Extended slide deck from talk at PyData Berlin 2016 conference.
Keywords: Polyglot Data Science, Data Science Platforms, Python, NumPy, PyData, Scala, Big Data, Scale Out, Spark, Infrastructure, Automation, DevOps, Boxes, Packaging, Ansible, Packer, Virtualization, Container, Docker, Kubernetes, Jupyter, Pipelines, Recommender, ALS, BLAS.
{kind=link}
{kind=link}
{kind=link}
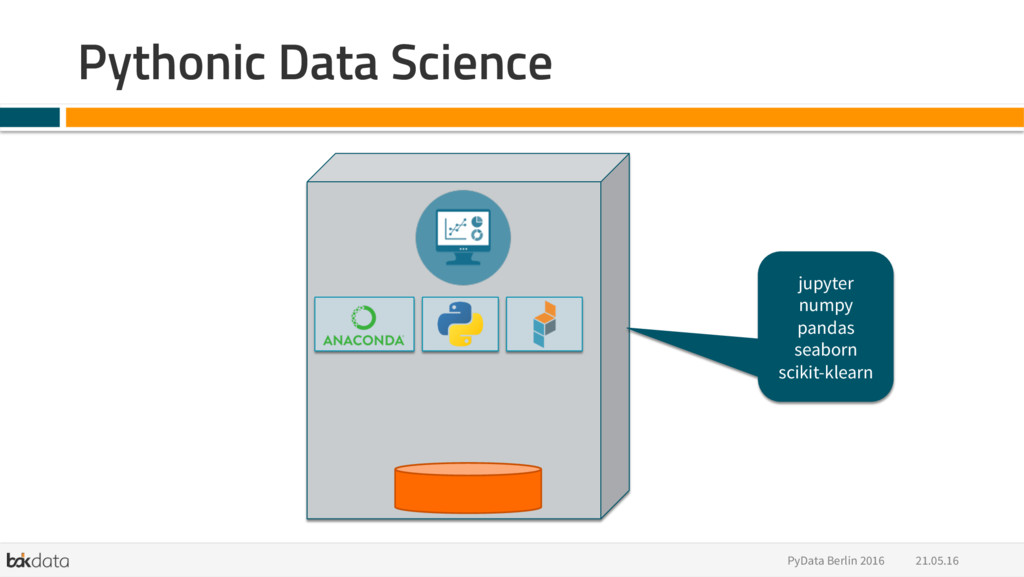{kind=link}
{kind=link}
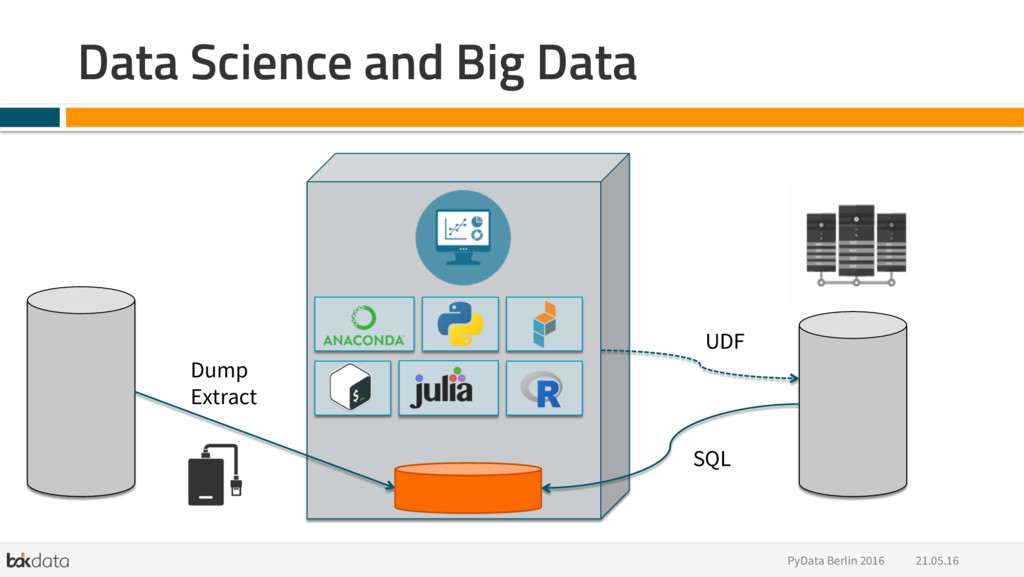{kind=link}
{kind=link}
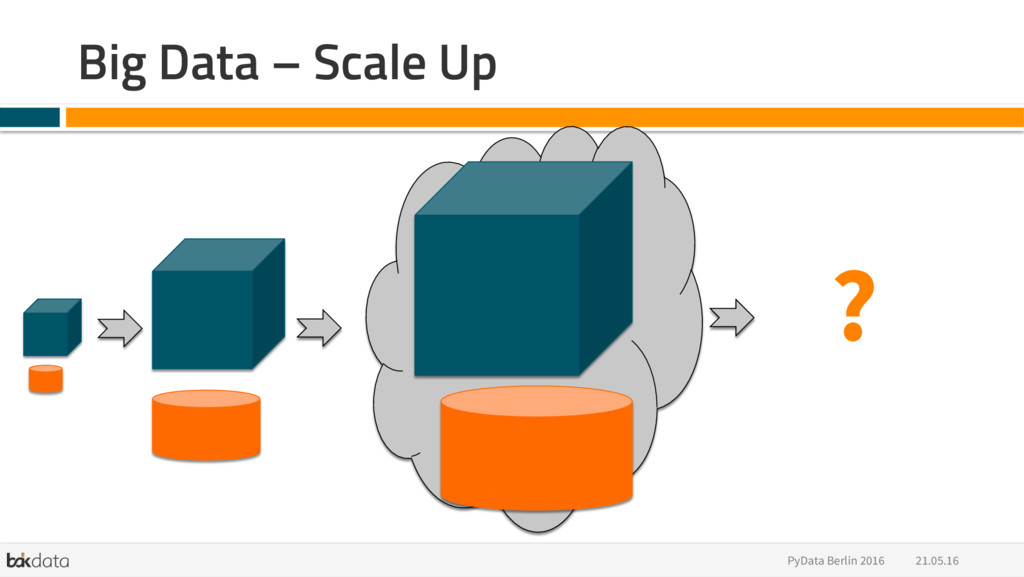{kind=link}
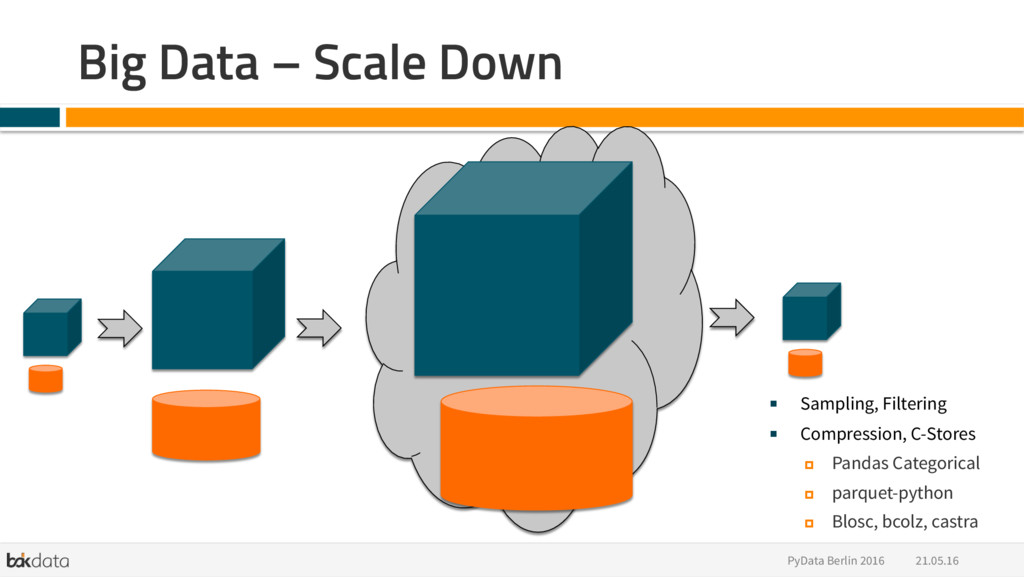{kind=link}
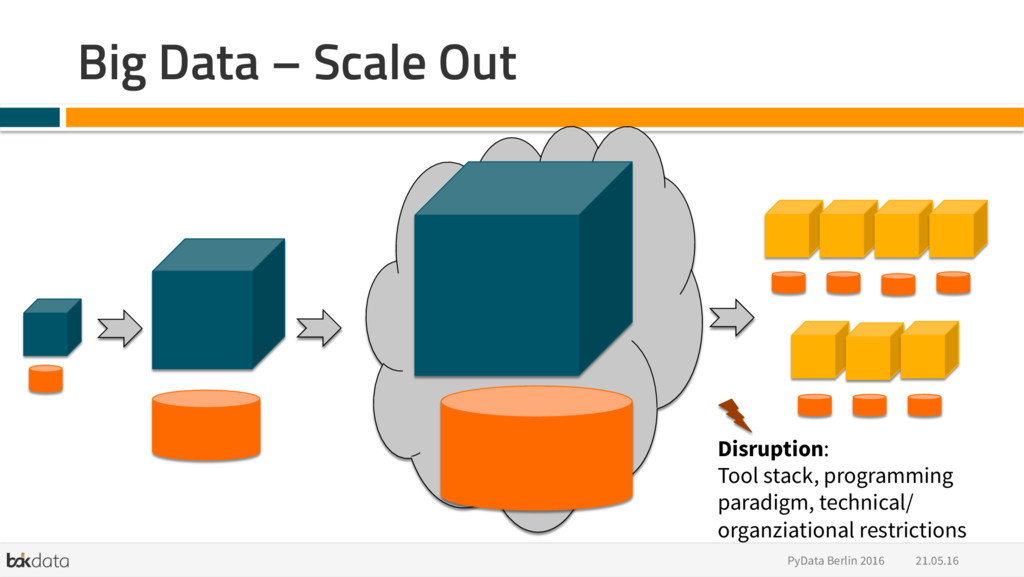{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
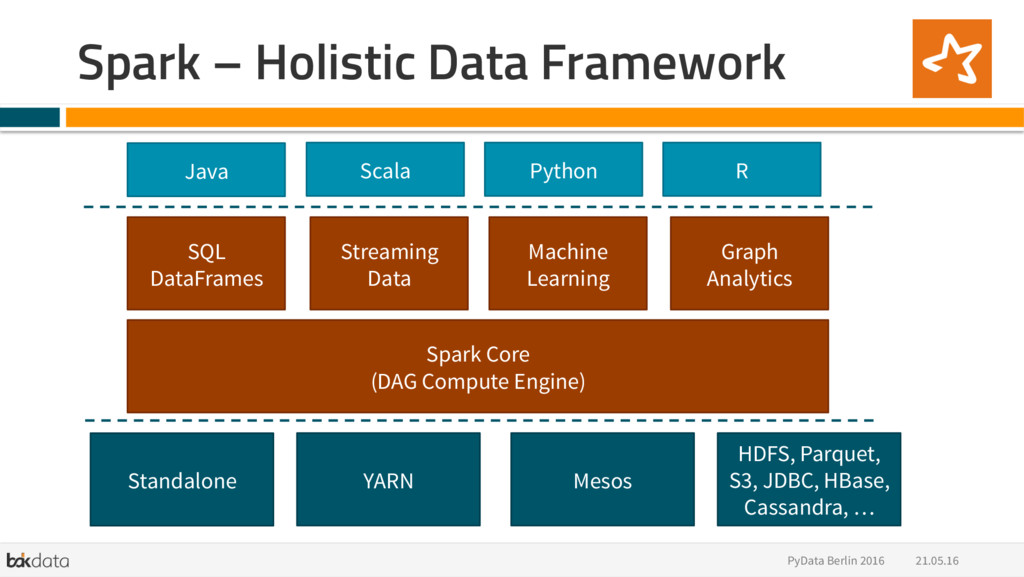{kind=link}
{kind=link}
{kind=link}
{kind=link}
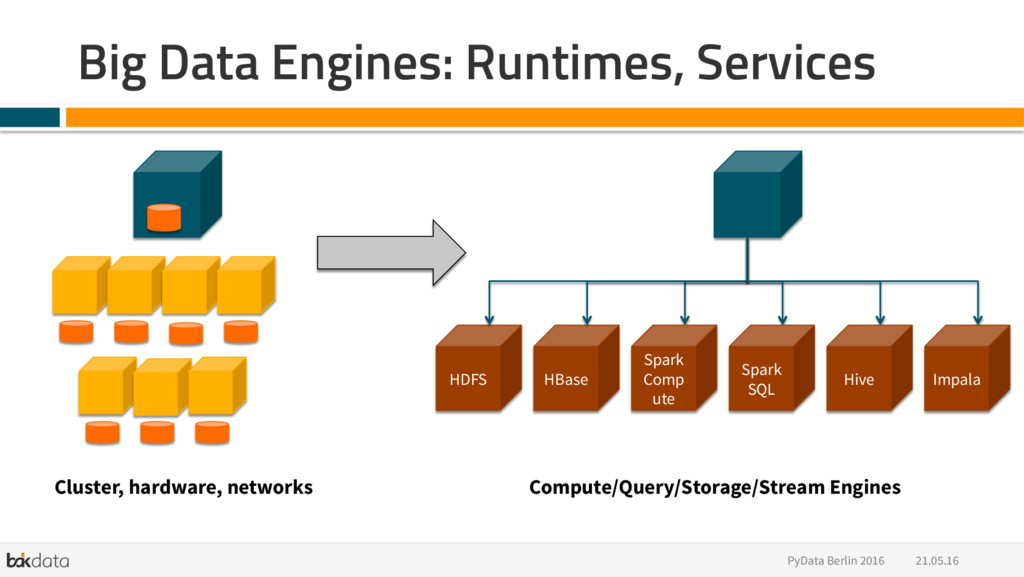{kind=link}
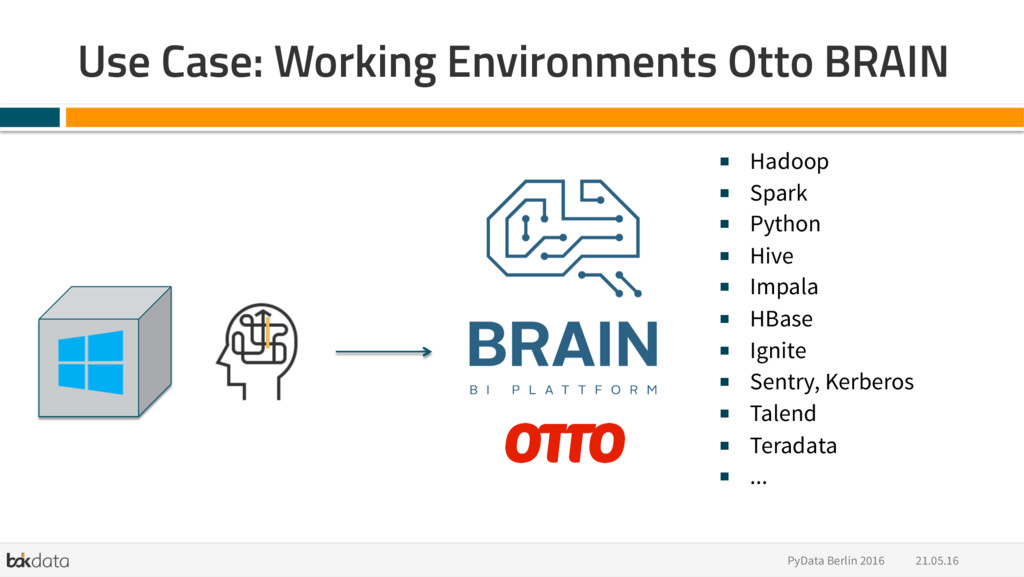{kind=link}
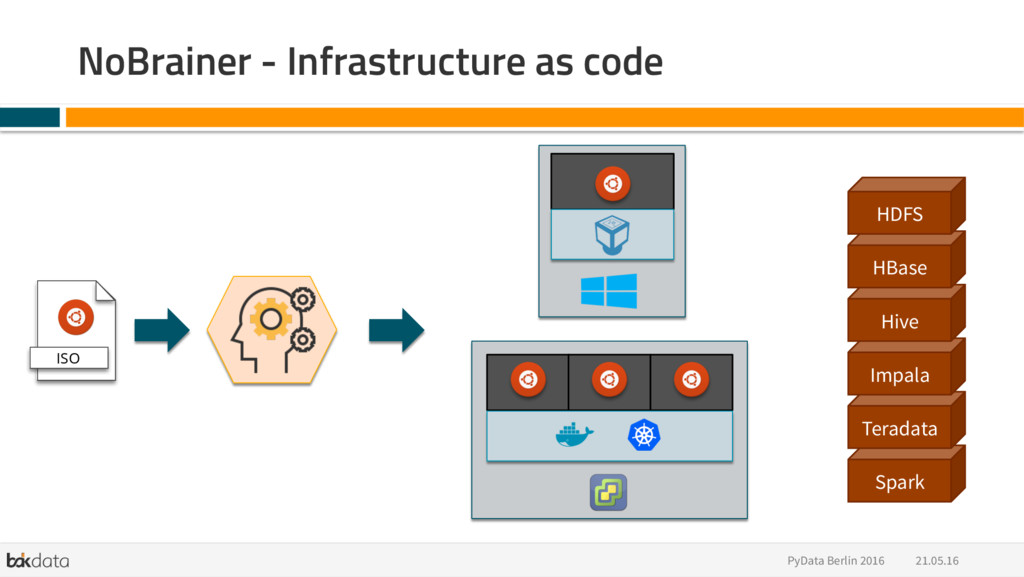{kind=link}
{kind=link}
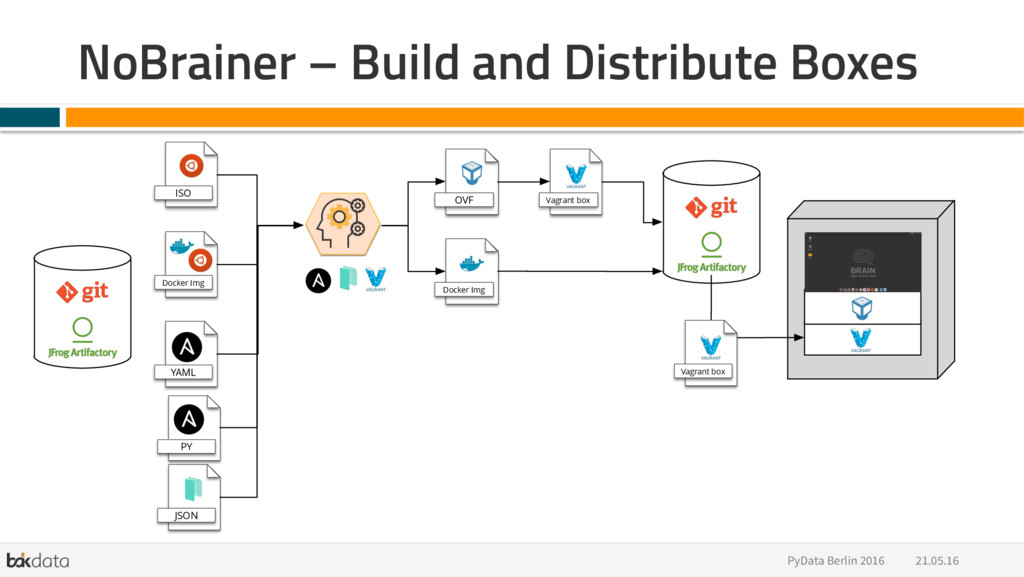{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
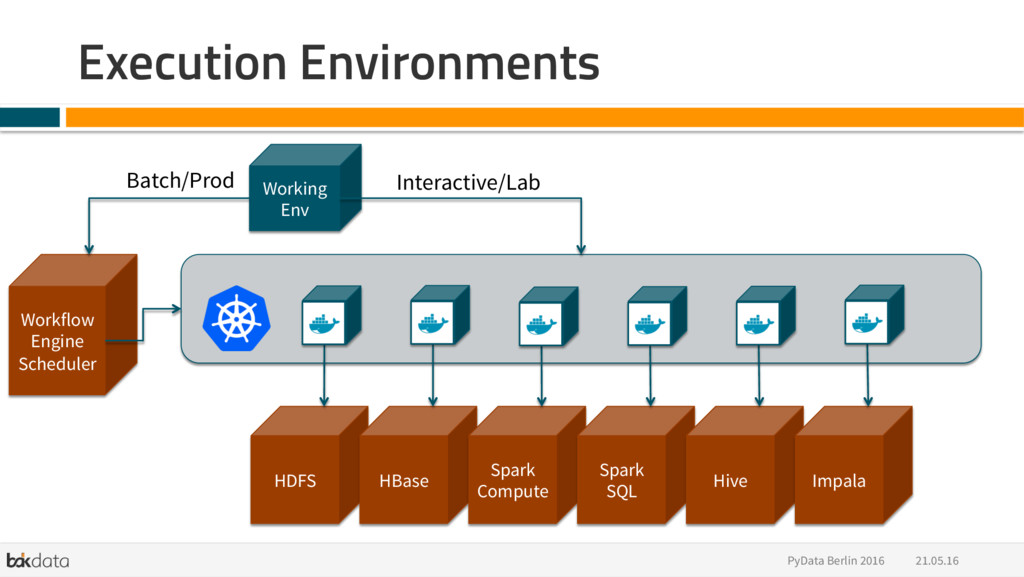{kind=link}
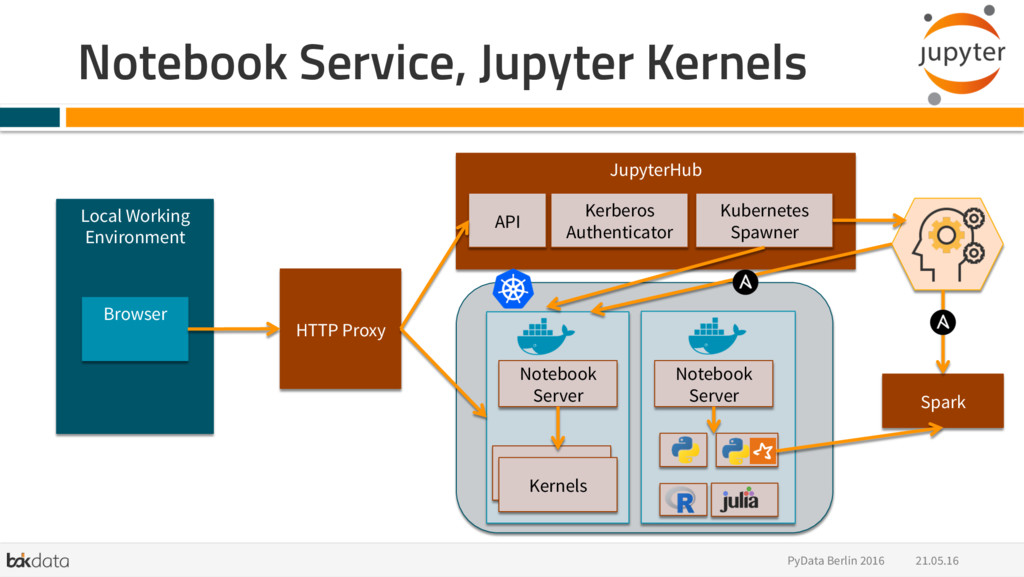{kind=link}
{kind=link}
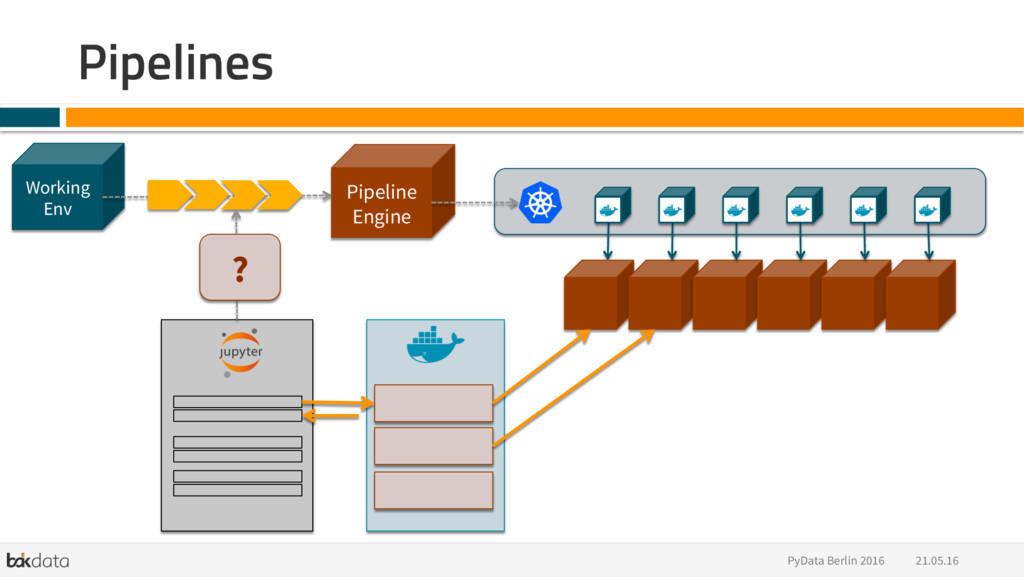{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
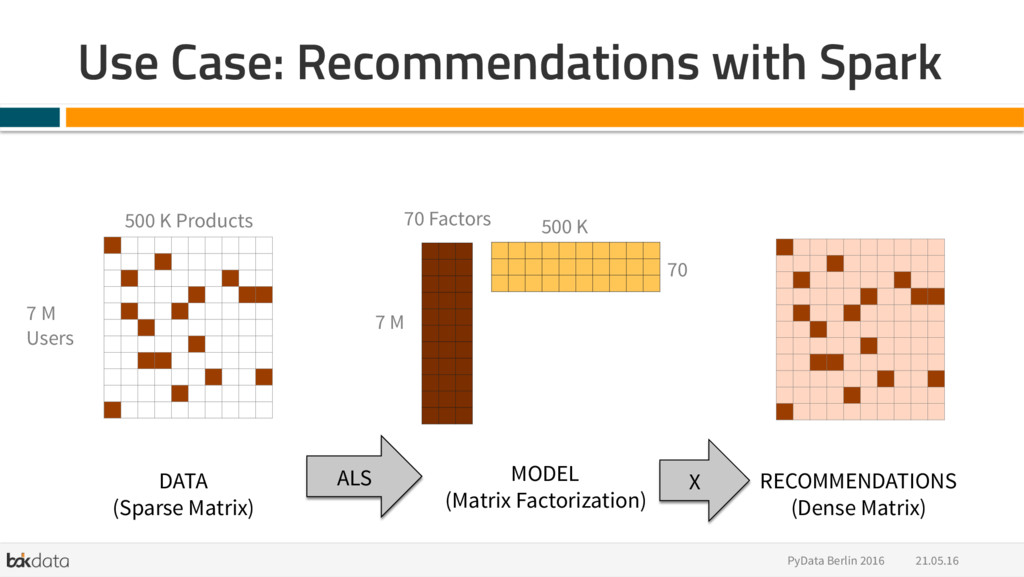{kind=link}
{kind=link}
{kind=link}
{kind=link}
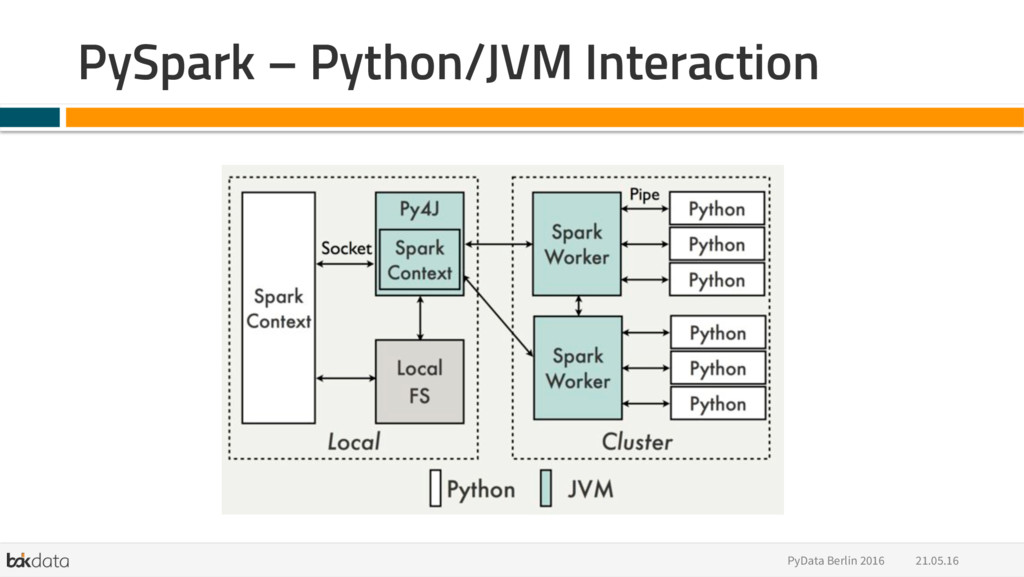{kind=link}
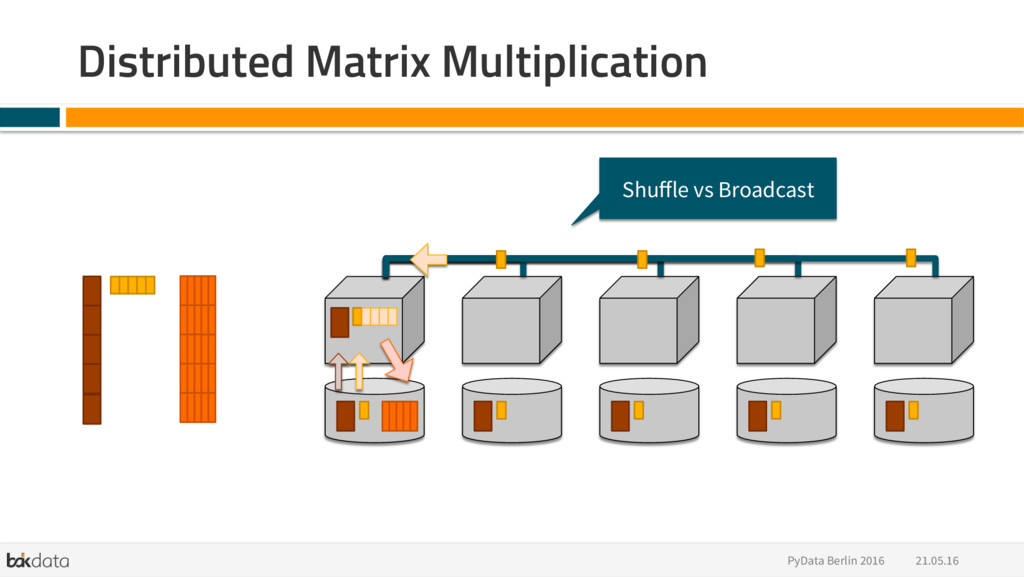{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}