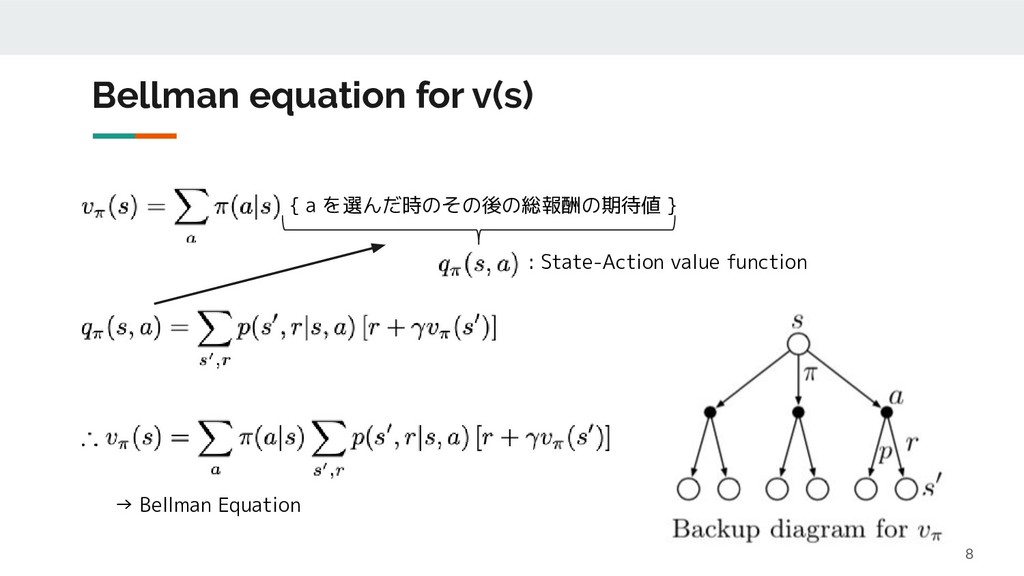
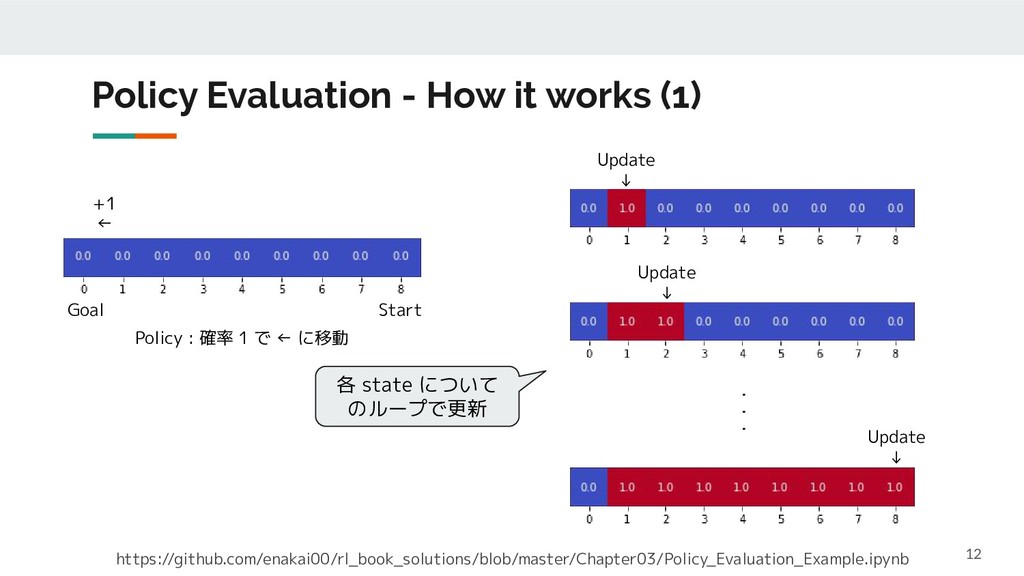
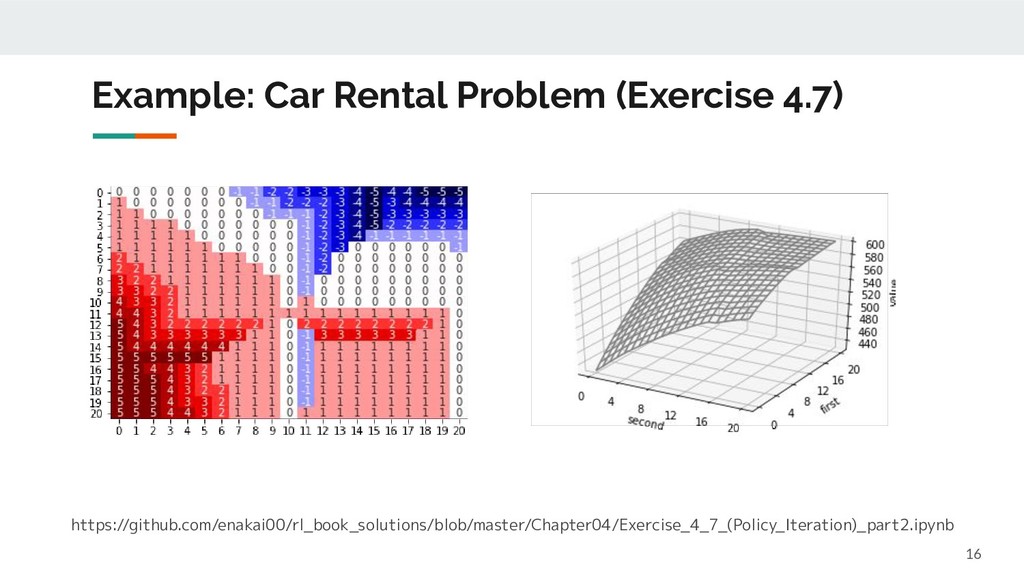
Dynamic Programming (動的計画法) ◦ 手続きは漸近的であるが、最終的には厳密解を求める手法である点に注意 ◦ 環境の Dynamics が分かっている前提の手法 • 欠点 ◦ Value Function の計算が収束するまで時間がかかる ◦ Policy Update の度に Value Function の再計算が必要 ◦ 環境の Dynamics が分からないと使えない Bootstrapping と言う Value Iteration で改善 Monte Carlo 法で対応
{kind=link}
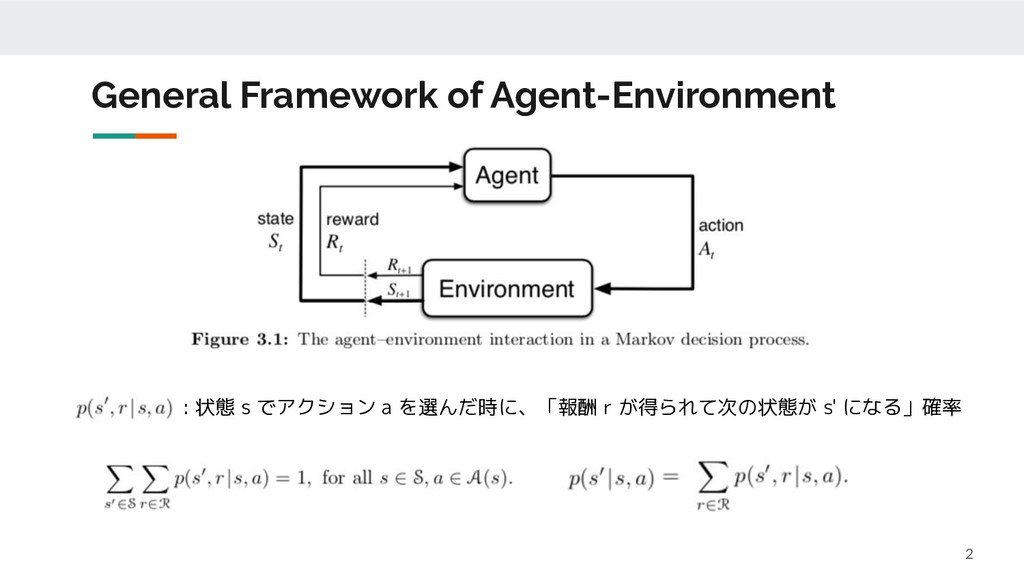{kind=link}
{kind=link}
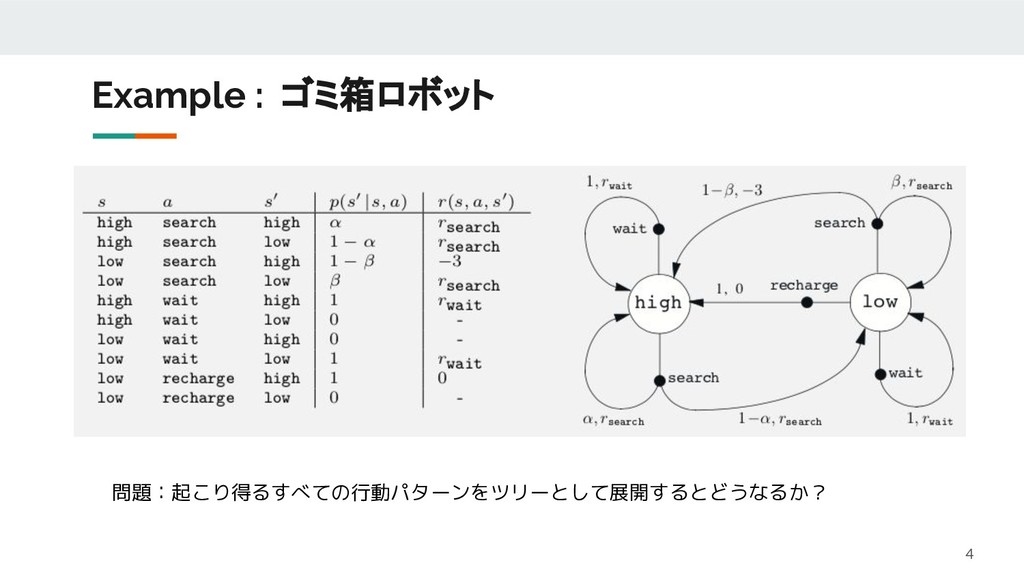{kind=link}
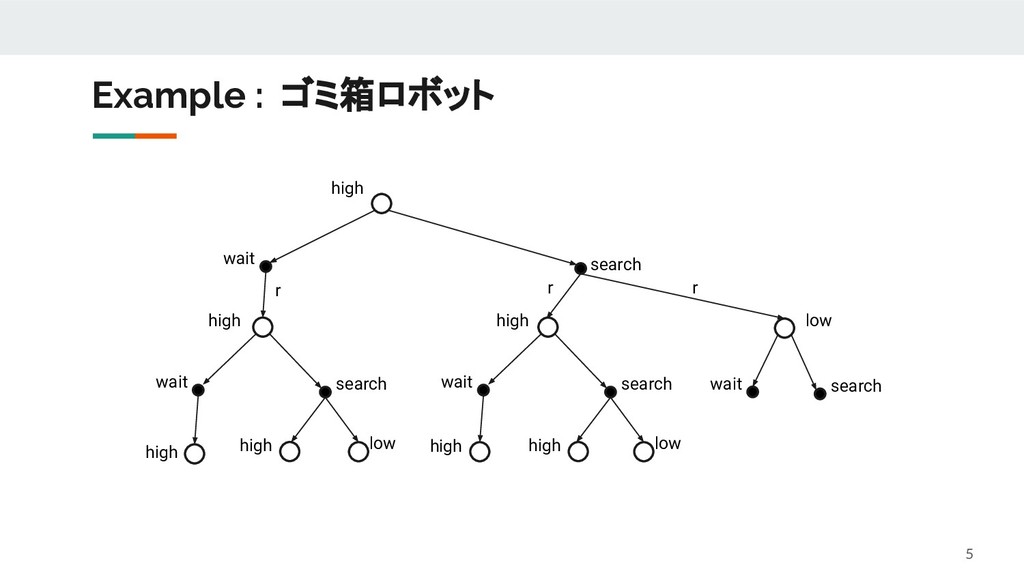{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}