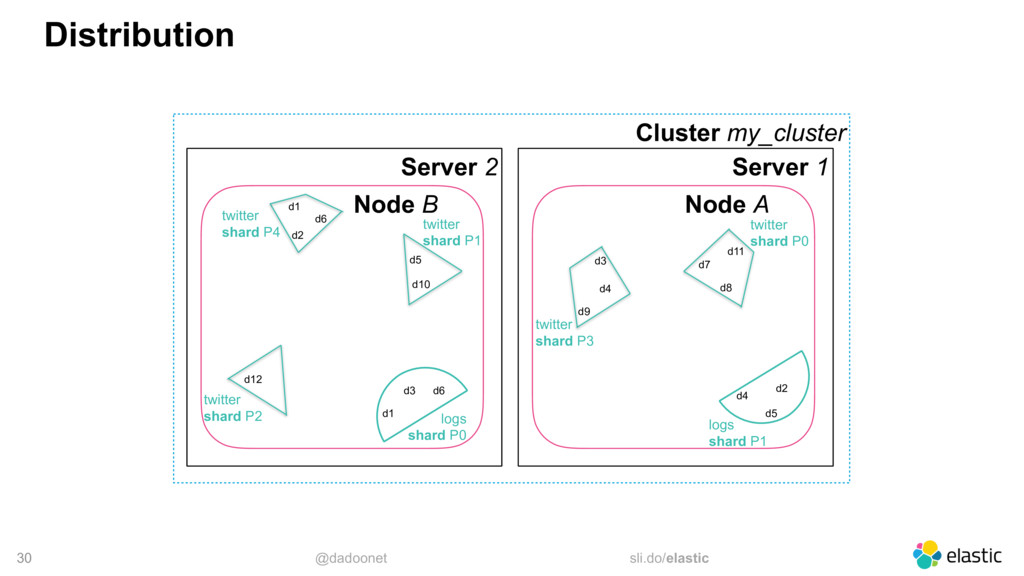
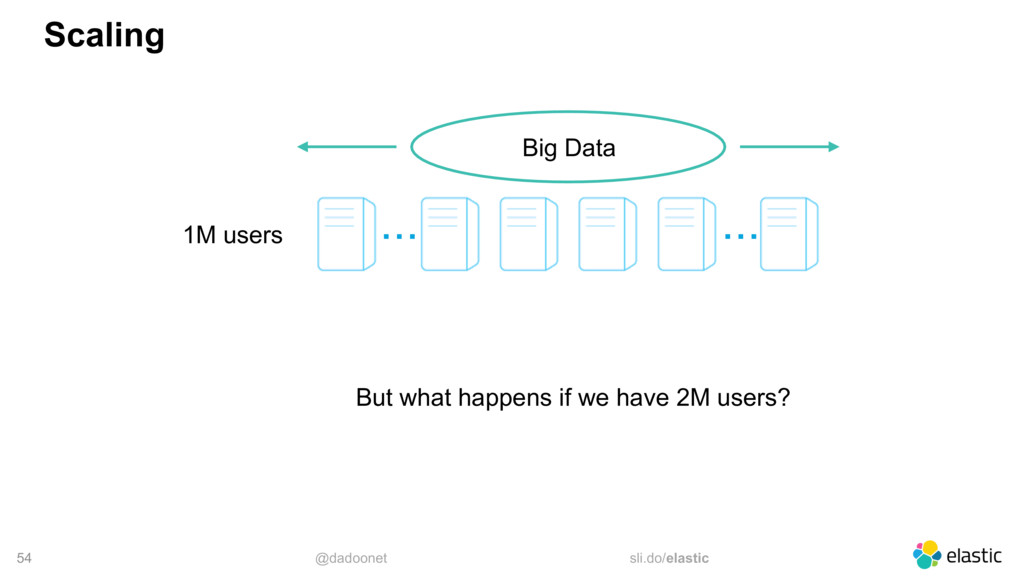
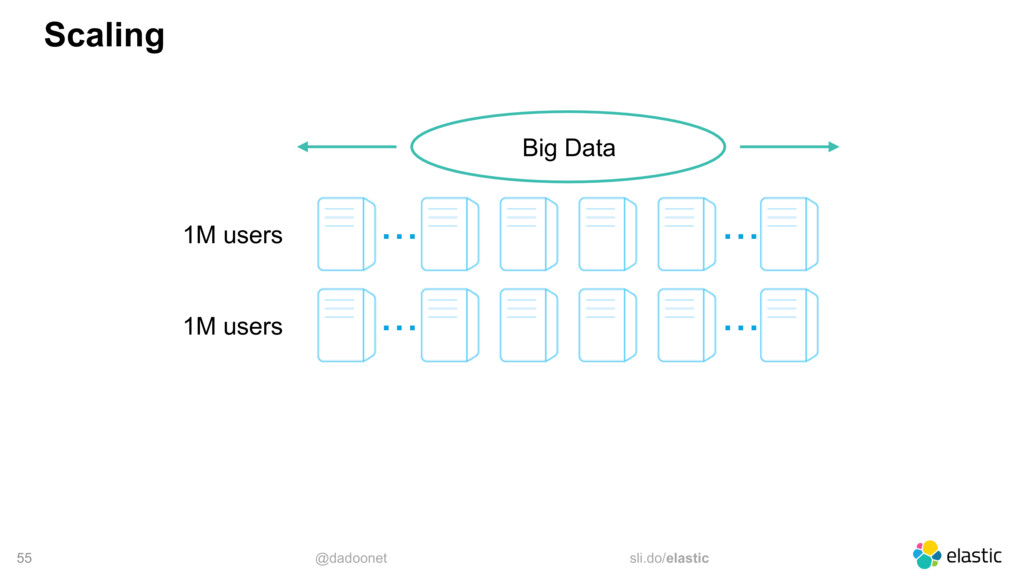
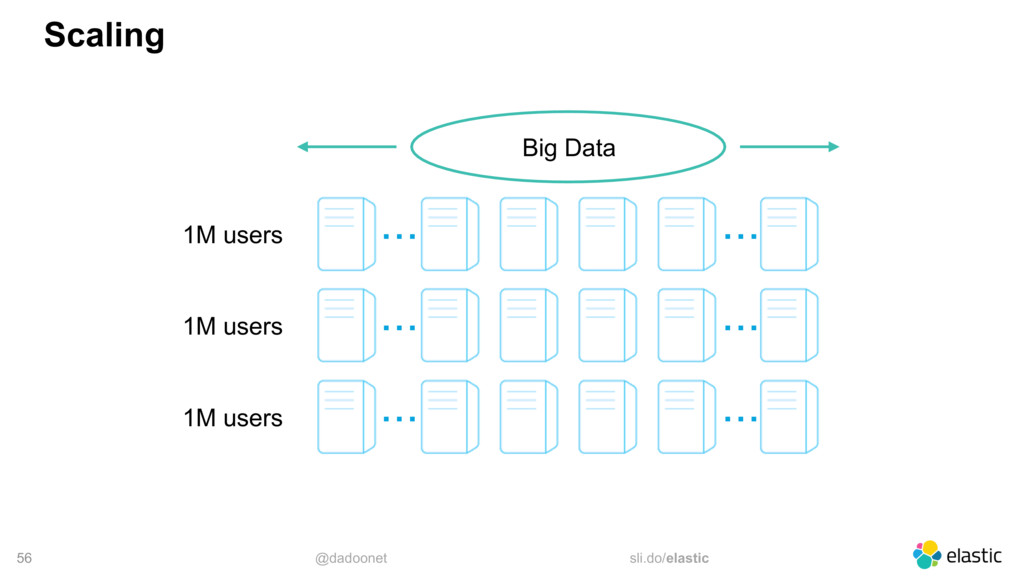
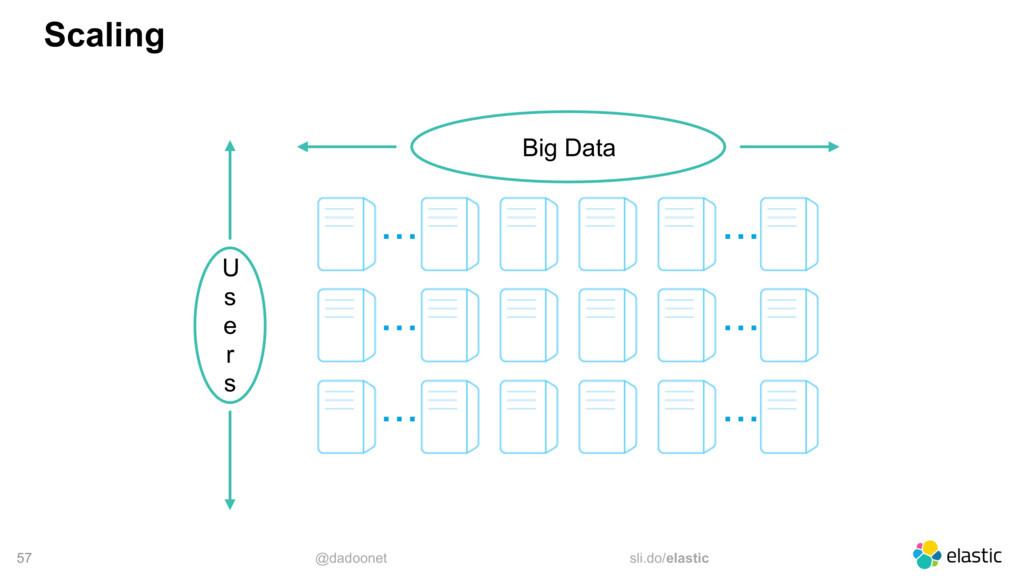
* distributing the load
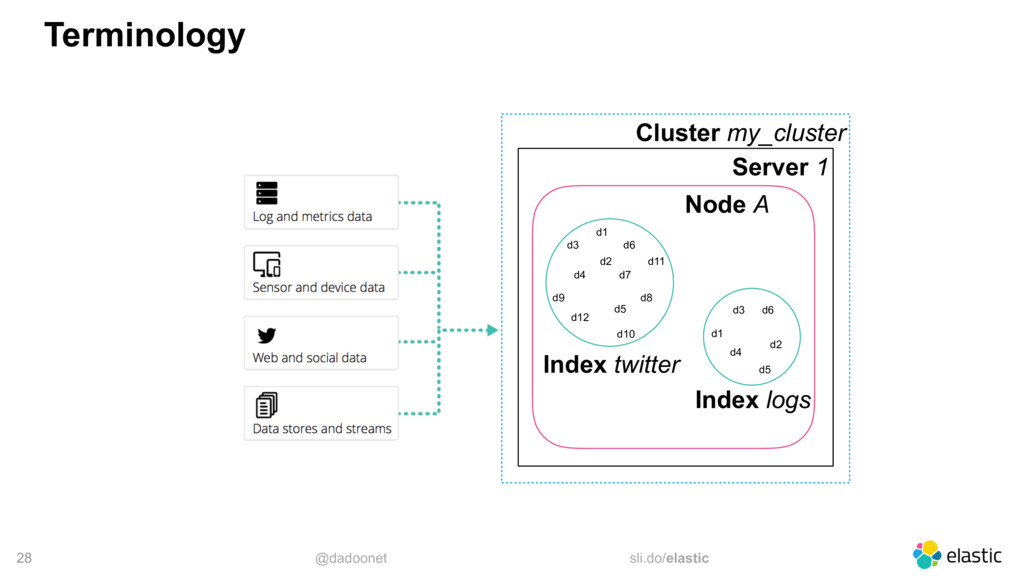
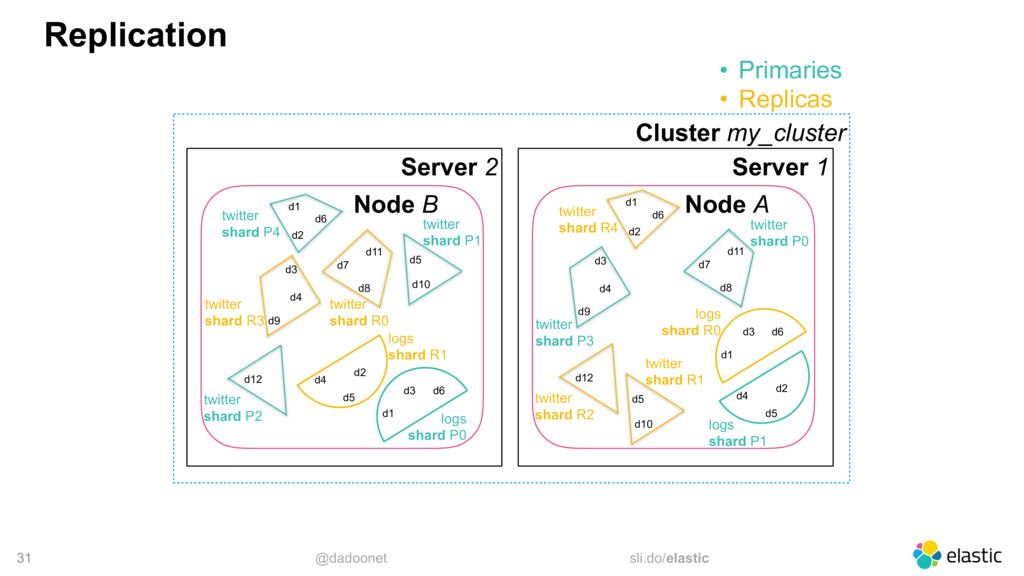
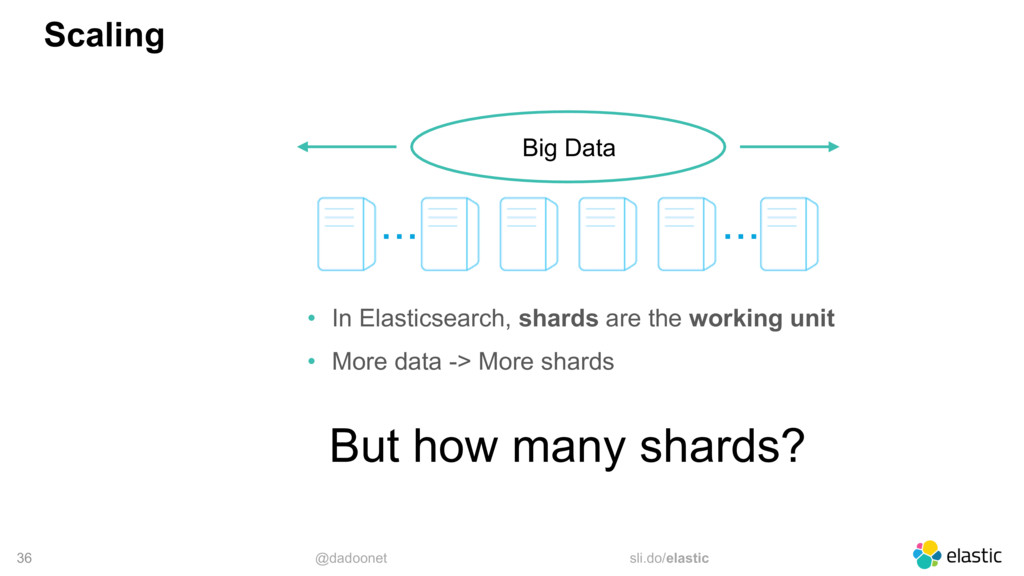
* index and shard size
* optimizing disk IO
* monitoring queries
* monitoring your monitoring system :P
Takeaway: best practices when building a monitoring system with the Elastic Stack, advanced tuning to optimize and increase event ingestion performance.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}