Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reinforcement Learning Second edition - Notes o...
Search
Etsuji Nakai
November 30, 2019
Technology
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Reinforcement Learning Second edition - Notes on Chapter 5
Etsuji Nakai
November 30, 2019
More Decks by Etsuji Nakai
See All by Etsuji Nakai
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
800
Agent Development Kit によるエージェント開発入門
enakai00
23
9.1k
GDG Tokyo 生成 AI 論文をわいわい読む会
enakai00
1
690
Lecture course on Microservices : Part 1
enakai00
1
3.8k
Lecture course on Microservices : Part 2
enakai00
2
3.7k
Lecture course on Microservices : Part 3
enakai00
1
3.7k
Lecture course on Microservices : Part 4
enakai00
1
3.7k
JAX / Flax 入門
enakai00
1
1.5k
生成 AI の基礎 〜 サンプル実装で学ぶ基本原理
enakai00
7
4.4k
Other Decks in Technology
See All in Technology
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.1k
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
130
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
290
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
660
カードゲーム作りが教えてくれた プロダクトオーナーシップ
moritamasami
0
110
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
480
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
180
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
210
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
290
Featured
See All Featured
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
340
Faster Mobile Websites
deanohume
310
32k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
310
エンジニアに許された特別な時間の終わり
watany
108
250k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
380
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Transcript
Reinforcement Learning Second edition - Notes on Chapter 5 Etsuji
Nakai (@enakai00)
環境のモデルが不明な場合 2 状態遷移のルール、すなわち、 が未知の場合、Dynamic Programming で Value Function を計算することはできない。 状態
s でアクション a を 取った時の結果 (s', r) を シミュレーションしている
• ポリシー π の下に、現実の環境で何度もプレイを繰り返して、データを収集する。1回分の プレイのデータを「1エピソード」と数える。 • エピソードに含まれるそれぞれの状態 s について、それ以降に得られる Reward
の合計を の「サンプル」と考える。 • 多数のエピソードを収集すると、同じ状態 s が何度も登場するので、それらサンプル全体の 平均値を の近似値とする。 ◦ First-visit MC:1つのエピソードに同じ状態 s が複数回登場した場合は、最初の状態 からの寄与(それ以降に得られる Reward の合計)のみを平均値の計算に含める。 ◦ Every-visit MC:1つのエピソードに同じ状態 s が複数回登場した場合は、それぞれ の状態からの寄与をすべて平均値の計算に含める。 Monte Carlo Prediction 3
Monte Carlo Prediction 4 この条件を除くと Every-visit MC になる。
「Bootstrapping」の意味について 5 • Dynamic Programming の場合、次の状態 s' の Value の近似値
V(s') を用いて、状態 s の Value V(s) の近似値を改善するというステップを繰り返す。 • これは、他の状態の近似値を用いながら、「近似の精度を互いに向上していく」手続きと言 える。一般に、このような手法を Bootstrapping と呼ぶ。 Bootstrapping
Monte Carlo Prediction for State-action value 6 • State-action value
q π (s, a) もほぼ同じ考え方で計算できる。
ポリシーの改善方法(Policy Iteration の復習) 7 ※ ここでは、 は既知とする。 ・任意のポリシー を1つ選択する ・Value function
を(何らかの方法で)計算する ・Action-Value function が決まる ・Greedy ポリシー ( が最大の a を確率 1 で選択する) この時、任意の s について が成り立つ。 つまり、π' は、π よりも優れたポリシーと言える。この改善処理を繰り返す。 MCの場合は、q π (s, a) を 求めておくことが必要
Monte Carlo Control(MC でのポリシー改善方法) 8 • 素朴に考えると、次の2つの方法が思いつく。 ◦ Policy Iteration:ポリシー
π の下に「十分な数のエピソード」をサンプリングして、 「十分に正確」と信じられる q π (s, a) を決定。その後、q π (s, a) に基づく Greedy Policy でポリシーを改善する。 ◦ Value Iteration:新しいエピソードを1つ追加して q(s, a) を更新した直後に、状態 s に対応するポリシーを q(s, a) に基づく Greedy Policy で改善する。 • 問題点:Greedy Policy を採用すると、その Policy では到達しない状態のサンプルが得られ なくなり、q(s, a) の近似精度がものすごく悪くなる。
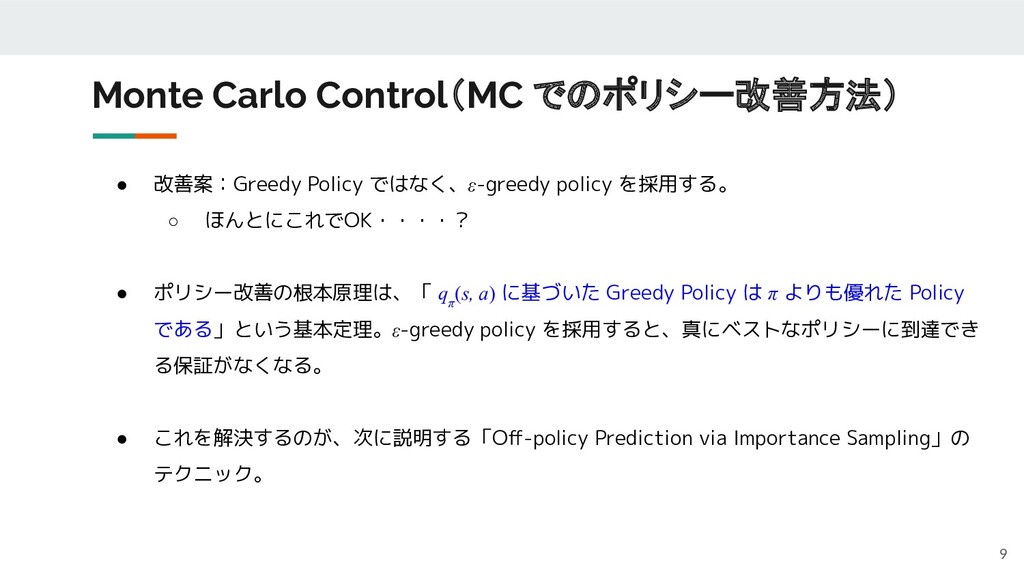
Monte Carlo Control(MC でのポリシー改善方法) 9 • 改善案:Greedy Policy ではなく、ε-greedy policy
を採用する。 ◦ ほんとにこれでOK・・・・? • ポリシー改善の根本原理は、「 q π (s, a) に基づいた Greedy Policy は π よりも優れた Policy である」という基本定理。ε-greedy policy を採用すると、真にベストなポリシーに到達でき る保証がなくなる。 • これを解決するのが、次に説明する「Off-policy Prediction via Importance Sampling」の テクニック。
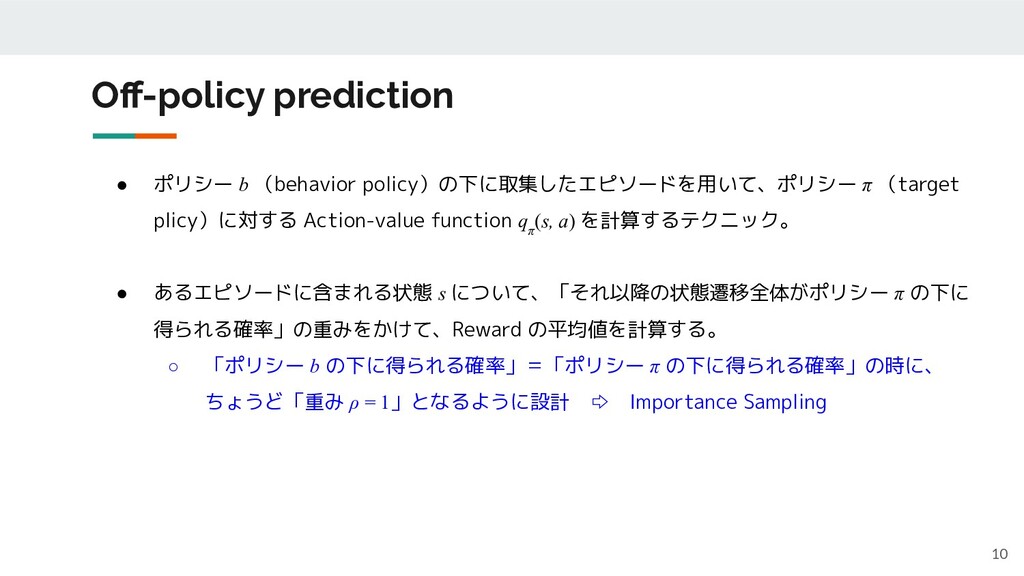
Off-policy prediction 10 • ポリシー b (behavior policy)の下に取集したエピソードを用いて、ポリシー π (target
plicy)に対する Action-value function q π (s, a) を計算するテクニック。 • あるエピソードに含まれる状態 s について、「それ以降の状態遷移全体がポリシー π の下に 得られる確率」の重みをかけて、Reward の平均値を計算する。 ◦ 「ポリシー b の下に得られる確率」=「ポリシー π の下に得られる確率」の時に、 ちょうど「重み ρ = 1」となるように設計 ⇨ Importance Sampling
Importance Sampling 11 • ポリシー π の下に状態遷移 が発生する確率 • ポリシー b
についても同様なので、確率の比率(平均値を計算する時の重み)は、
Importance Sampling 12 • 重み付きの平均値を計算する際、分母を「足したサンプルの個数」にするか、「重みの合 計」にするかの2つの方法がある。 • 無限個のサンプルを取得する極限では、どちらも正しい Value Function
に収束するが、収 束前の振る舞いが異なる。(本章では、以降は、Weighted を採用する。) Ordinary Importance Sampling : Unbiased, High variance Weighted Importance Sampling : Biased, Low variance
Incremental Implementation 13 • Weighted Importance Sampling による Value Function
の近似値(n - 1 個のサンプルを取 得した時点) • これは次の逐次計算と同等 • Action-value Function も同様に計算可能。下記のシーケンスに対して、例えば、 以降の Reward の合計を 以降のアクションのシーケンスが発生する確率の重みで平均したもの を とする。
Off-policy MC prediction 14 • ポリシー b (behavior policy)の下に取集したエピソードを用いて、ポリシー π
に対する Value function V(s) を計算する例
Off-policy MC control with ε - greedy 15 • ε
-greedy policy の下に取集したエピソードを用いて、greedy ポリシー π に対する Action-value function q π (s, a) を計算する例( に注意)。 Target policy π が Greedy(非確率的) なので、π と異なるアクションがあると、 それ以前を含むパスの確率は 0 になる。
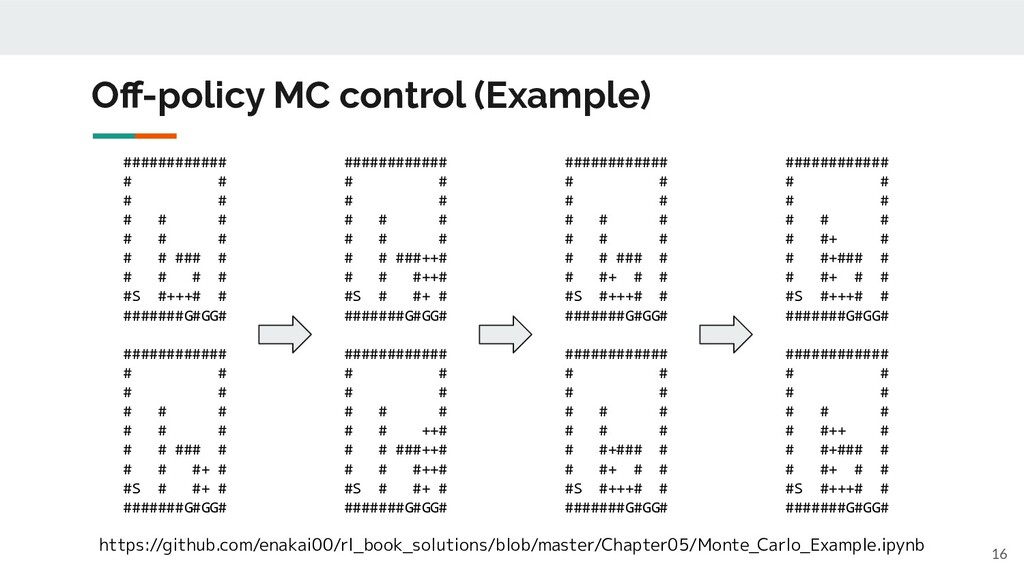
Off-policy MC control (Example) 16 https://github.com/enakai00/rl_book_solutions/blob/master/Chapter05/Monte_Carlo_Example.ipynb ############ # # #
# # # # # # # # # ### # # #+ # # #S #+++# # #######G#GG# ############ # # # # # # # # # # # #+### # # #+ # # #S #+++# # #######G#GG# ############ # # # # # # # # # # # # ### # # # # # #S #+++# # #######G#GG# ############ # # # # # # # # # # # # ### # # # #+ # #S # #+ # #######G#GG# ############ # # # # # # # # # # # # ###++# # # #++# #S # #+ # #######G#GG# ############ # # # # # # # # # ++# # # ###++# # # #++# #S # #+ # #######G#GG# ############ # # # # # # # # #+ # # #+### # # #+ # # #S #+++# # #######G#GG# ############ # # # # # # # # #++ # # #+### # # #+ # # #S #+++# # #######G#GG#
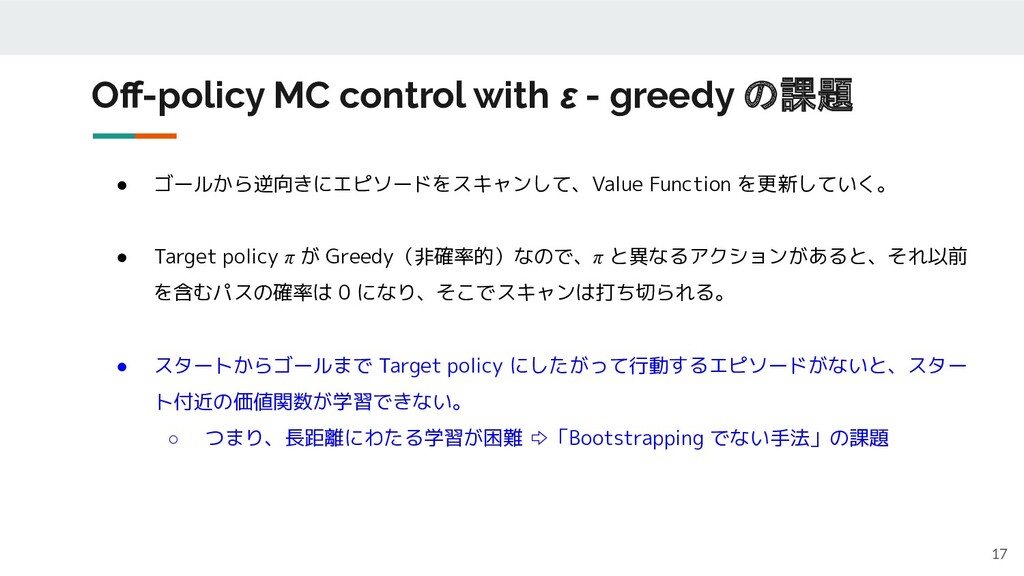
Off-policy MC control with ε - greedy の課題 17 •
ゴールから逆向きにエピソードをスキャンして、Value Function を更新していく。 • Target policy π が Greedy(非確率的)なので、π と異なるアクションがあると、それ以前 を含むパスの確率は 0 になり、そこでスキャンは打ち切られる。 • スタートからゴールまで Target policy にしたがって行動するエピソードがないと、スター ト付近の価値関数が学習できない。 ◦ つまり、長距離にわたる学習が困難 ⇨「Bootstrapping でない手法」の課題
Exercise 5.12 (Racetrack) 18 https://github.com/enakai00/rl_book_solutions/blob/master/Chapter05/Exercise_5_12.ipynb
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}