Softwareentwickler haben bei ihren altgedienten Anwendungssystemen oft das Bauchgefühl, dass irgendetwas komisch läuft. Das Management lässt sich aber nur mit Zahlen-Daten-Fakten von dringenden Verbesserungsarbeiten überzeugen.
In diesem Meetup stellt Markus Harrer den Bereich "Software Analytics" vor, dessen Vorgehen und Methoden darauf abzielen, Daten aus der Softwareentwicklung so aufzubereiten, dass sie von Managern zur Entscheidungsfindung herangezogen werden können.
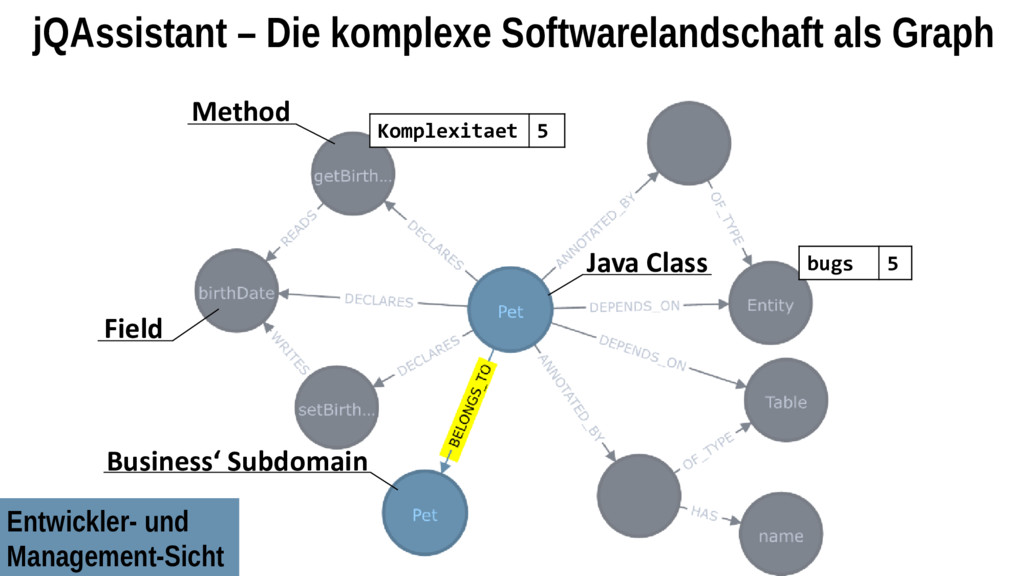
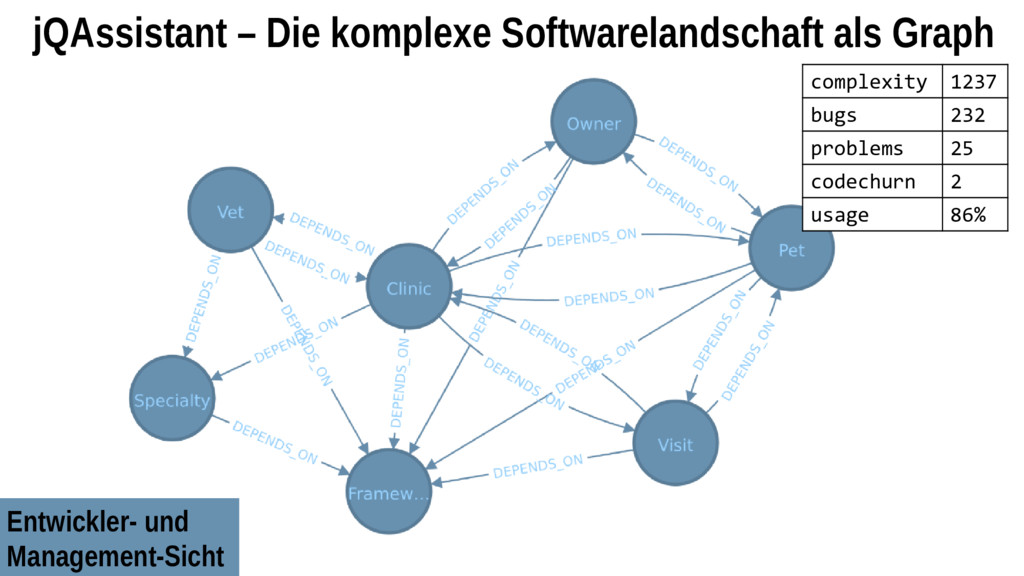
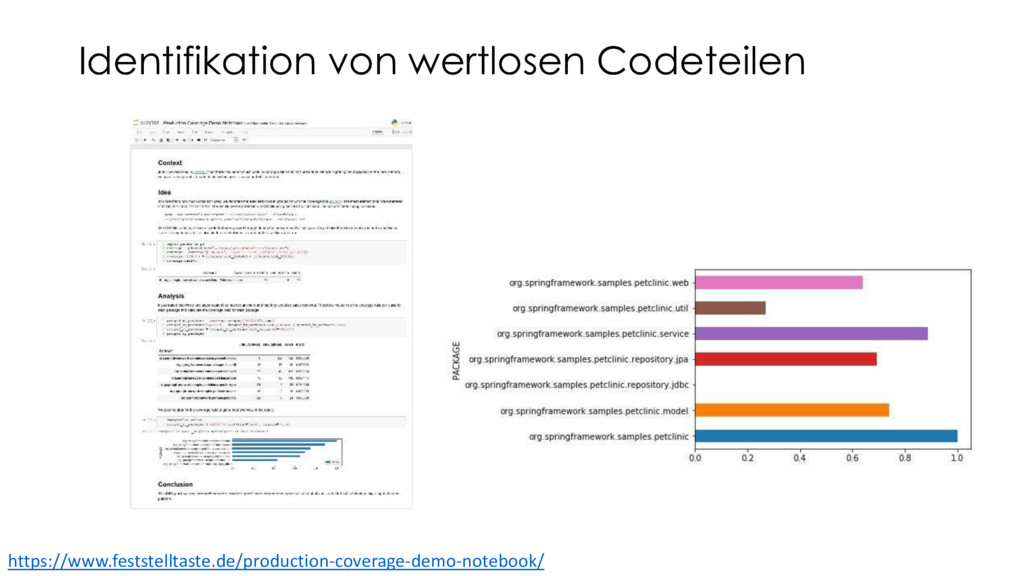
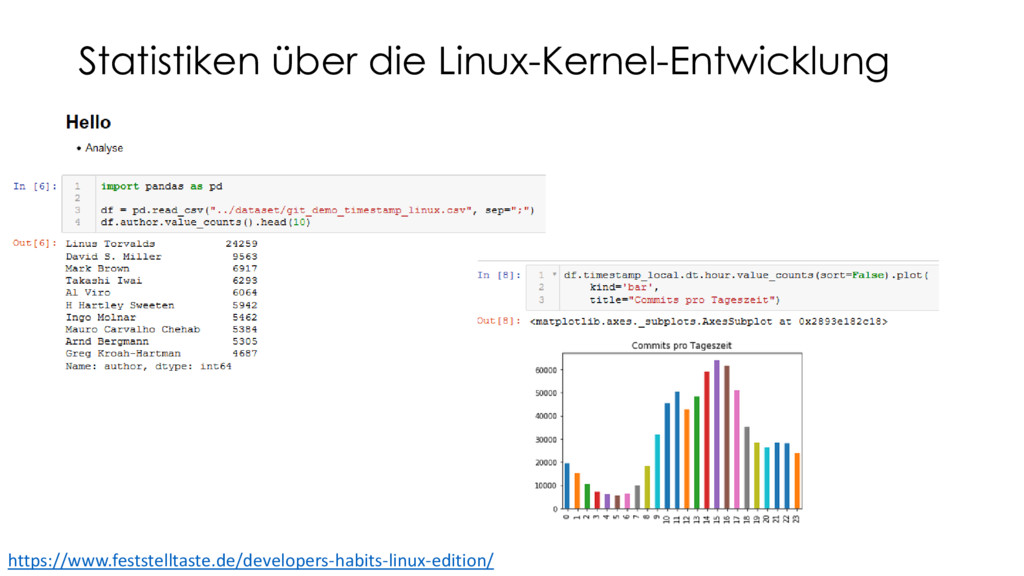
Markus bringt hierzu einen digitalen Notizbuchansatz sowie Werkzeuge für die schnelle Durchführung von nachvollziehbaren Datenanalysen mit. Damit können ganz individuelle Problemursachen in Softwaresystemen Schritt für Schritt herausgearbeitet und explizit dargestellt werden. Markus zeigt das Zusammenspiel von Open-Source-Analysewerkzeugen (wie Jupyter, Pandas, jQAssistant, Neo4j und D3) zur Untersuchung von Java-Anwendungen und deren Umgebung (Git, JaCoCo, Profiler, Logfiles etc.). Im Live-Coding-Teil sehen wir uns einige Auswertungen zu Race-Conditions, Wissenslücken, wertlosen Codeteilen sowie die Optimierung des fachlichen Schnitts einer Anwendung an – von den Rohdaten bis zu den Visualisierungen.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
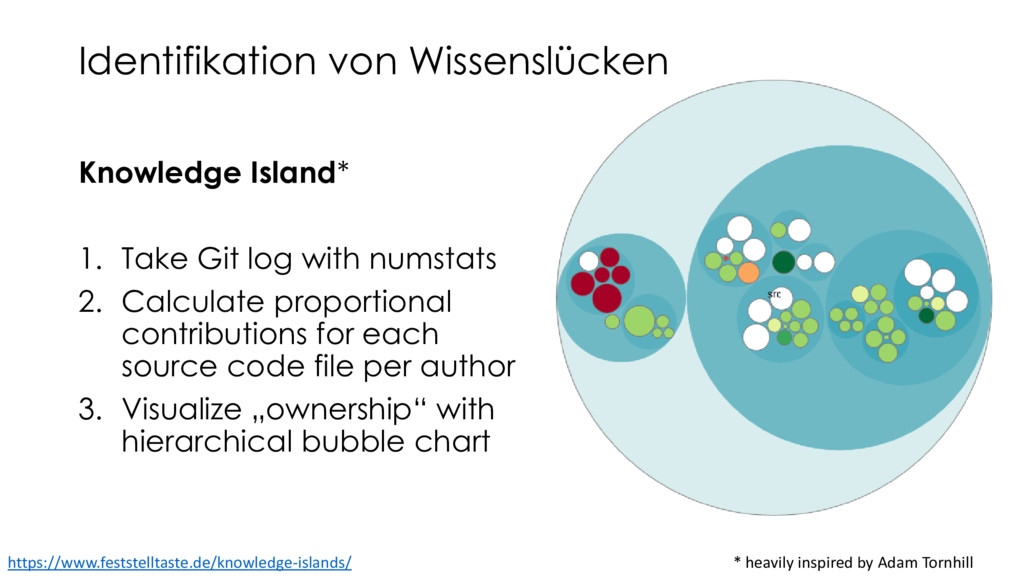{kind=link}
![Identifikation von rekursiven DB-Aufrufen Cypher-Query und Teilgraph-Ergebnis MATCH (m:Method)-[:INVOKES*]->(m) -[:INVOKES]->(dbMethod:Method)](https://files.speakerdeck.com/presentations/538a48d05dd244df8ff796b54ae10c1a/slide_81.jpg){kind=link}
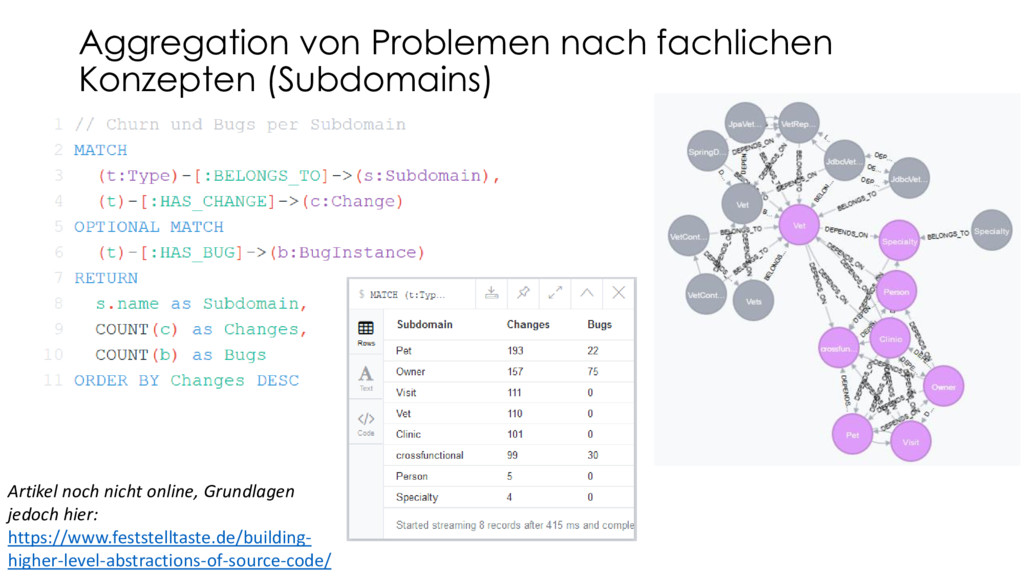{kind=link}
![Analyse potenzieller Bounded Contexts MATCH (s1:Subdomain)<-[:BELONGS_TO]- (type:Type)-[r:DEPENDS_ON*0..1]-> (dependency:Type)-[:BELONGS_TO]->(s2:Subdomain) RETURN s1.name](https://files.speakerdeck.com/presentations/538a48d05dd244df8ff796b54ae10c1a/slide_83.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}