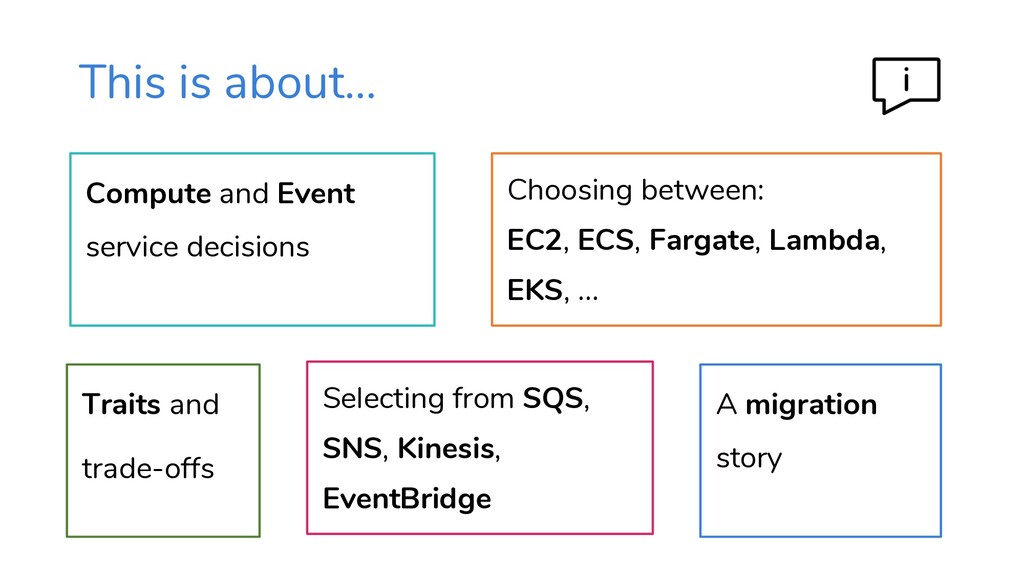
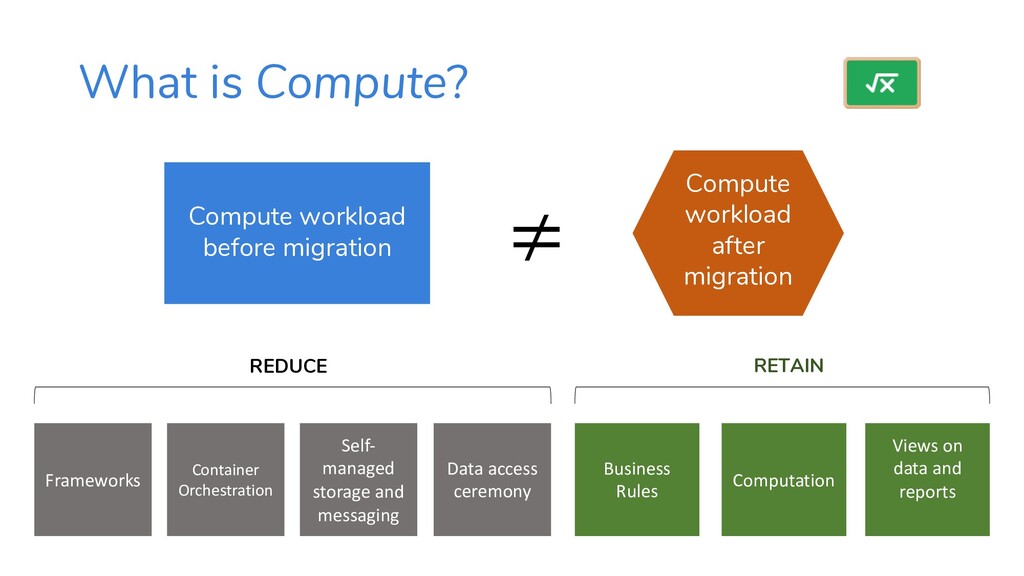
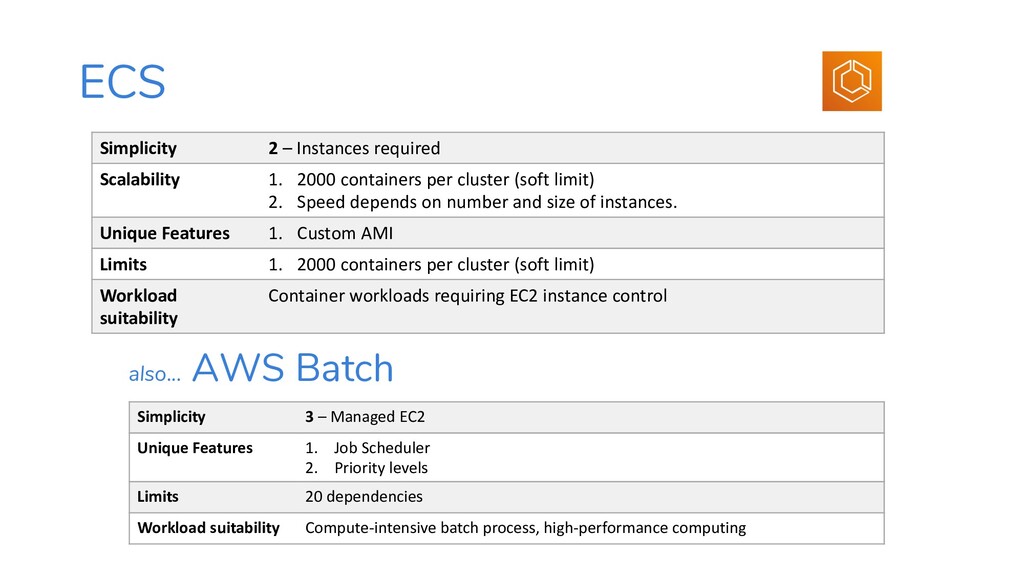
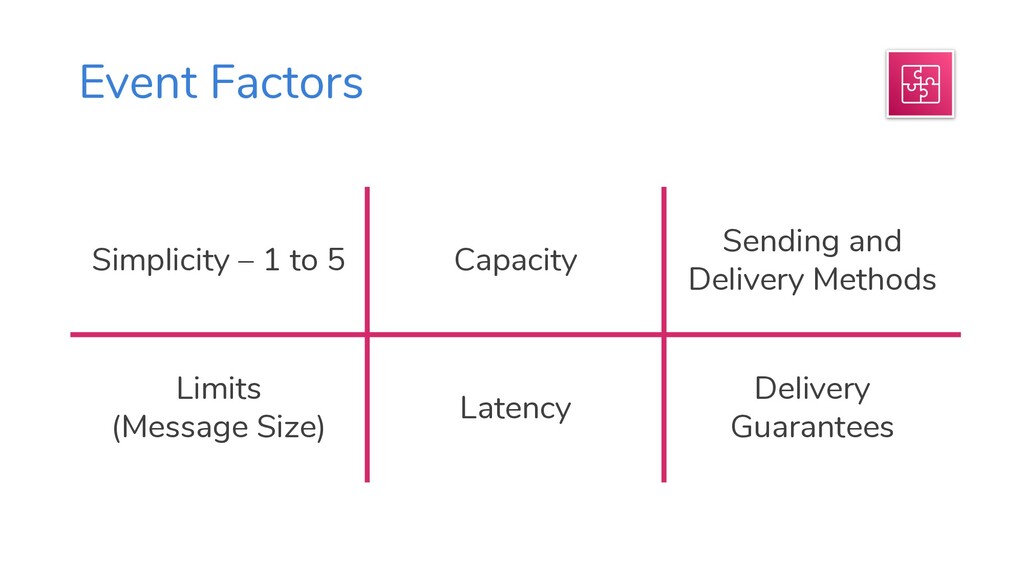
A cheat sheat-style presentation with tactics and data to help you choose services when migrating workloads to AWS. This presentation helps guide you towards the simplest, most-effective, most-serverless outcome.
Presented at the AWS Summer School organised by AWS User Groups Dublin on July 28th 2020.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
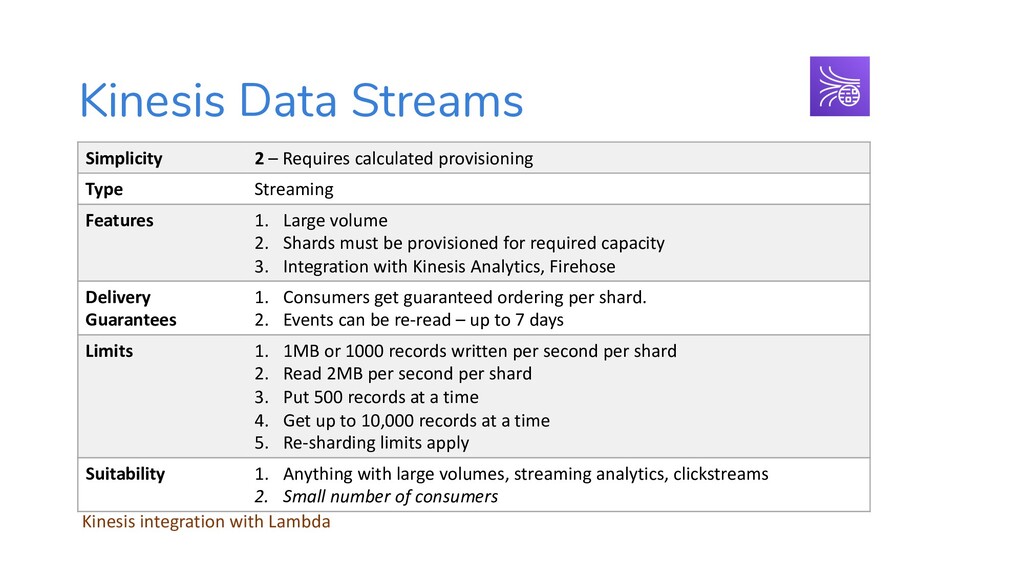{kind=link}
{kind=link}
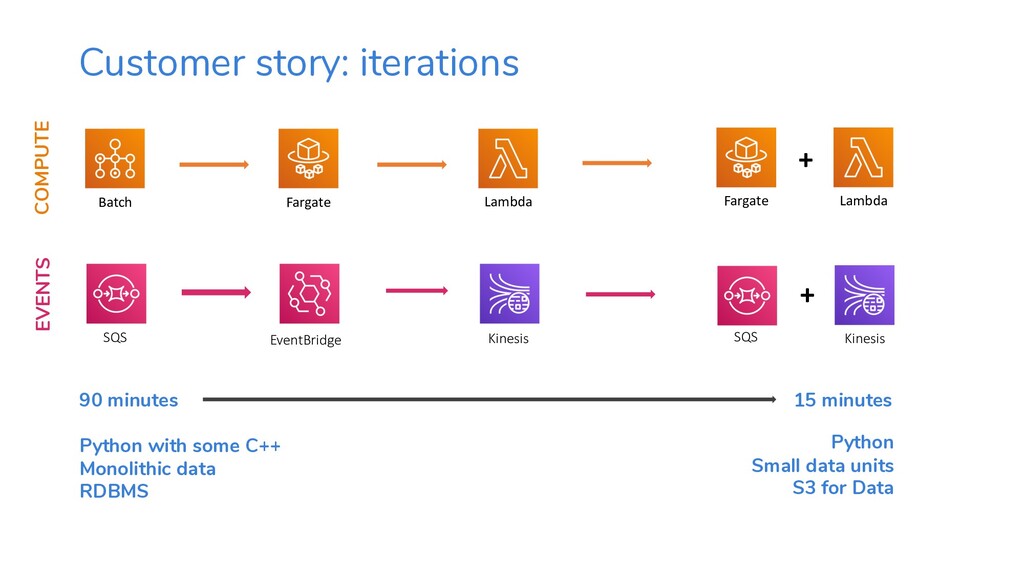{kind=link}
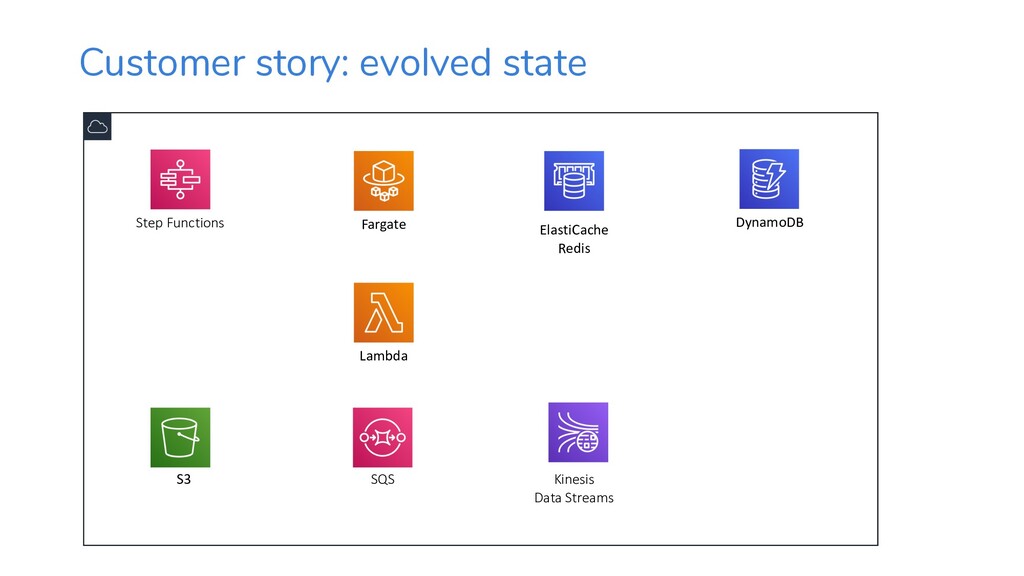{kind=link}
{kind=link}
![Thank You [email protected] @eoins fourtheorem.com/careers](https://files.speakerdeck.com/presentations/99b0289445174886b9fb71b3f8519e2e/slide_22.jpg){kind=link}