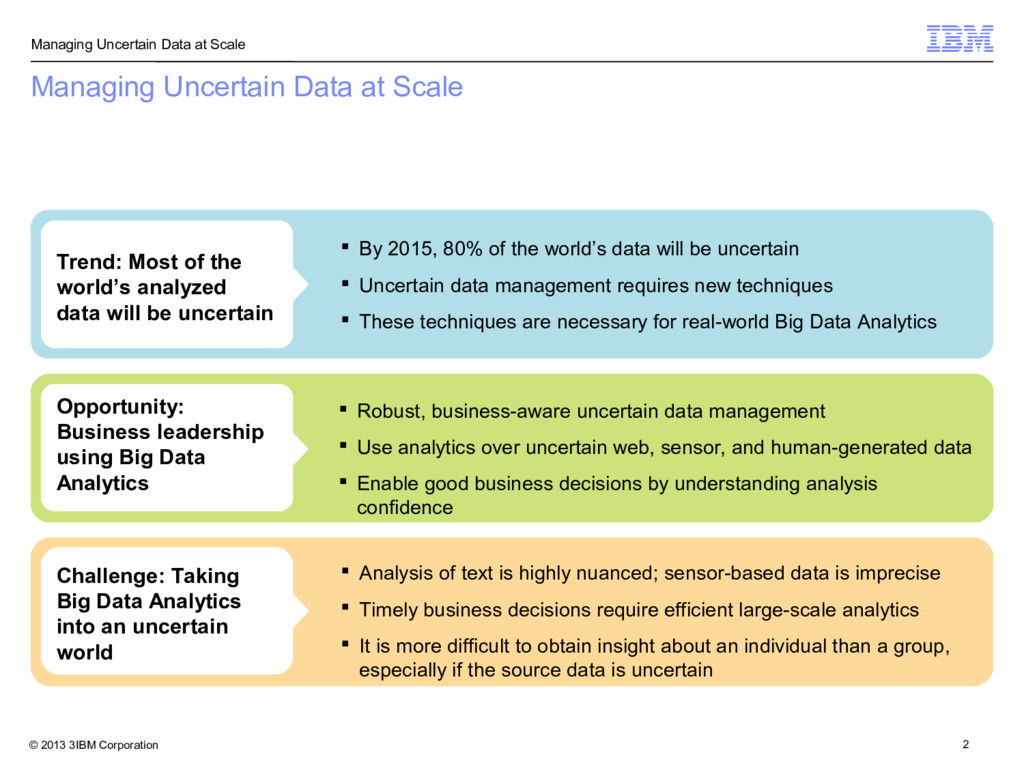
Managing Uncertain Data at Scale Trend: Most of the world’s analyzed data will be uncertain By 2015, 80% of the world’s data will be uncertain Uncertain data management requires new techniques These techniques are necessary for real-world Big Data Analytics Opportunity: Business leadership using Big Data Analytics Robust, business-aware uncertain data management Use analytics over uncertain web, sensor, and human-generated data Enable good business decisions by understanding analysis confidence Challenge: Taking Big Data Analytics into an uncertain world Analysis of text is highly nuanced; sensor-based data is imprecise Timely business decisions require efficient large-scale analytics It is more difficult to obtain insight about an individual than a group, especially if the source data is uncertain
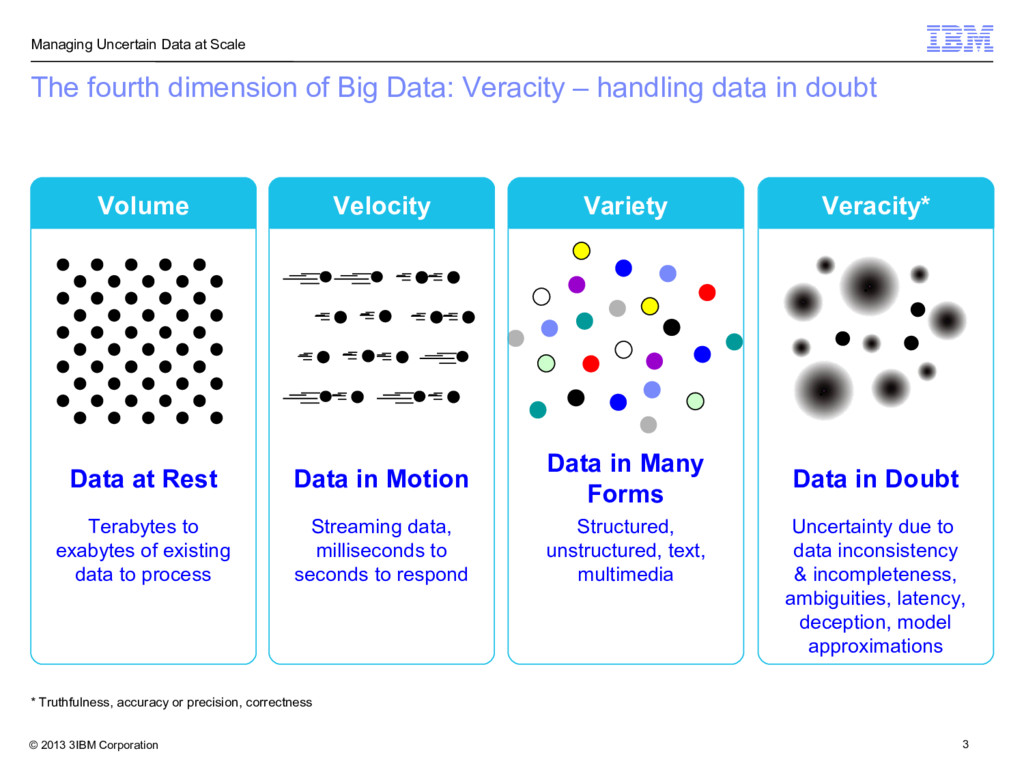
* Truthfulness, accuracy or precision, correctness The fourth dimension of Big Data: Veracity – handling data in doubt Volume Velocity Veracity* Variety Data at Rest Terabytes to exabytes of existing data to process Data in Motion Streaming data, milliseconds to seconds to respond Data in Many Forms Structured, unstructured, text, multimedia Data in Doubt Uncertainty due to data inconsistency & incompleteness, ambiguities, latency, deception, model approximations
Forecasting a hurricane (www.noaa.gov) Fitting a curve to data Model Uncertainty All modeling is approximate Process Uncertainty Processes contain “randomness” Uncertainty arises from many sources Uncertain travel times Semiconductor yield Intended Spelling Text Entry Actual Spelling GPS Uncertainty ? ? ? Rumors Contaminated? {John Smith, Dallas} {John Smith, Kansas} Data Uncertainty Data input is uncertain Ambiguity {Paris Airport} Testimony Conflicting Data ? ? ?
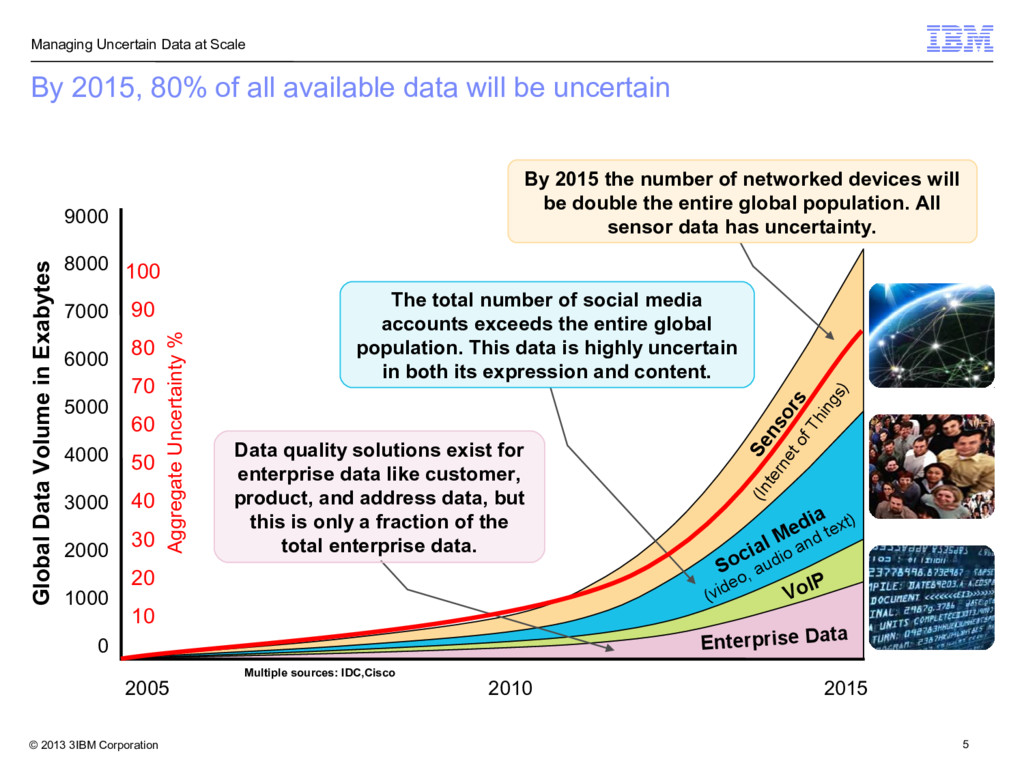
Global Data Volume in Exabytes Sensors (Internet of Things) Multiple sources: IDC,Cisco 100 90 80 70 60 50 40 30 20 10 Aggregate Uncertainty % VoIP 9000 8000 7000 6000 5000 4000 3000 2000 1000 0 2005 2010 2015 By 2015, 80% of all available data will be uncertain Enterprise Data Data quality solutions exist for enterprise data like customer, product, and address data, but this is only a fraction of the total enterprise data. By 2015 the number of networked devices will be double the entire global population. All sensor data has uncertainty. Social Media (video, audio and text) The total number of social media accounts exceeds the entire global population. This data is highly uncertain in both its expression and content.
Requires specific business process and industry context How to reduce uncertainty in processes, models, and data Constructing context for better understanding Extract as much information as feasible from each source Combine (condense) data from multiple sources More data from more sources is better – Gathers more evidence for statistical methods Using statistical methods scaled for Big Data Stochastic techniques efficiently reason about uncertainty Monte Carlo techniques explore many possible scenarios in order to gain insight
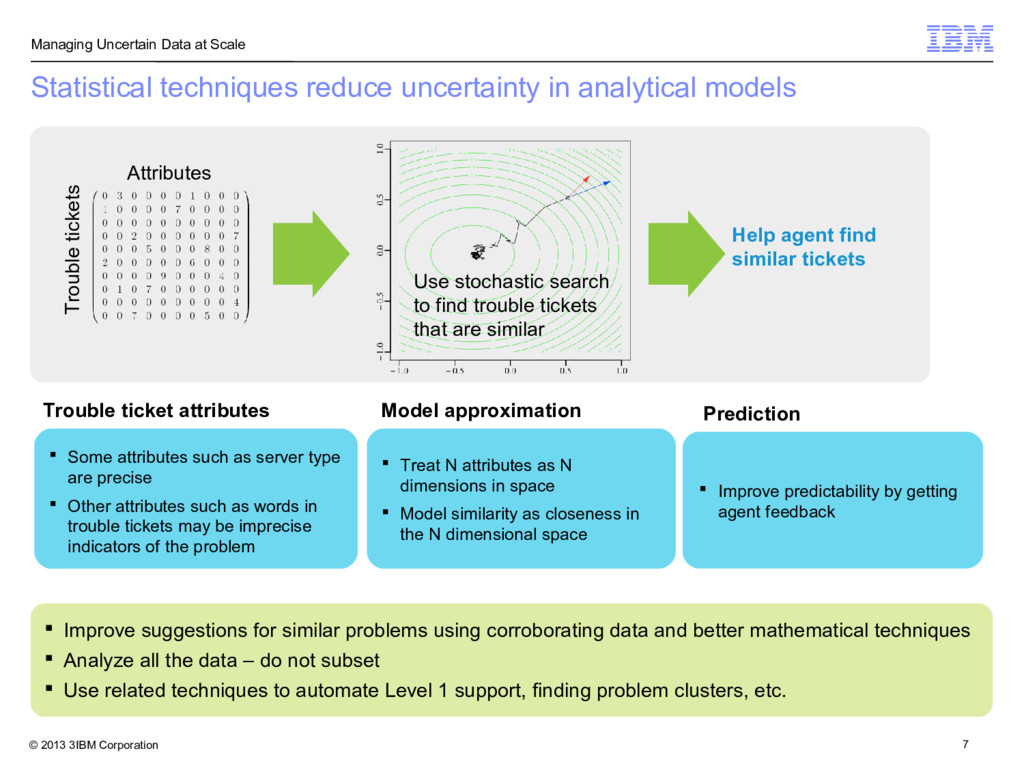
Attributes Trouble tickets Help agent find similar tickets Improve suggestions for similar problems using corroborating data and better mathematical techniques Analyze all the data – do not subset Use related techniques to automate Level 1 support, finding problem clusters, etc. Use stochastic search to find trouble tickets that are similar Trouble ticket attributes Some attributes such as server type are precise Other attributes such as words in trouble tickets may be imprecise indicators of the problem Model approximation Treat N attributes as N dimensions in space Model similarity as closeness in the N dimensional space Prediction Improve predictability by getting agent feedback Statistical techniques reduce uncertainty in analytical models
Analytics is broadly defined as the use of data and computation to make smart decisions Data Historical Simulated Text Video, Images Audio Data instances Reports and queries on data aggregates Predictive models Answers and confidence Feedback and learning Decision point Possible outcomes Option 1 Option 2 Option 3
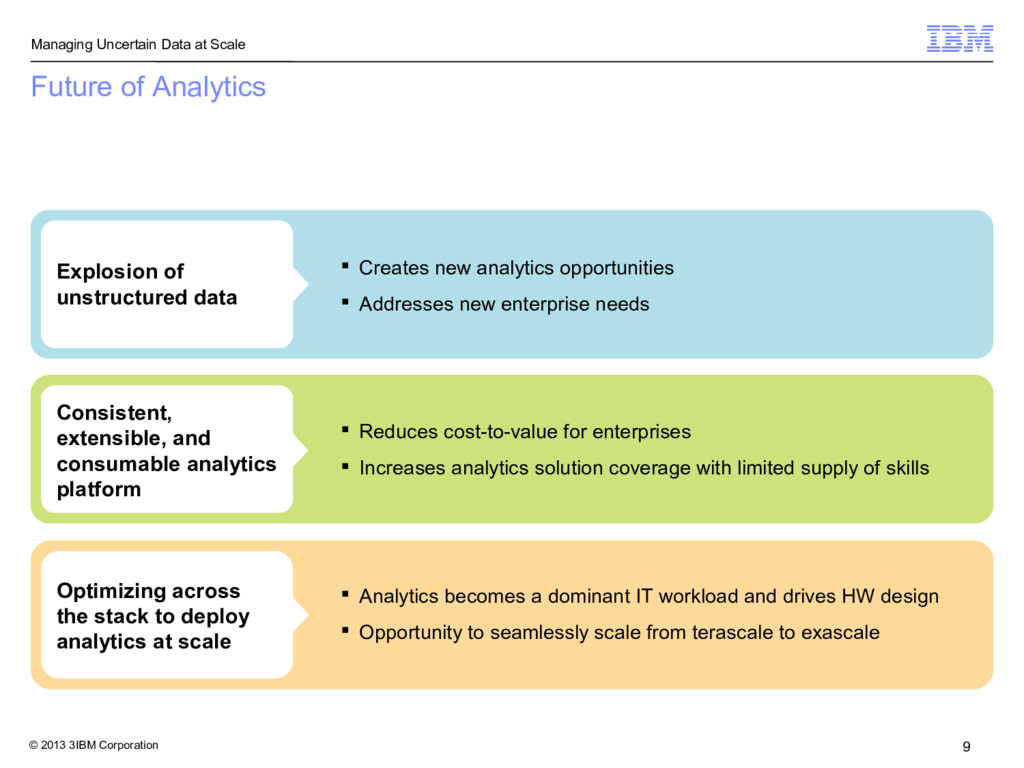
Future of Analytics Explosion of unstructured data Creates new analytics opportunities Addresses new enterprise needs Consistent, extensible, and consumable analytics platform Reduces cost-to-value for enterprises Increases analytics solution coverage with limited supply of skills Optimizing across the stack to deploy analytics at scale Analytics becomes a dominant IT workload and drives HW design Opportunity to seamlessly scale from terascale to exascale
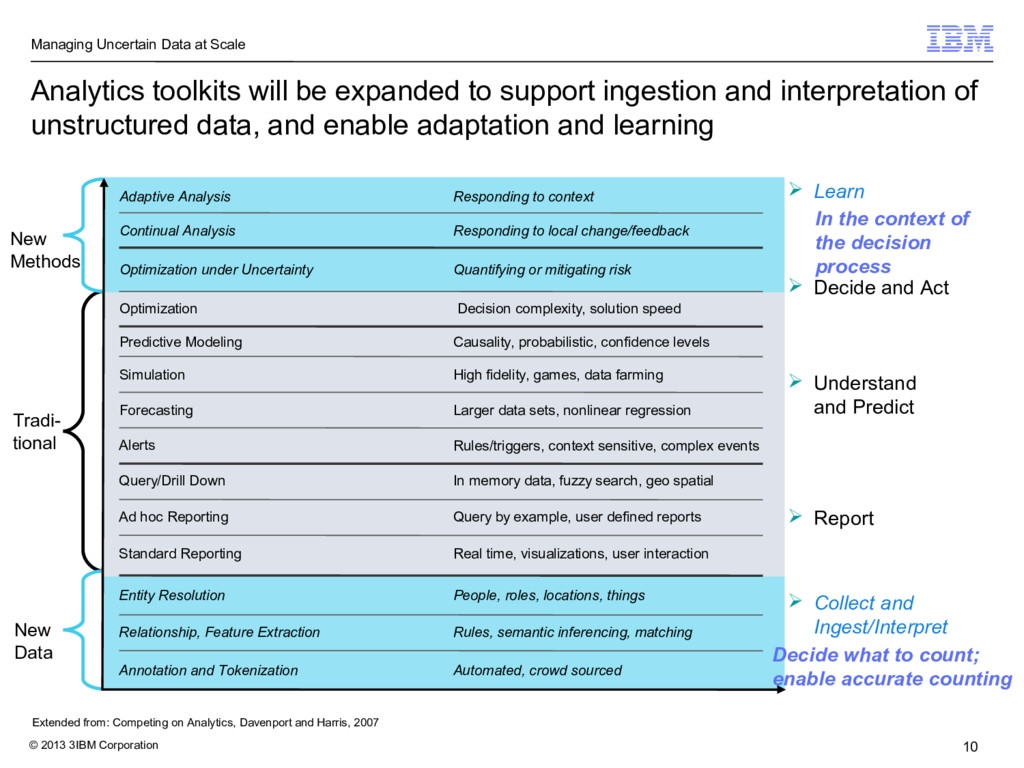
Analytics toolkits will be expanded to support ingestion and interpretation of unstructured data, and enable adaptation and learning Extended from: Competing on Analytics, Davenport and Harris, 2007 Standard Reporting Ad hoc Reporting Query/Drill Down Alerts Forecasting Simulation Predictive Modeling In memory data, fuzzy search, geo spatial Causality, probabilistic, confidence levels High fidelity, games, data farming Larger data sets, nonlinear regression Rules/triggers, context sensitive, complex events Query by example, user defined reports Real time, visualizations, user interaction Report Decide and Act Understand and Predict Collect and Ingest/Interpret Learn Optimization Optimization under Uncertainty Decision complexity, solution speed Quantifying or mitigating risk Adaptive Analysis Continual Analysis Responding to local change/feedback Responding to context Entity Resolution Annotation and Tokenization Relationship, Feature Extraction People, roles, locations, things Rules, semantic inferencing, matching Automated, crowd sourced Decide what to count; enable accurate counting In the context of the decision process Tradi- tional New Methods New Data
Finally...what about a longer term view.... say the next 10-50 years? 1. Artificial Intelligence 2. Nano –“everything” 3. Cognitive Computing 4. Deep (Exascale) Computing 5. Automic & Quantum Computing 6. Human / Computer Interaction 7. Machine to Machine Interaction 8. BioTech / Human Augmentation 9. Robots & Robotics 10. Advanced / Predictive Analytics 11. Security & Privacy 12. 3-D Printing 13. Video-enabled Business Processes 14. Personalized Web/Assistants 15. Ubiquitous Computing 16. Gaming 17. Simulation 18. Virtual Computing (including virtual worlds, tele-presence, etc.) 19. Augmented Reality IBM Academy of Technology and Global Technology Outlook can help you find some answers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}