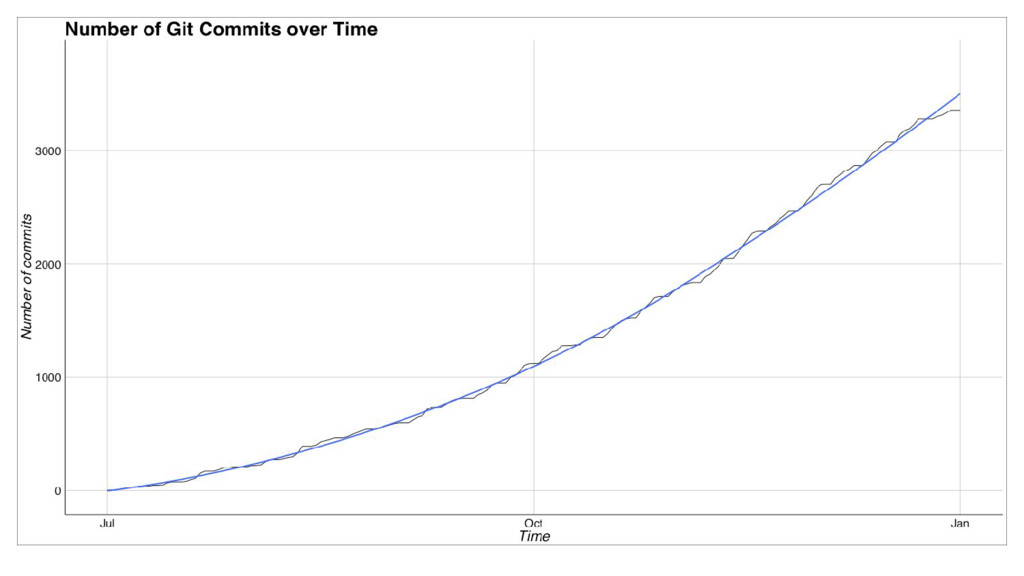
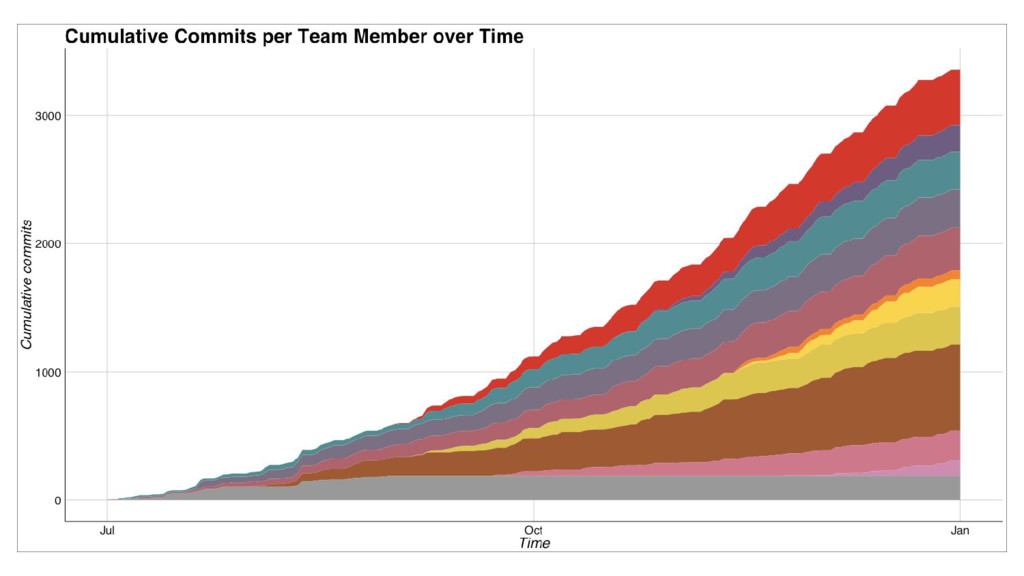
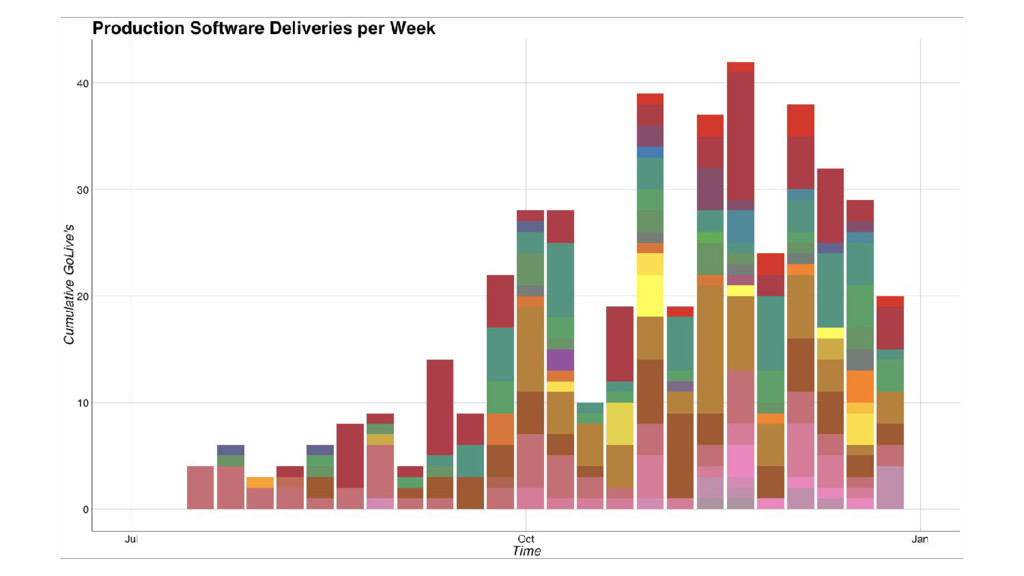
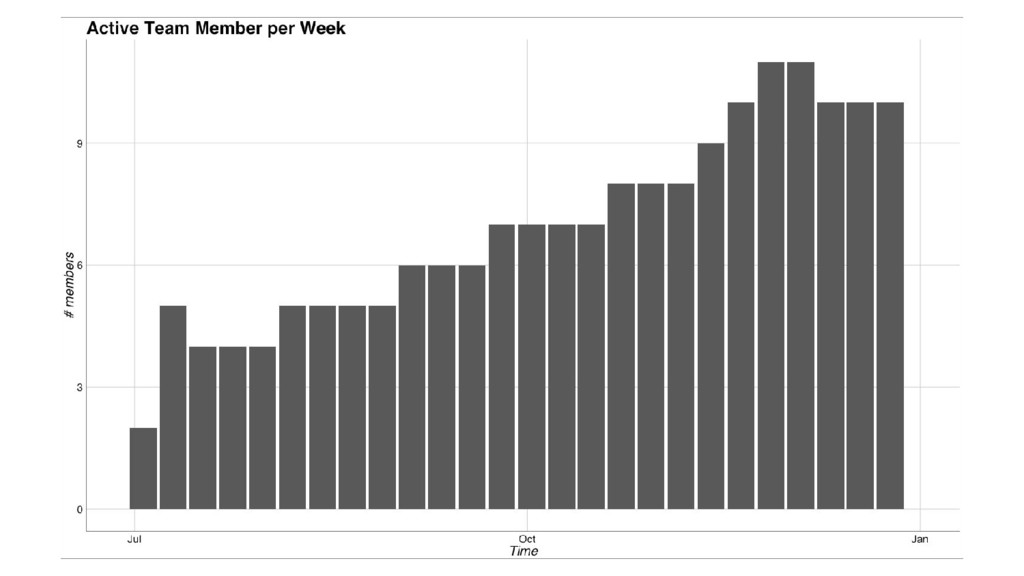
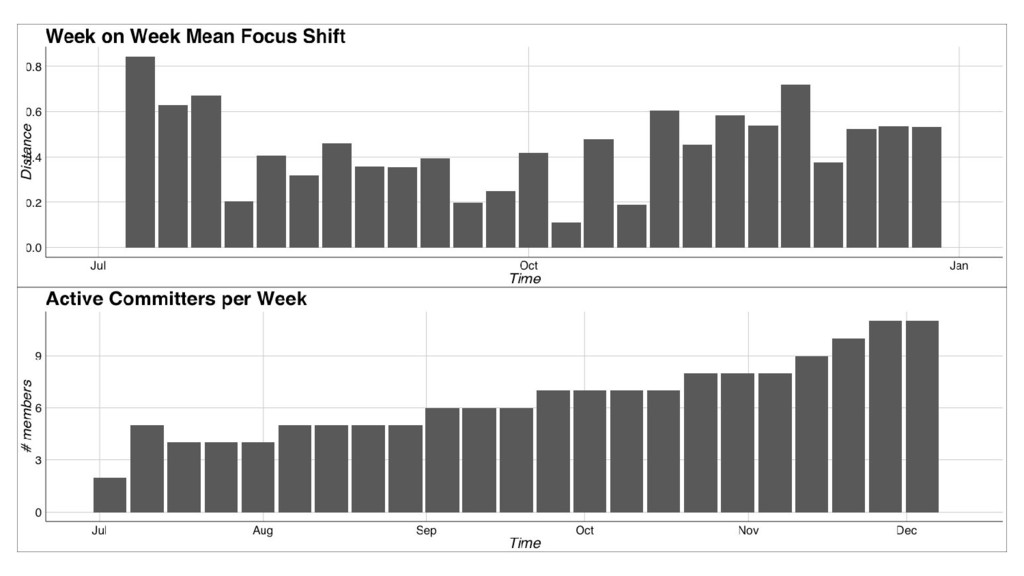
At FashionTrade, we use Docker containers deployed to Kubernetes hosted on Google Cloud Platform to primarily achieve two very important goals: a) whenever someone joins the team, we want them to make their first useful production commit within a day or two and b) creating, testing and deploying a service should not be much harder than editing a text file and pushing to git. We achieve these with our Docker based services setup and automated deployment pipeline built on Jenkins. In this talk we'll go into technical details about our setup, the organisational aspects of our approach and the results so far.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS ! www.fashiontrade.com | [email protected]](https://files.speakerdeck.com/presentations/8303c39a13a9486dba63c68d59bfbf96/slide_42.jpg){kind=link}