Using Elasticsearch, Parse.ly wrote a time series backend for its real-time content analytics product. This talk will cover time-based indices, hot/warm/cold tiers, doc values, index aliases/versioning, and other techniques to run a multi-terabyte Elasticsearch cluster to perform time series at scale.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
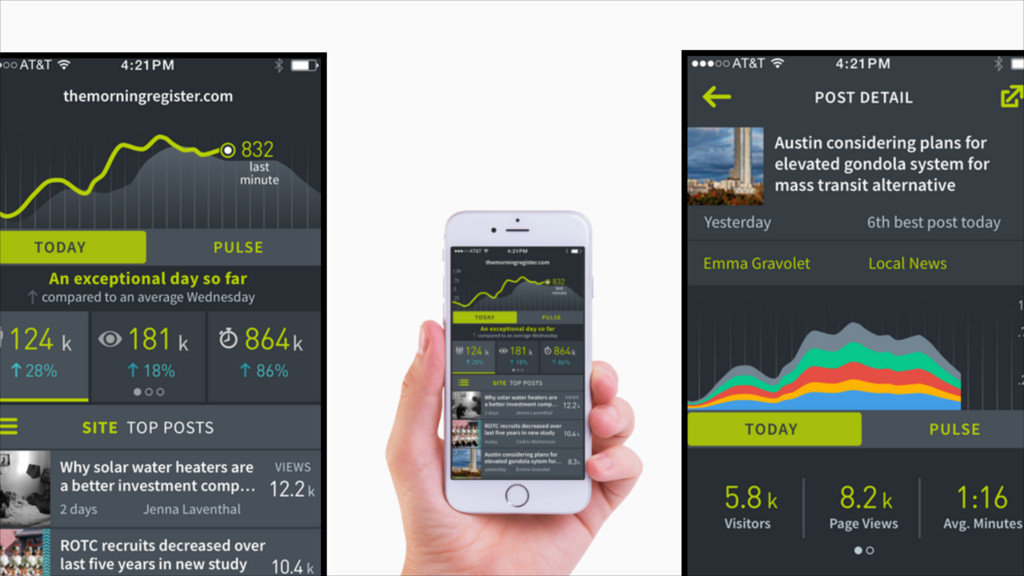{kind=link}
{kind=link}
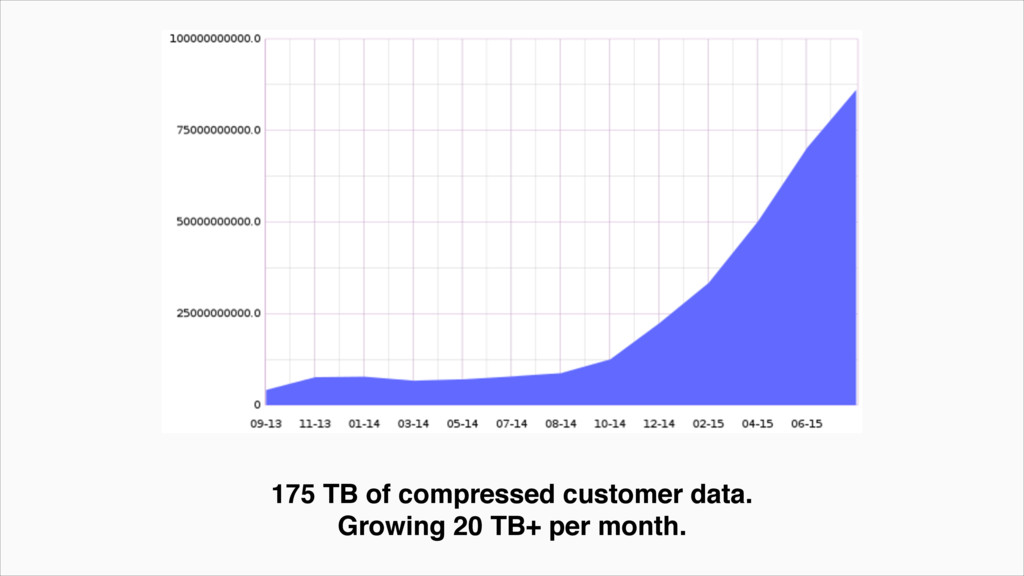{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "url": "http://arstechnica.com/12345", "ts": "2015-01-02T00:00:000Z",! "visitors": ["3f3f", "3f3g", ...millions],! !](https://files.speakerdeck.com/presentations/0b3b4aaa3d274c15bf7eabf651073c0a/slide_19.jpg){kind=link}
![{ "url": "http://arstechnica.com/12345", "ts": "2015-01-02T08:05:000Z",! "visitors": ["3f3f", "3f3g", ...hundreds],! !](https://files.speakerdeck.com/presentations/0b3b4aaa3d274c15bf7eabf651073c0a/slide_20.jpg){kind=link}
![{ "url": "http://arstechnica.com/12345", "ts": "2015-01-02T08:05:123Z",! "visitors": ["3f3f3"],! ! "metrics": {](https://files.speakerdeck.com/presentations/0b3b4aaa3d274c15bf7eabf651073c0a/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
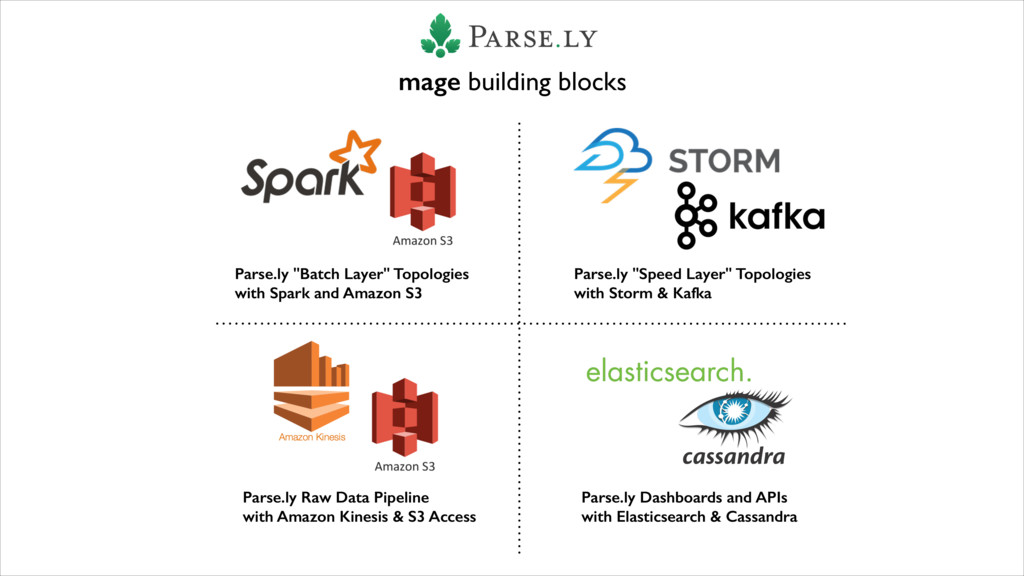{kind=link}
{kind=link}
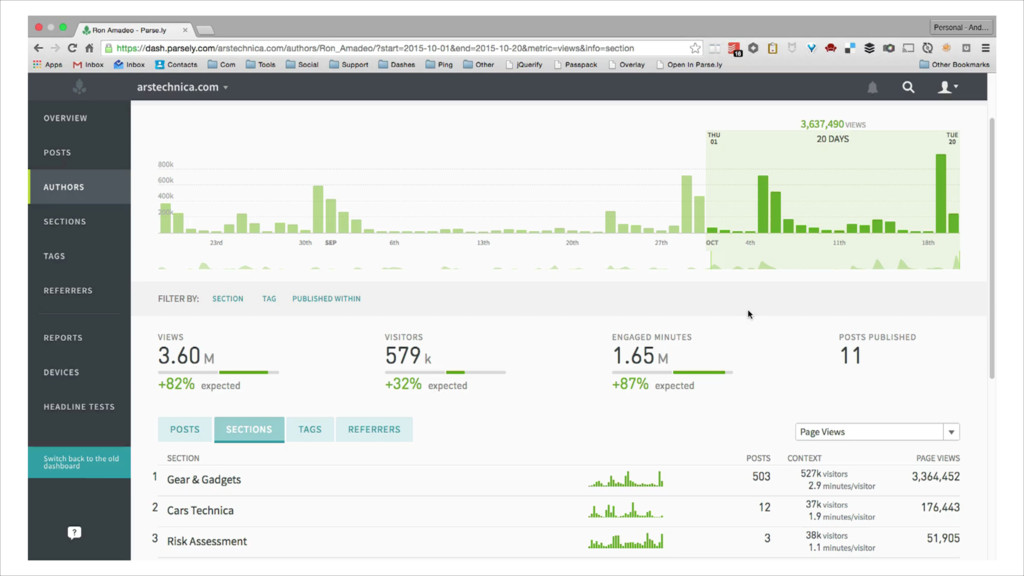{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
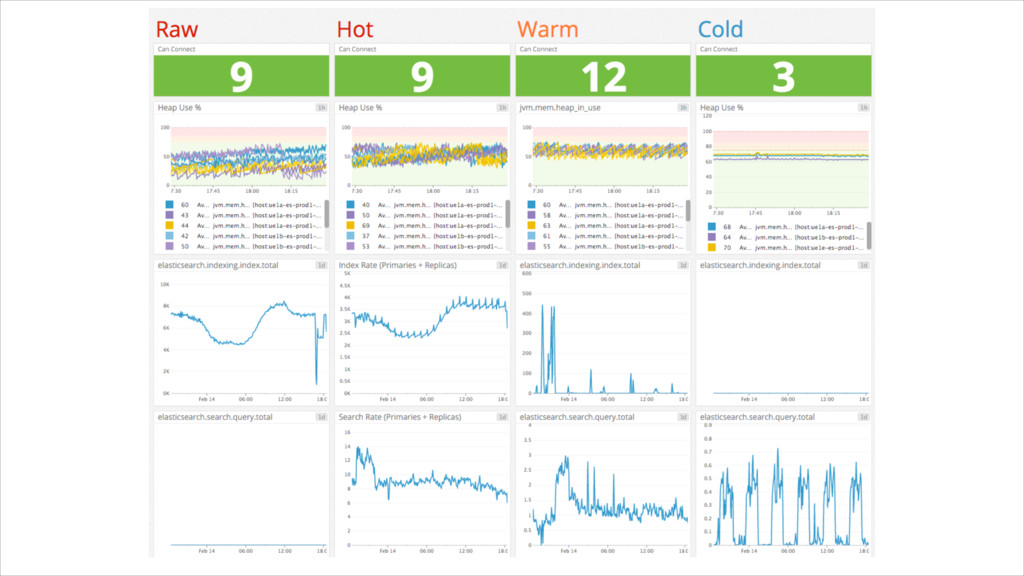{kind=link}
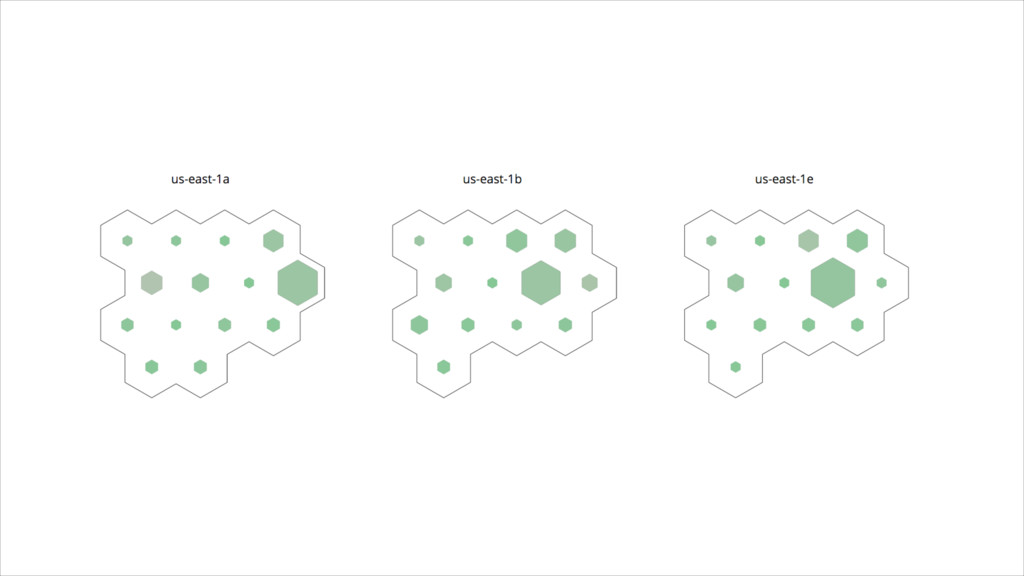{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
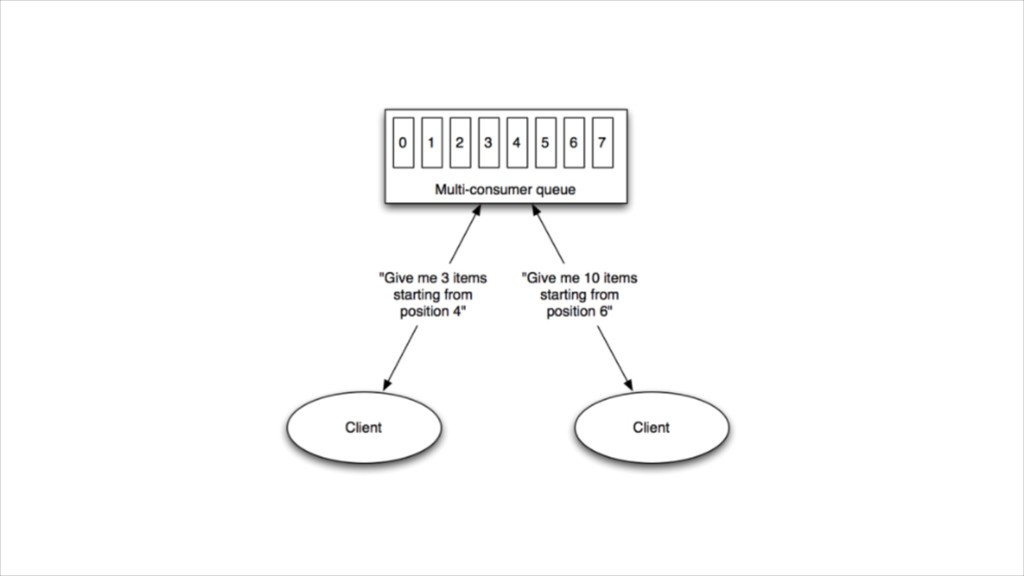{kind=link}
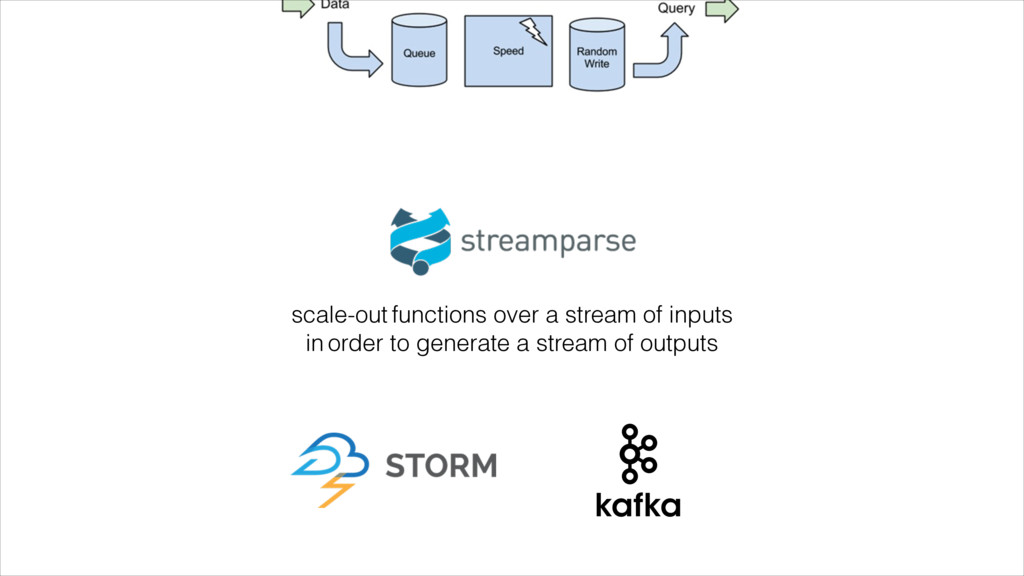{kind=link}
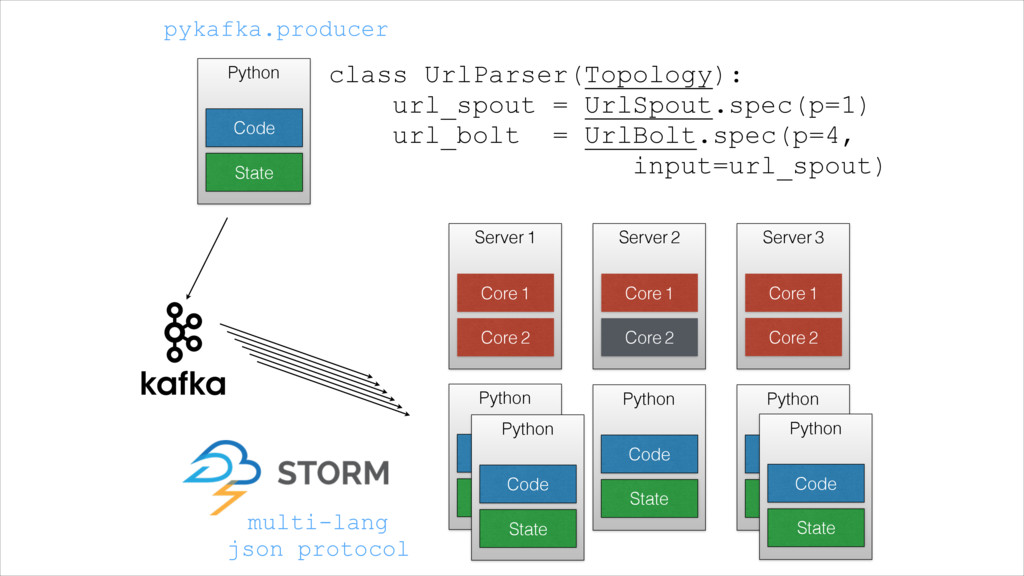{kind=link}
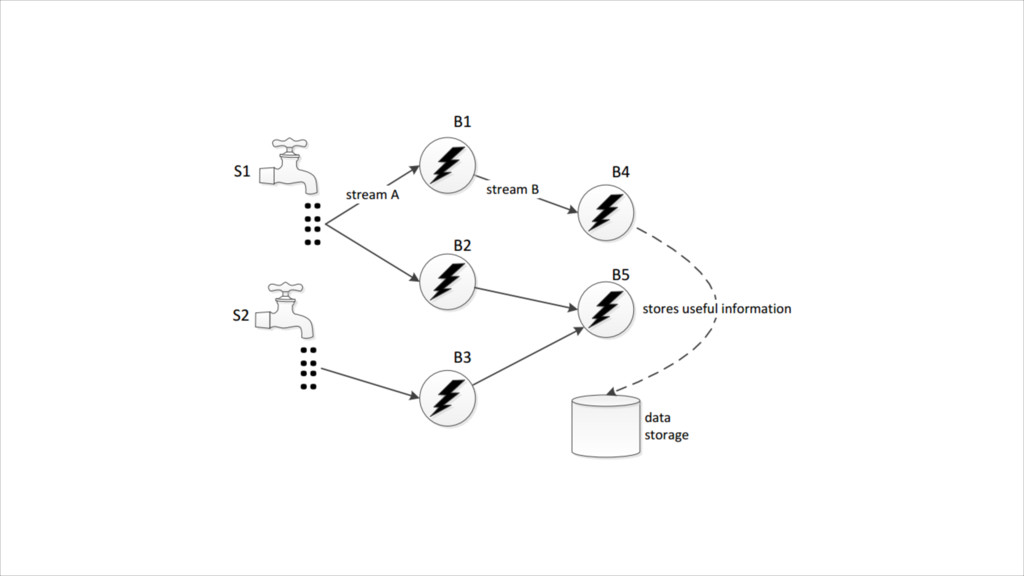{kind=link}
{kind=link}
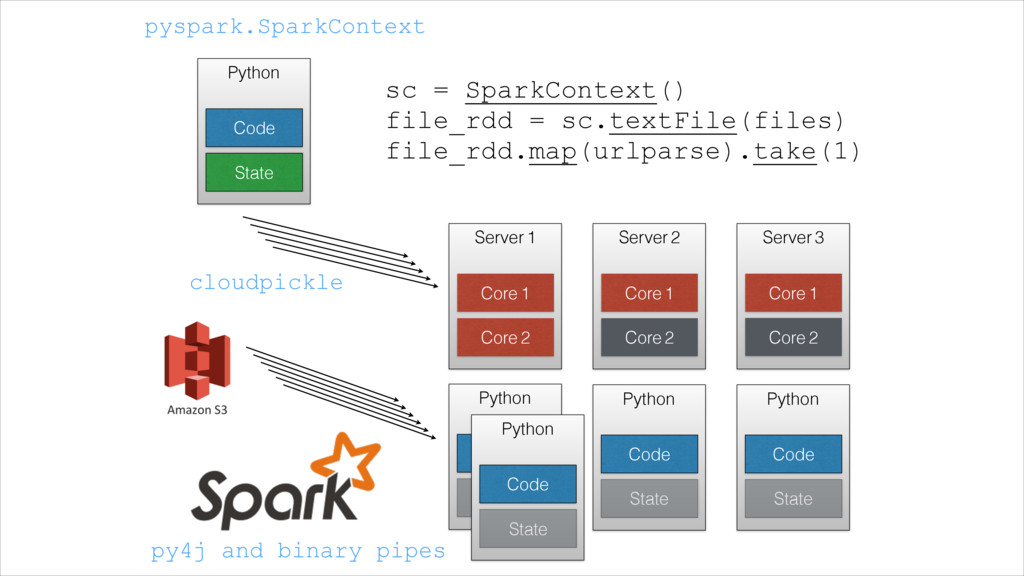{kind=link}
{kind=link}
{kind=link}
{kind=link}