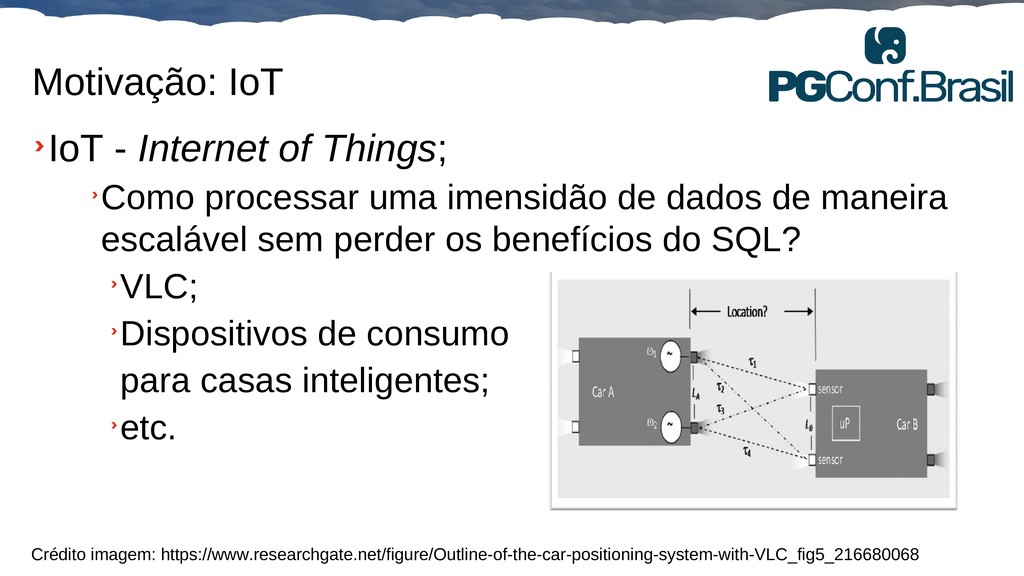
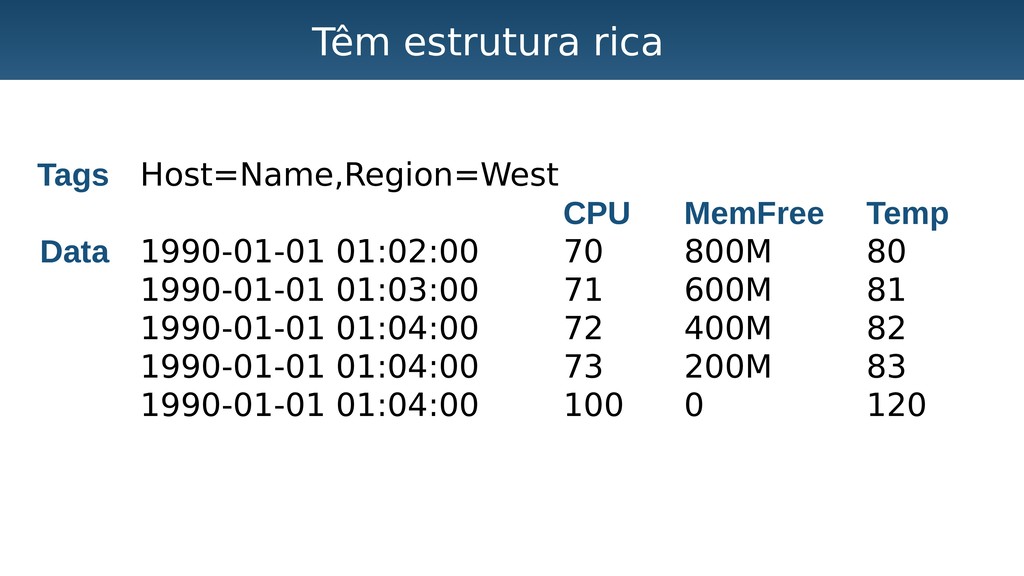
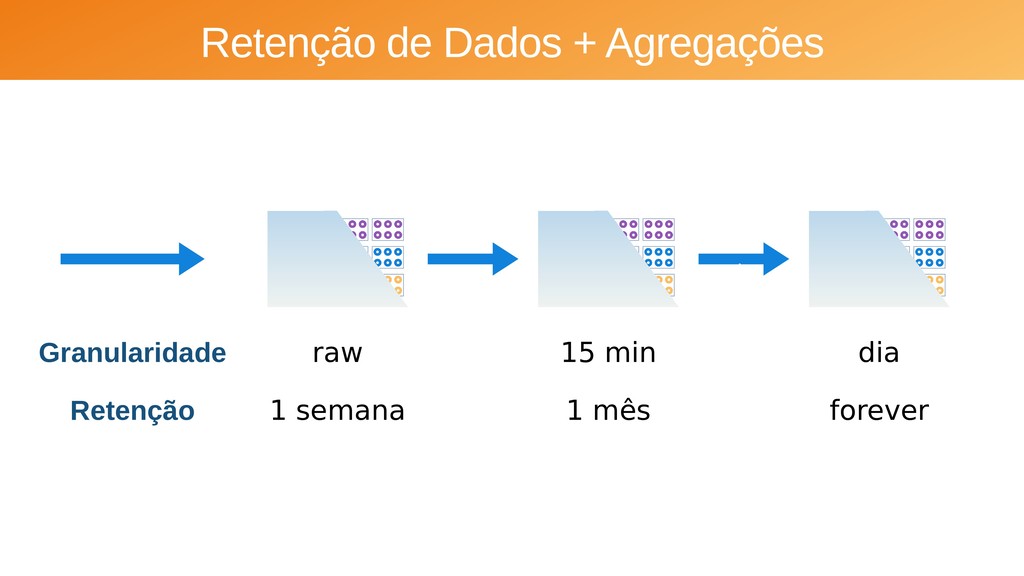
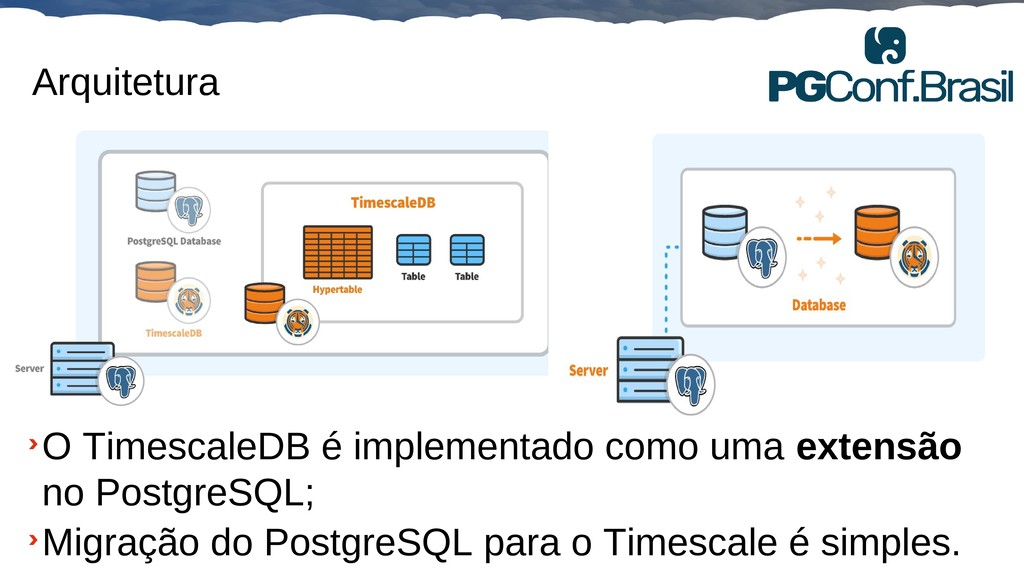
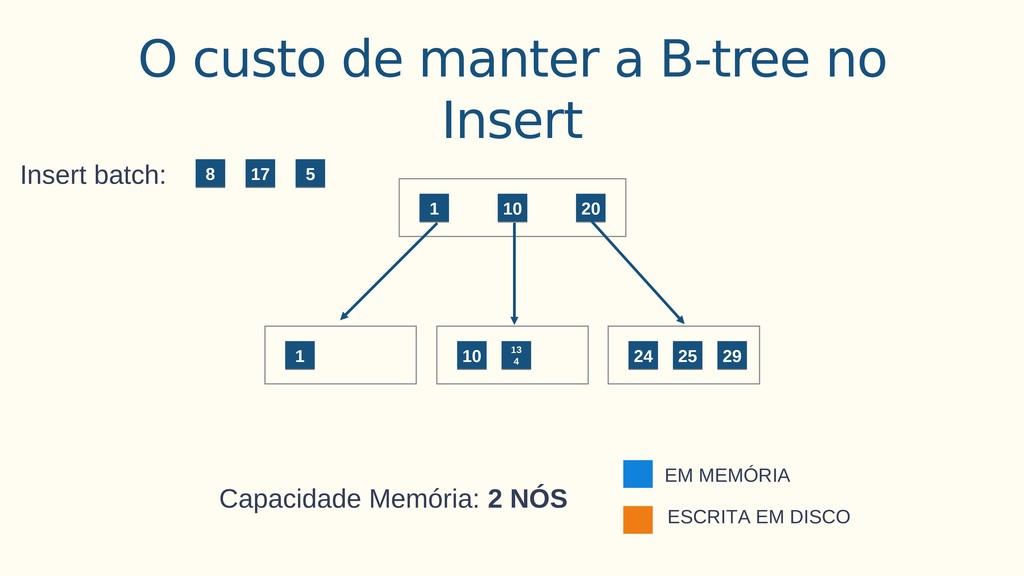
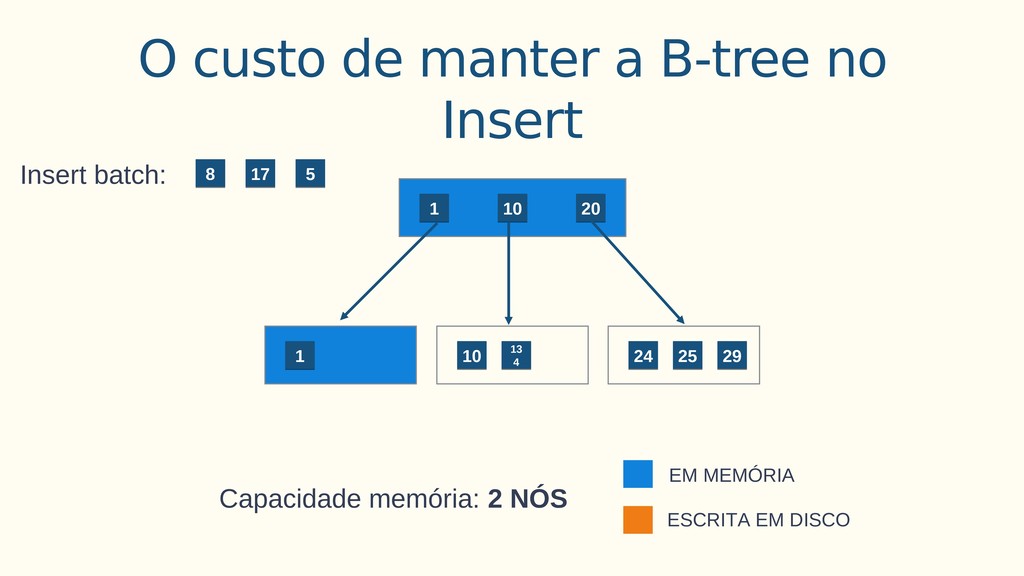
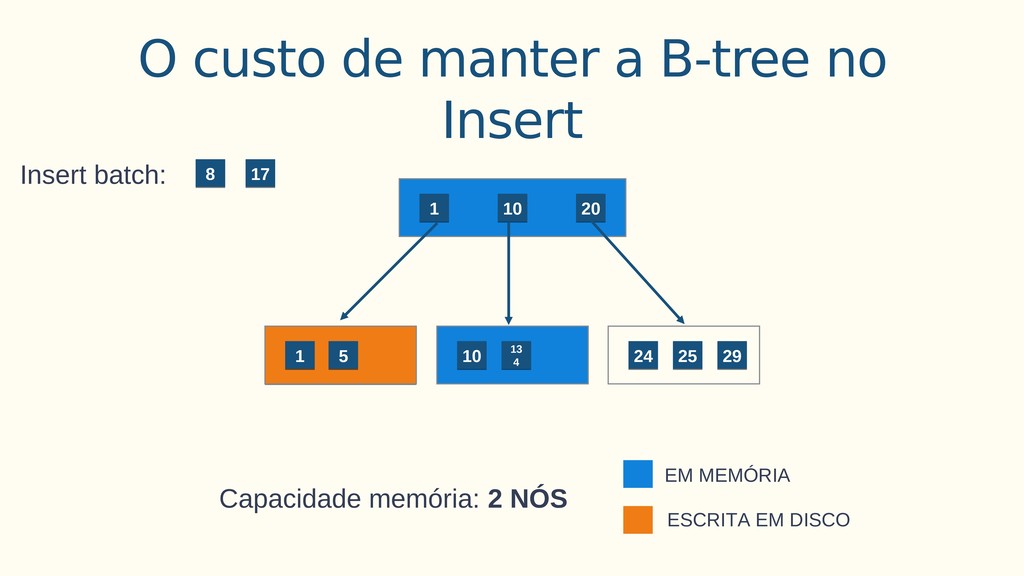
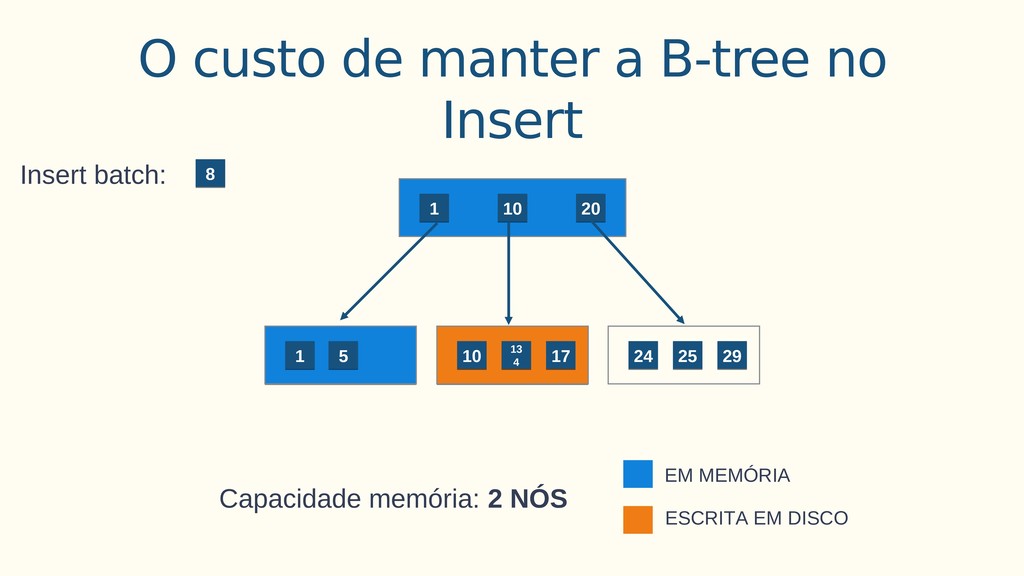
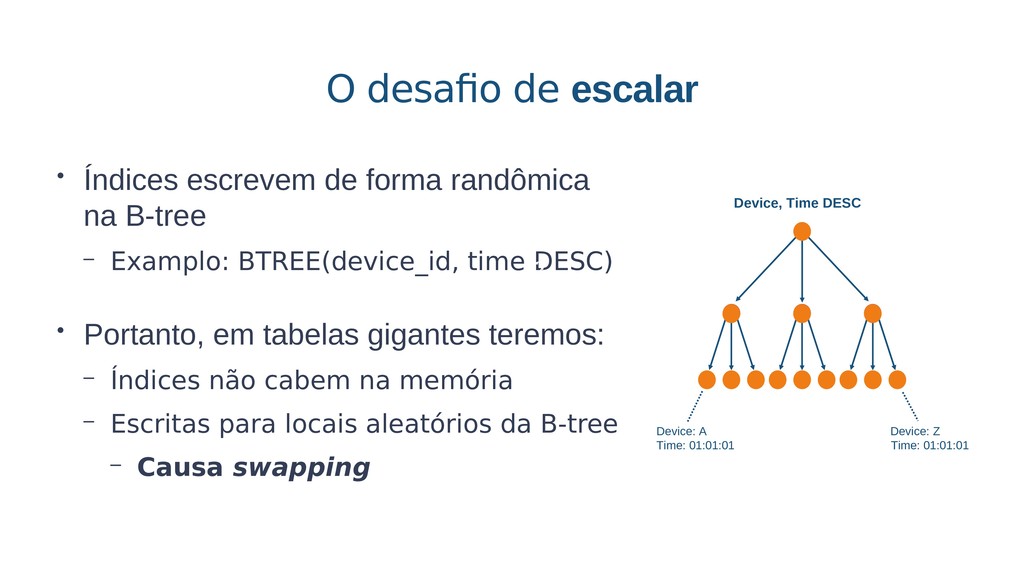
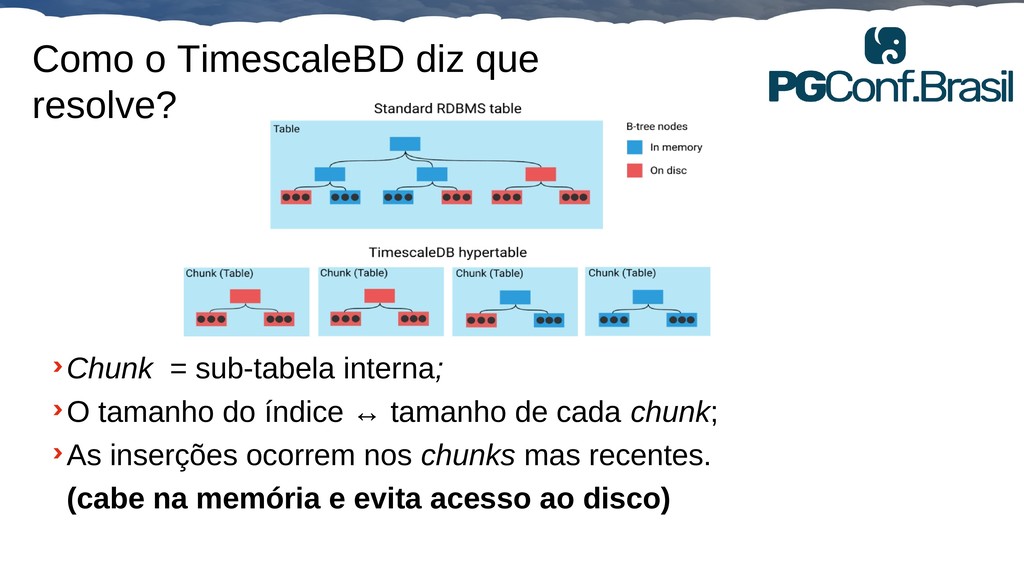
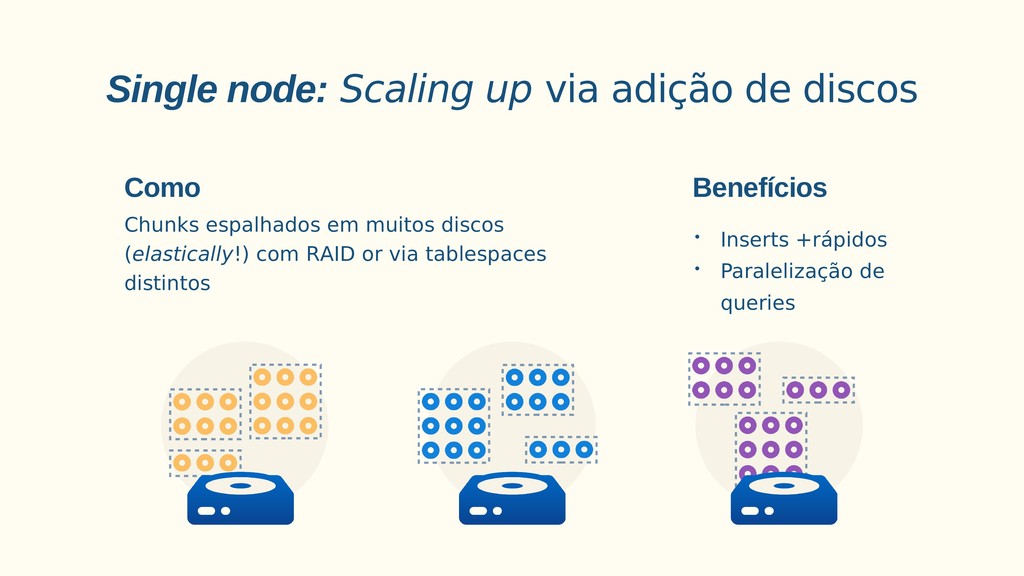
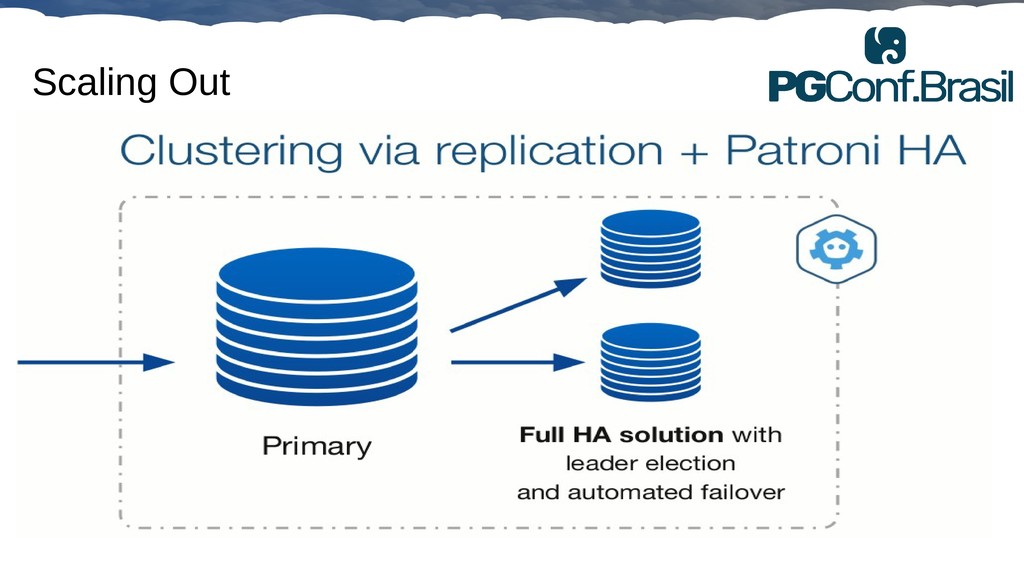
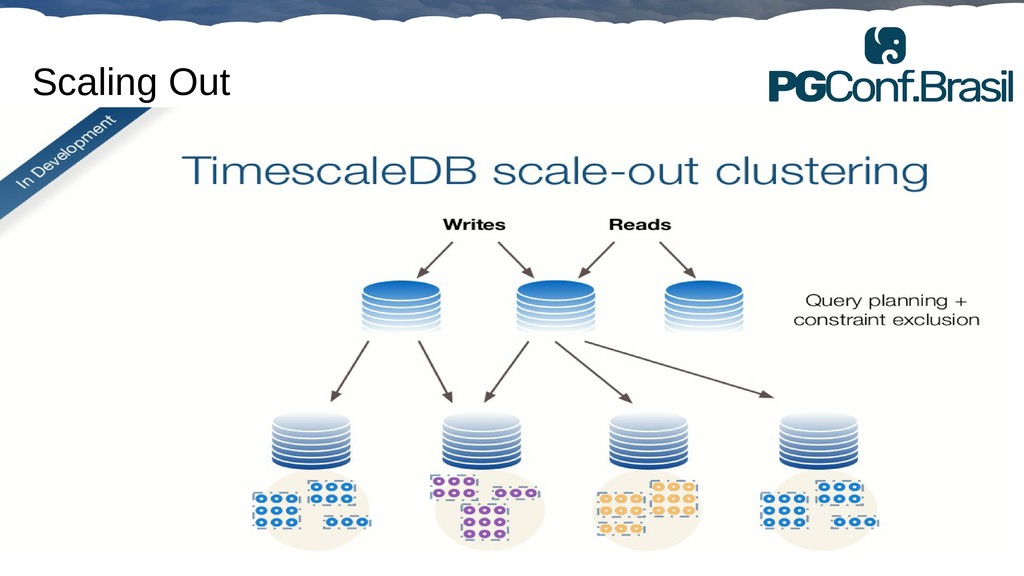
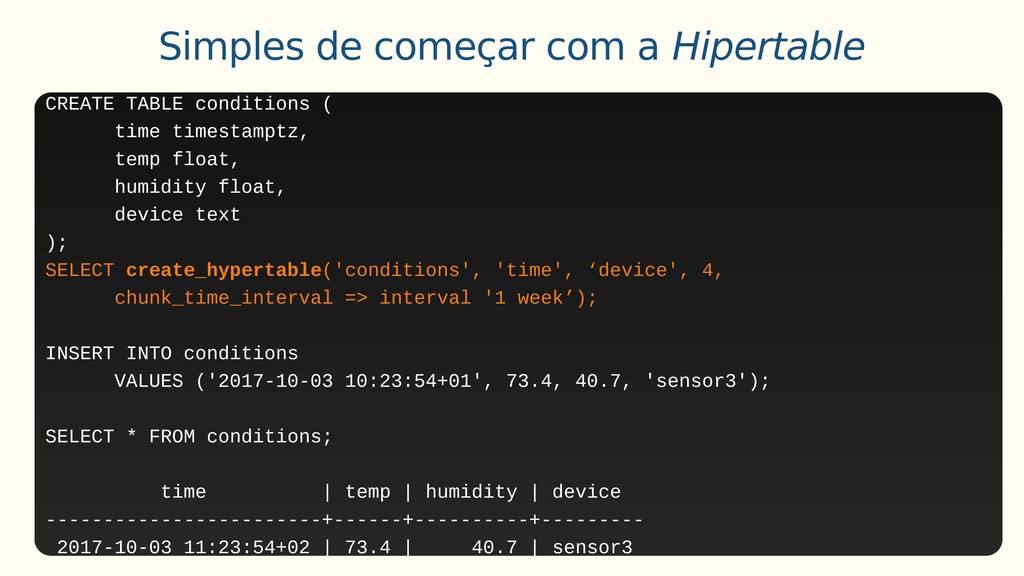
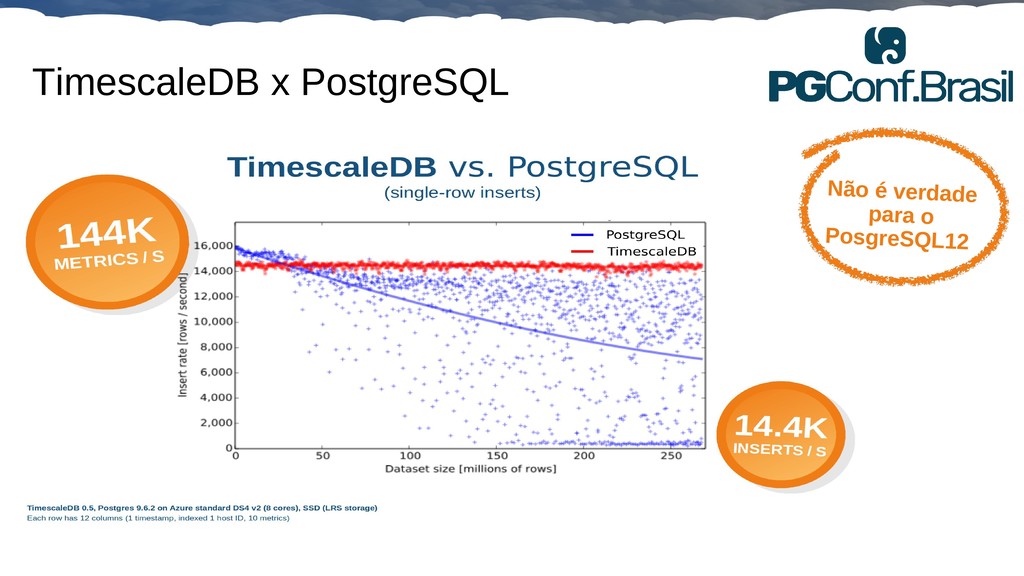
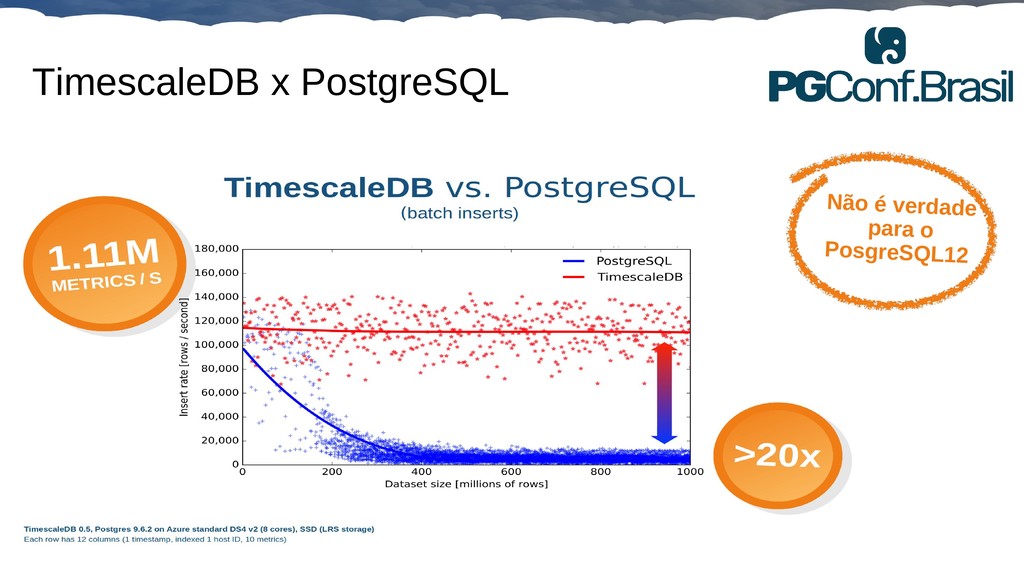
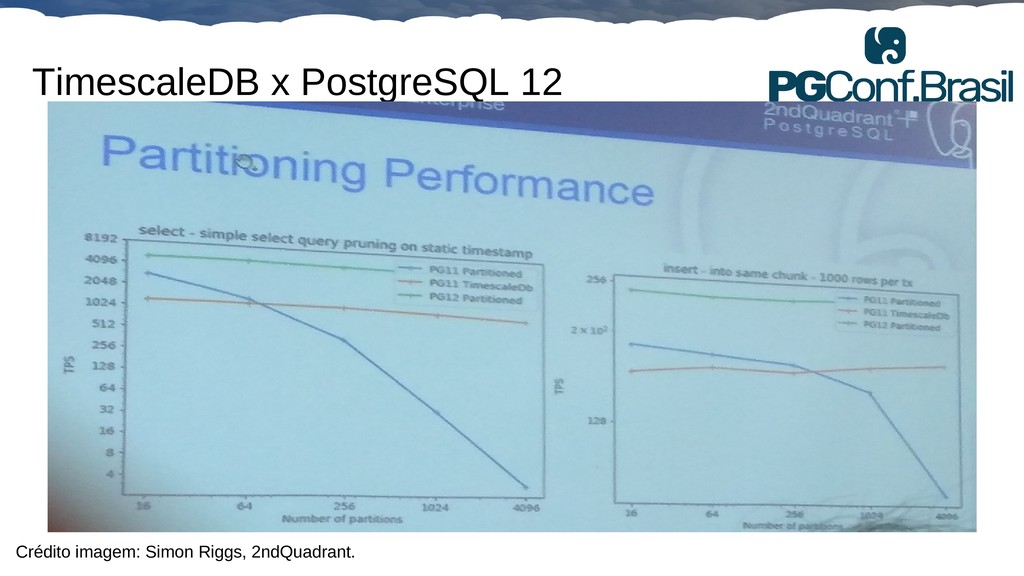
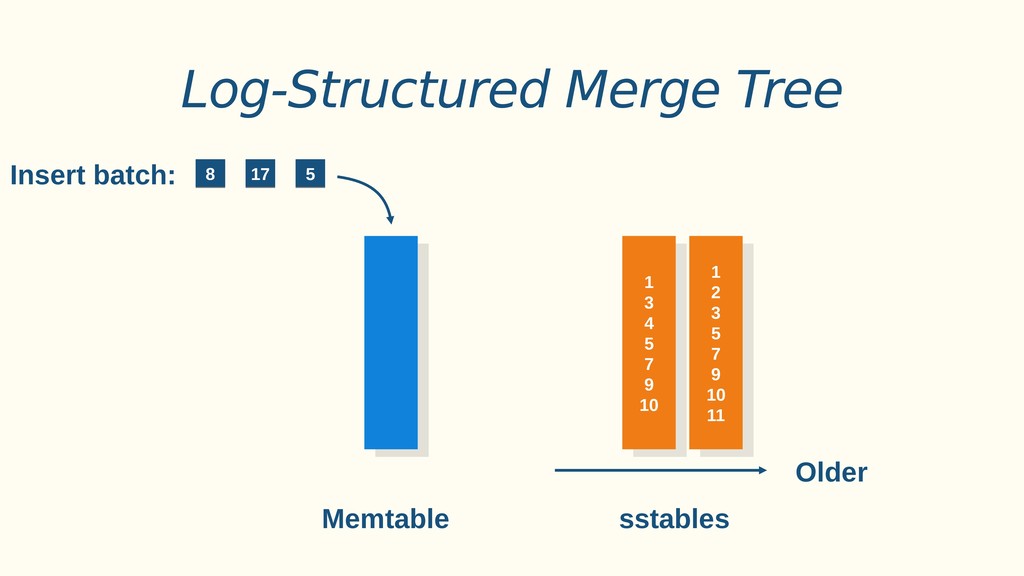
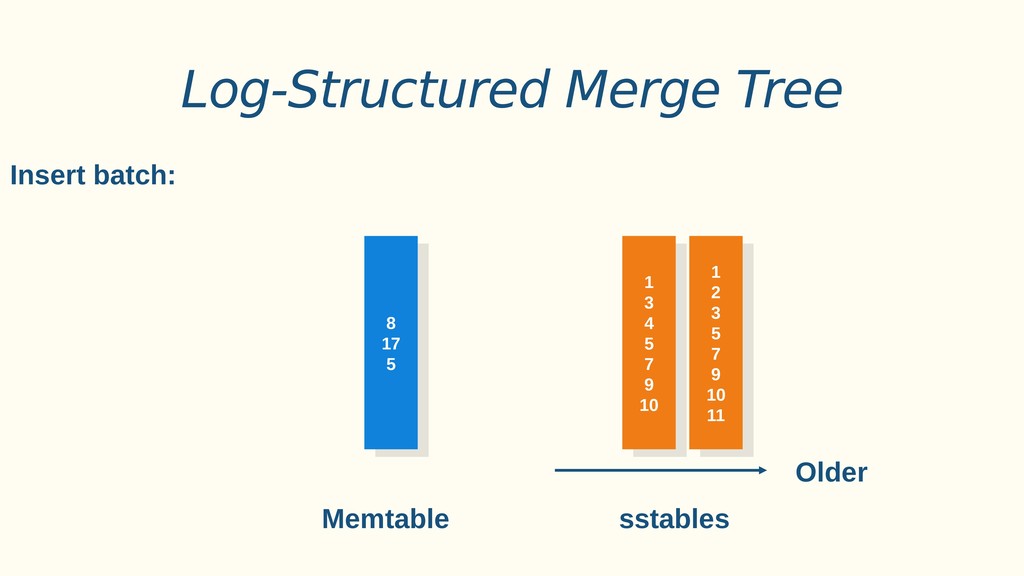
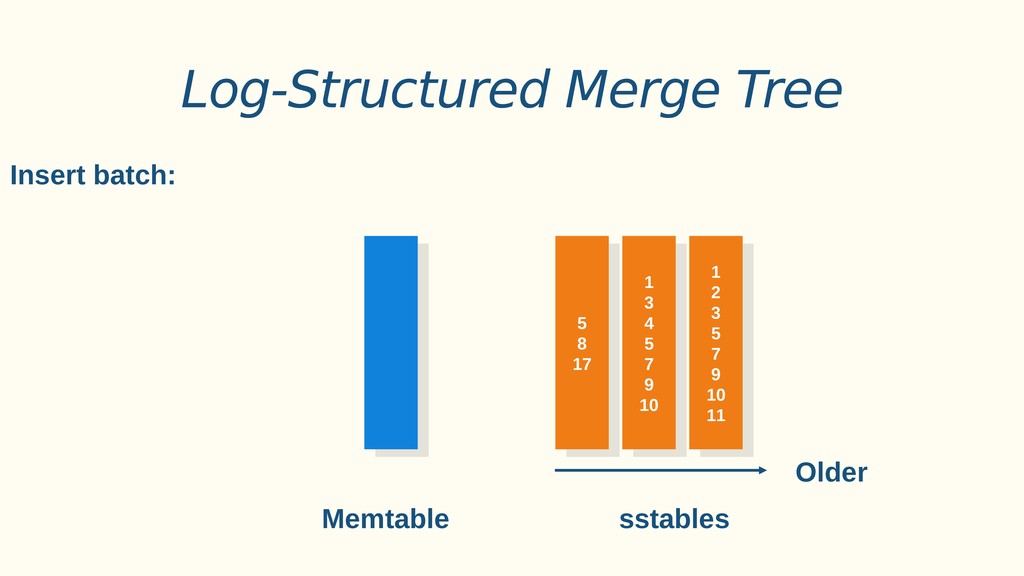
Aplicações IoT podem gerar uma imensidão de dados e daí vem a pergunta: Como escalar? O banco de dados relacional é poderoso, porém não é especializado para escalar. Porém, com o PostgreSQL e o TimescaleDB é possível escalar de maneira simples, eficiente e eficaz. O TimescaleDB é uma extensão especializada para dados de séries temporais de código aberto otimizado para consultas rápidas e complexas. Ela fala 'SQL completo' e, de forma correspondente, é fácil de usar como um banco de dados relacional tradicional, além de escalar em formas anteriormente reservadas para bancos de dados NoSQL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Globalcode – Open4education Usando o TimescaleDB Instalação: root@tdc18-timescaledb ~]# sudo](https://files.speakerdeck.com/presentations/d8ad96f0bd6749ce8ebfd4dda3c7b034/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
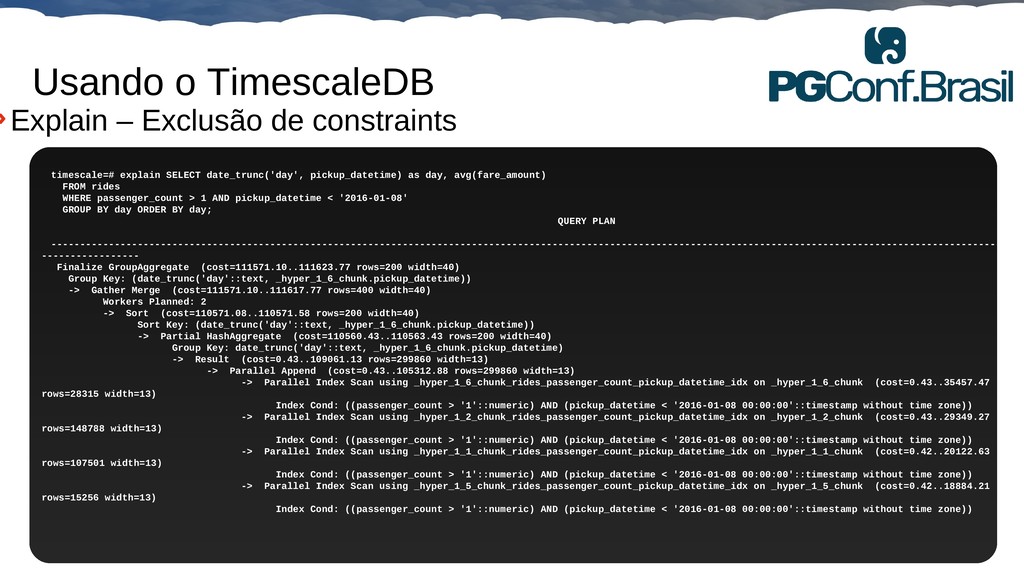{kind=link}
![Dúvidas? [email protected]](https://files.speakerdeck.com/presentations/d8ad96f0bd6749ce8ebfd4dda3c7b034/slide_84.jpg){kind=link}