@ Parkio, Microsoft, Harvard • Interested in distributed systems. • Scala enthusiast. I’m Nick • We’re the marketing platform for the visual web. • Traditional social media relies upon keywords to “hear” consumers. • When people “speak” with pictures (on Pinterest, Instagram, Tumblr, etc), very few words are used. • Interesting problems around intersection of computer-vision and web-scale data. • Philly-based, 13 months old. I work at Curalate
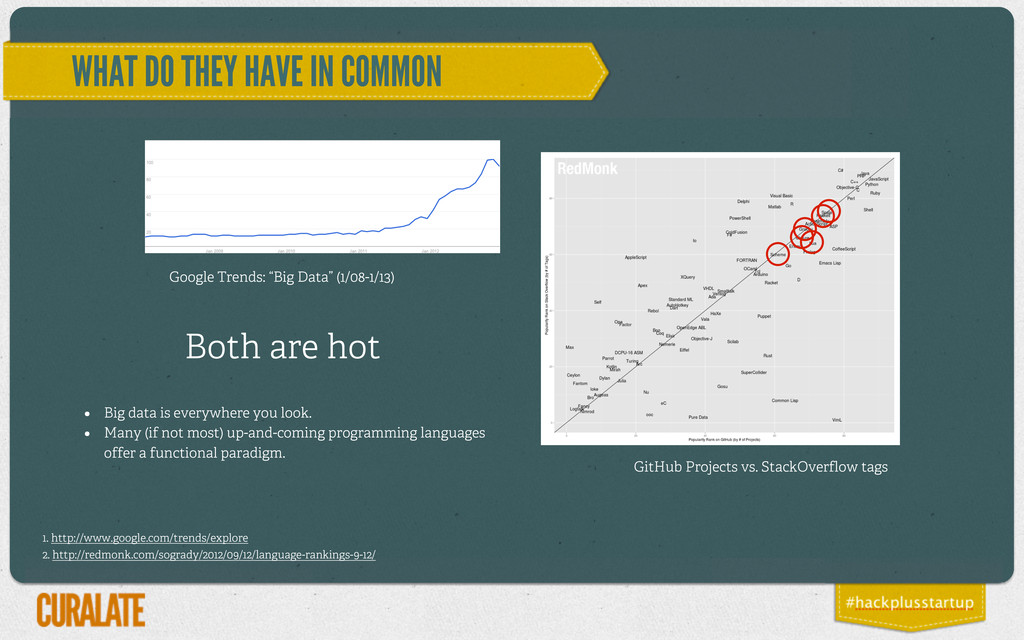
Google Trends: “Big Data” (1/08-1/13) GitHub Projects vs. StackOverflow tags 1. http://www.google.com/trends/explore 2. http://redmonk.com/sogrady/2012/09/12/language-rankings-9-12/ • Big data is everywhere you look. • Many (if not most) up-and-coming programming languages offer a functional paradigm.
Concurrency is hard. • Multi-core machines are ubiquitous. • Renewed interest in distributed computing and web-scale problems. • FP languages are no longer slow. • Social factors. The ways in which one can divide up the original problem depend directly on the ways in which one can glue solutions together. Therefore, to increase ones ability to modularise a problem conceptually, one must provide new kinds of glue in the programming language. Jon Hughes - Why Functional Programming Matters (1984) The Modern Reason(s)
map is a higher-order function that takes two parameters: a function f, and a list of values. • It applies f to each item in the list, and returns a new list composed of the results. Reduce is functional • Reduce is a special case of the fold function. • In FP, fold is a function that takes three parameters: a function, a value, and a list of values. • It combines all values in the list into a single value, using f. } def map(f: Function, items: List): List = { val newItems = new ListBuffer items.foreach(item => { newItems.add(f(item)) }) return newItems } def fold(f: Function, s: S, items: List): S = { var retval = s items.foreach(item => { retval = f(retval, item) }) return retval } def reduce(f: Function, items: List): S = fold(f, items.head, items.tail)
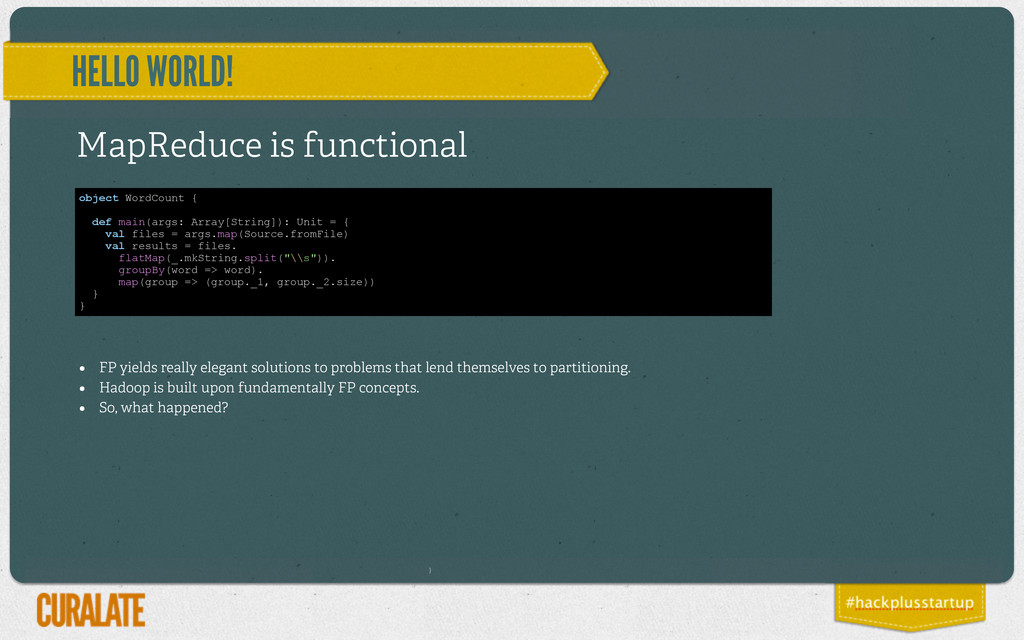
def main(args: Array[String]): Unit = { val files = args.map(Source.fromFile) val results = files. flatMap(_.mkString.split("\\s")). groupBy(word => word). map(group => (group._1, group._2.size)) } } • FP yields really elegant solutions to problems that lend themselves to partitioning. • Hadoop is built upon fundamentally FP concepts. • So, what happened?
than .map.reduce • Distributed computation. • Data locality. • Fault tolerance & high availability. • Support for non-FP languages. Can we get all this alongside our FP idioms and libaries?
a first-class feature? • This is not as crazy as it sounds. • Parallel collections are built into Scala. • Google built FlumeJava (distributed collections). • Scala committers were, at one point, working on a distributed collections library. This has since been abandoned [1]. • Current focus is on distributed computing via actors. 1. https://github.com/scala-incubator/distributed-collections theList.map(doSomething) theList.par.map(doSomething) theList.dist.map(doSomething)
Hadoop FP- friendly? • Functional programming aside, there is a ton of activity around building novel wrappers around Hadoop. Cascalog Apache Crunch • Some of these libraries have FP-friendly equivalents. • Crunch -> Scrunch • Cascading -> Scalding
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#hackplusstartup [email protected] THANK YOU!](https://files.speakerdeck.com/presentations/7748411064eb0130c19312313d1a79cc/slide_13.jpg){kind=link}
{kind=link}