Hilary Mason c/o bitly 416 w 13th St New York, NY 10014 Hilary Mason bit.ly 416 w 13St suite #203 New York City 10014 Hilary Mason Chief Scientist Bitly 416 west 13th Street New York, NY 10014
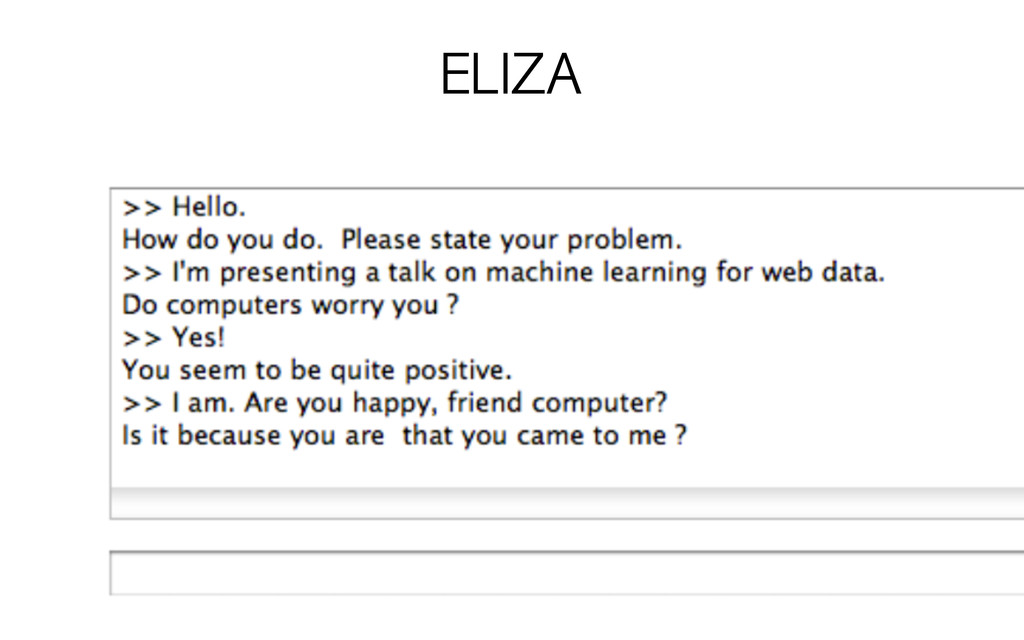
you want shymuffin32: ok shymuffin32: why do you like music? jmstriegel: hmm. i've never really considered that. jmstriegel: hell, i'm not going to be able to contrive a good answer for that one. ask me something else. shymuffin32: jeesus, you're worse than eliza http://bit.ly/b7dter
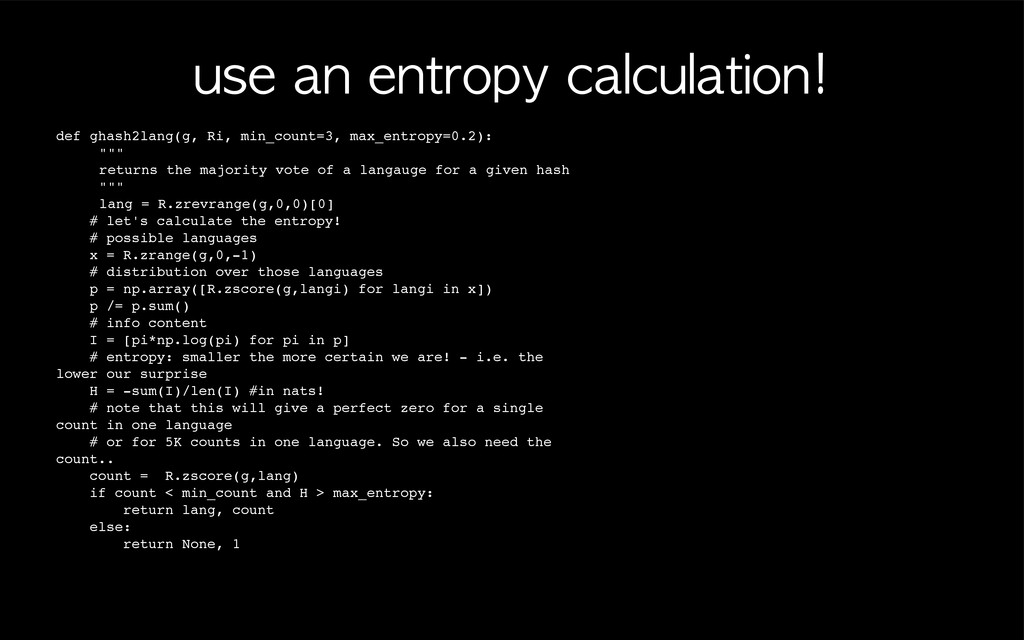
""" ! returns the majority vote of a langauge for a given hash ! """ ! lang = R.zrevrange(g,0,0)[0] # let's calculate the entropy! # possible languages x = R.zrange(g,0,-1) # distribution over those languages p = np.array([R.zscore(g,langi) for langi in x]) p /= p.sum() # info content I = [pi*np.log(pi) for pi in p] # entropy: smaller the more certain we are! - i.e. the lower our surprise H = -sum(I)/len(I) #in nats! # note that this will give a perfect zero for a single count in one language # or for 5K counts in one language. So we also need the count.. count = R.zscore(g,lang) if count < min_count and H > max_entropy: return lang, count else: return None, 1
{kind=link}
![Hilary Mason Chief Scientist, bitly @hmason [email protected] The Beauty of](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![+ + sum() [1,2,3]](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_6.jpg){kind=link}
{kind=link}
![[archive photo]](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[this is working]](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_14.jpg){kind=link}
{kind=link}
![[excel]](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[spam folders]](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
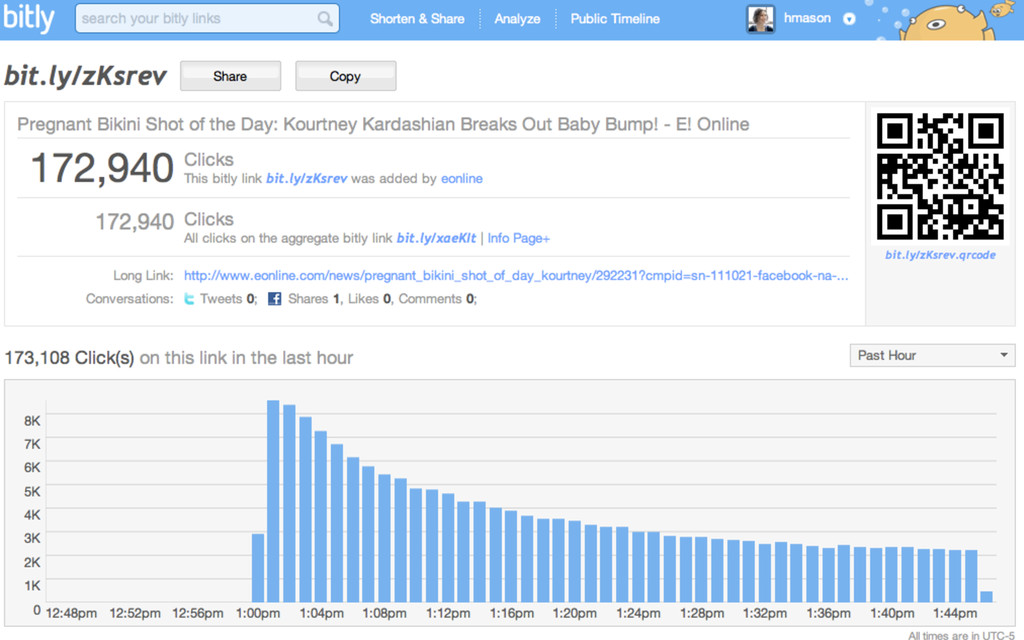{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
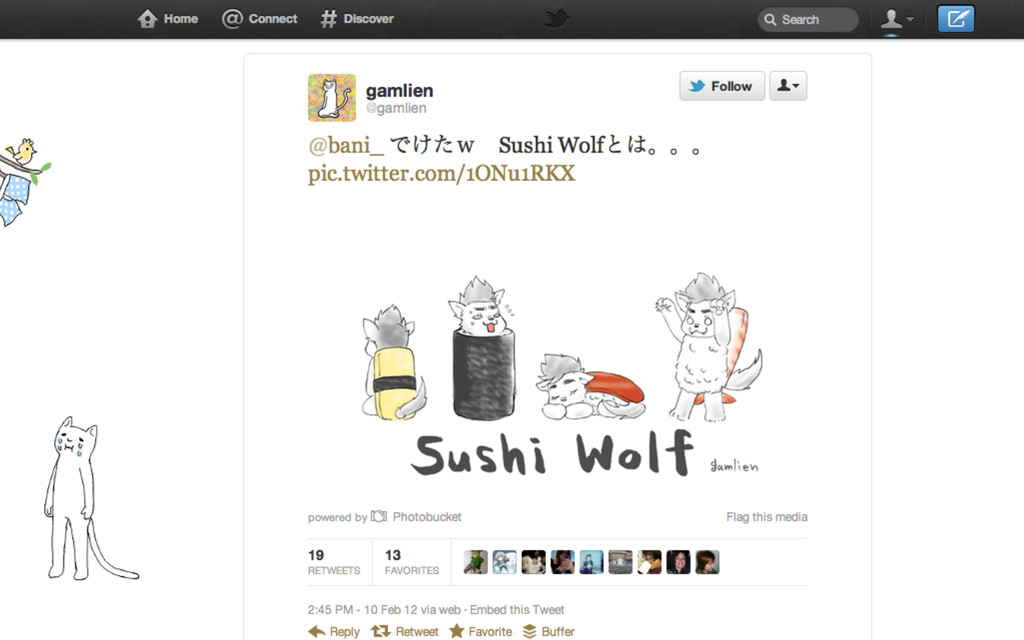{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
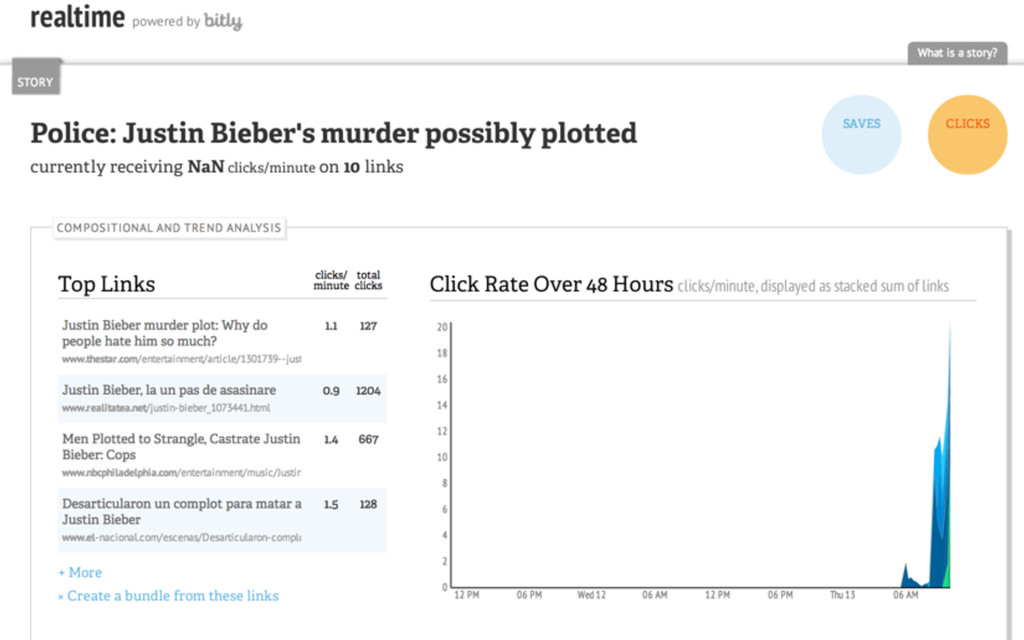{kind=link}
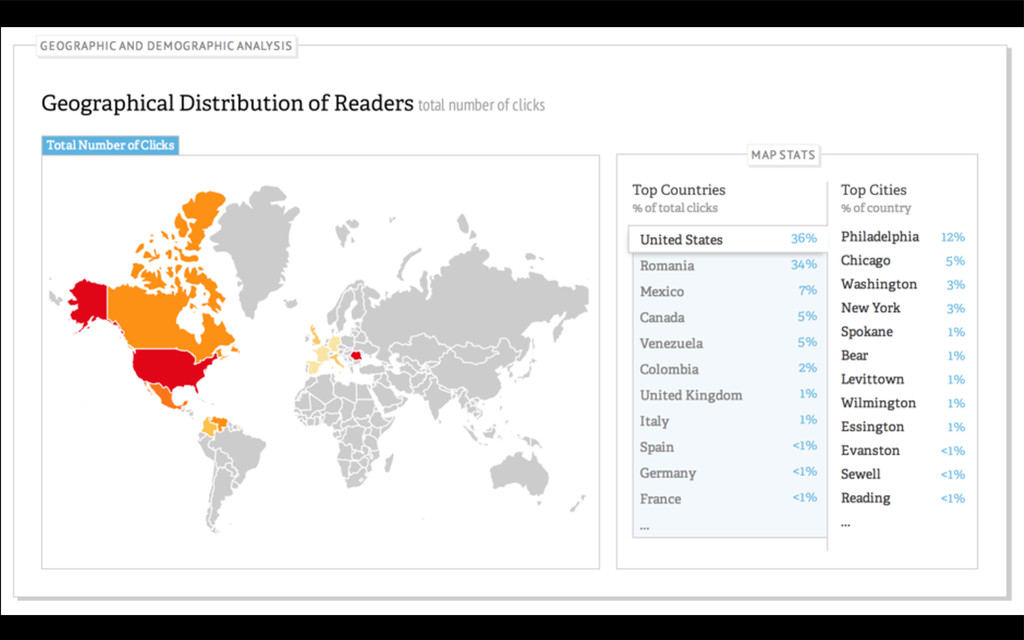{kind=link}
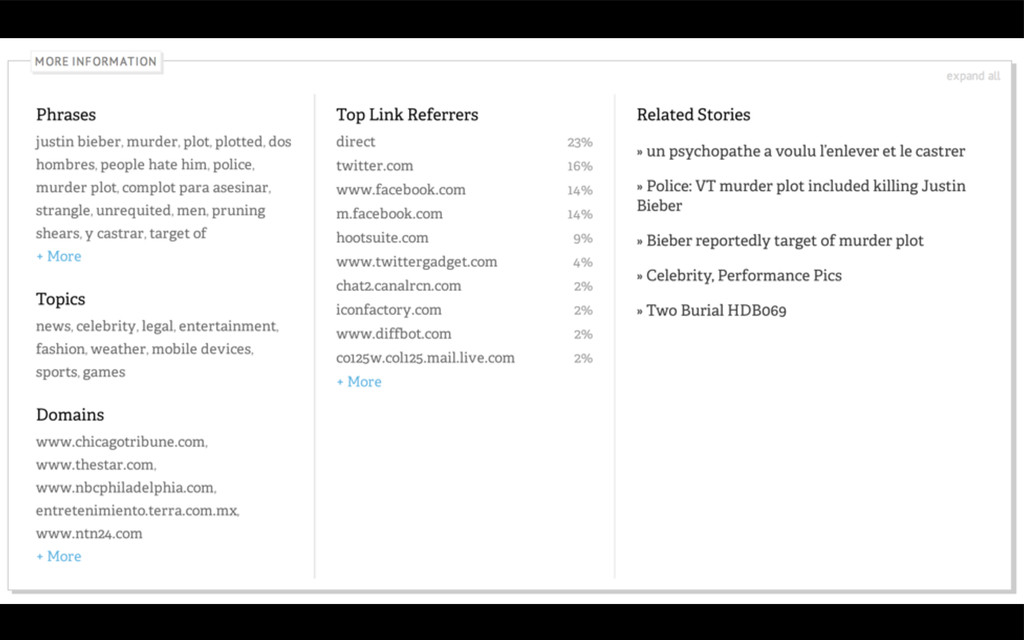{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] @hmason Thank you!](https://files.speakerdeck.com/presentations/df215a1064e70130b23612313b0318ca/slide_76.jpg){kind=link}
{kind=link}