Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reinforcement Learning Second edition - Notes o...
Search
Etsuji Nakai
February 10, 2020
Technology
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Reinforcement Learning Second edition - Notes on DQN
Etsuji Nakai
February 10, 2020
More Decks by Etsuji Nakai
See All by Etsuji Nakai
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
800
Agent Development Kit によるエージェント開発入門
enakai00
23
9.1k
GDG Tokyo 生成 AI 論文をわいわい読む会
enakai00
1
690
Lecture course on Microservices : Part 1
enakai00
1
3.8k
Lecture course on Microservices : Part 2
enakai00
2
3.7k
Lecture course on Microservices : Part 3
enakai00
1
3.7k
Lecture course on Microservices : Part 4
enakai00
1
3.7k
JAX / Flax 入門
enakai00
1
1.5k
生成 AI の基礎 〜 サンプル実装で学ぶ基本原理
enakai00
7
4.4k
Other Decks in Technology
See All in Technology
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3.3k
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
0
110
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
3
4.1k
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
340
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
260
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
140
シンガポールで登壇してきます
yama3133
0
240
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
410
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
190
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
180
Featured
See All Featured
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Believing is Seeing
oripsolob
1
170
Product Roadmaps are Hard
iamctodd
55
12k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Making the Leap to Tech Lead
cromwellryan
135
10k
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
Prompt Engineering for Job Search
mfonobong
0
380
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Transcript
Reinforcement Learning Second edition - Notes on DQN Etsuji Nakai
(@enakai00)
Functional Approximation 2 • これまでは、State Value Function v(s) 、もしくは、Action-State Value
Function q(s, a) の値をすべての状態 s について個別に記録(Tabular Method) • 状態数が爆発的に増加する問題では、メモリーの不足、計算時間の増加といった問題が発生 • 少数のパラメーター w を持った関数で v(s) 、もしくは、 q(s, a) を表現して、w をチューニン グすることで、近似的に計算する
Functional Approximation 3 • 近似関数が正しい価値関数の振る舞いとかけ離れていると、計算が収束しない可能性がある • 例:2つの状態 A, B があり相互の遷移に伴う報酬は
0。つまり、v(A) = v(B) = 0 が正解。 ◦ v(A) = w, v(B) = 2w と線形近似すると、A のベルマン方程式は、w を増加させようと して、B のベルマン方程式は、w を減少させようとするので、w は振動を続ける。 • パラメーターが発散するような例を作ることも可能
Functional Approximation 4
DQN 5 • 近似関数として、ニューラルネットワークを使用する(表現力の高い関数を用いることで、 前述の問題を避ける。) • Action - State Value
Function を下記の「方針」でアップデートする(Q-Learning) ◦ Off-policy メソッドなので、エピソードの収集は任意のポリシーで実施可能
DQN 6 • 実際の学習方法としては、エピソードに含まれる の4つ組を大量にストック しておいて、下記の誤差関数を最小化するようにバッチで学習する。(勾配降下法) • エピソードの収集は、たとえば、現在の Q(S, A) に基づいた
ε-Greedy を用いる。
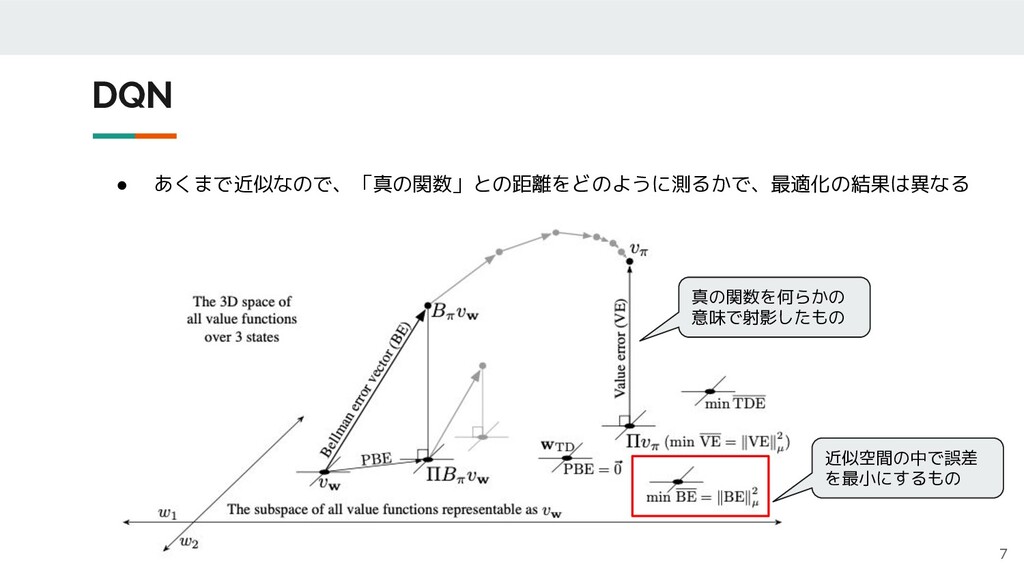
DQN 7 • あくまで近似なので、「真の関数」との距離をどのように測るかで、最適化の結果は異なる 真の関数を何らかの 意味で射影したもの 近似空間の中で誤差 を最小にするもの
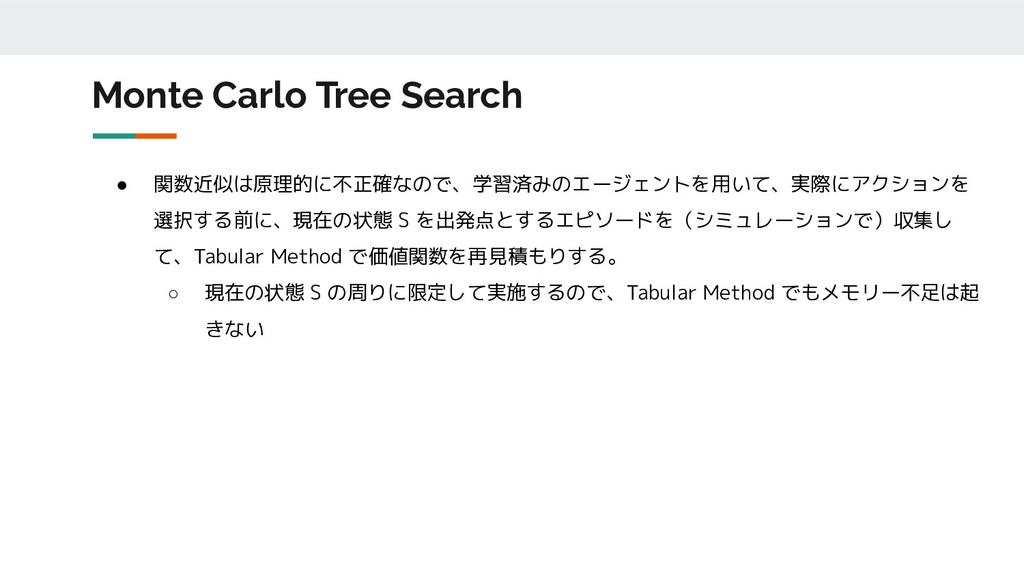
Monte Carlo Tree Search • 関数近似は原理的に不正確なので、学習済みのエージェントを用いて、実際にアクションを 選択する前に、現在の状態 S を出発点とするエピソードを(シミュレーションで)収集し て、Tabular
Method で価値関数を再見積もりする。 ◦ 現在の状態 S の周りに限定して実施するので、Tabular Method でもメモリー不足は起 きない
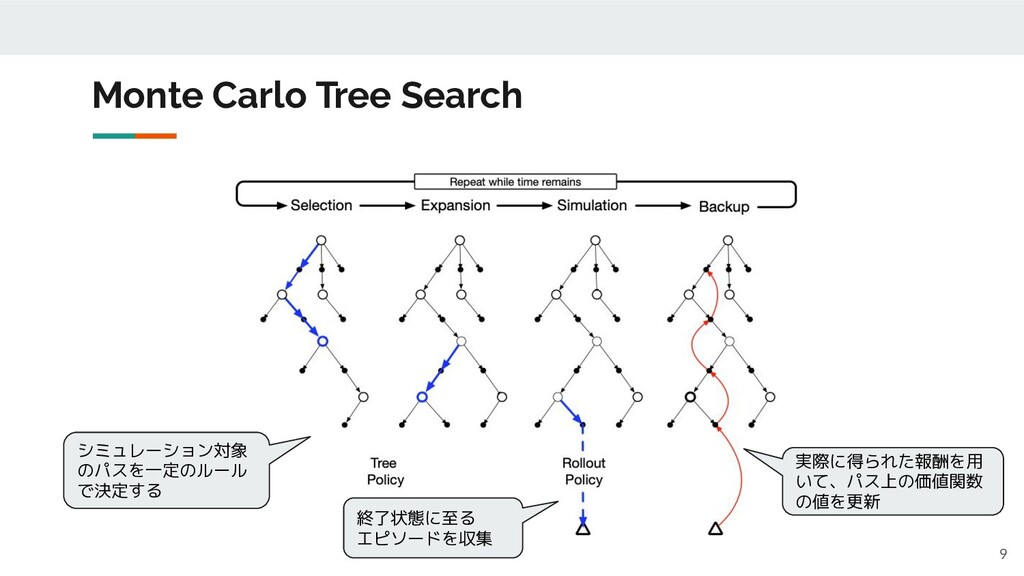
9 Monte Carlo Tree Search シミュレーション対象 のパスを一定のルール で決定する 終了状態に至る エピソードを収集
実際に得られた報酬を用 いて、パス上の価値関数 の値を更新
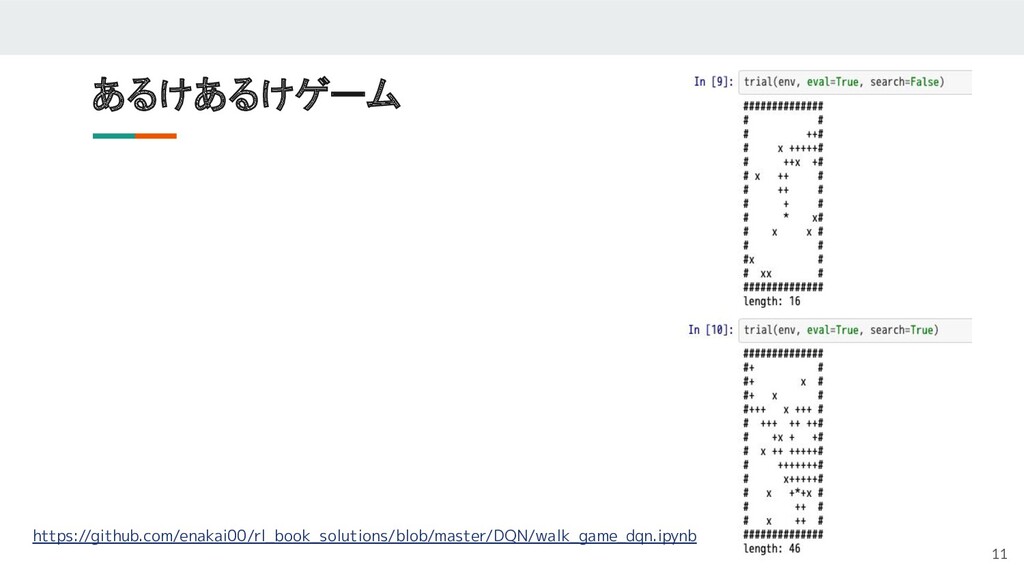
10 あるけあるけゲーム
11 あるけあるけゲーム https://github.com/enakai00/rl_book_solutions/blob/master/DQN/walk_game_dqn.ipynb
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}