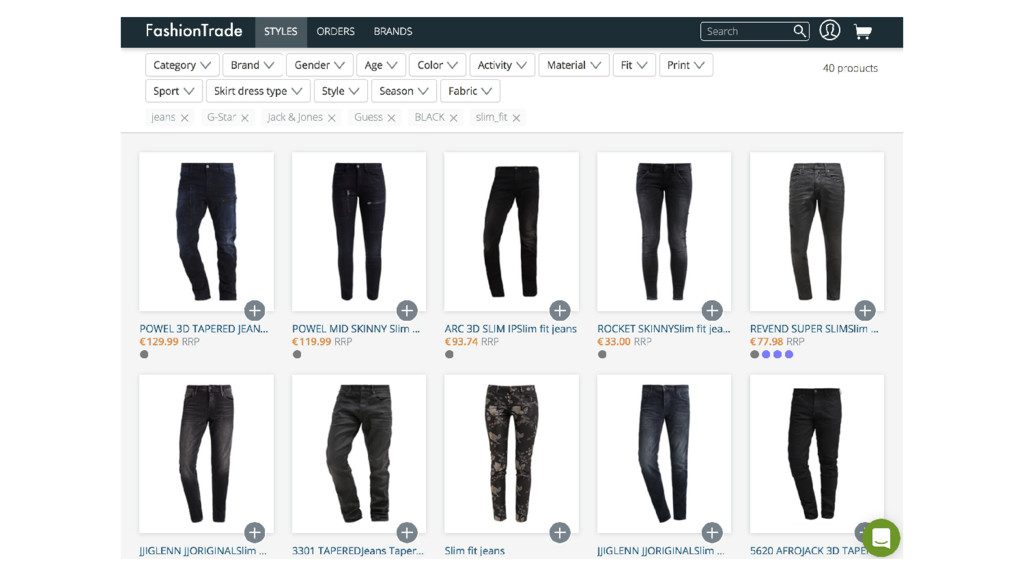
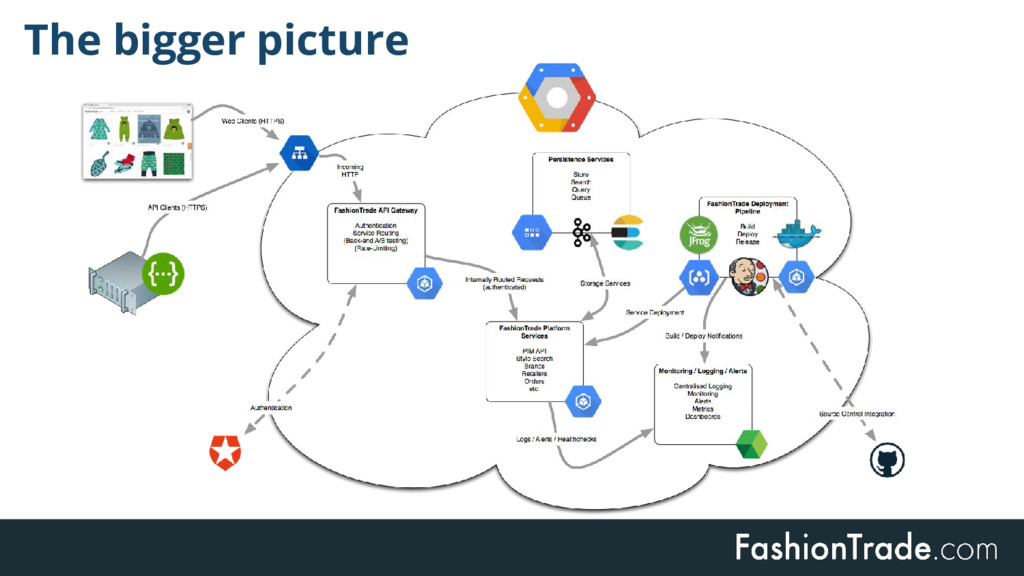
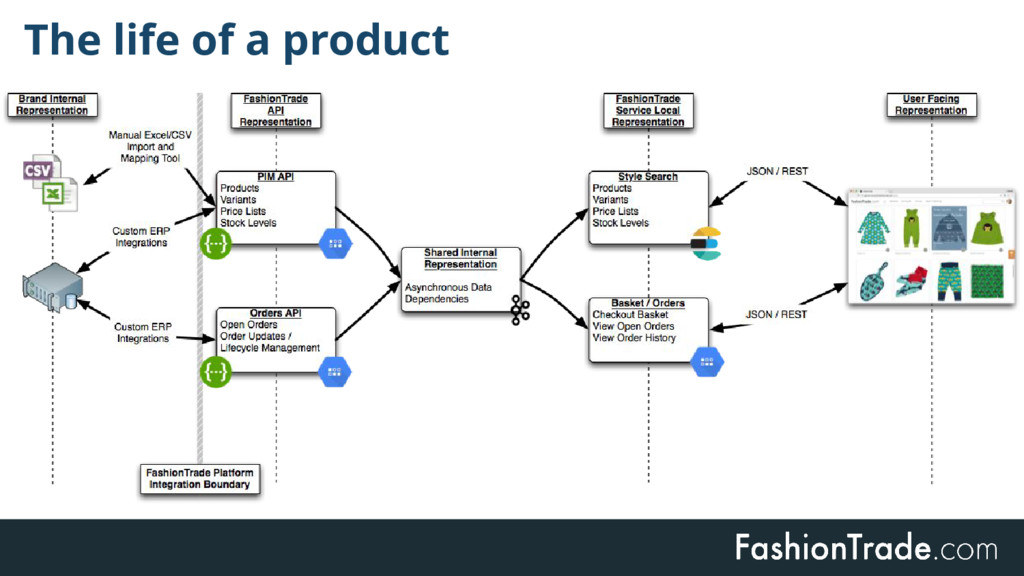
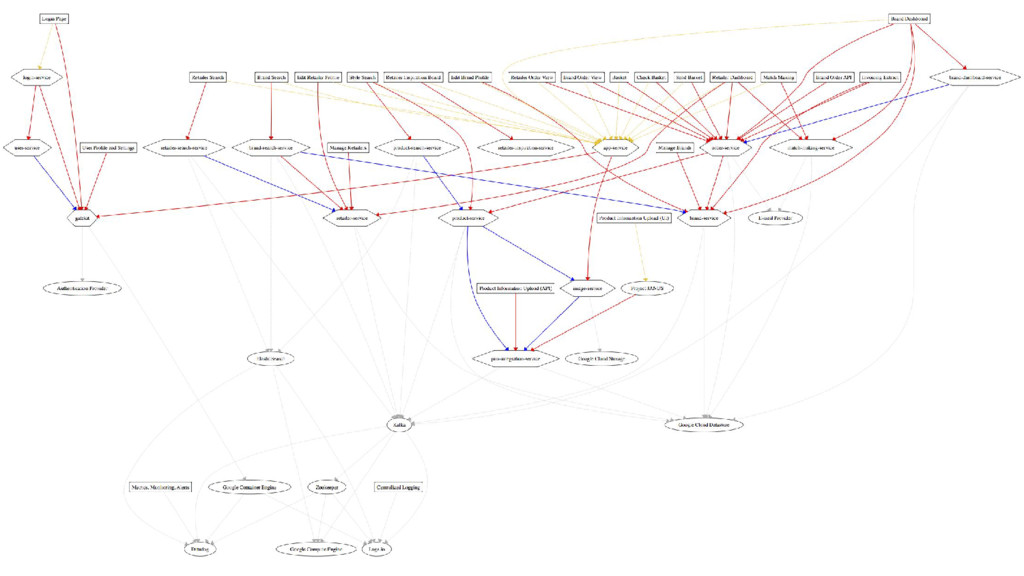
At FashionTrade we use (micro-)services which are independently deployed and maintained. We rely heavily on Kafka based logs for distribution of data. A key design goal is that services build up local state in service specific representations. In this talk we'll go into the conceptual and implementation details of several approaches to typical challenges in log and event based setups, including schema changes, staleness, decoupling and mixing asynchronous with synchronous dependencies. In the end we will elaborate on the implementation choices that we made to strive for a healthy tradeoff between simplicity and correctness of design.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS ! www.fashiontrade.com | [email protected]](https://files.speakerdeck.com/presentations/26a9e6e3d5864a88a1d685318e23eaac/slide_45.jpg){kind=link}