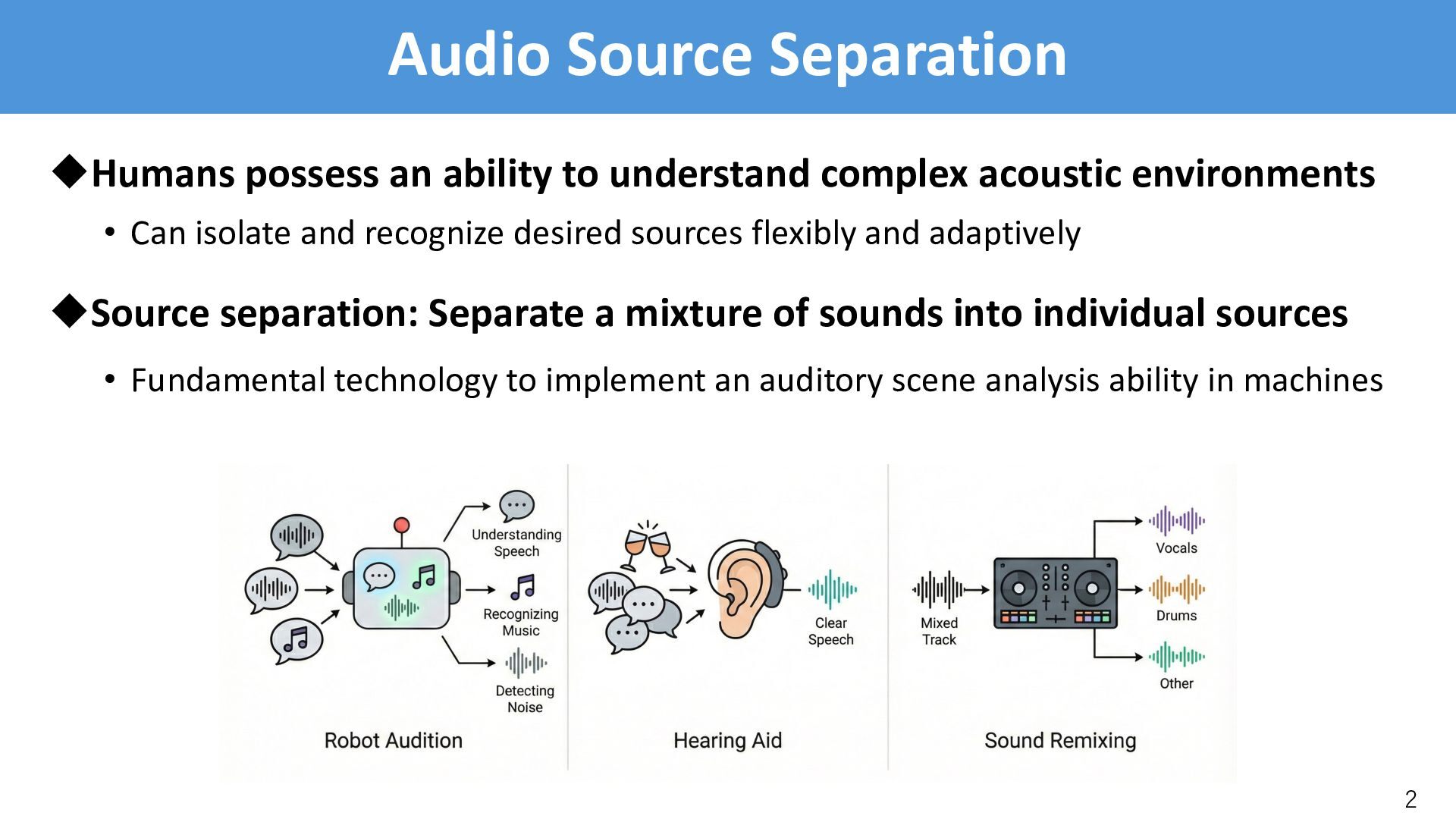
acoustic environments • Can isolate and recognize desired sources flexibly and adaptively uSource separation: Separate a mixture of sounds into individual sources • Fundamental technology to implement an auditory scene analysis ability in machines 2
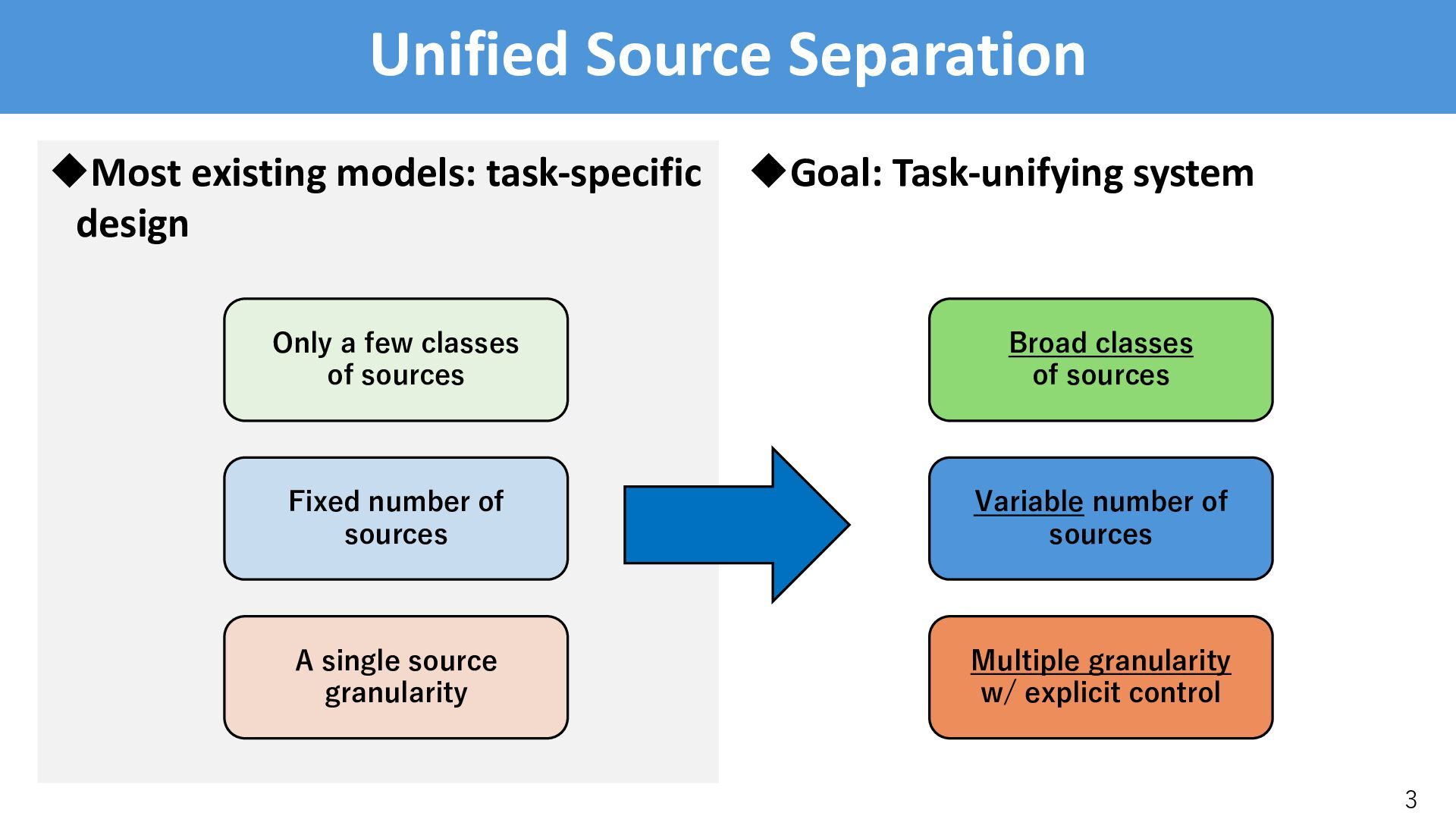
system 3 Fixed number of sources A single source granularity Only a few classes of sources Variable number of sources Multiple granularity w/ explicit control Broad classes of sources
model (Chapter 3.2) • Unified source separation model based on prompting (Chapter 6.3) uEncoder/Decoder for Unified Source Separation Model • Cross-attention-based encoder/decoder for spectral feature compression (Chapter 3.3) uFuture Directions • Large-scale pre-training by unsupervised learning • Unified source separation with input universality 4
model (Chapter 3.2) • Unified source separation model based on prompting (Chapter 6.3) uEncoder/Decoder for Unified Source Separation Model • Cross-attention-based encoder/decoder for spectral feature compression (Chapter 3.3) uFuture Directions • Large-scale pre-training by unsupervised learning • Unified source separation with input universality 5
interest • Task-specific models needs to be deployed for each application, which is not efficient uNN’s powerful modeling capability may enable unifying all separation tasks • LLMs handles various tasks that were originally handled by specialist models • To address all separation tasks, the model needs to handle (i) arbitrary classes of and (ii) a variable number of sources, with (iii) an explicit control of granularity 6 Task Sources of interest Speech enhancement (SE) Speech, Noise Speech separation (SS) Speech × ", Noise Environmental sound separation (USS) Sound effects (SFX) × " Music source separation (MSS) Vocals, Bass, Drums, Other inst. Cinematic audio source separation (CASS) Speech, SFX-mix, Music-mix
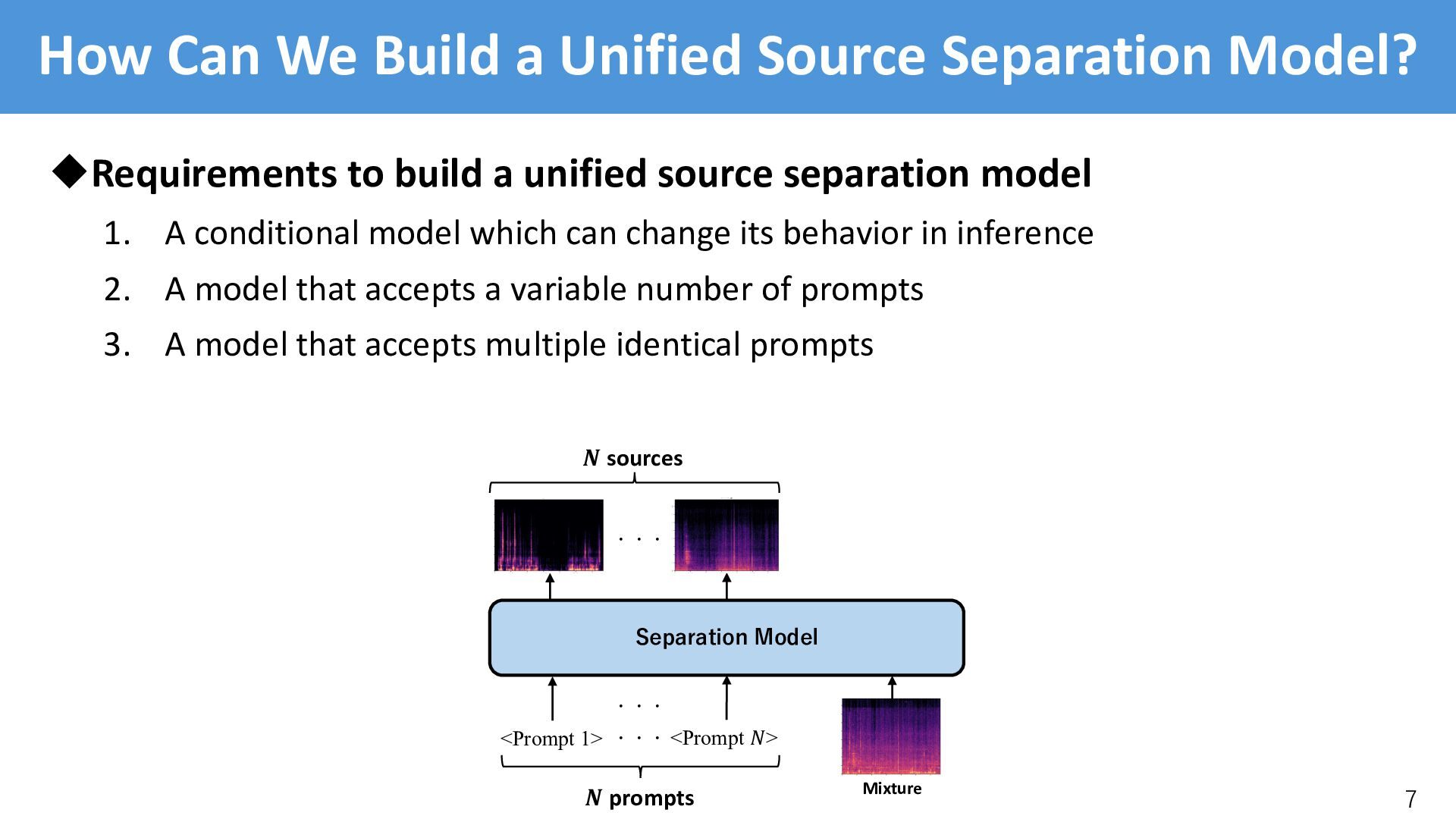
to build a unified source separation model 1. A conditional model which can change its behavior in inference 2. A model that accepts a variable number of prompts 3. A model that accepts multiple identical prompts 7 Separation Model Mixture <Prompt 1> <Prompt !> ・・・ ・・・ ! prompts ! sources ・・・
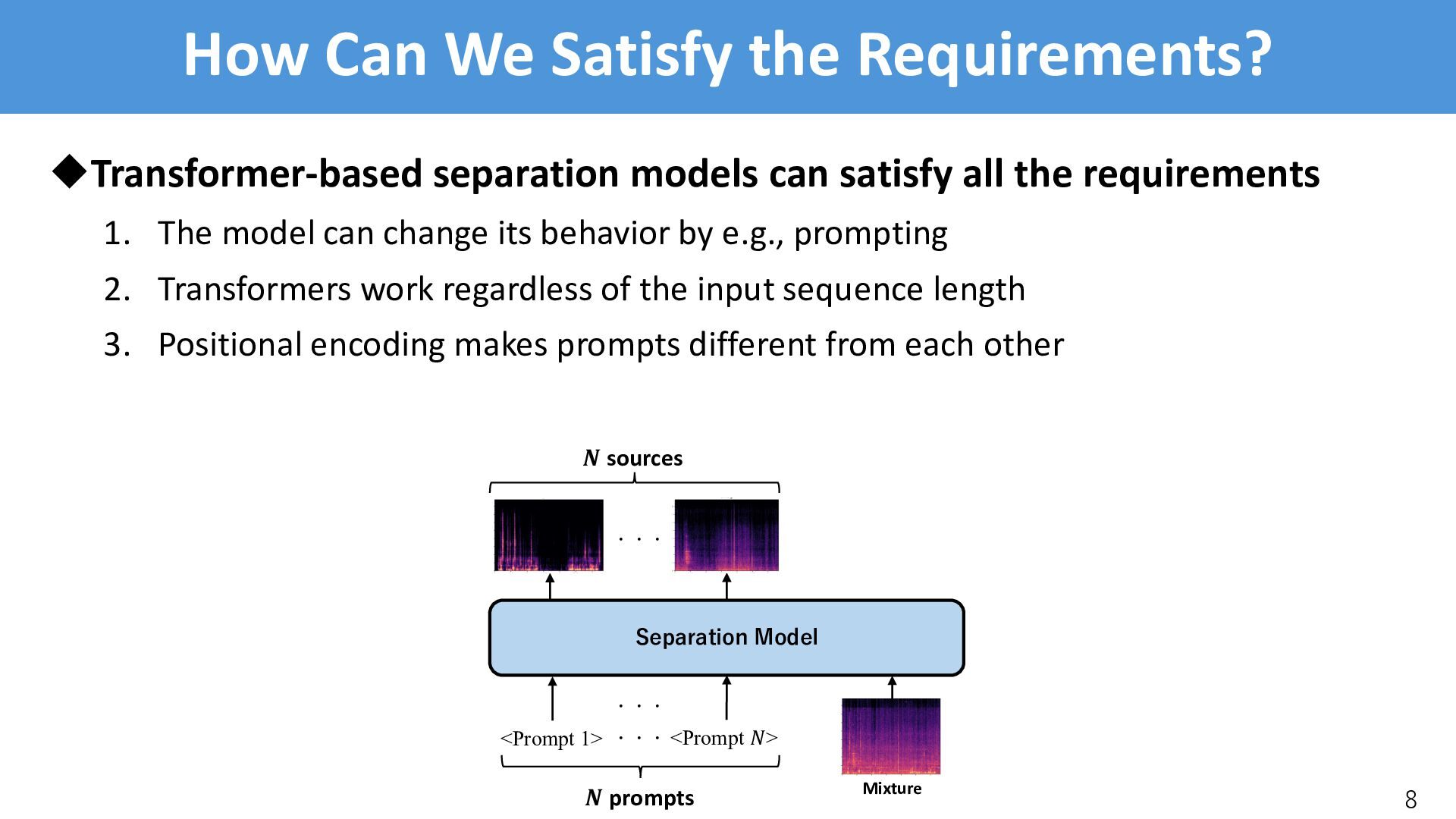
satisfy all the requirements 1. The model can change its behavior by e.g., prompting 2. Transformers work regardless of the input sequence length 3. Positional encoding makes prompts different from each other 8 Separation Model Mixture <Prompt 1> <Prompt !> ・・・ ・・・ ! prompts ! sources ・・・
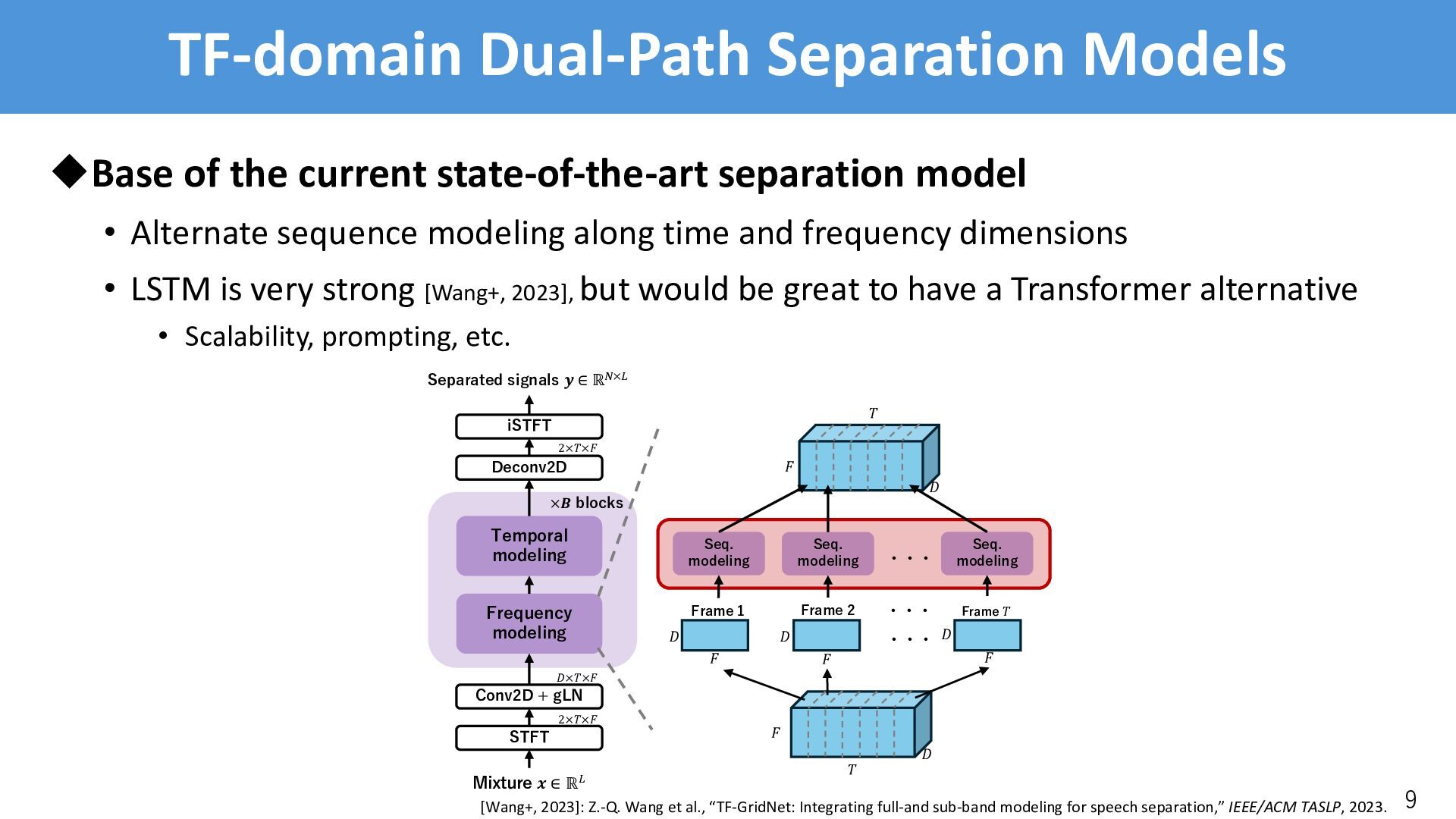
model • Alternate sequence modeling along time and frequency dimensions • LSTM is very strong [Wang+, 2023], but would be great to have a Transformer alternative • Scalability, prompting, etc. 9 Frequency modeling Temporal modeling Conv2D + gLN STFT iSTFT Deconv2D Separated signals ! ∈ ℝ!×# Mixture $ ∈ ℝ# 2×%×& '×%×& 2×%×& ×" blocks # $ % # $ # $ # Frame 1 Frame 2 Frame ! $ ・・・ ・・・ Seq. modeling Seq. modeling Seq. modeling ・・・ # $ % [Wang+, 2023]: Z.-Q. Wang et al., “TF-GridNet: Integrating full-and sub-band modeling for speech separation,” IEEE/ACM TASLP, 2023.
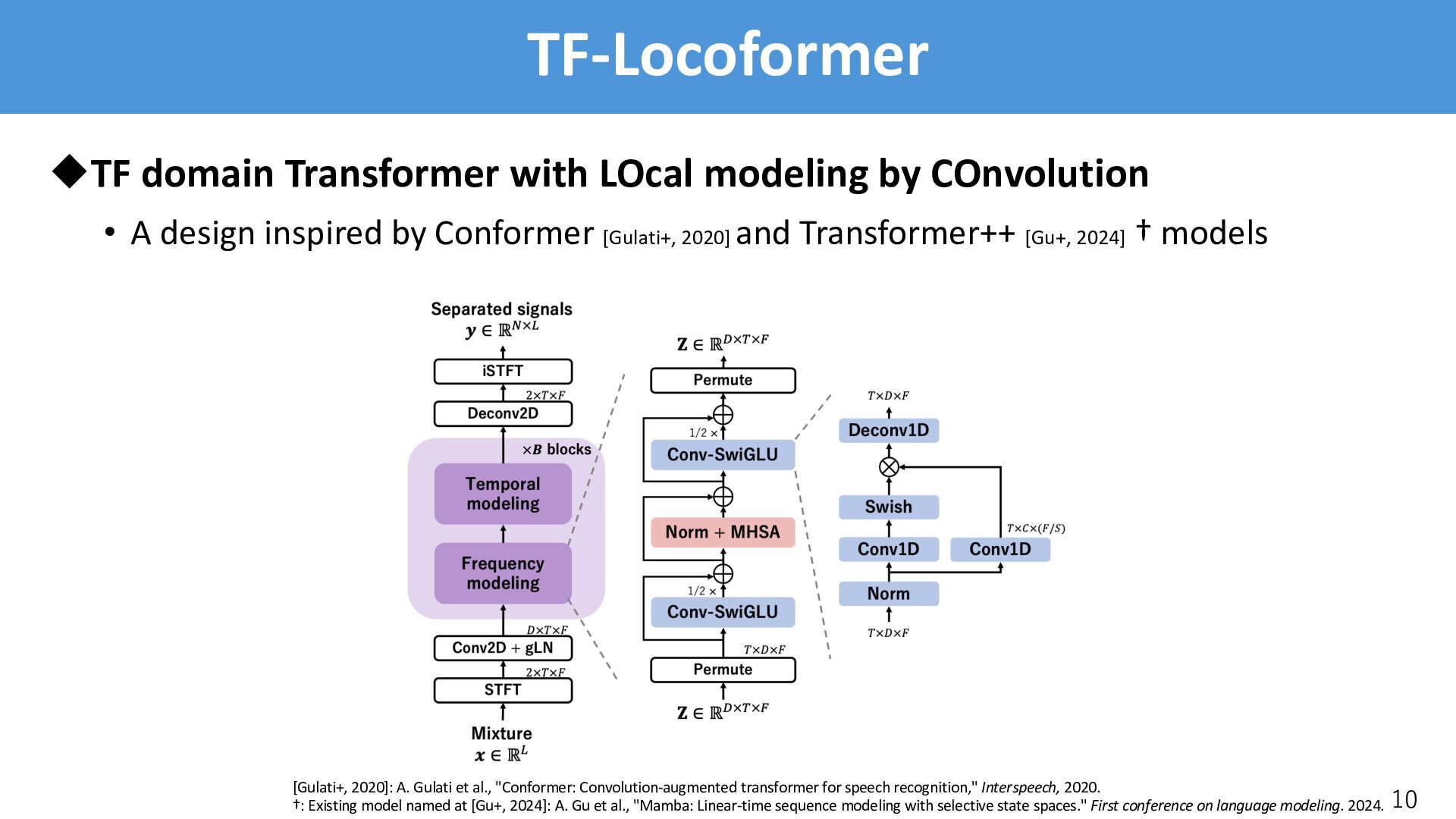
A design inspired by Conformer [Gulati+, 2020] and Transformer++ [Gu+, 2024] † models 10 [Gulati+, 2020]: A. Gulati et al., "Conformer: Convolution-augmented transformer for speech recognition," Interspeech, 2020. †: Existing model named at [Gu+, 2024]: A. Gu et al., "Mamba: Linear-time sequence modeling with selective state spaces." First conference on language modeling. 2024.
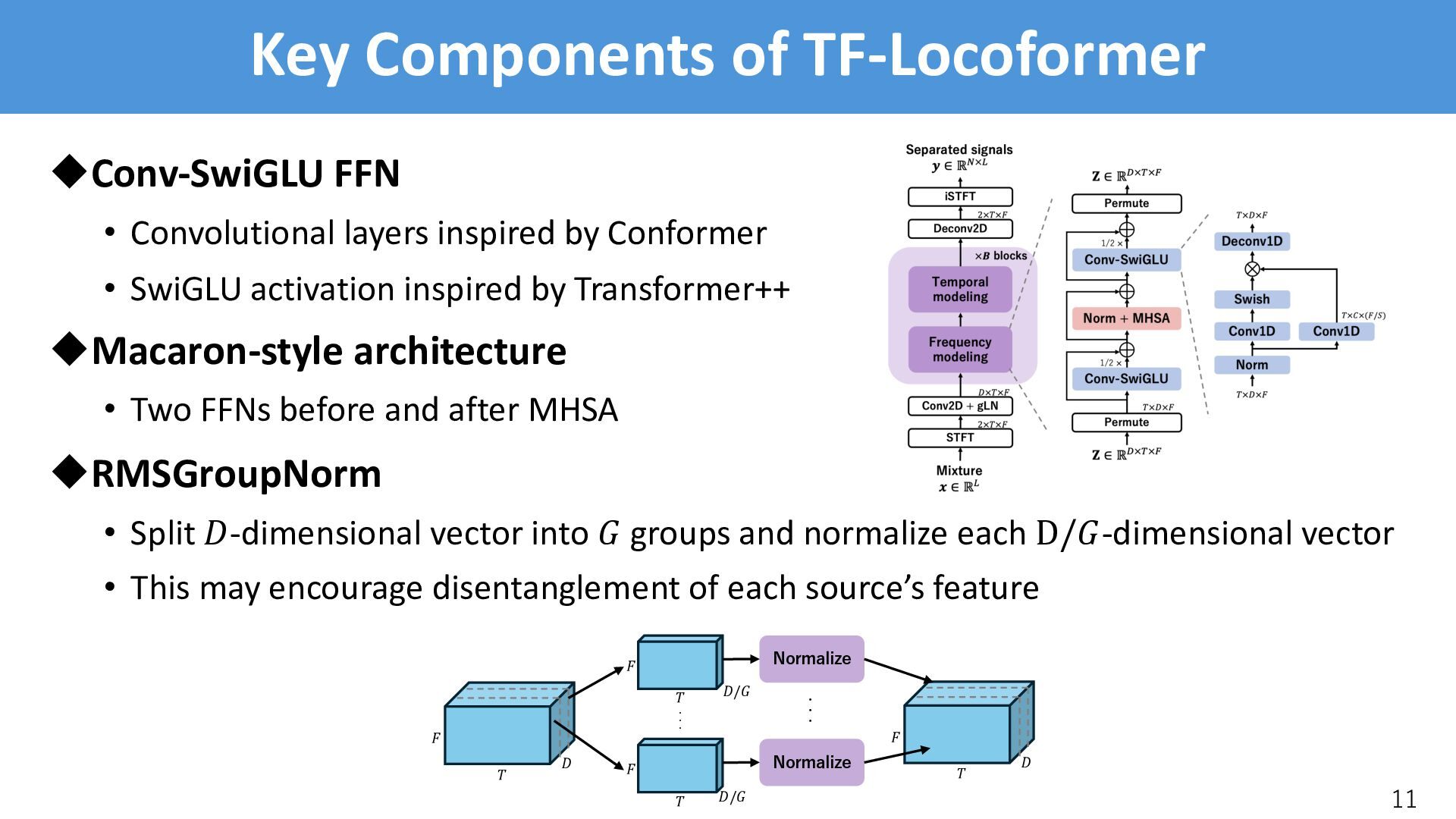
by Conformer • SwiGLU activation inspired by Transformer++ uMacaron-style architecture • Two FFNs before and after MHSA uRMSGroupNorm • Split !-dimensional vector into " groups and normalize each D/"-dimensional vector • This may encourage disentanglement of each source’s feature 11 # % $ # % # % $/' $/' ・・・ Normalize Normalize ・・・ # % $
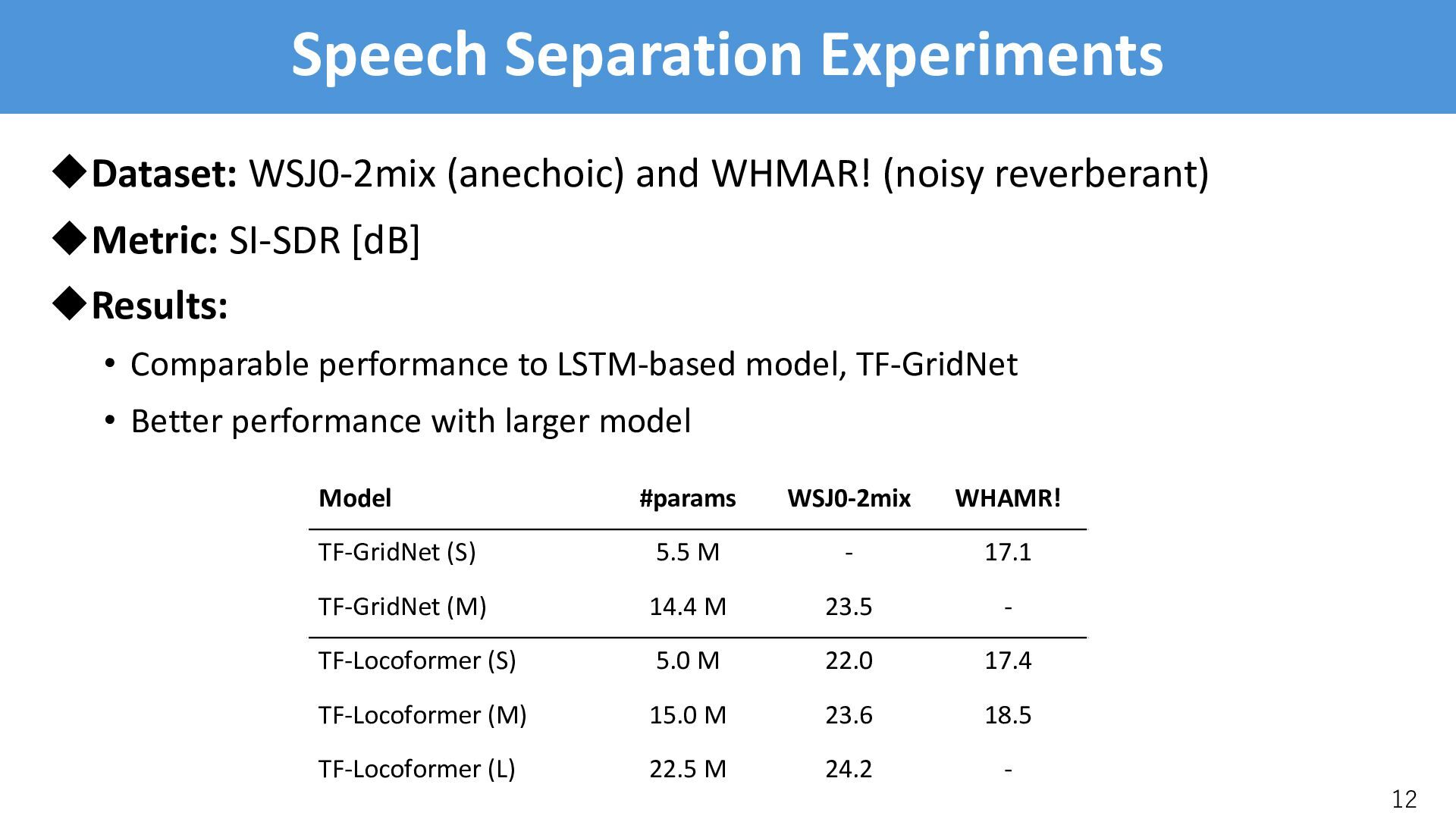
uMetric: SI-SDR [dB] uResults: • Comparable performance to LSTM-based model, TF-GridNet • Better performance with larger model 12 Model #params WSJ0-2mix WHAMR! TF-GridNet (S) 5.5 M - 17.1 TF-GridNet (M) 14.4 M 23.5 - TF-Locoformer (S) 5.0 M 22.0 17.4 TF-Locoformer (M) 15.0 M 23.6 18.5 TF-Locoformer (L) 22.5 M 24.2 -
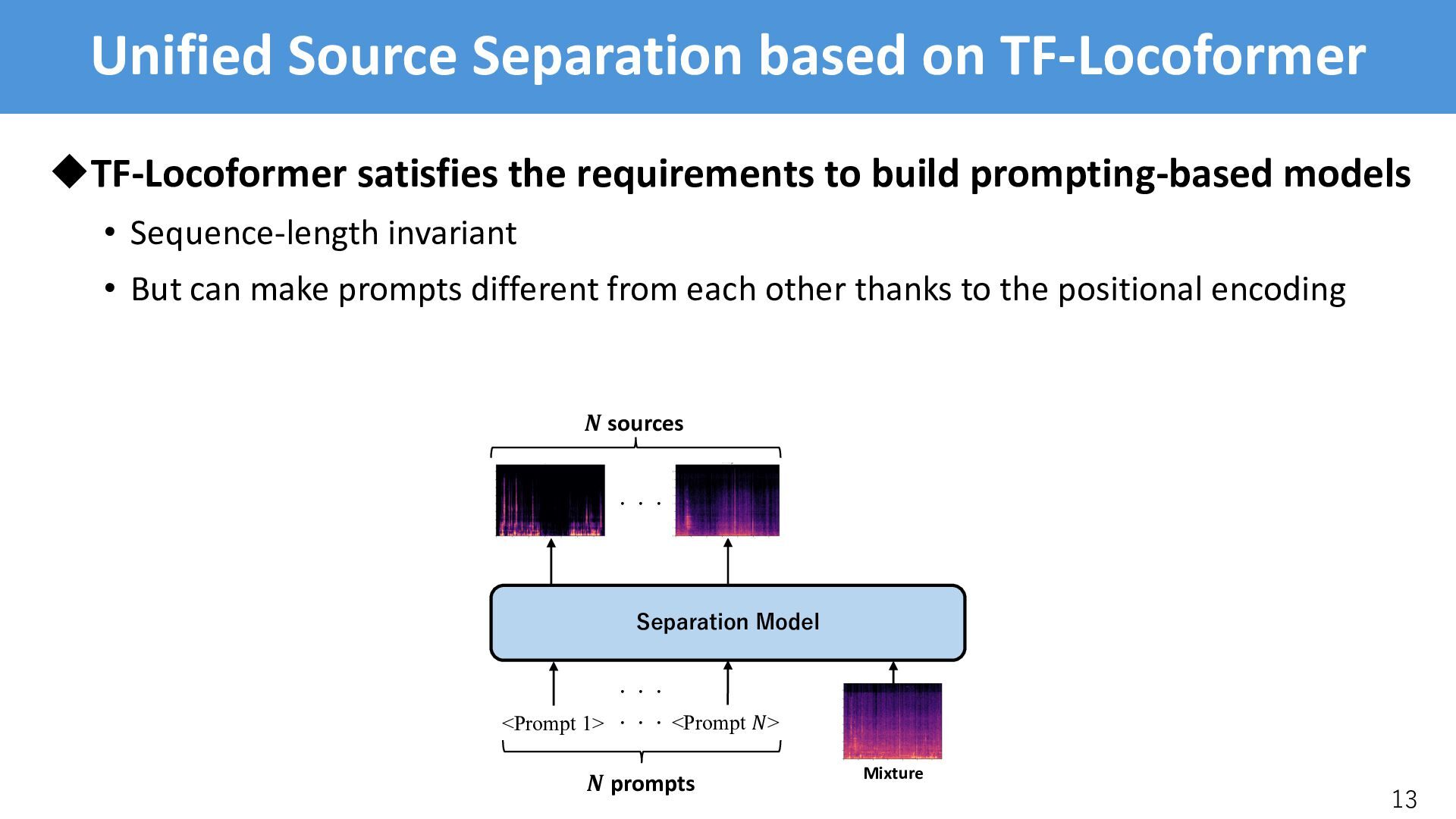
to build prompting-based models • Sequence-length invariant • But can make prompts different from each other thanks to the positional encoding 13 Separation Model Mixture <Prompt 1> <Prompt !> ・・・ ・・・ ! prompts ! sources ・・・
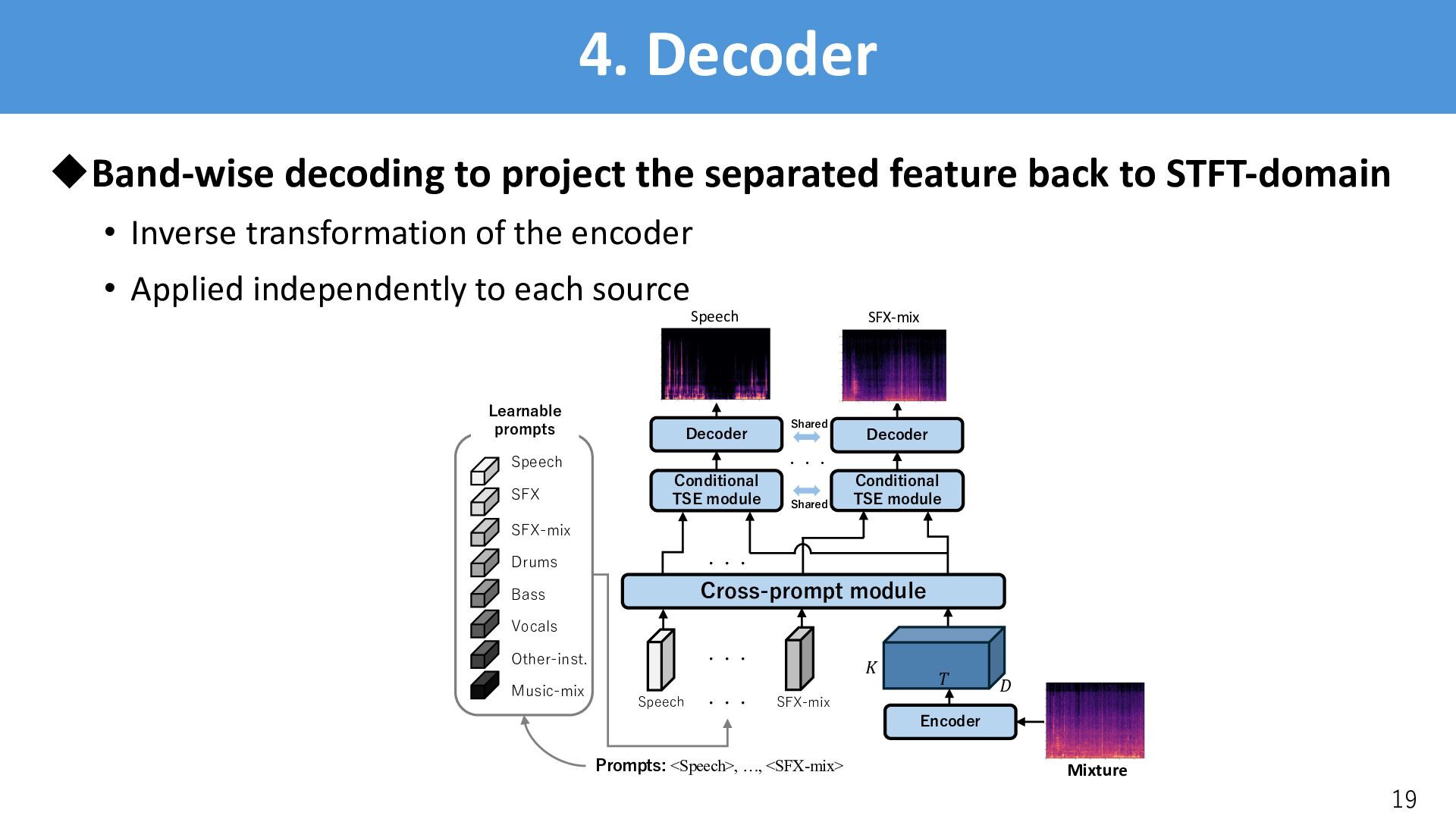
STFT to the mixture waveform % ∈ ℝ#×$×% • Further encodes the spectrogram into ( ∈ ℝ&×'×% 16 ! " # Encoder Mixture [Luo+, 2023]: Y. Luo and J. Yu, “Music source separation with band-split rnn,” IEEE/ACM TASLP, 2023.
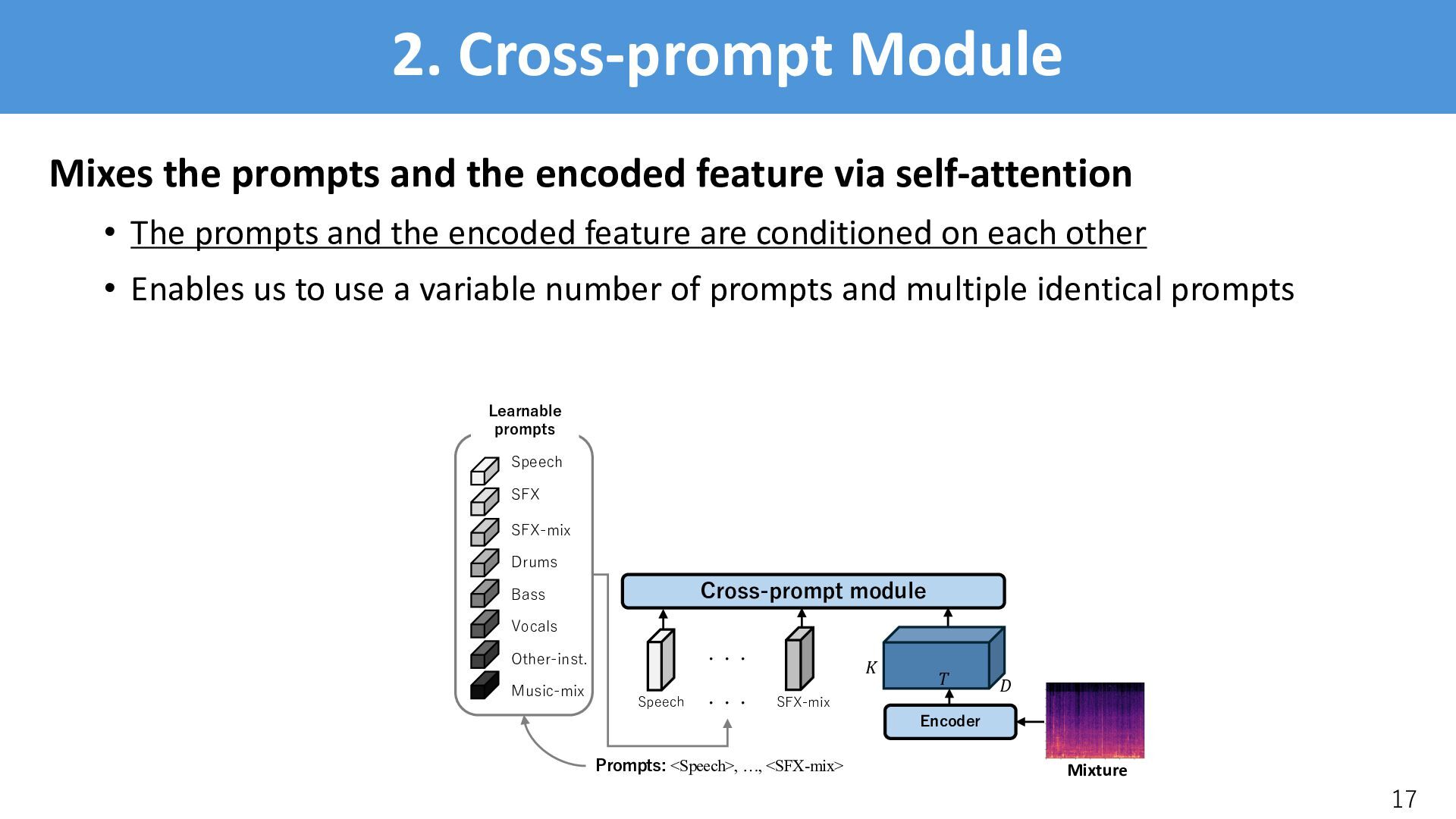
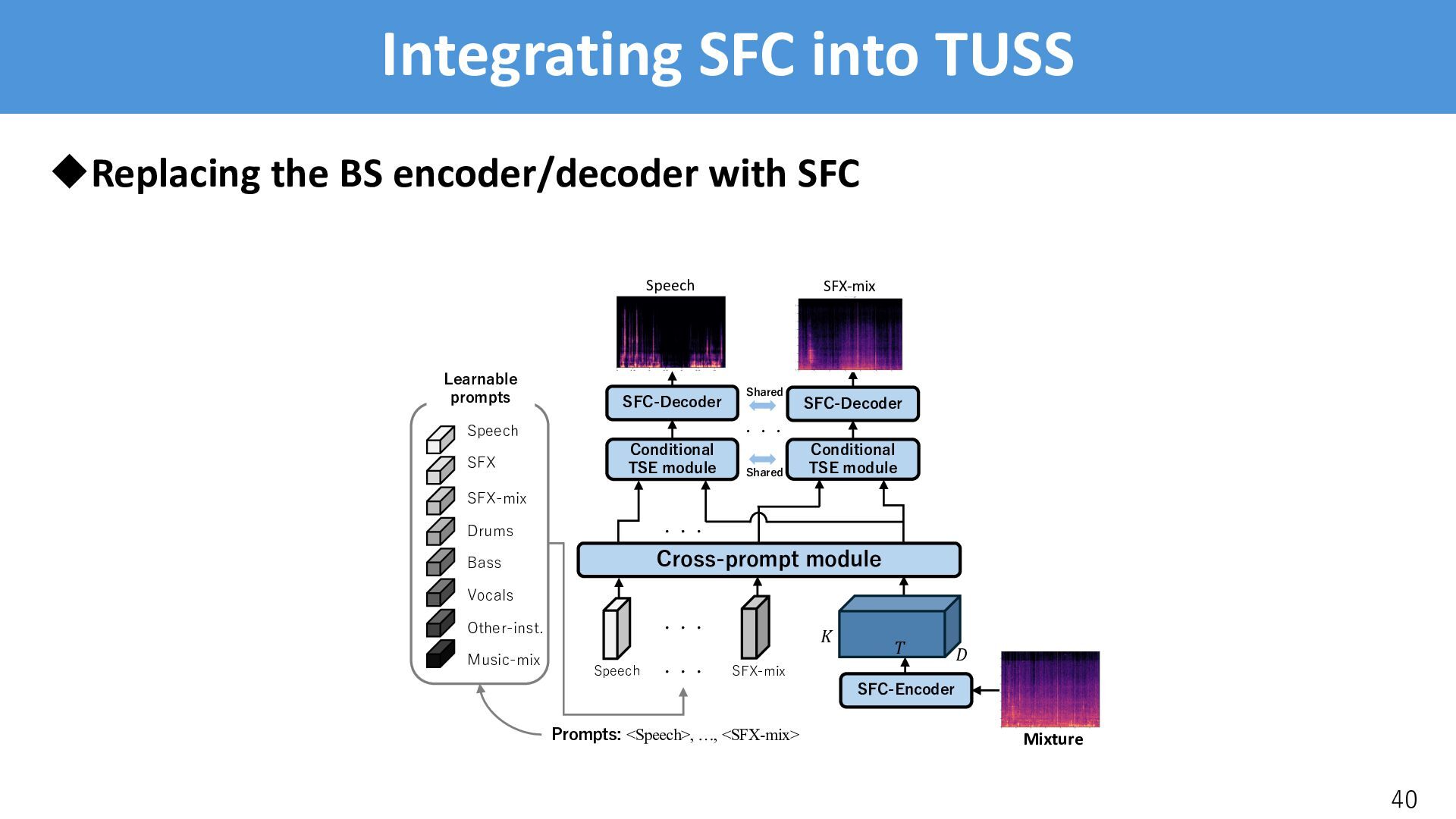
via self-attention • The prompts and the encoded feature are conditioned on each other • Enables us to use a variable number of prompts and multiple identical prompts 17 ! " # Cross-prompt module Speech Learnable prompts SFX SFX-mix Drums Bass Vocals Other-inst. Music-mix Speech SFX-mix ・・・ Prompts: <Speech>, …, <SFX-mix> ・・・ Encoder Mixture
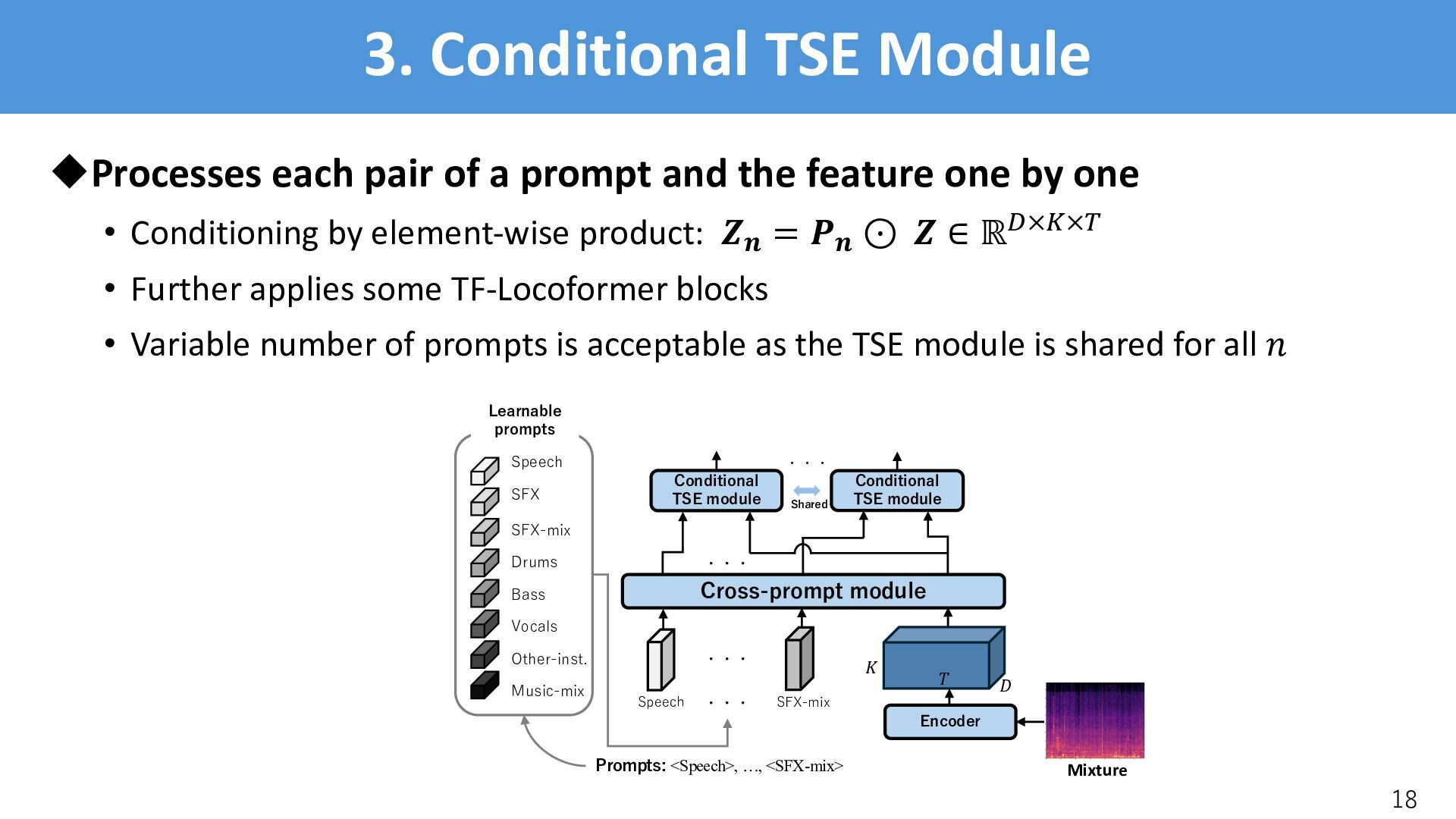
and the feature one by one • Conditioning by element-wise product: (( = *( ⊙ ( ∈ ℝ&×'×% • Further applies some TF-Locoformer blocks • Variable number of prompts is acceptable as the TSE module is shared for all , 18 ! " # Cross-prompt module Speech Learnable prompts SFX SFX-mix Drums Bass Vocals Other-inst. Music-mix Speech SFX-mix Conditional TSE module ・・・ Conditional TSE module Prompts: <Speech>, …, <SFX-mix> ・・・ ・・・ Shared Encoder ・・・ Mixture
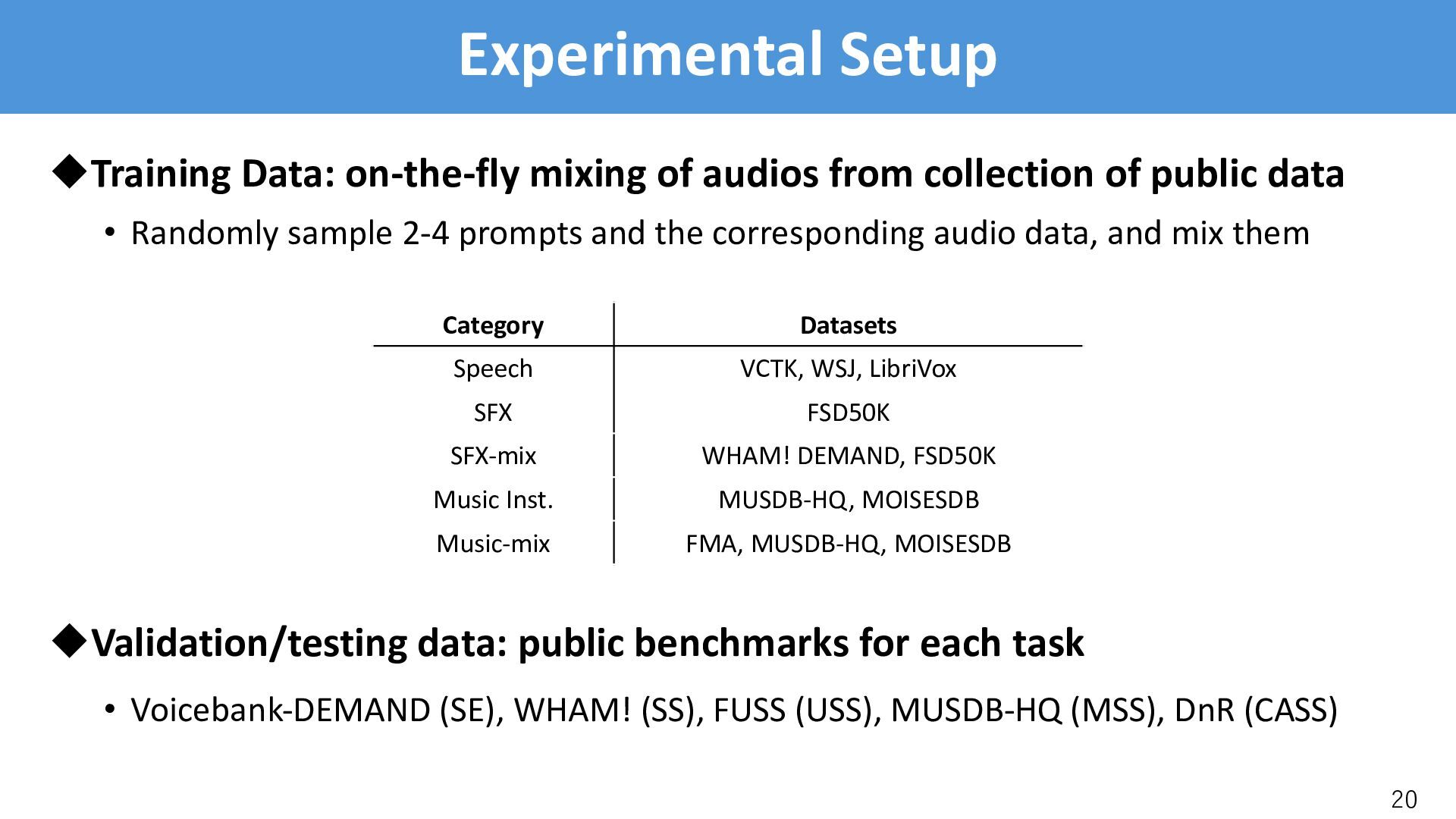
of public data • Randomly sample 2-4 prompts and the corresponding audio data, and mix them uValidation/testing data: public benchmarks for each task • Voicebank-DEMAND (SE), WHAM! (SS), FUSS (USS), MUSDB-HQ (MSS), DnR (CASS) 20 Category Datasets Speech VCTK, WSJ, LibriVox SFX FSD50K SFX-mix WHAM! DEMAND, FSD50K Music Inst. MUSDB-HQ, MOISESDB Music-mix FMA, MUSDB-HQ, MOISESDB
with fixed number of outputs • TUSS: proposed TUSS-based conditional model uMetrics: • SI-SDR [dB], except for MSS where we use SNR [dB] uResults: • Prompting-based unified model outperforms the unconditional model • Successfully handled tasks that require different #sources and granularity 21 Method SE SS USS MSS CASS Average Unconditional 14.0 6.8 8.1 4.9 6.0 8.0 TUSS 14.8 9.1 9.6 6.8 9.1 9.9
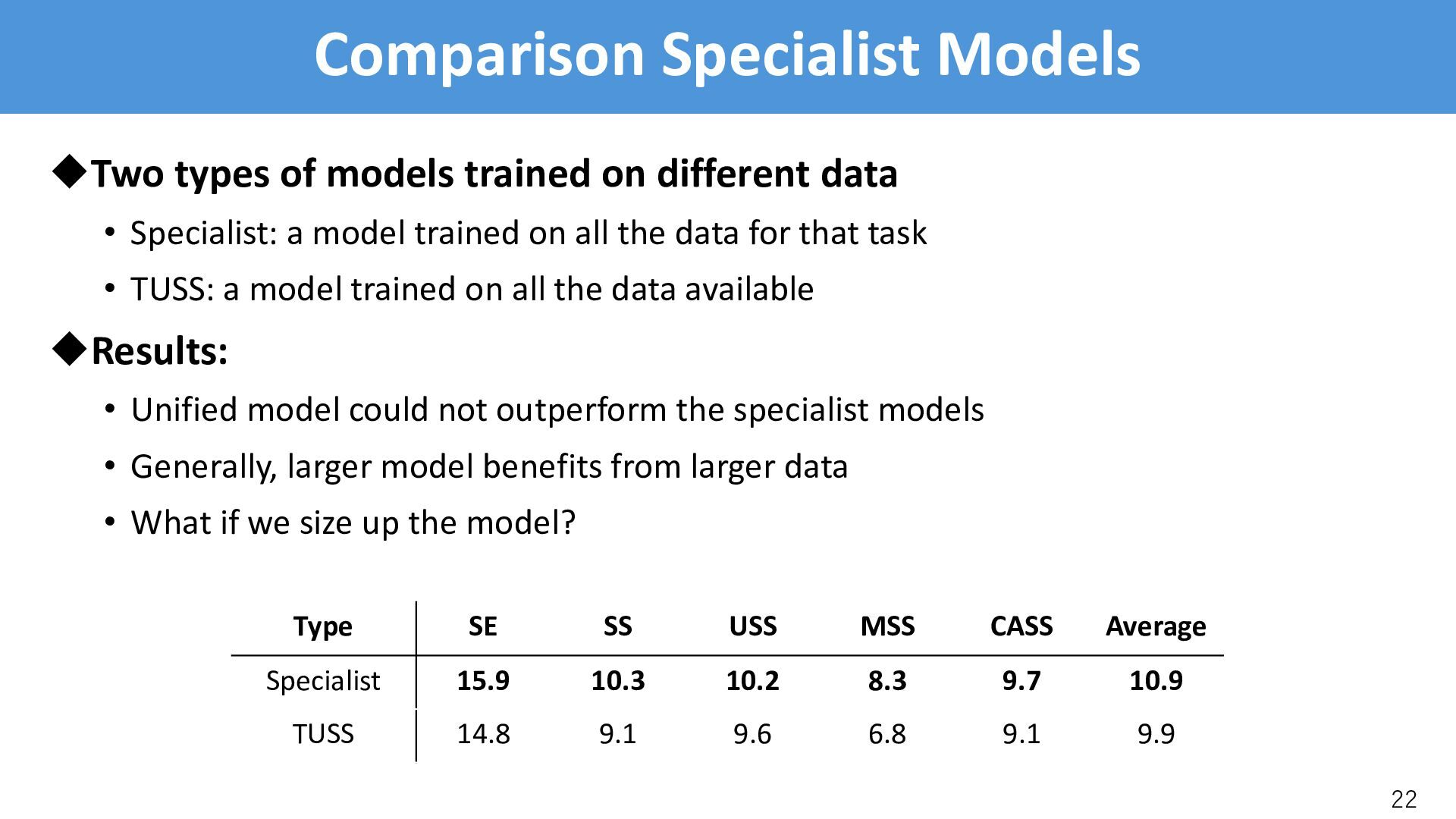
data • Specialist: a model trained on all the data for that task • TUSS: a model trained on all the data available uResults: • Unified model could not outperform the specialist models • Generally, larger model benefits from larger data • What if we size up the model? 22 Type SE SS USS MSS CASS Average Specialist 15.9 10.3 10.2 8.3 9.7 10.9 TUSS 14.8 9.1 9.6 6.8 9.1 9.9
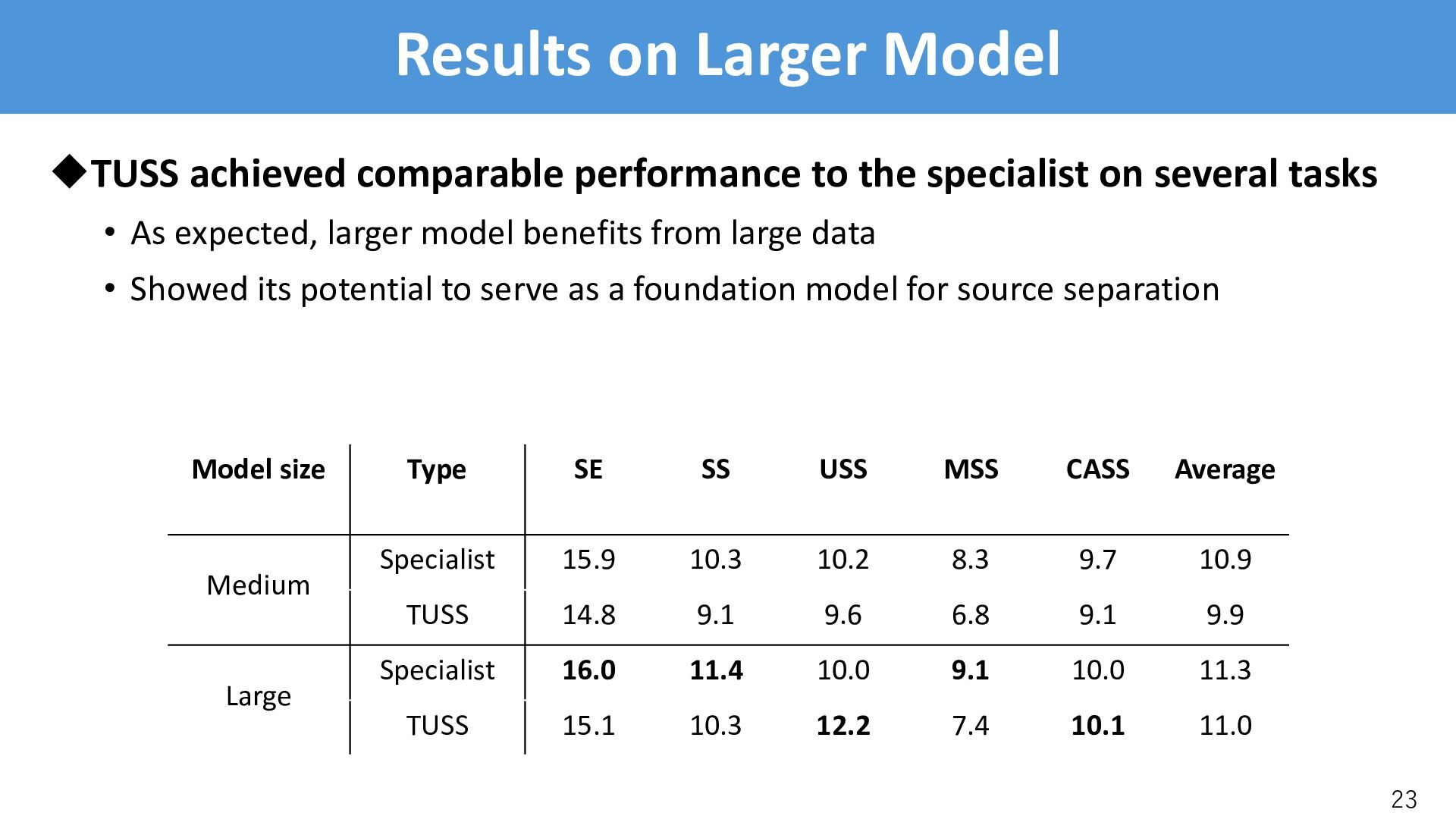
specialist on several tasks • As expected, larger model benefits from large data • Showed its potential to serve as a foundation model for source separation 23 Model size Type SE SS USS MSS CASS Average Medium Specialist 15.9 10.3 10.2 8.3 9.7 10.9 TUSS 14.8 9.1 9.6 6.8 9.1 9.9 Large Specialist 16.0 11.4 10.0 9.1 10.0 11.3 TUSS 15.1 10.3 12.2 7.4 10.1 11.0
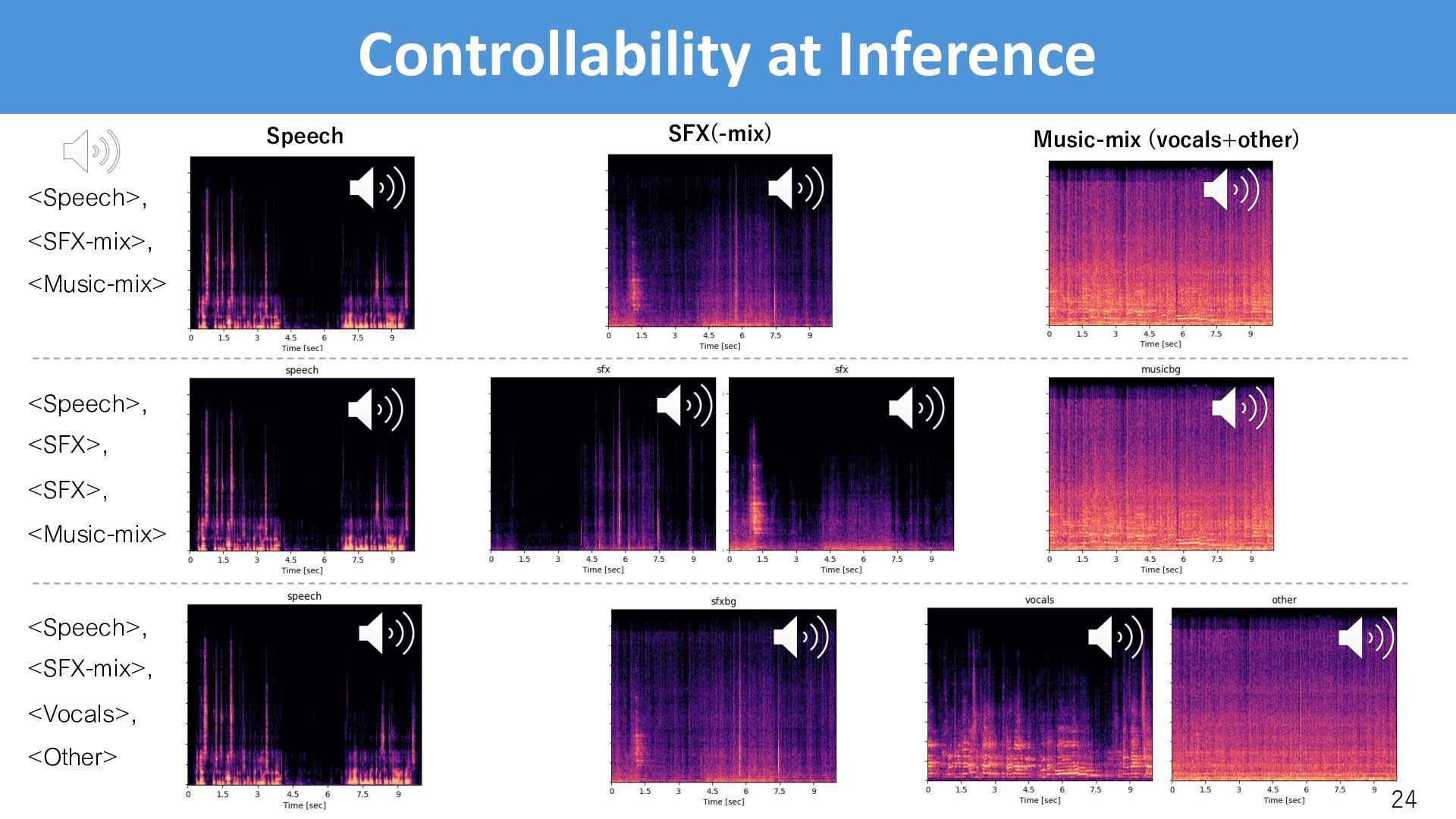
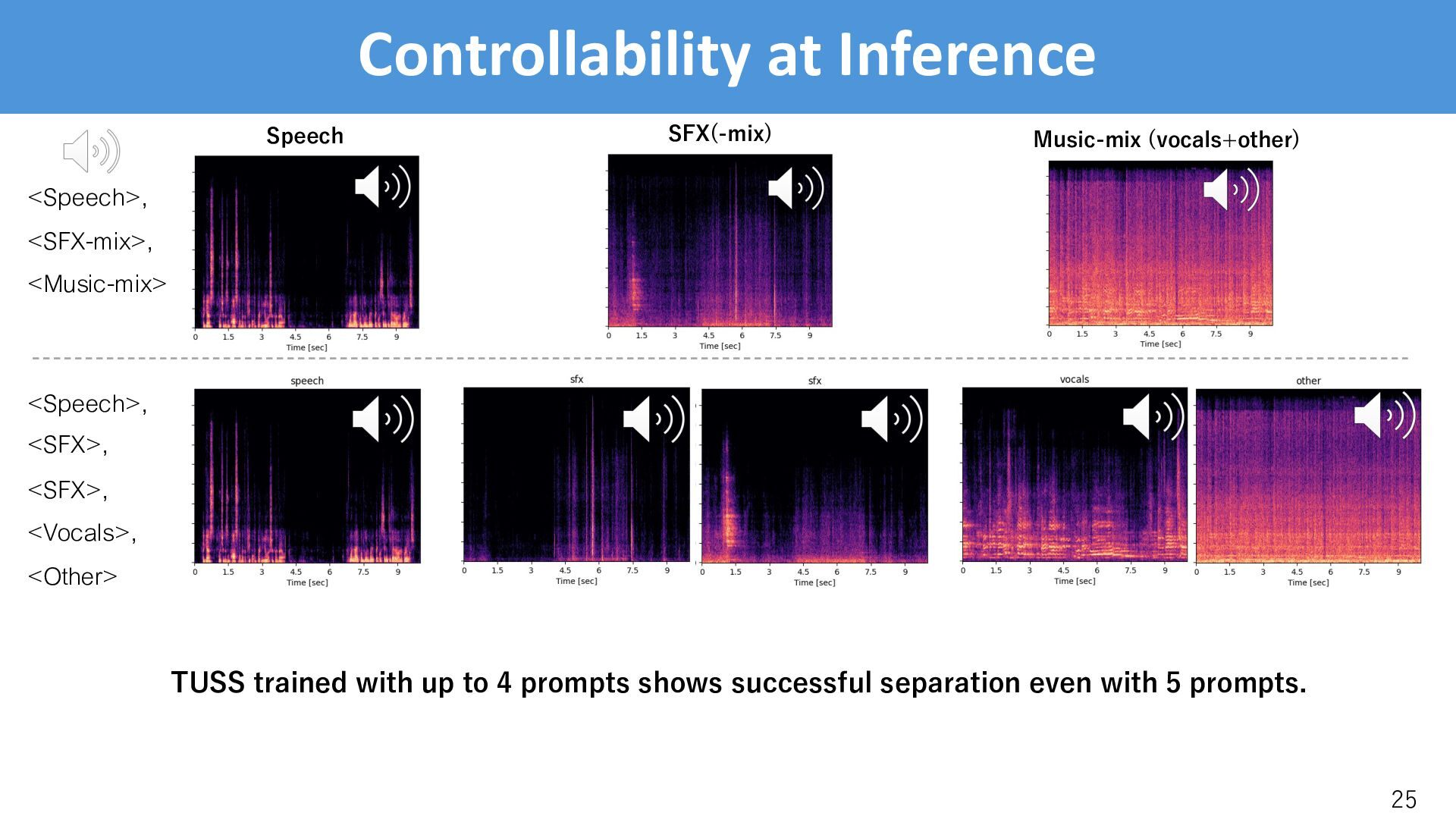
trained with up to 4 prompts shows successful separation even with 5 prompts. Speech SFX(-mix) Music-mix (vocals+other) <Speech>, <SFX-mix>, <Music-mix>
model (Chapter 3.2) • Unified source separation model based on prompting (Chapter 6.3) uEncoder/Decoder for Unified Source Separation Model • Cross-attention-based encoder/decoder for spectral feature compression (Chapter 3.3) uFuture Directions • Large-scale pre-training by unsupervised learning • Unified source separation with input universality 26
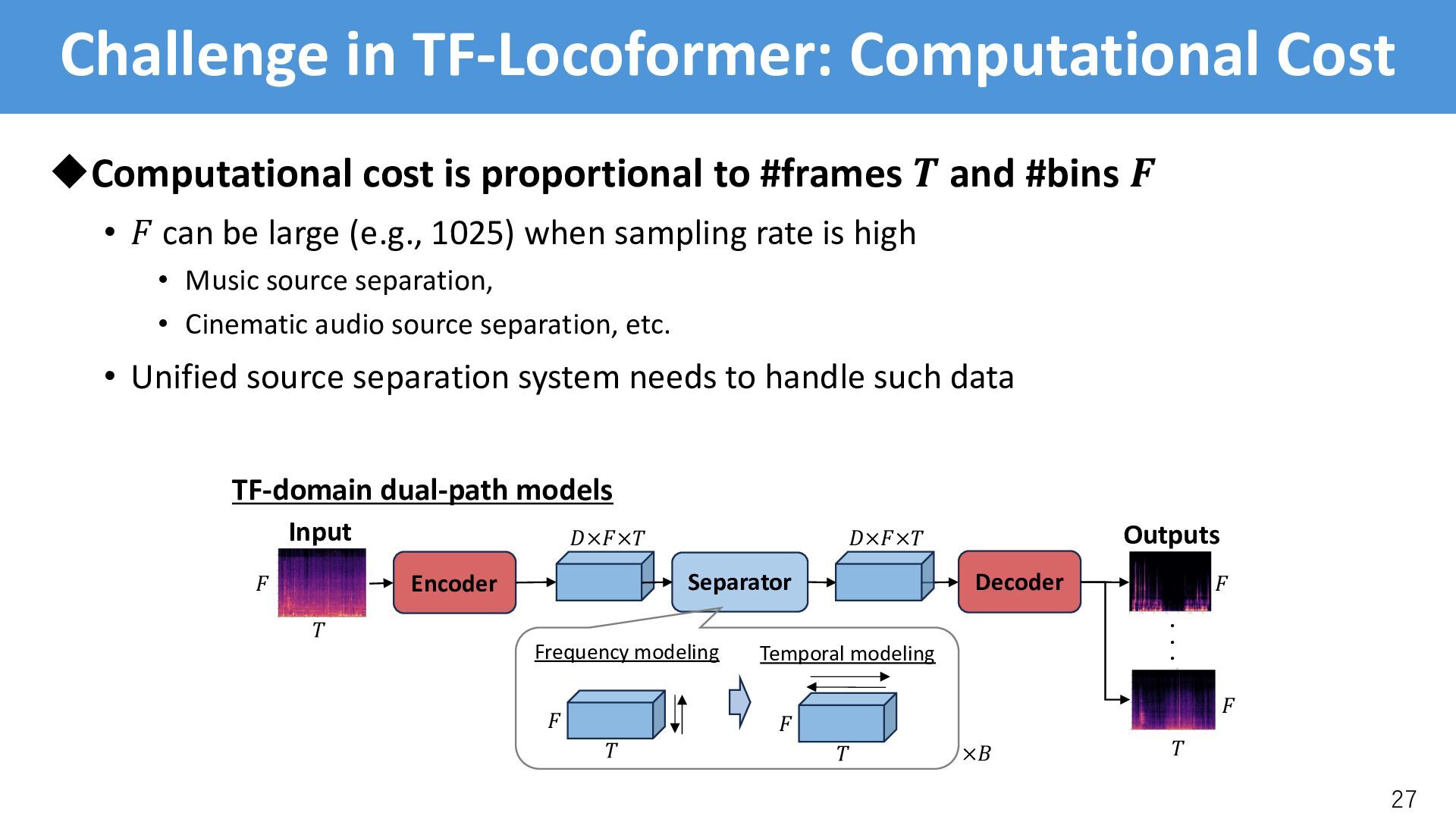
to #frames ! and #bins " • - can be large (e.g., 1025) when sampling rate is high • Music source separation, • Cinematic audio source separation, etc. • Unified source separation system needs to handle such data Encoder Separator ・ ・ ・ Input Outputs ! " #×"×! ! " Decoder TF-domain dual-path models #×"×! ! " ! " Frequency modeling Temporal modeling ×% "
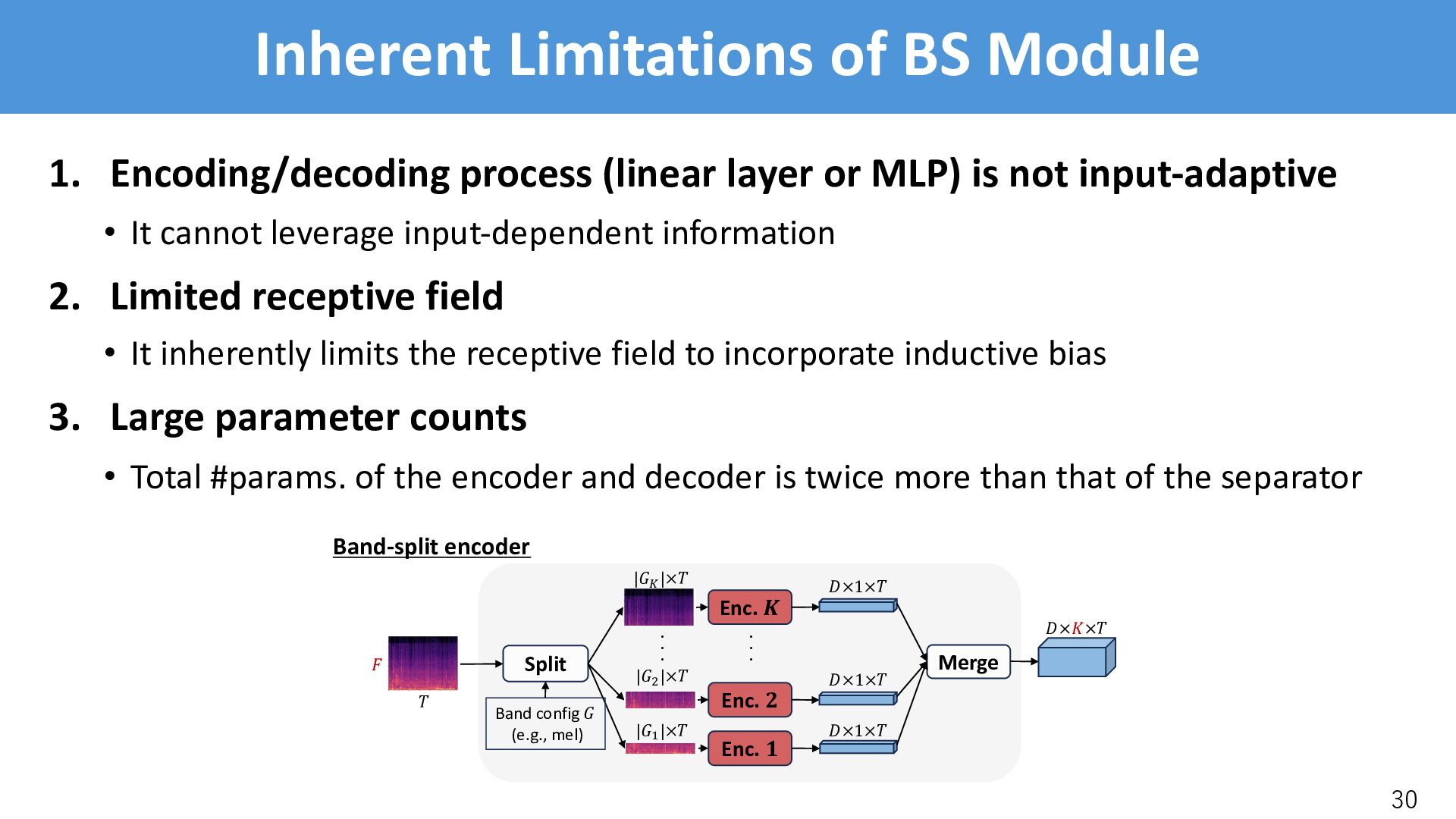
or MLP) is not input-adaptive • It cannot leverage input-dependent information 2. Limited receptive field • It inherently limits the receptive field to incorporate inductive bias 3. Large parameter counts • Total #params. of the encoder and decoder is twice more than that of the separator 30 Encoder Separator ・ ・ ・ Input Outputs ! " #×%×! ! " Decoder Split ・ ・ ・ Enc. ! Enc. " Enc. # ・ ・ ・ Merge Band-split encoder #×%×! ! " #×1×! |(! |×! #×%×! |(" |×! #×1×! #×1×! |(# |×! ! % ! % Frequency modeling Temporal modeling ×) Band config ( (e.g., mel) " TF-domain dual-path models with spectral compression
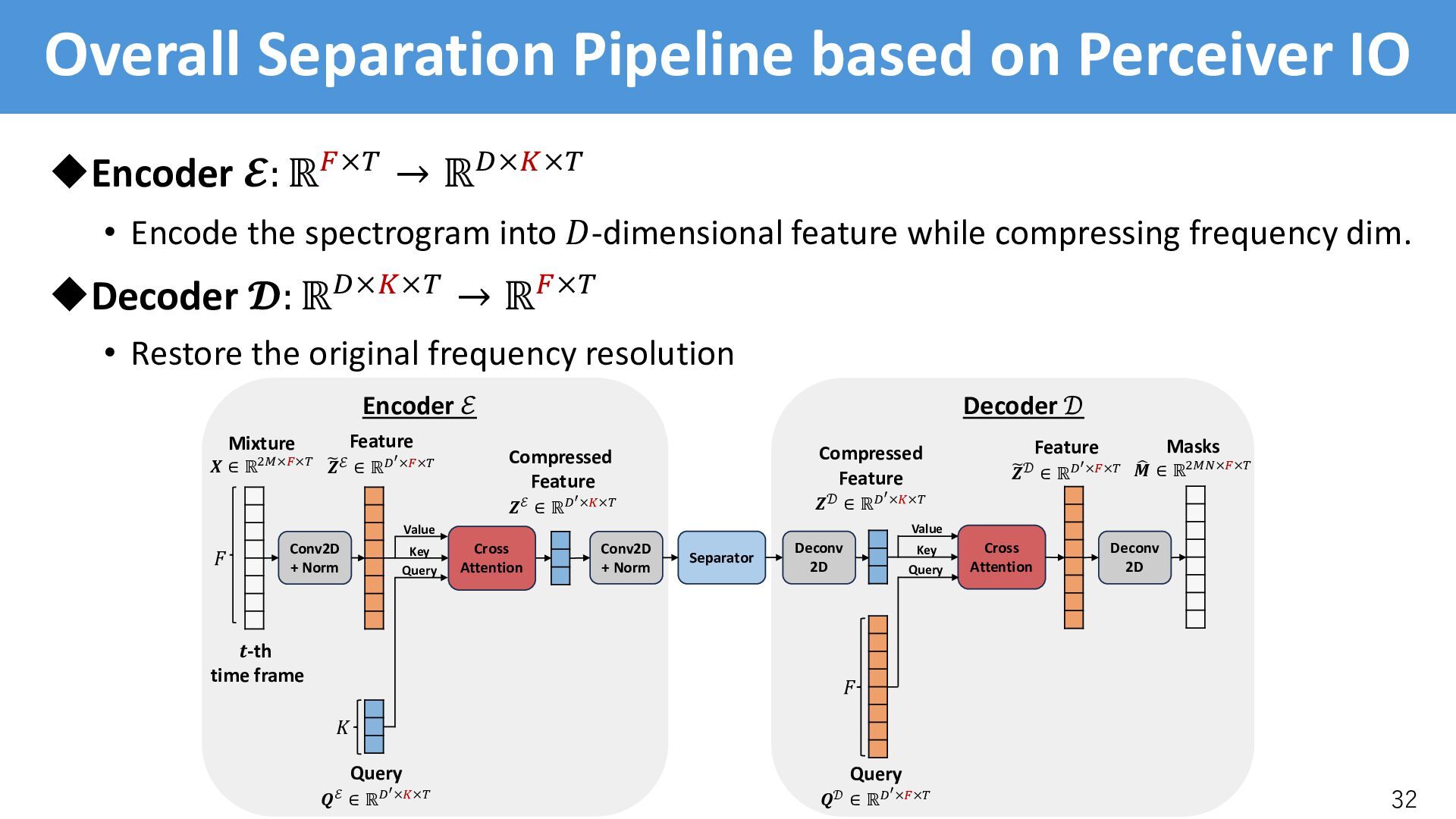
satisfies 1. Input-adaptive encoding/decoding leveraging input-dependent information 2. Unlimited receptive field 3. Small parameter counts Sequence modeling satisfies all the requirements • Cross-attention with a query of length . (Perceiver IO [Jaegle+, 2022]) 31 Sequence modeling Query ! " #×%×! #′×%×! [Jaegle +, 2022]: A. Jaegle, et. al., “Perceiver IO: A General Architecture for Structured Inputs & Outputs,” in Proc. ICLR, 2022.
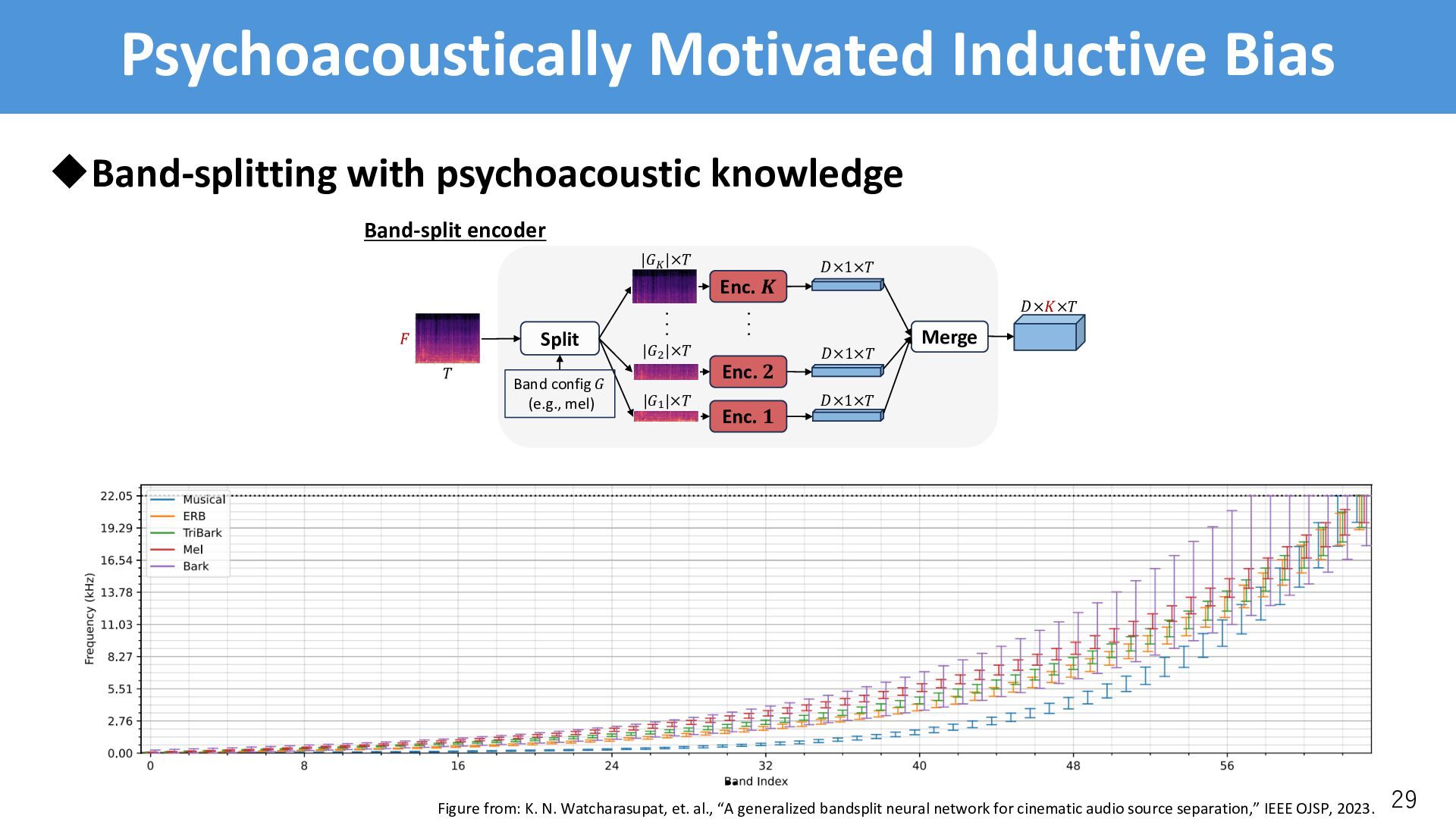
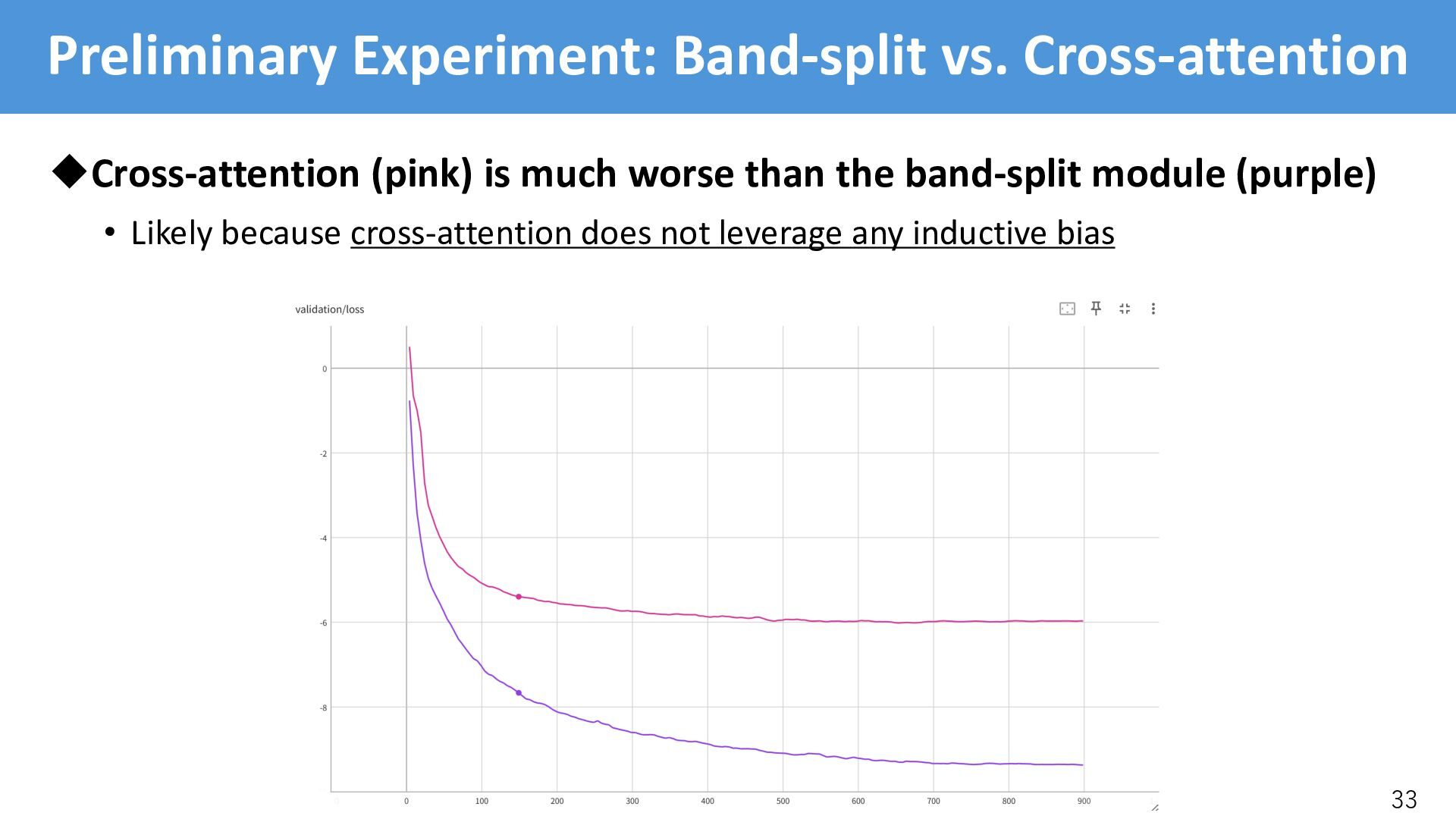
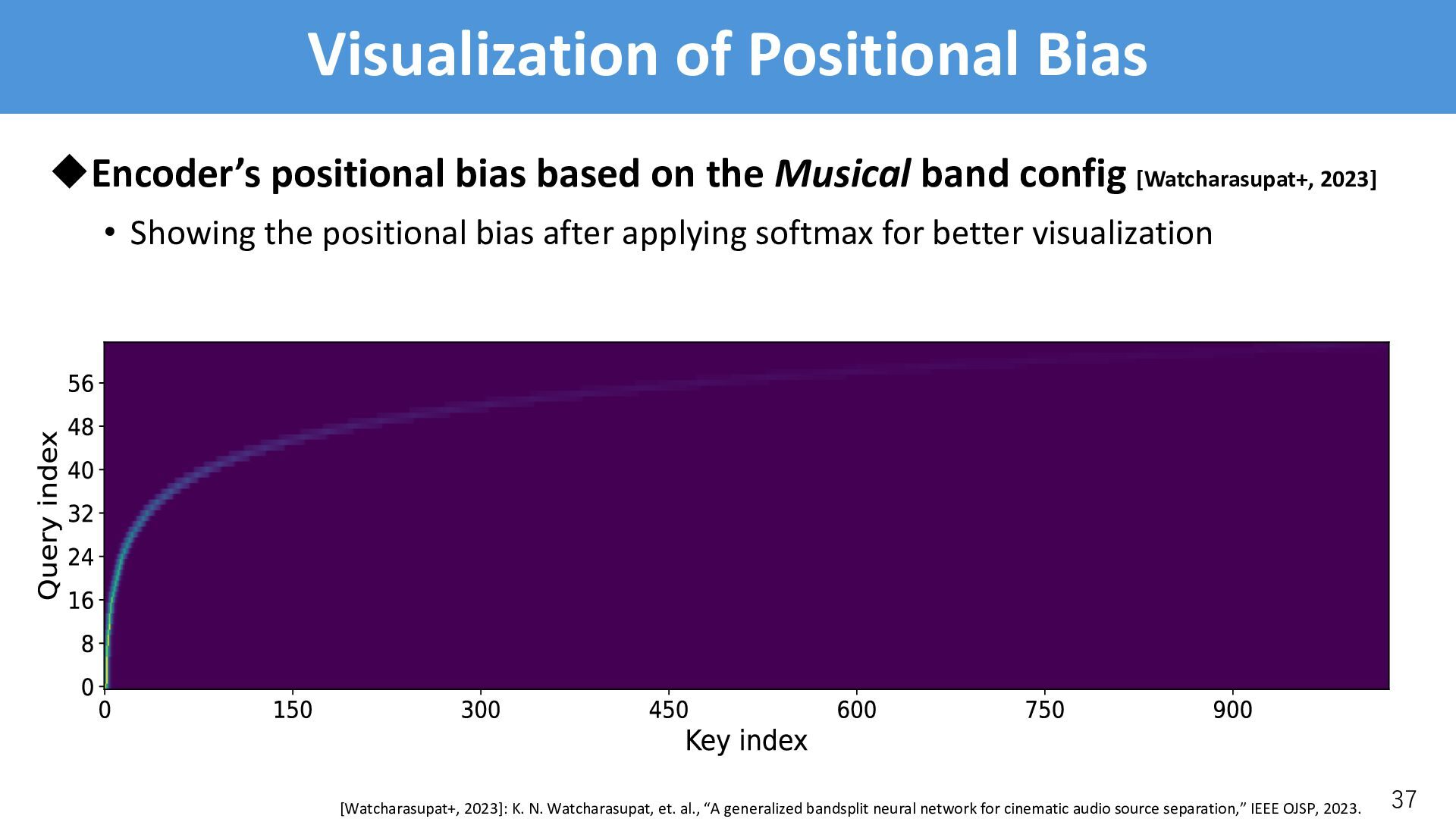
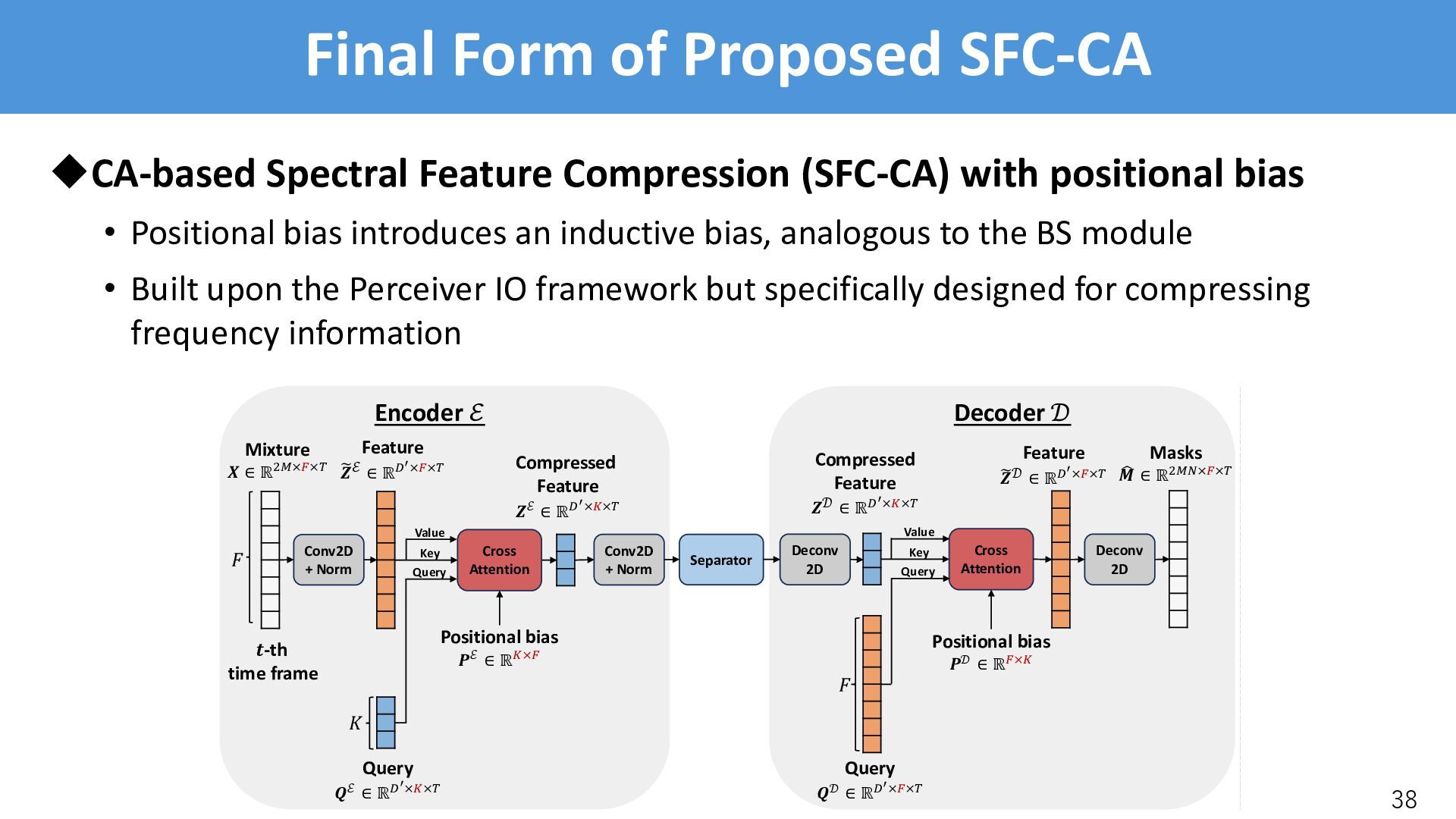
/-th encoder/decoder is in charge of the /-th band uCross-attention • The /-th query is in charge of to /-th band • Needs to learn where the /-th should attend, but the model failed uSolution • Incorporate psychoacoustically motivated inductive bias in cross-attention • Reformulate CA with a positional bias * ∈ ℝ)"×)#$ [Press+, 2022] CrossAttention(:, <, =): = softmax :<* ! + * = [Press+, 2022]: O. Press, et. al., “Train short, test long: Attention with linear biases enables input length extrapolation,” in Proc. ICLR, 2022.
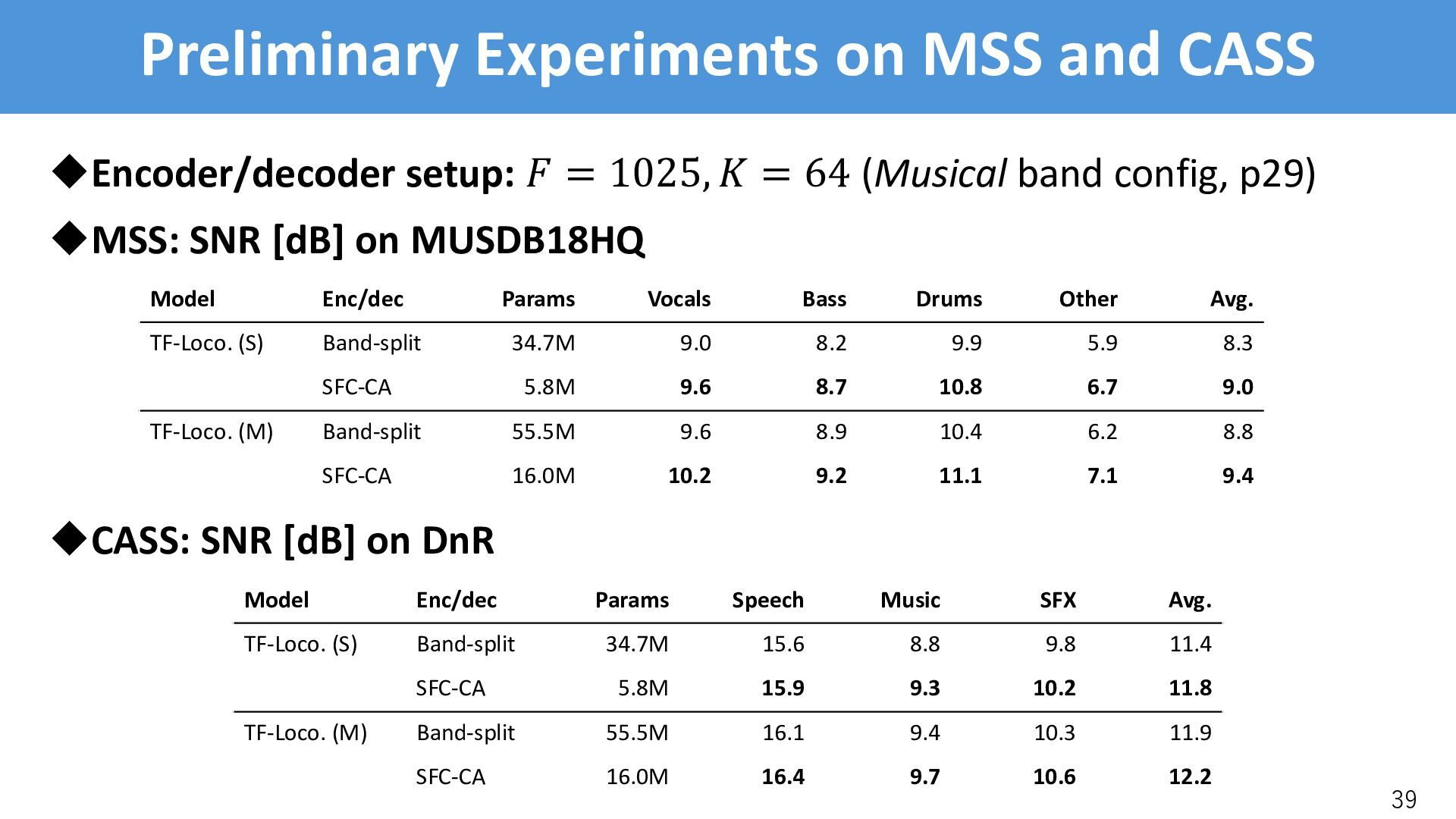
• BSRoformer’s band config: . = 61, without inter-band overlap • Musical band config: . = 64, with inter-band overlap uEvaluation on SI-SDR [dB] (except for MSS where SNR [dB] is used): • SFC-CA performs consistently better than the Band-split module 41 Enc/Dec Band config SE SS USS MSS CASS Average Band-split* BSRoformer (61) 15.2 9.0 9.1 6.8 9.1 9.8 SFC-CA BSRoformer (61) 15.4 9.1 10.6 6.8 9.2 10.2 Band-split Musical (64) 14.8 8.6 8.3 6.8 8.8 9.5 SFC-CA Musical (64) 15.5 9.2 10.4 7.2 9.3 10.3 *: The result is different from the previous slides, since batch size is smaller (8->4)
model (Chapter 3.2) • Unified source separation model based on prompting (Chapter 6.3) uEncoder/Decoder for Unified Source Separation Model • Cross-attention-based encoder/decoder for spectral feature compression (Chapter 3.3) uFuture Directions • Large-scale pre-training by unsupervised learning • Unified source separation with input universality 42
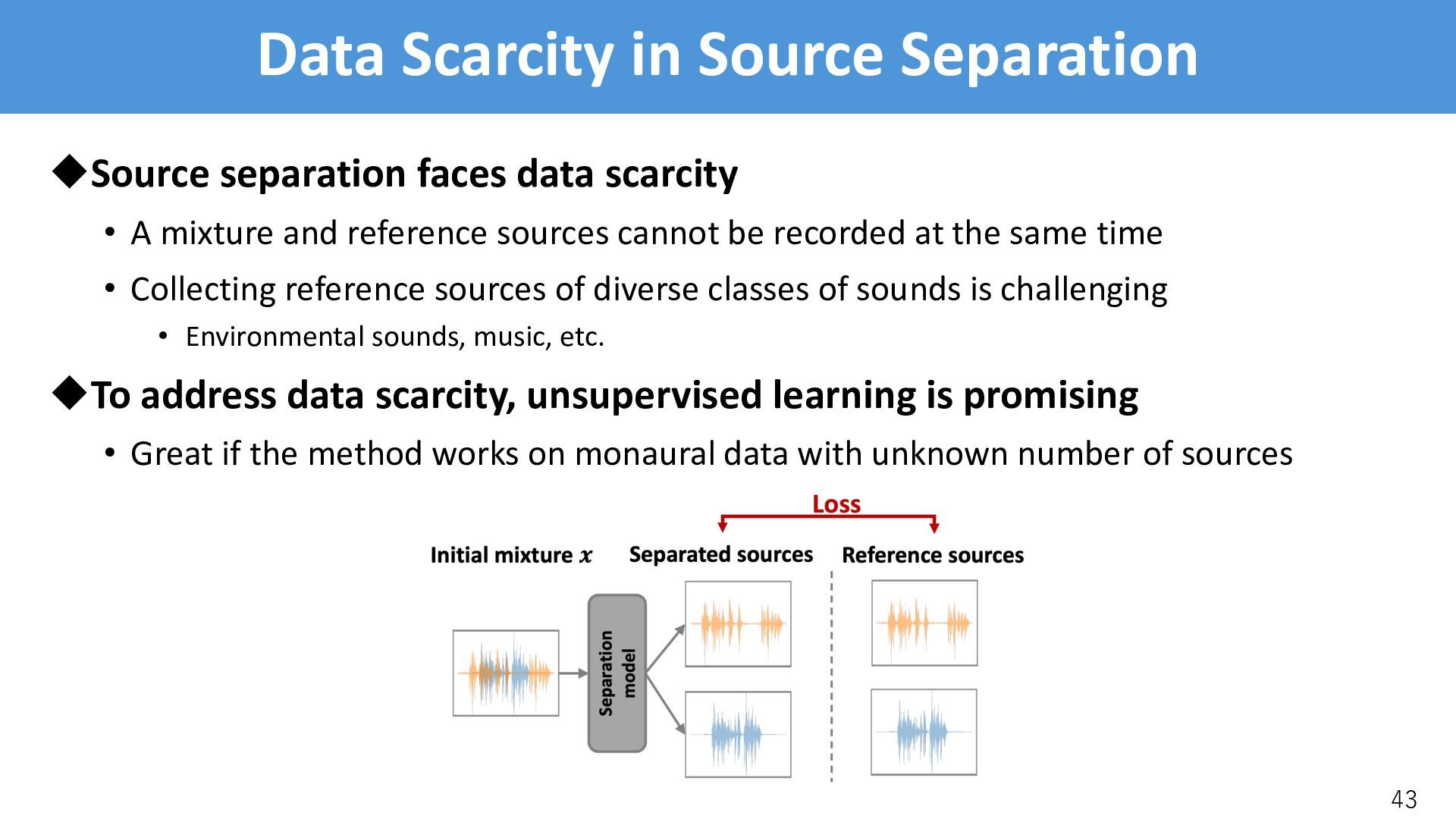
• A mixture and reference sources cannot be recorded at the same time • Collecting reference sources of diverse classes of sounds is challenging • Environmental sounds, music, etc. uTo address data scarcity, unsupervised learning is promising • Great if the method works on monaural data with unknown number of sources 43
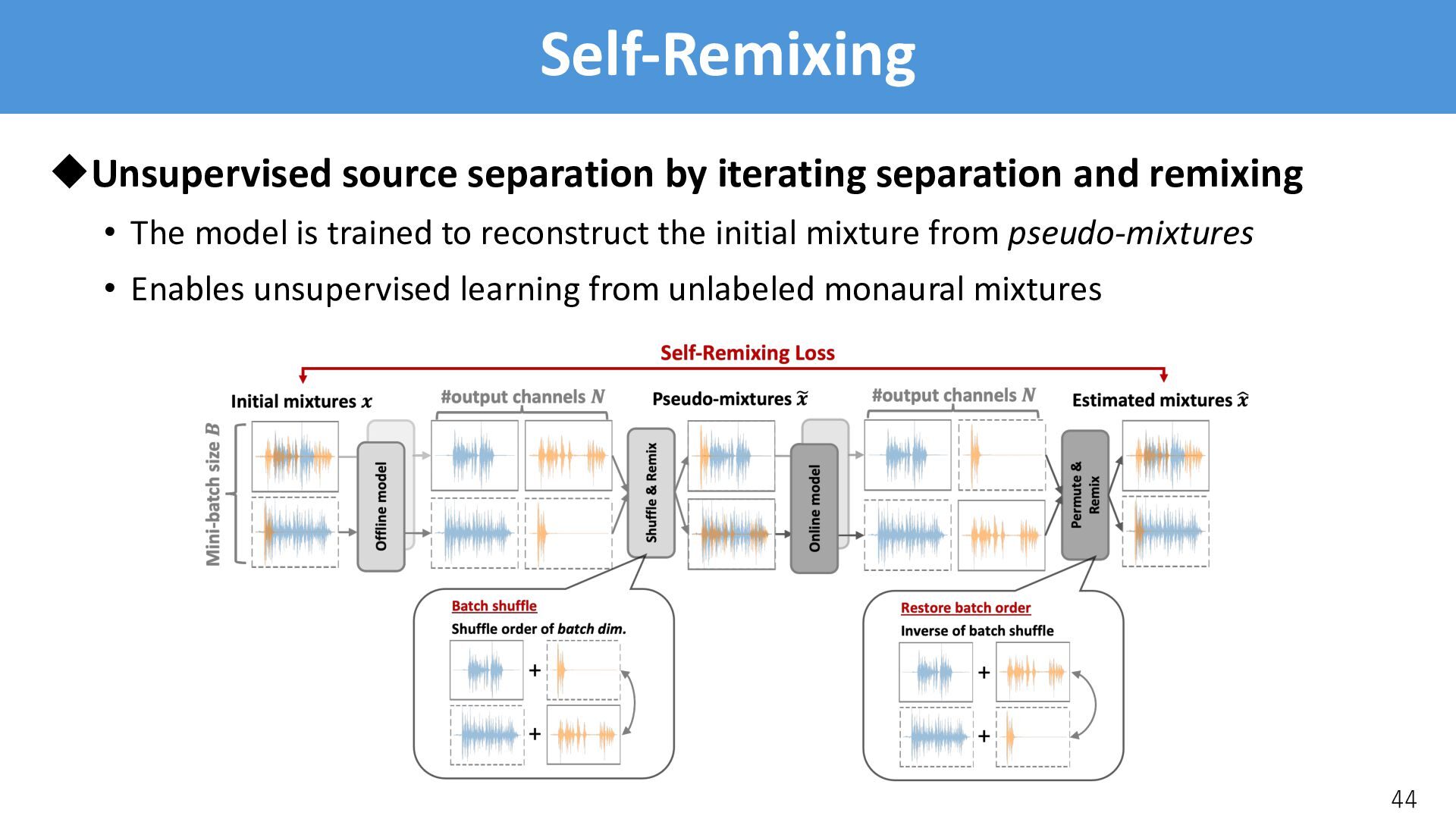
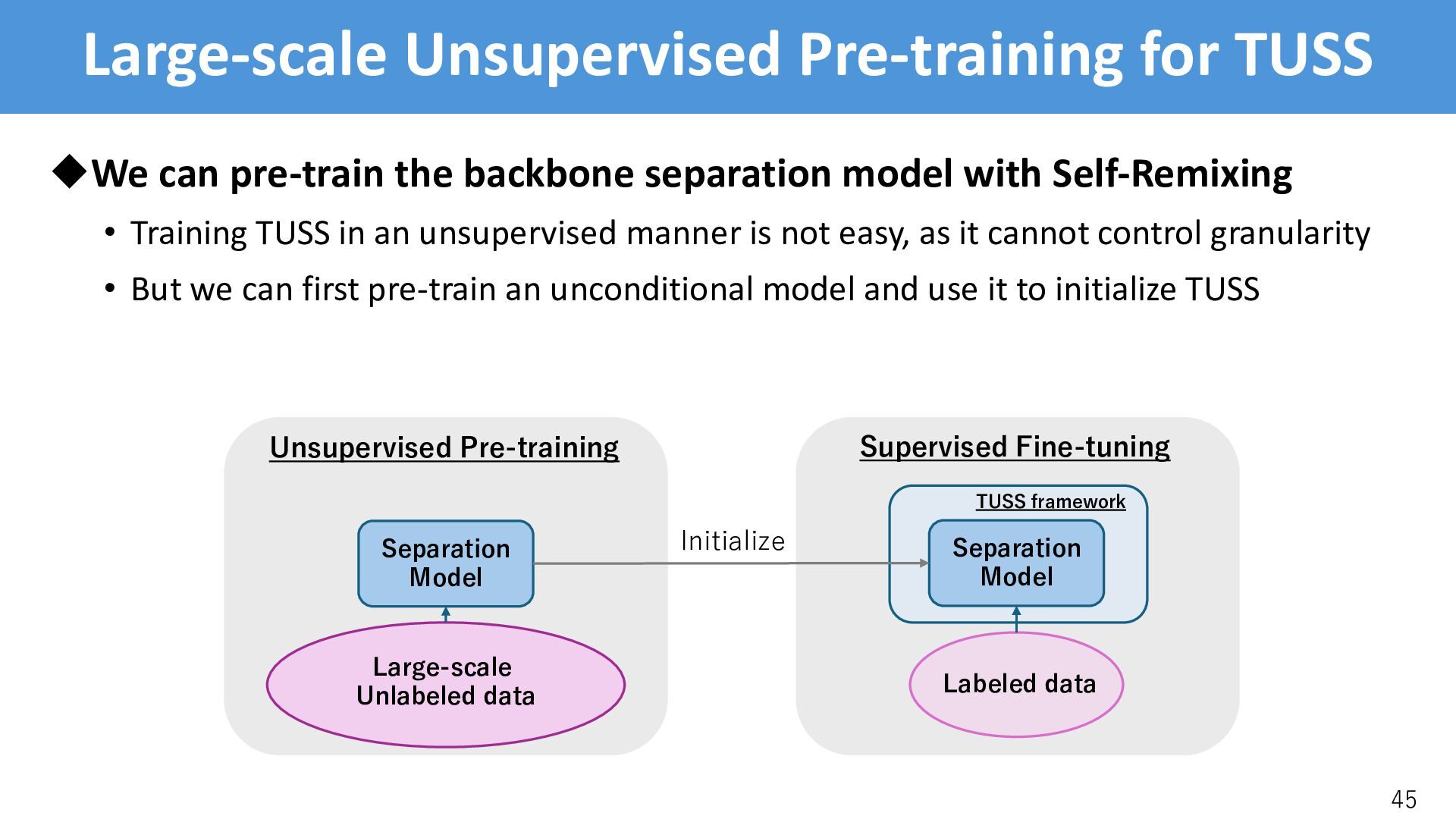
backbone separation model with Self-Remixing • Training TUSS in an unsupervised manner is not easy, as it cannot control granularity • But we can first pre-train an unconditional model and use it to initialize TUSS 45 Separation Model Unsupervised Pre-training Large-scale Unlabeled data Separation Model Supervised Fine-tuning Labeled data TUSS framework
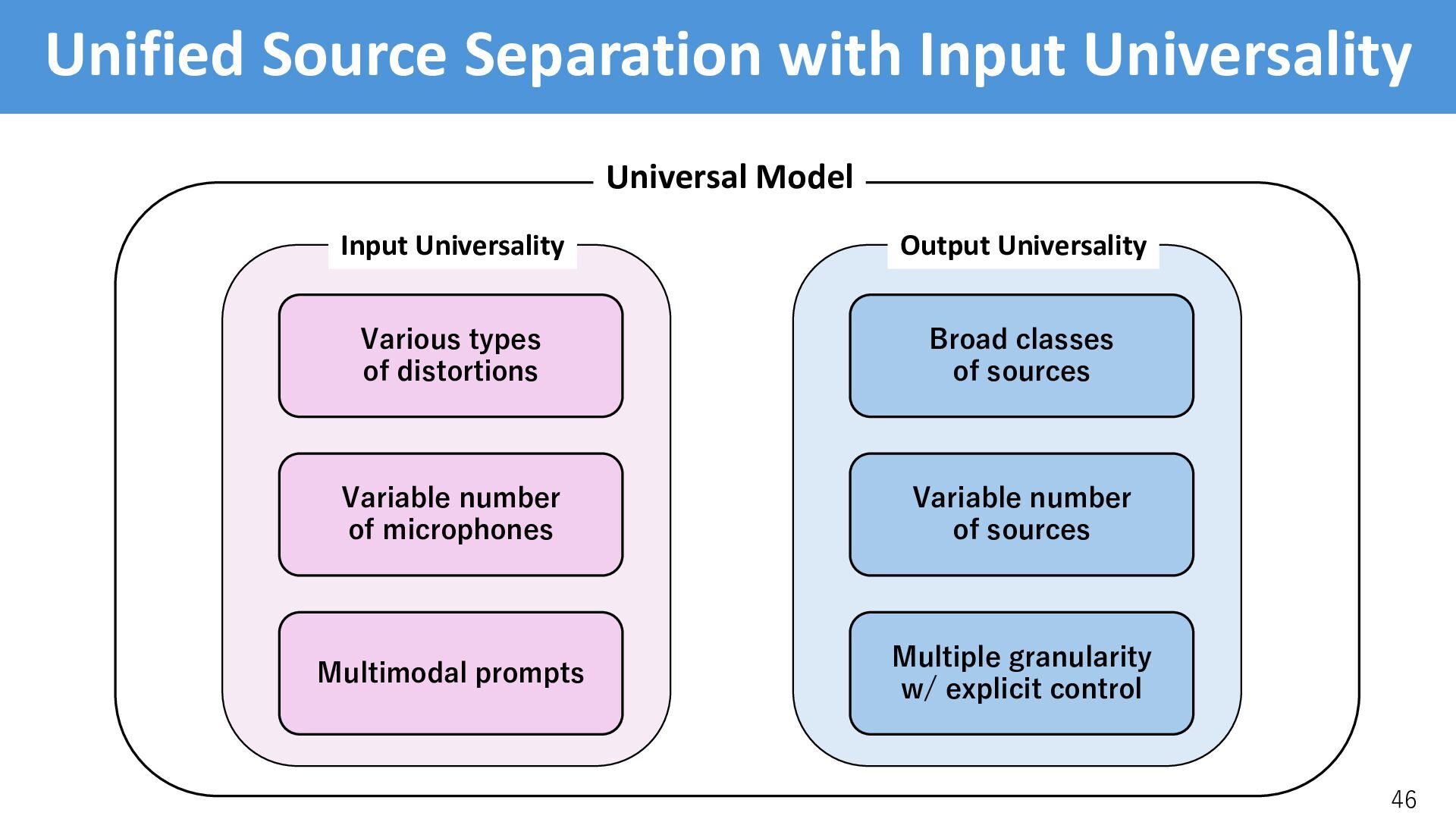
sources Multiple granularity w/ explicit control Broad classes of sources Output Universality Variable number of microphones Multimodal prompts Various types of distortions Input Universality Universal Model
and arbitrary classes of sources with controllability uApproaches • TF-Locoformer • A Transformer-based separation model which becomes the basis of TUSS • Task-aware Unified Source Separation (TUSS) • A framework to controls #sources and their granularities by prompting • Spectral Feature Compression (SFC) • Encoder/decoder to handle TF domain features efficiently uFuture directions • Large-scale unsupervised pre-training, TUSS with input universality 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Task-aware Unified Source Separation (TUSS) [Saijo+, ICASSP2025] uA model that](https://files.speakerdeck.com/presentations/077f1146e6c448288ea3eb2010e7372d/slide_14.jpg){kind=link}
![1. Encoder uSTFT-domain band-split module [Luo+, IEEE/ACM TASLP2023] • Applies](https://files.speakerdeck.com/presentations/077f1146e6c448288ea3eb2010e7372d/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Band-split (BS) encoder/decoder [Luo+, 2023] uSubband-wise encoding/decoding with # sub-encoders/sub-decoders](https://files.speakerdeck.com/presentations/077f1146e6c448288ea3eb2010e7372d/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}