To avoid the curse of dimensionality in the exponent of ε−1 or the coefficient, we typically must appeal to weighted spaces, i.e., spaces where not all coordinates are equally important, e.g, Kd(x, t) = u⊂1:d γu j∈u xj + tj − xj − tj , γu → 0 as max j : j ∈ u or |u| → ∞ f, g H = f(0)g(0) γ∅ + 1 2γ{1} 1 −1 ∂f ∂x1 (x1, 0, · · · ) ∂g ∂x1 (x1, 0, · · · ) dx1 + 1 2γ{2} 1 −1 ∂f ∂x2 (0, x2, 0, · · · ) ∂g ∂x2 (0, x1, 0, · · · ) dx2 + · · · + 1 4γ{1,2} 1 −1 1 −1 ∂2f ∂x1∂x2 (x1, x2, 0, · · · ) ∂2g ∂x1∂x2 (x1, x2, 0, · · · ) dx1dx2 + · · · The discrepancy, ηn H , tends to zero as n → ∞ for your favorite data sites if γu → 0 fast enough. For f H to be of reasonable size as γu → 0, the importance of the coordinates in u must vanish. Problem: How do you know which coordinates are most important a priori? 11/17
{kind=link}
{kind=link}
{kind=link}
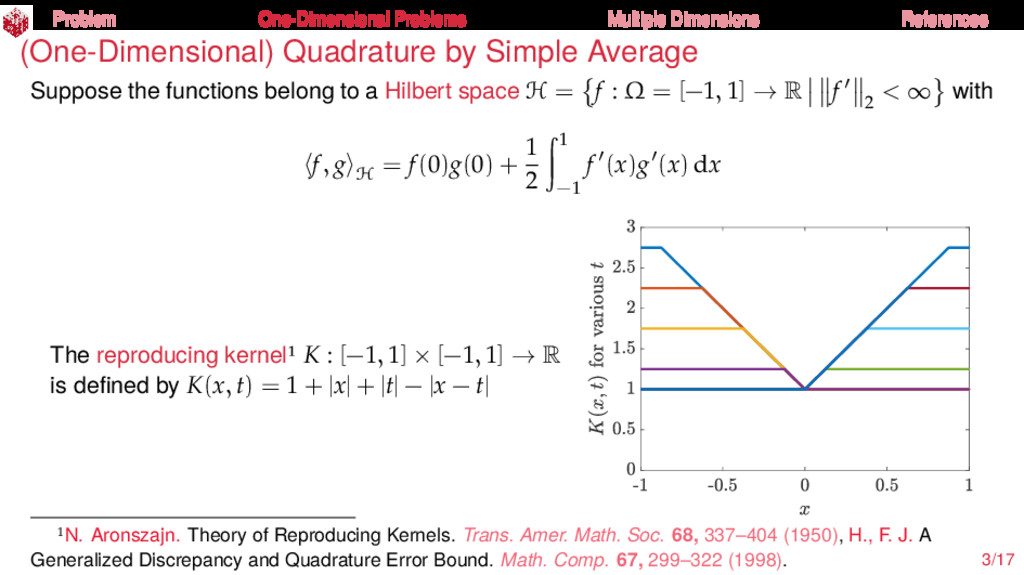{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
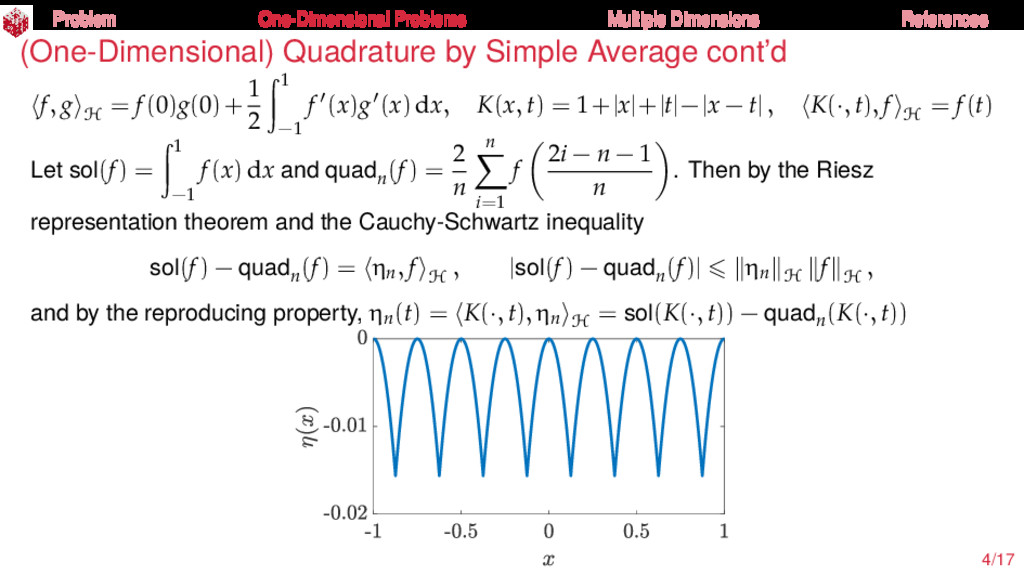{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
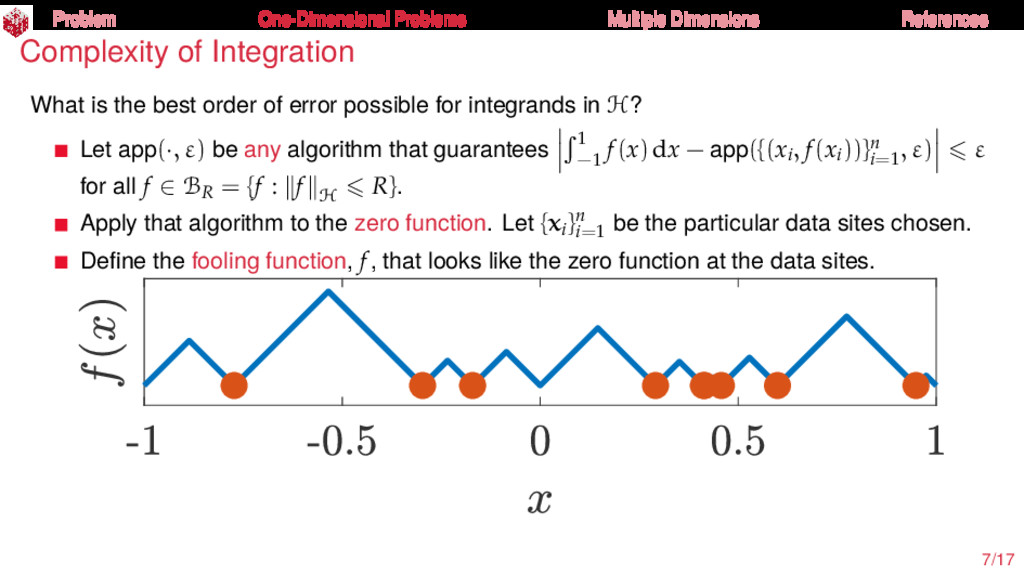{kind=link}
{kind=link}
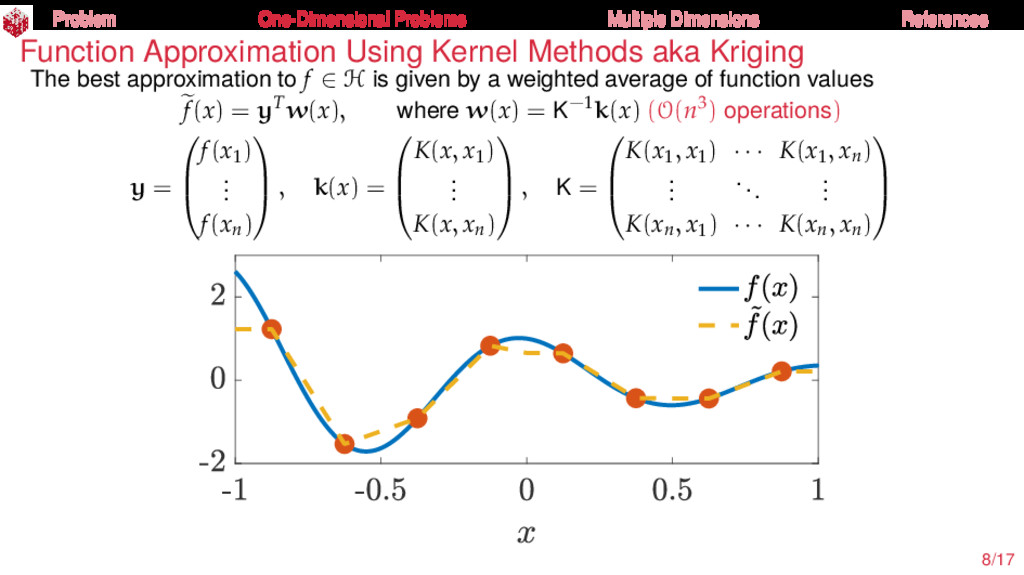{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}