la mise en œuvre de la stratégie de l’Etat dans le domaine de la donnée. Une action tout au long du cycle de vie de la donnée : Ouverture (open data) et partage des données ƃ Exploitation des données et algorithmes publics ġ Innovation et ouverture de l’action publique 1
projets IA de l’administration Đ Développer des outils mutualisés pour l’action publique ¯ Animer la communauté IA de l’administration Et aussi... Ǘ Développer l’éthique de l’IA dans la sphère publique et la transparence vers les citoyens Î Construire un partenariat avec l’écosystème de la recherche en IA 2
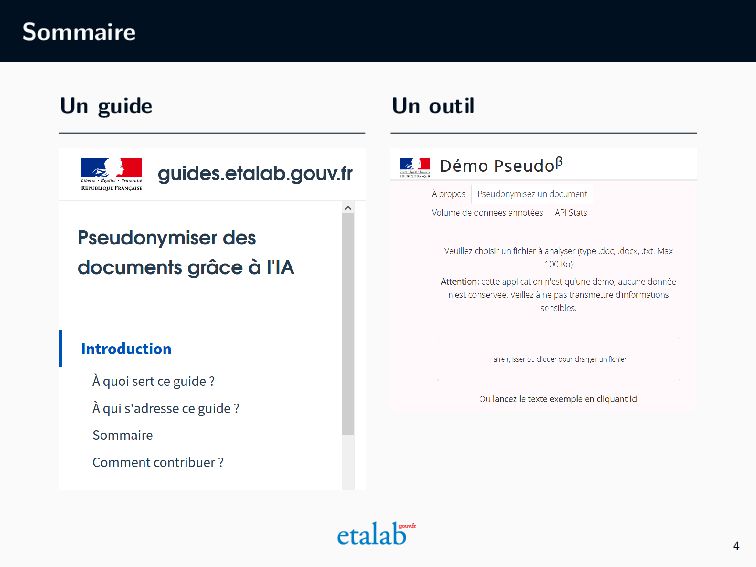
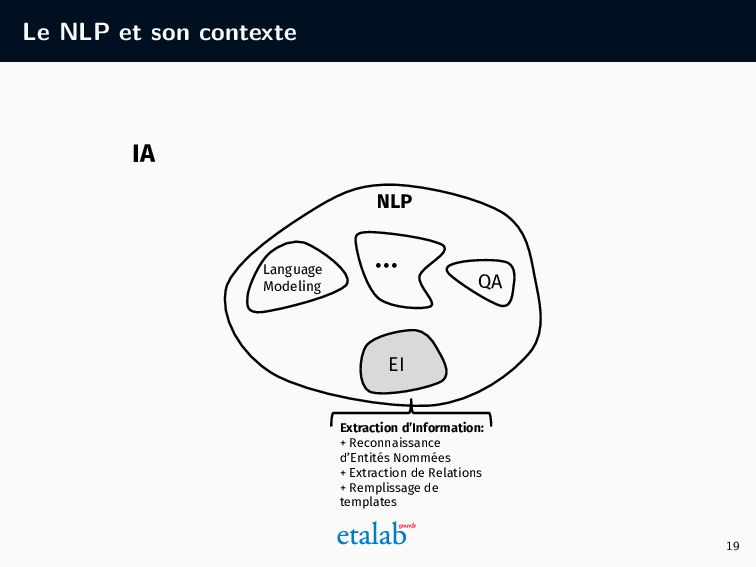
pseudonymisation de documents textuels contenant des données à caractère personnel, pour leur ouverture. Dans quel cadre ? Nos travaux sur la pseudonymisation documents textuels par l’IA, en particulier sur les décisions du Conseil d’État. Quels résultats ? Un guide et un outil. 3
travail réalisé depuis plusieurs années sur l’outil technique Présenter la motivation de la conception de l’outil ì Expliquer la méthodologie technique DŽ Recenser les choix et arbitrages techniques Et au-delà ɔ Présenter la pseudonymisation par l’IA et son utilité ȸ Faire découvrir les étapes et moyens d’un projet d’IA ɤ Préciser les limites et points d’améliorations 7
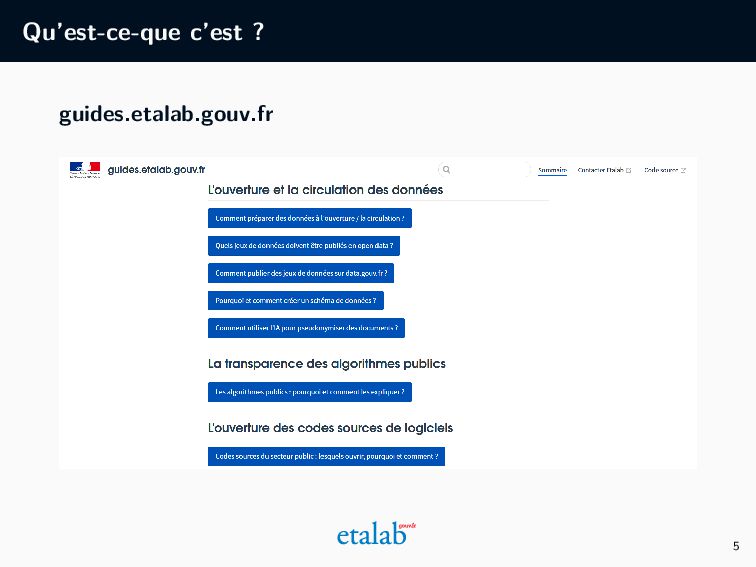
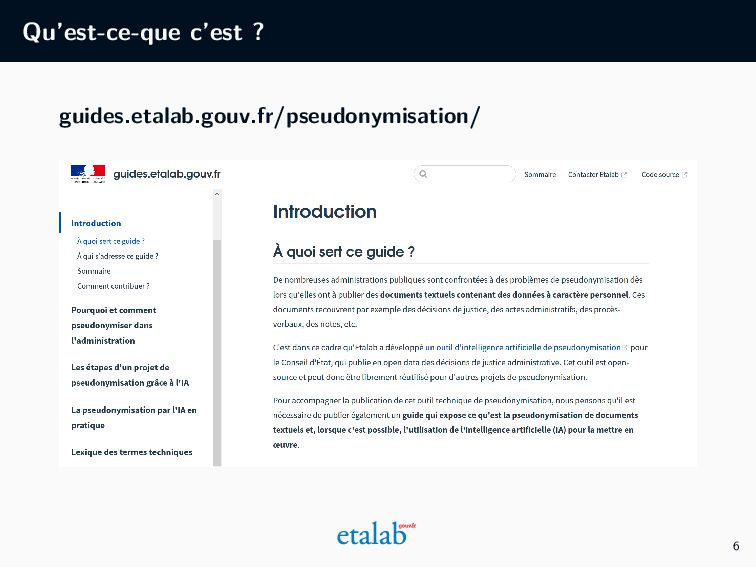
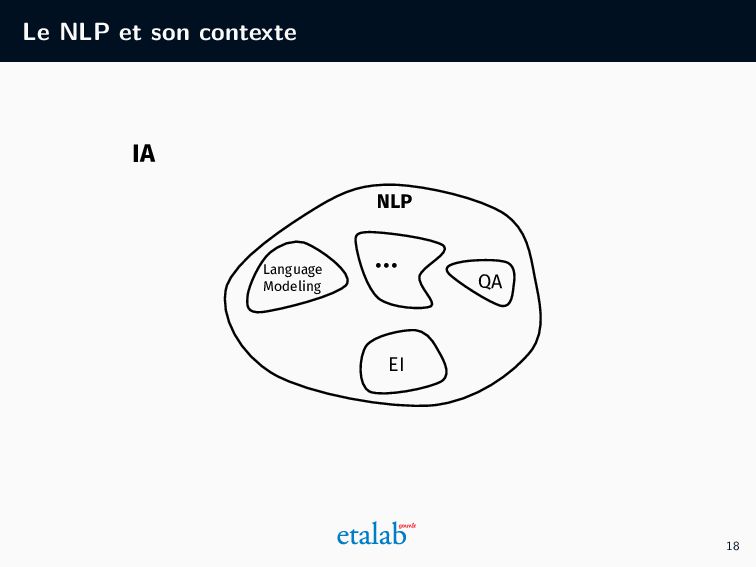
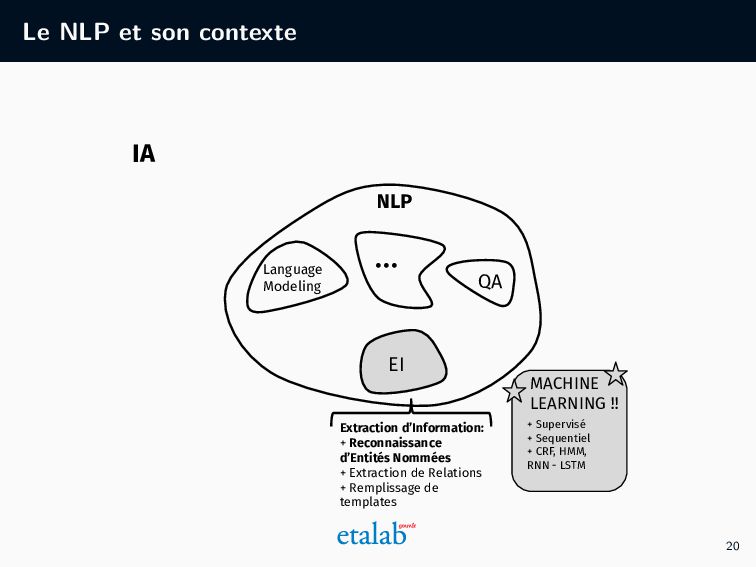
l’administration Qu’est-ce que la pseudonymisation ? Pourquoi pseudonymiser des documents administratifs ? Quelles sont les différentes méthodes de pseudonymisation ? Quels sont les prérequis pour utiliser l’IA ? Les étapes d’un projet de pseudonymisation grâce à l’IA Quelles sont les différentes étapes de la méthode basée sur l’IA que nous avons développée à Etalab ? Quelles ressources sont à mobiliser ? La pseudonymisation par l’IA en pratique Pour un public plus technique, quelles sont les étapes algorithmes de notre approche ? Quels choix techniques et préconisations en avons-nous tiré ? 8
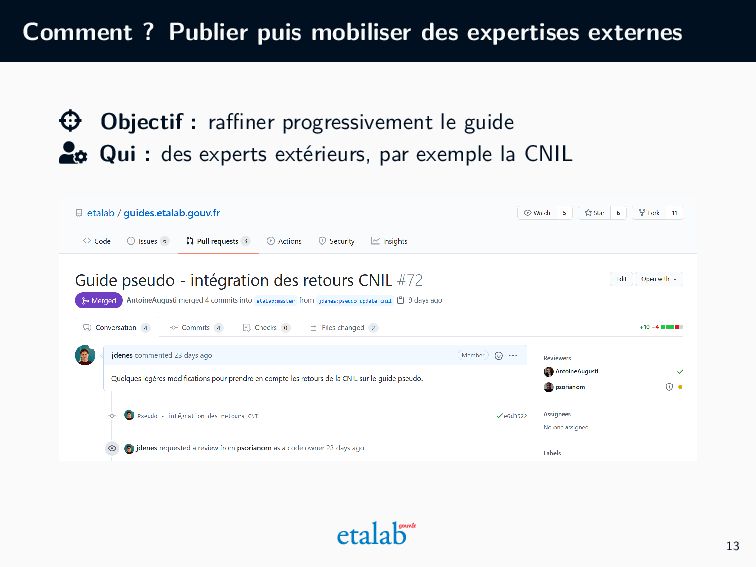
qui part de l’outil technique pour aller vers une abstraction et une accessibilité croissante. Partir d’une explication technique de l’outil Déterminer le propos recherché : pourquoi, pour qui... Rédiger, simplifier, enrichir Améliorer par des retours du public cible 9
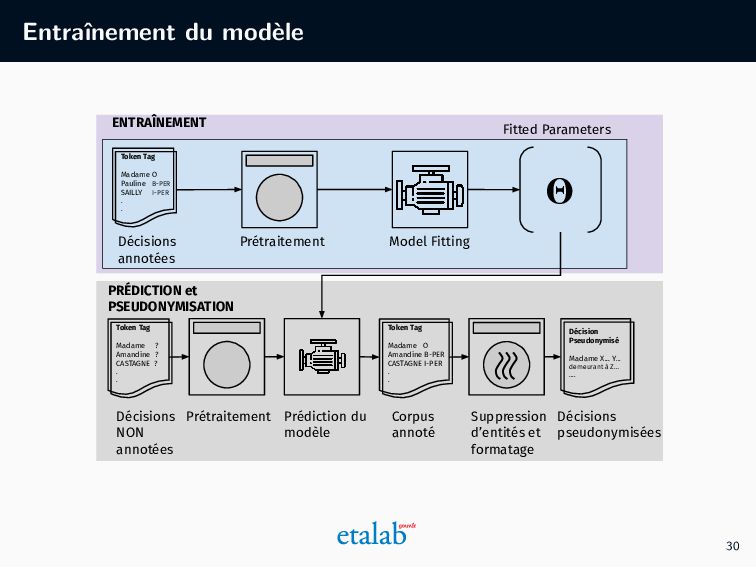
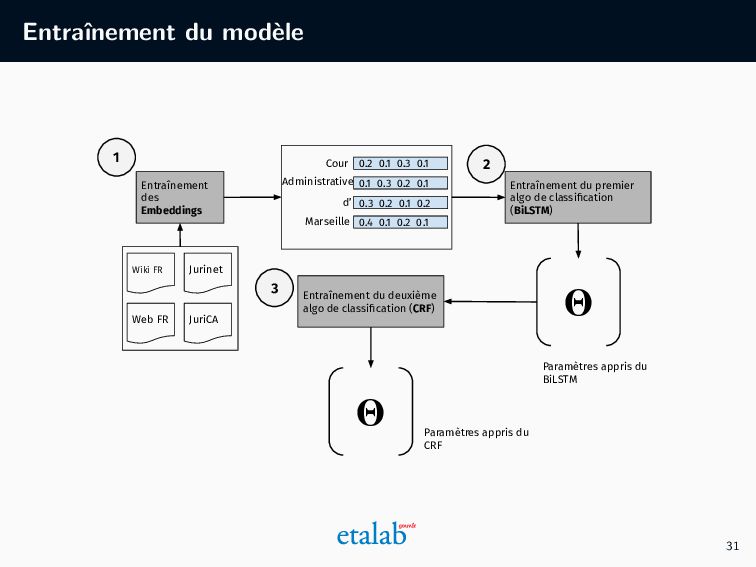
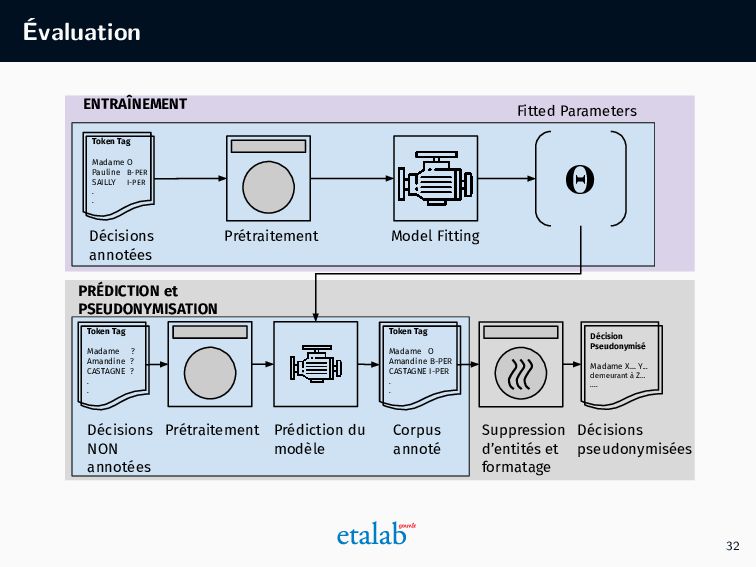
projet de ce type ! • Planification et configuration du projet • Collecte et labellisation des données • Entraînement du modèle • Évaluation • Déploiement • Maintenance (en cours) 22
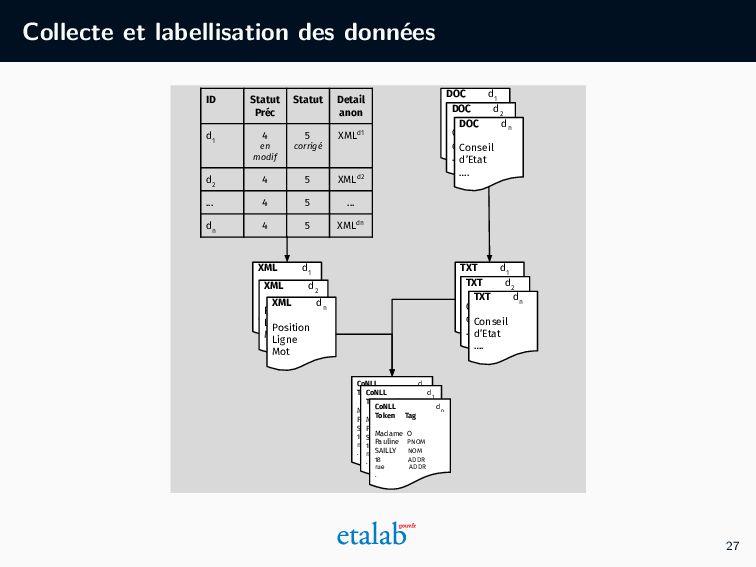
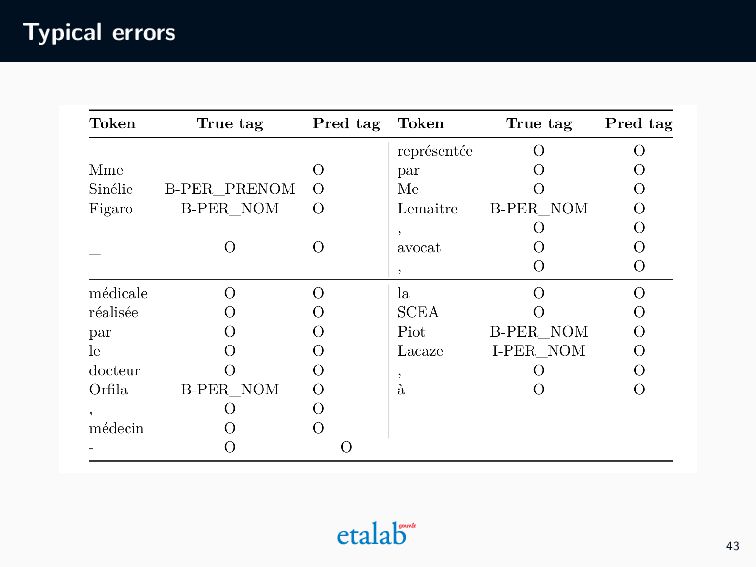
les corrections manuelles fournissent des ”annotations indirectes” (à garder en tête : pas de lignes directrices pour l’annotation), • Le système sauvegarde la localisation et l’entité (nom/prénom/adresse) détectée dans une table (sous forme de XML), • Nous profitons de ces XMLs pour générer un dataset annoté à distance. 26
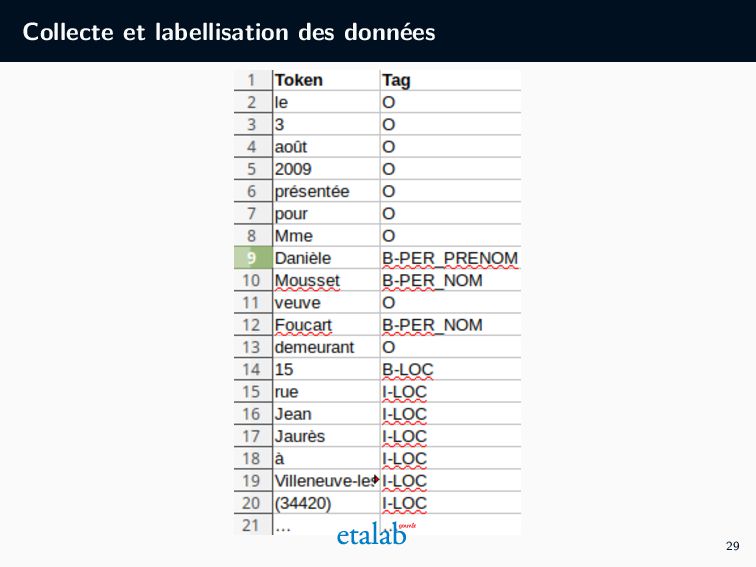
anon d 1 4 en modif 5 corrigé XMLd1 d 2 4 5 XMLd2 ... 4 5 ... d n 4 5 XMLdn XML d 1 Position Ligne Mot XML d 2 Position Ligne Mot XML d n Position Ligne Mot DOC d 1 Conseil d’Etat …. DOC d 2 Conseil d’Etat …. DOC d n Conseil d’Etat …. TXT d 1 Conseil d’Etat …. TXT d 2 Conseil d’Etat …. TXT d n Conseil d’Etat …. CoNLL d 1 Token Tag Madame O Pauline PNOM SAILLY NOM 18 ADDR rue ADDR . CoNLL d 1 Token Tag Madame O Pauline PNOM SAILLY NOM 18 ADDR rue ADDR . CoNLL d n Token Tag Madame O Pauline PNOM SAILLY NOM 18 ADDR rue ADDR . 27
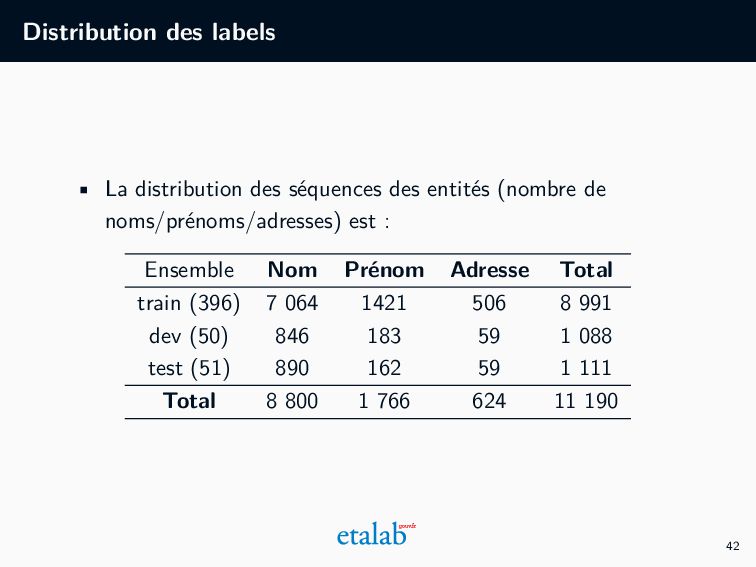
931 décisions qui ont été corrigées à la main. • Parmi ces décisions, 24 769 nous sont disponibles • 16 559 ont été transformées avec succès (démarche précédente) • Nous prenons un échantillon de 497 décisions (afin de diminuer les temps de calcul pendent les expériences) • Nous divisons ces 497 décisions en trois ensembles: train (396), dev (50), test (51), 28
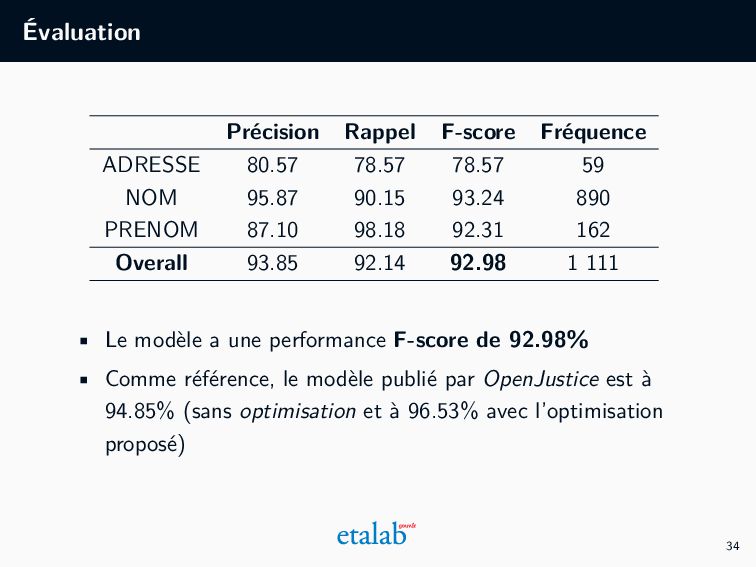
créé précédemment, 2. Un ensemble de métriques (si on prend les noms comme exemple) : • Précision : taux des noms correctement identifiés comme un nom parmi tous les noms identifiés par le modèle, • Rappel : taux de noms correctement identifiés comme un nom parmi tous les vrais noms dans l’ensemble de test, • F-score : moyenne harmonique de la précision et du rappel. • Erreur Métier : ratio de nombre de décisions pseudonymisées avec au moins une erreur divisé par le nombre total des décisions pseudonymisées. 33
NOM 95.87 90.15 93.24 890 PRENOM 87.10 98.18 92.31 162 Overall 93.85 92.14 92.98 1 111 • Le modèle a une performance F-score de 92.98% • Comme référence, le modèle publié par OpenJustice est à 94.85% (sans optimisation et à 96.53% avec l’optimisation proposé) 34
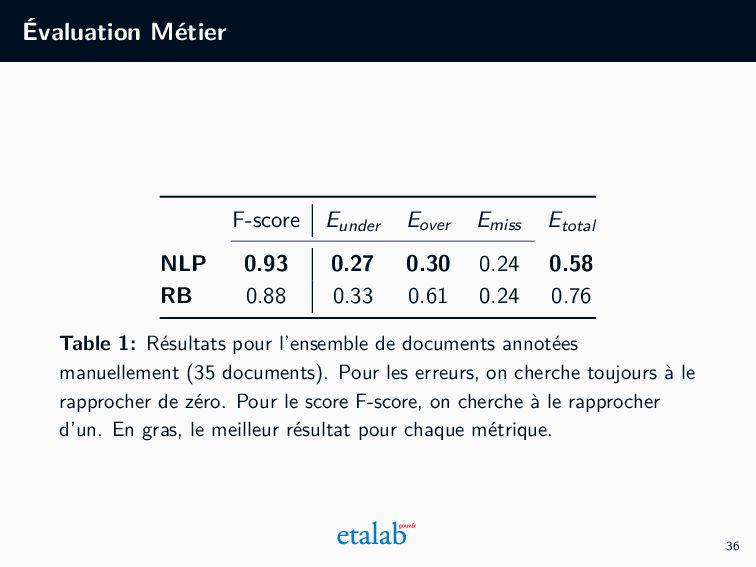
pour un ensemble de décisions pseudonymisées avec notre système (NLP) et de le comparer au taux d’erreur du système actuel (RB). On calcule quatre types d’erreurs (qui occurrent au moins une fois dans l’analyse): 1. Sous-identification (Eunder ) : des entités (noms/prenoms/adresses) non détectées par le système 2. Sur-identification (Eover ) : des entités repérées comme une entité sans l’être 3. Fausse-identification (Emiss ) : des entités classifiées comme une autre type d’entité 4. Total : toute sorte d’erreur 35
0.30 0.24 0.58 RB 0.88 0.33 0.61 0.24 0.76 Table 1: Résultats pour l’ensemble de documents annotées manuellement (35 documents). Pour les erreurs, on cherche toujours à le rapprocher de zéro. Pour le score F-score, on cherche à le rapprocher d’un. En gras, le meilleur résultat pour chaque métrique. 36
serveurs du Conseil d’État • Encore mieux consolider les données d’entrée • S’occuper de la maintenance du modèle/code (ajouter des tests) • Lancer plus d’expériences visant l’amélioration du modèle 38
projet fait partie des outils mutualisés du Lab IA à Etalab. Cela peut vous aider à : • Se renseigner et comprendre comment ça marche la pseudonymisation à l’aide de l’IA • Bootstrapper un chantier de pseudonymisation des données textuelles • Mieux comprendre comment ça marche un projet NLP/Machine Learning 39
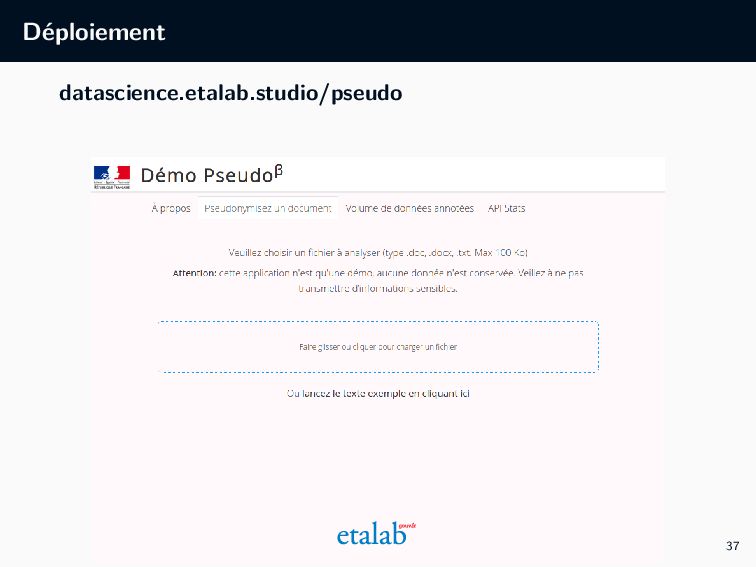
guides.etalab.gouv.fr/pseudonymisation 2. La démo Pseudo + Pseudo REST API datascience.etalab.studio/pseudo/ 3. Du code et documentation ouverte et deployable sur des autres environnements 4. La livraison des produits au Conseil d’État 5. La contributions à des librairies open source NLP (Flair) 40
pseudonymiser les décisions de justice pour les ouvrir en open data • On peut attaquer la problématique à l’aide de la reconnaissance d’entités nommées (REN) • La REN nécessite des données annotées manuellement ou un proxy • Nous avons besoin d’accès à une machine capable d’entraîner des modelés • Le NLP n’est pas magique. Ce n’est pas parfait • Un modèle pas deployé est un modèle qui ne serve pas à grand chose. Contacts : [email protected] / [email protected] 41
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}