Sergey Frenkel and Victor Zakharov
International Conference on Software Testing, Machine Learning and Complex Process Analysis (TMPA-2019)
7-9 November 2019, Tbilisi
Video: https://youtu.be/7xtfC0QQtcE
TMPA Conference website https://tmpaconf.org/
TMPA Conference on Facebook https://www.facebook.com/groups/tmpaconf/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
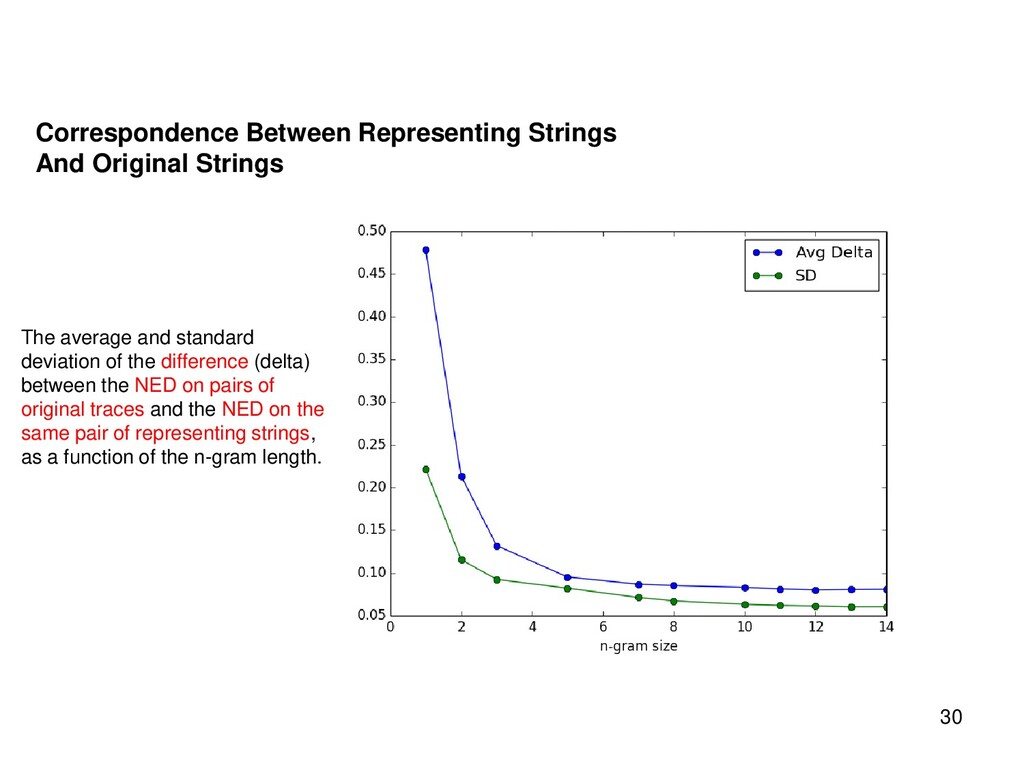{kind=link}
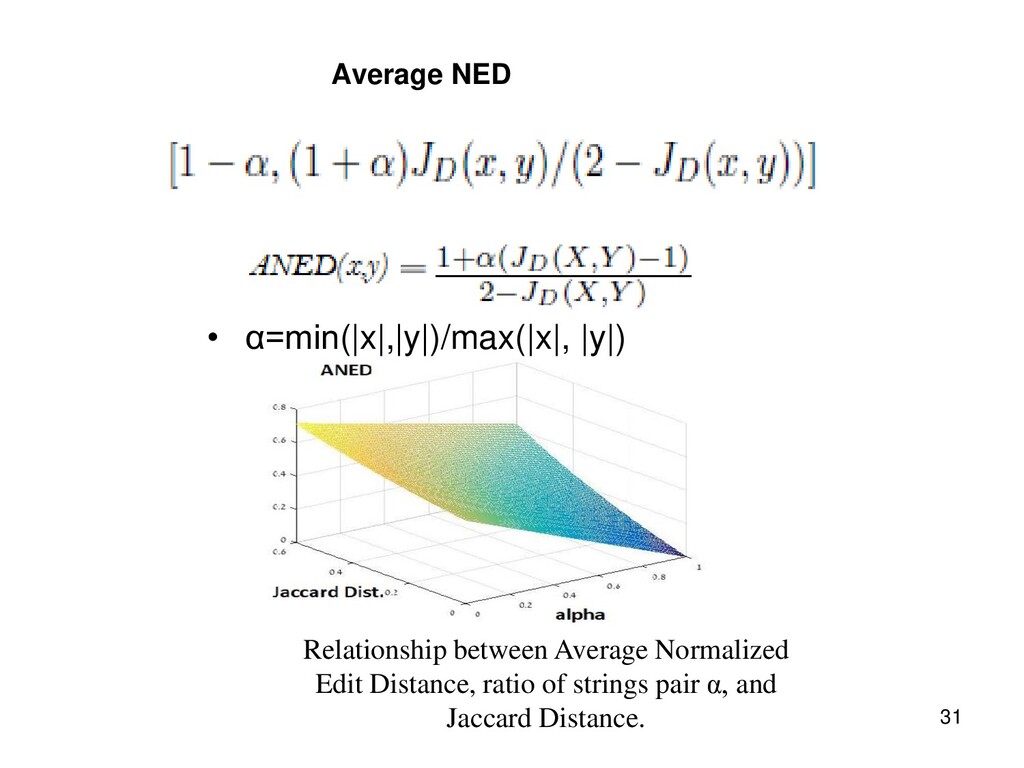{kind=link}
{kind=link}
{kind=link}
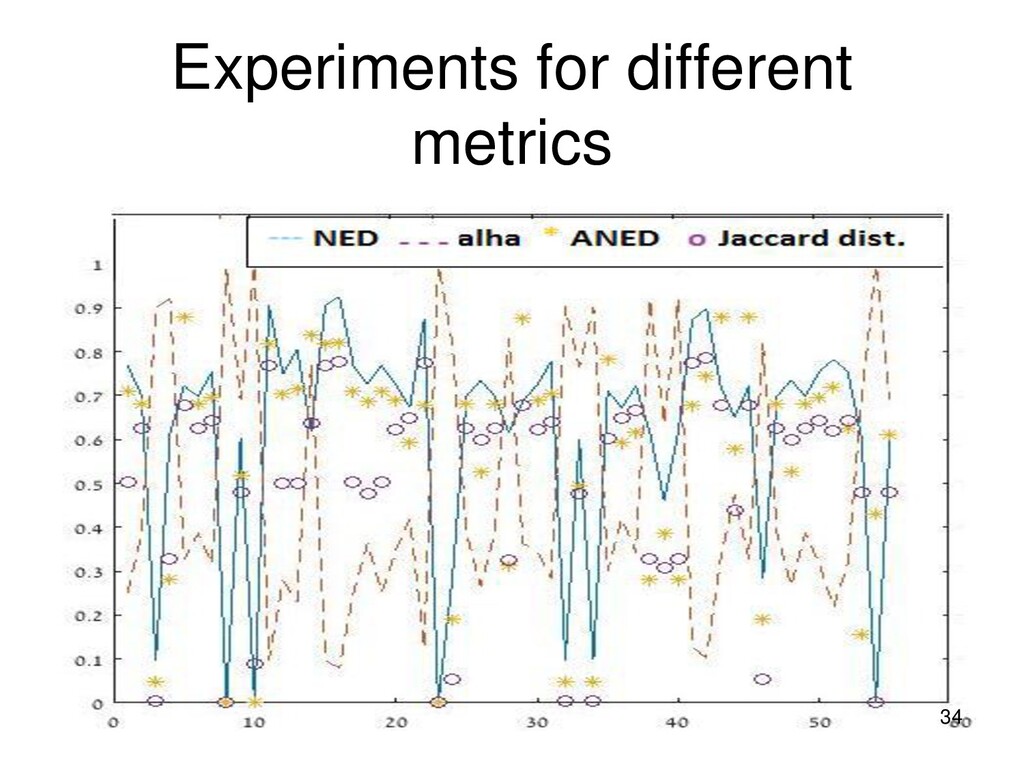{kind=link}
{kind=link}
{kind=link}
{kind=link}