Vortrag (DE) "Python und Big-Data-Frameworks" von Frank Kaufer und Christoph Böhm, bakdata (http://www.bakdata.com), auf der Data2Day (http://www.data2day.de/) 2014, Karlsruhe, 26.11.2014.
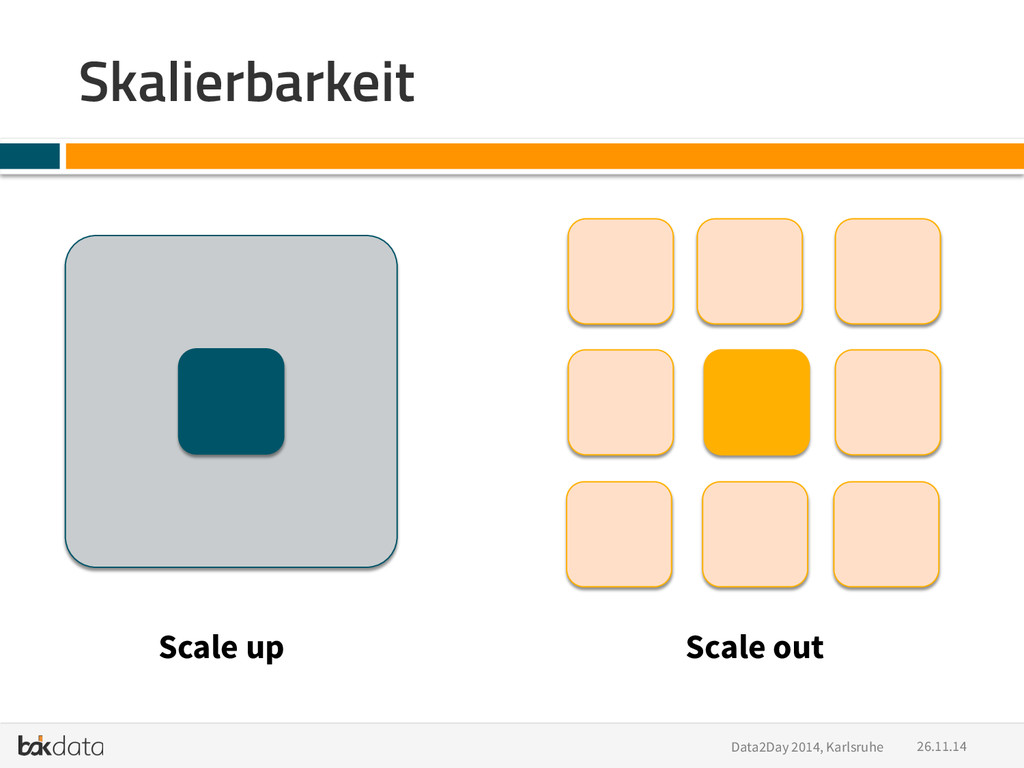
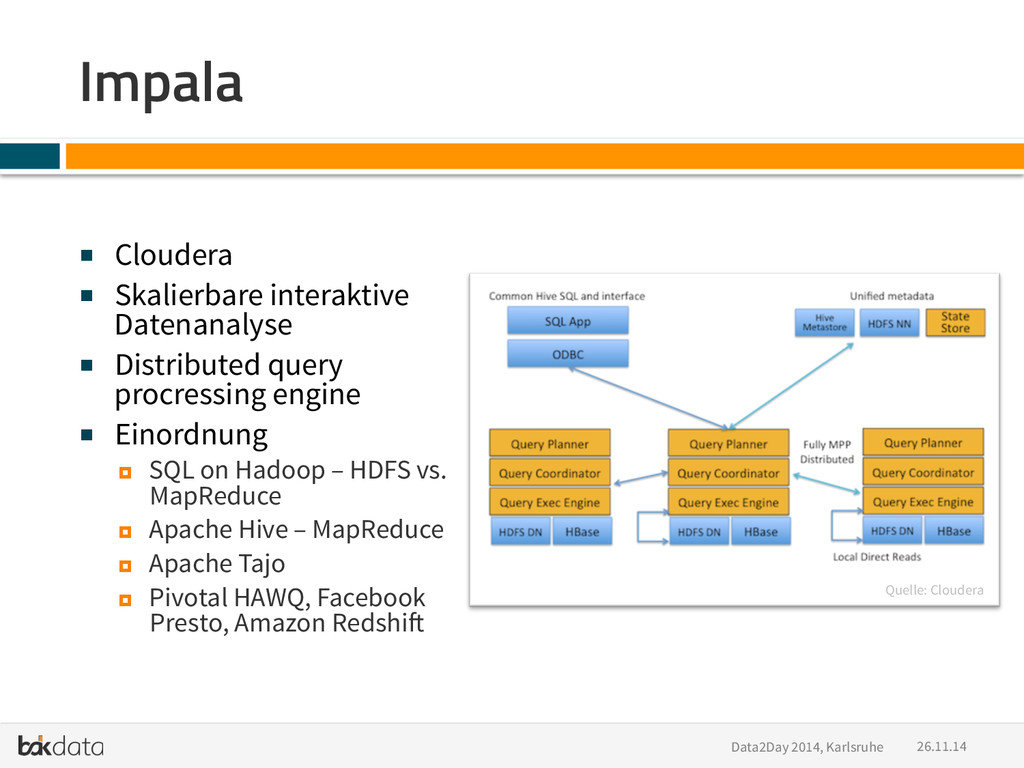
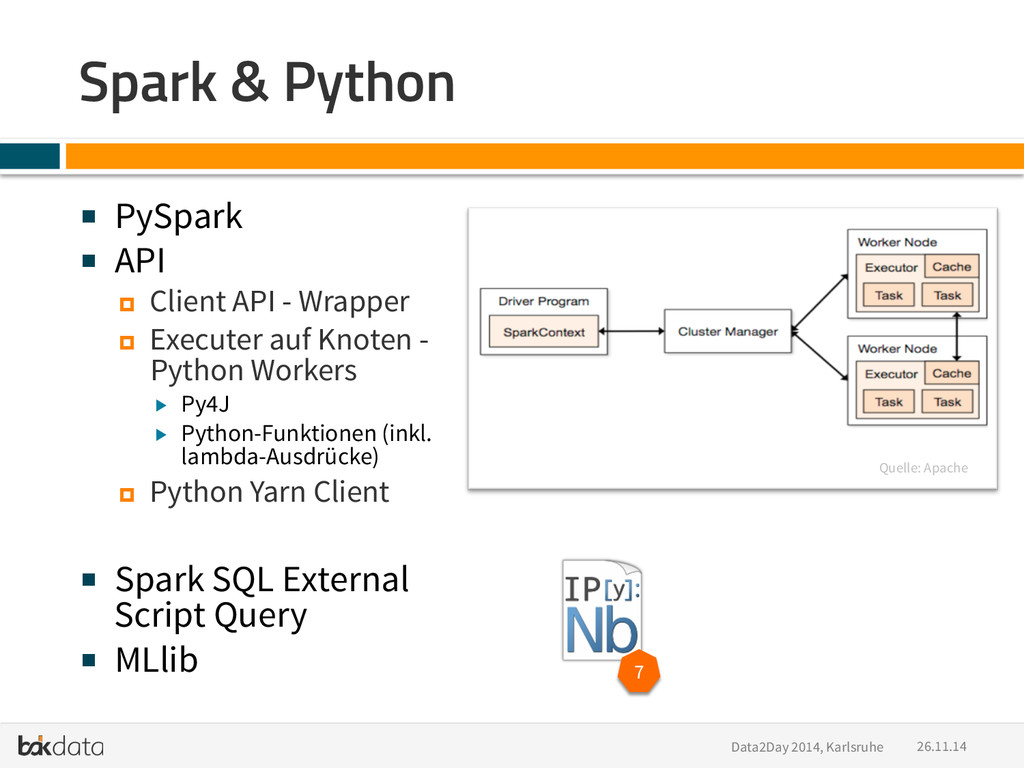
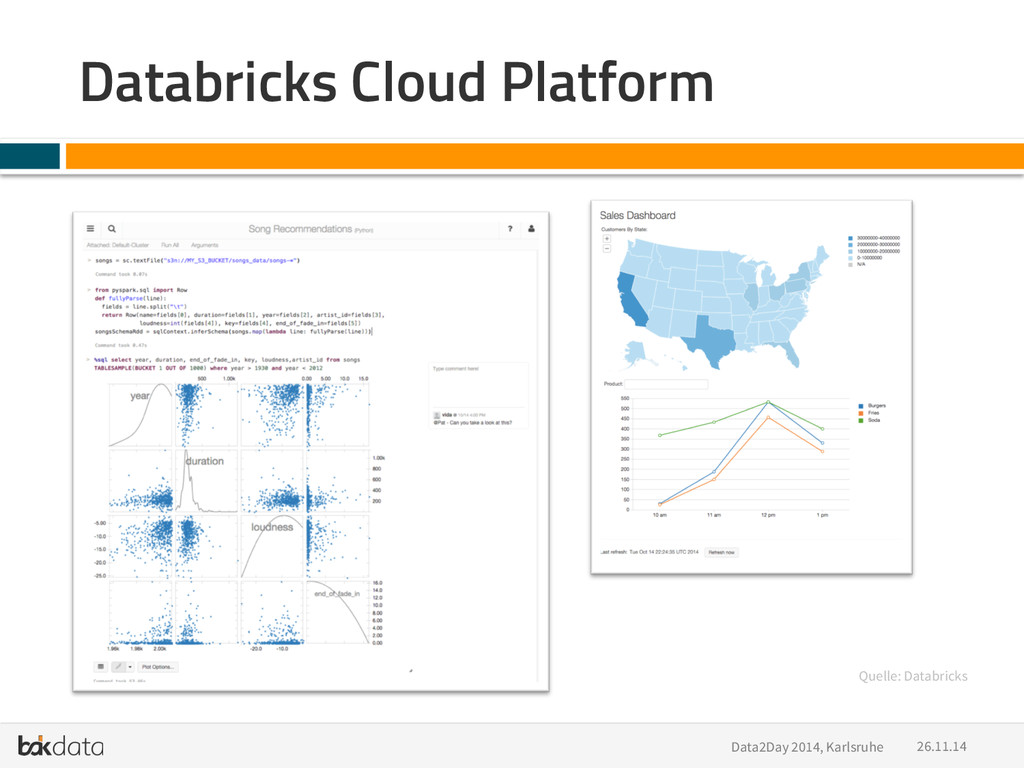
Buzzwords: Python, PyData, Big Data, Scale out, Distributed Systems, Hadoop, Impala, Spark
Code & Links: https://github.com/bakdata/data2day-2014
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}