entregues de uma forma transparente A mesma ideia tem sido aplicada no contexto da informática Cloud Computing ou Computação em Nuvem Computação em Nuvem Ideia antiga: Software como um Serviço (SaaS) Entrega de aplicações através da Internet Recentemente: “[Hardware, Infraestrutura, Plataforma] como um serviço” “X como um serviço” 3
muito grande Economia de escala sem precedentes Transferência de risco Fatores de tecnologia Internet de banda larga difundida Maturidade de tecnologias de virtualização Fatores de negócios Custo inicial mínimo Modelo de pagamento baseado no uso pay-as-you-go 4
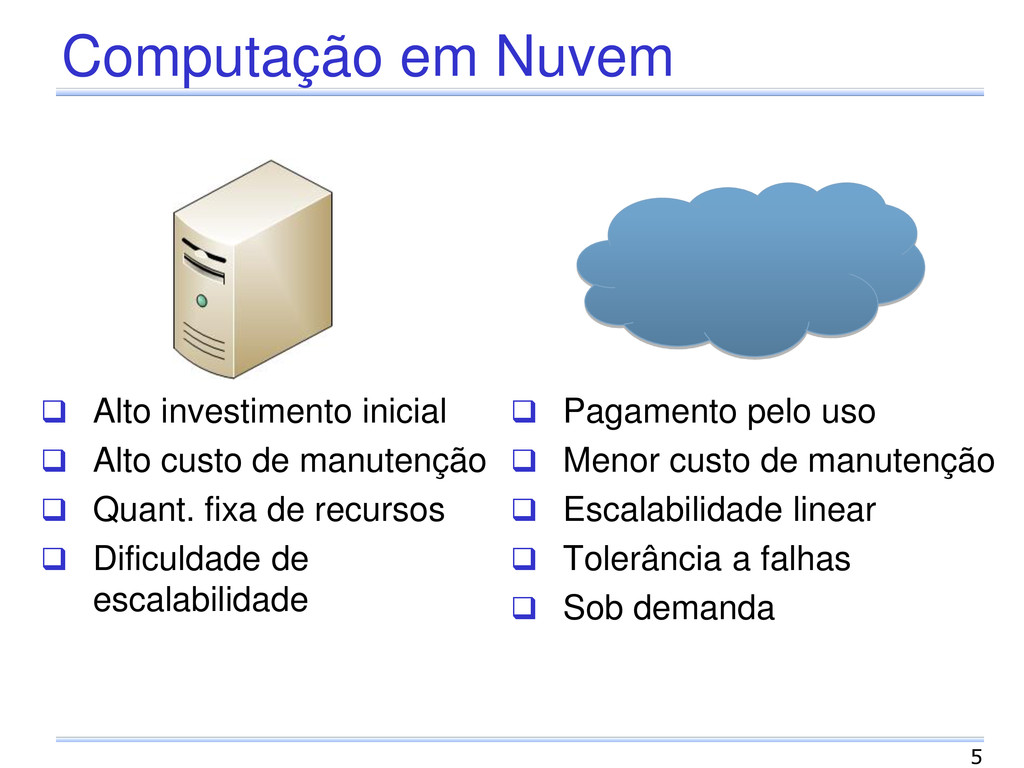
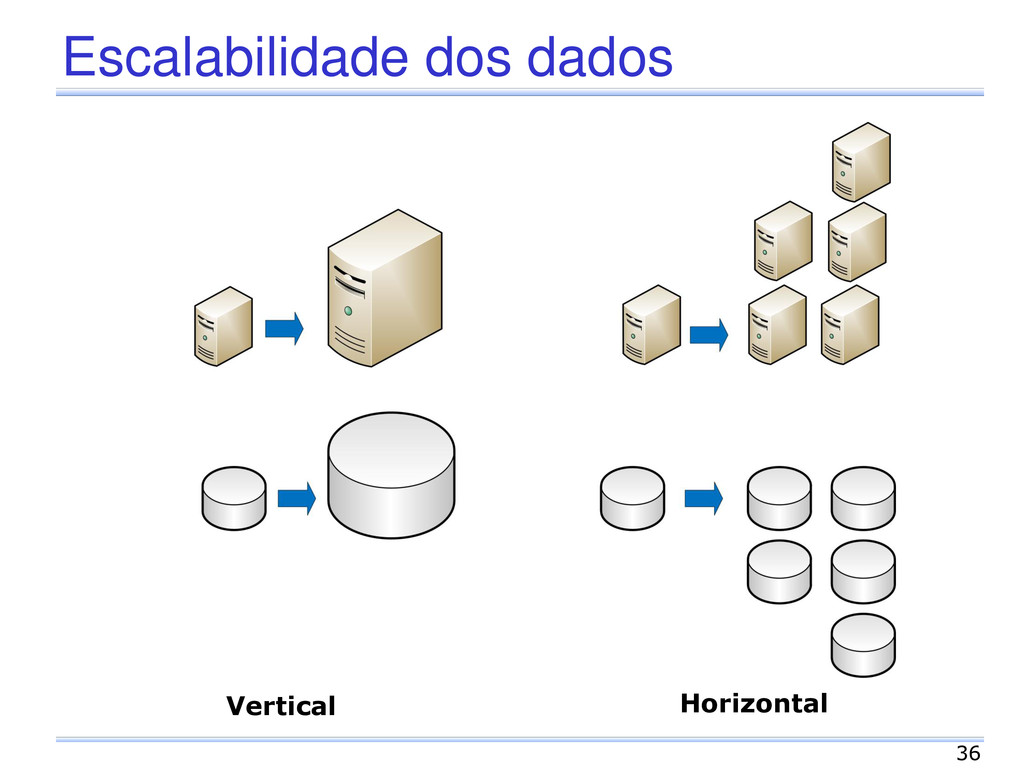
de manutenção Quant. fixa de recursos Dificuldade de escalabilidade Pagamento pelo uso Menor custo de manutenção Escalabilidade linear Tolerância a falhas Sob demanda 5
É uma metáfora para a Internet ou infraestrutura de comunicação entre os componentes arquiteturais, baseada em uma abstração que oculta a complexidade de infraestrutura 6
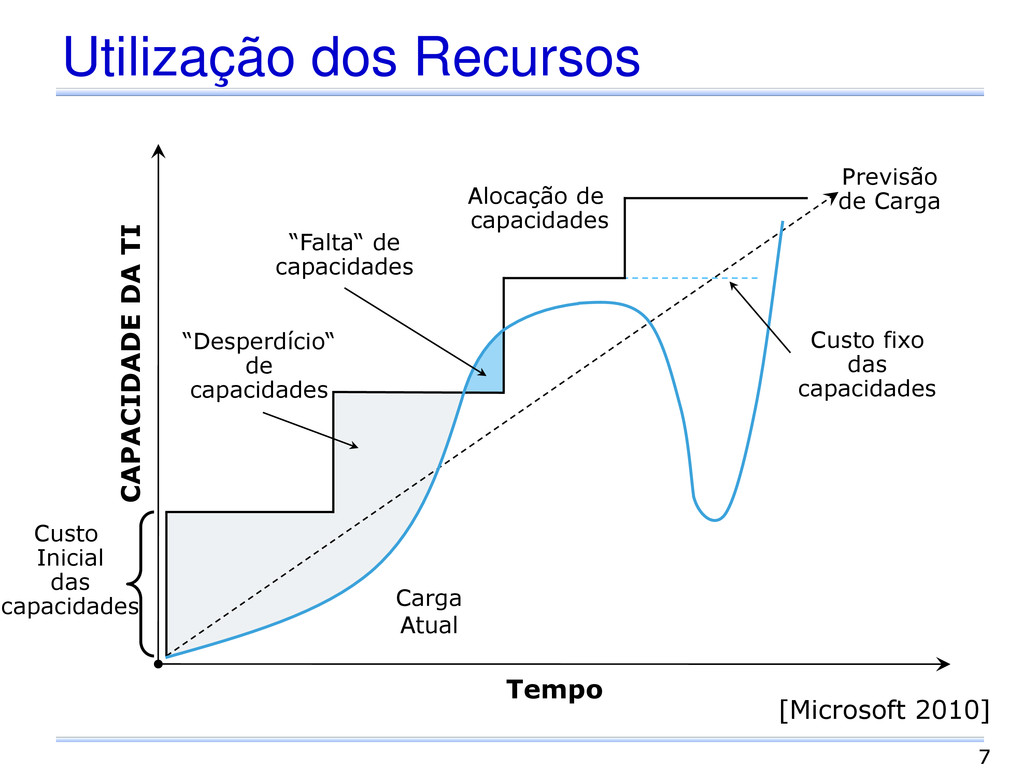
Alocação de capacidades “Desperdício“ de capacidades “Falta“ de capacidades Custo fixo das capacidades Previsão de Carga Custo Inicial das capacidades [Microsoft 2010]
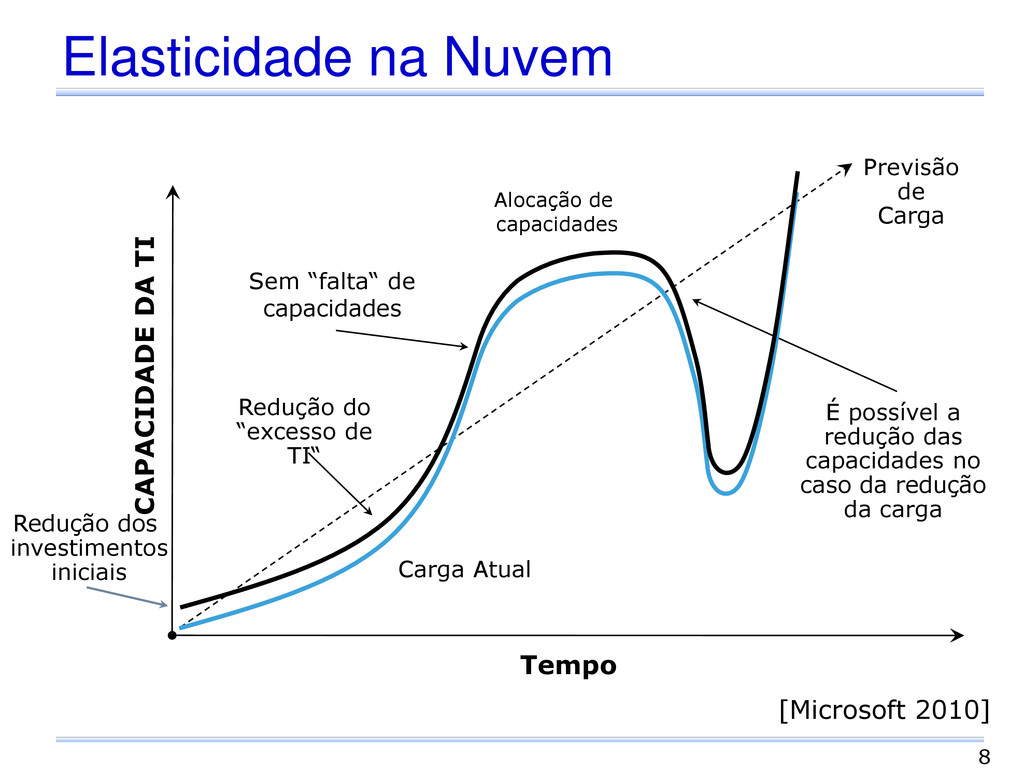
dos investimentos iniciais Redução do “excesso de TI“ Sem “falta“ de capacidades É possível a redução das capacidades no caso da redução da carga Tempo CAPACIDADE DA TI Previsão de Carga [Microsoft 2010]
Standards and Technology, 2009] Computação em nuvem é um modelo que possibilita acesso, de modo conveniente e sob demanda, a um conjunto de recursos computacionais configuráveis que podem ser rapidamente adquiridos e liberados com mínimo esforço gerencial ou interação com o provedor de serviços 10
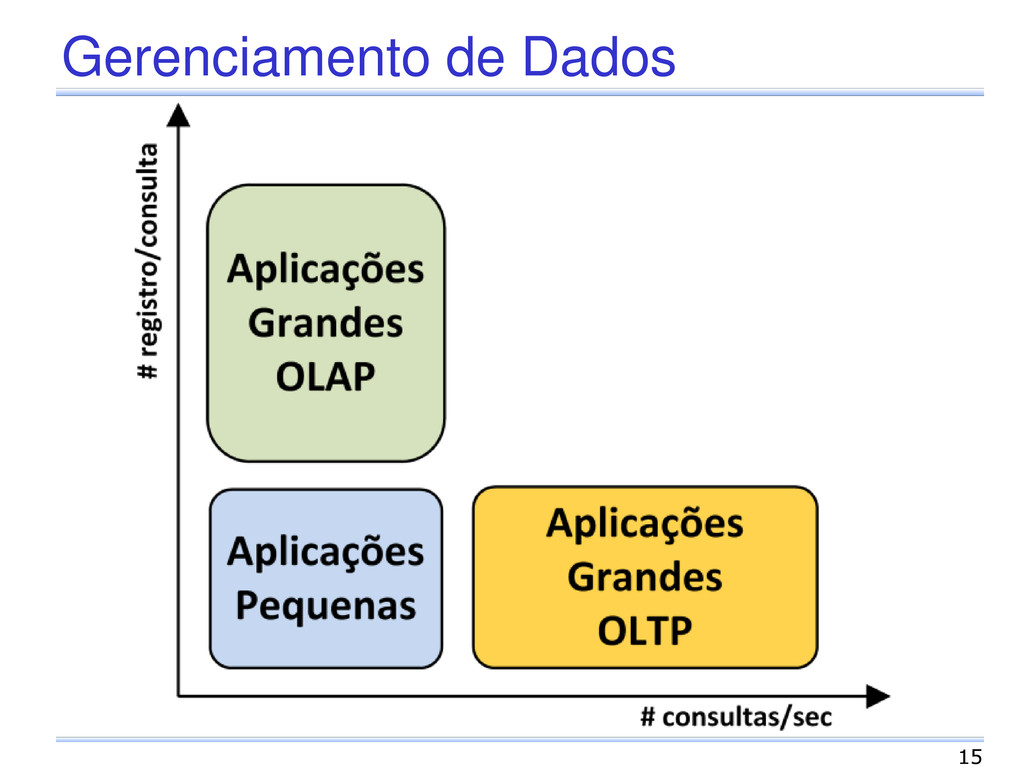
Analytical Processing) OLTP (Online Transaction Processing) Características das aplicações Grandes quantidades de dados Banco de dados único Foco na escalabilidade do banco de dados Pequenas quantidades de dados Múltiplos bancos de dados Foco na escalabilidade da infraestrutura 14
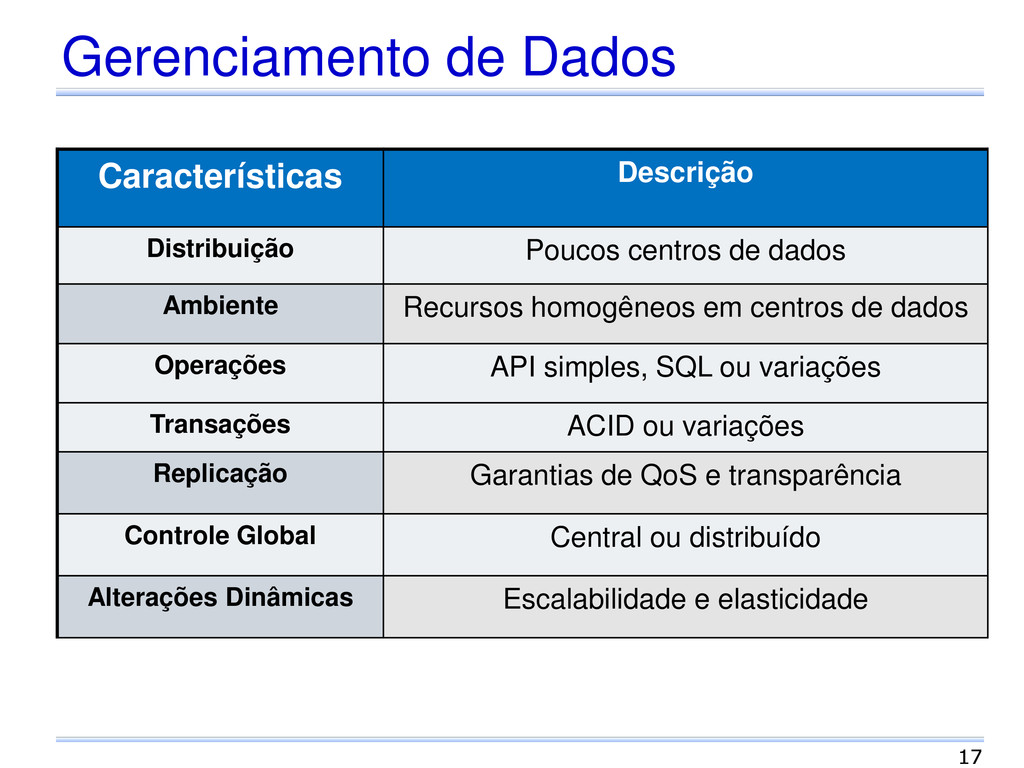
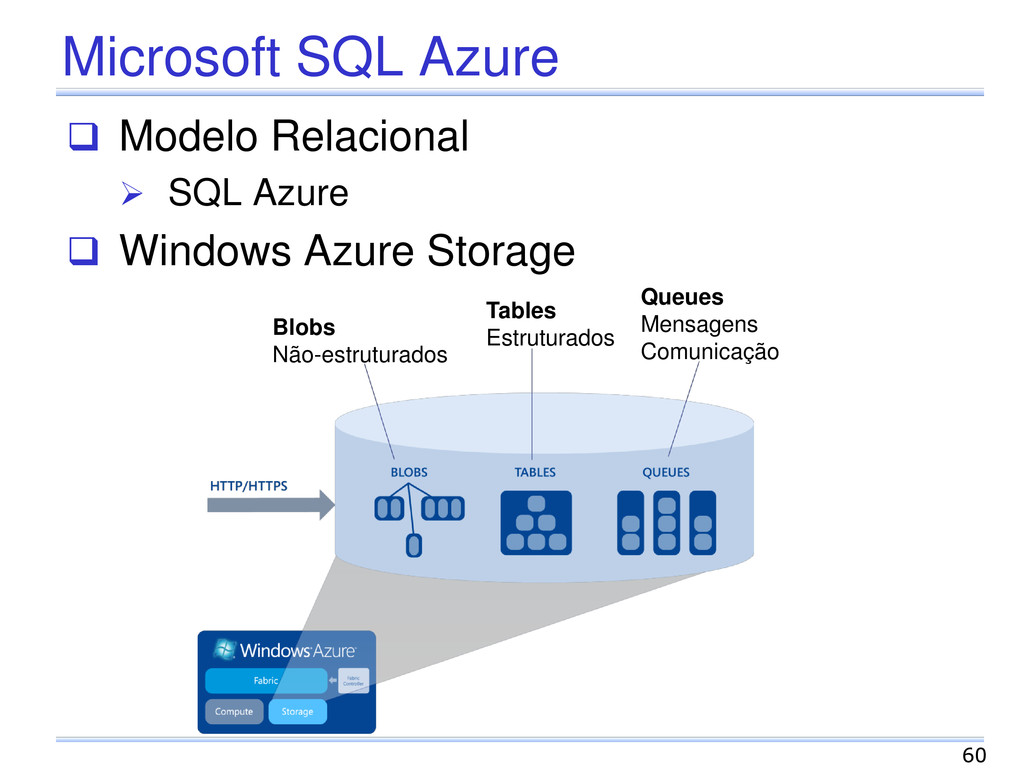
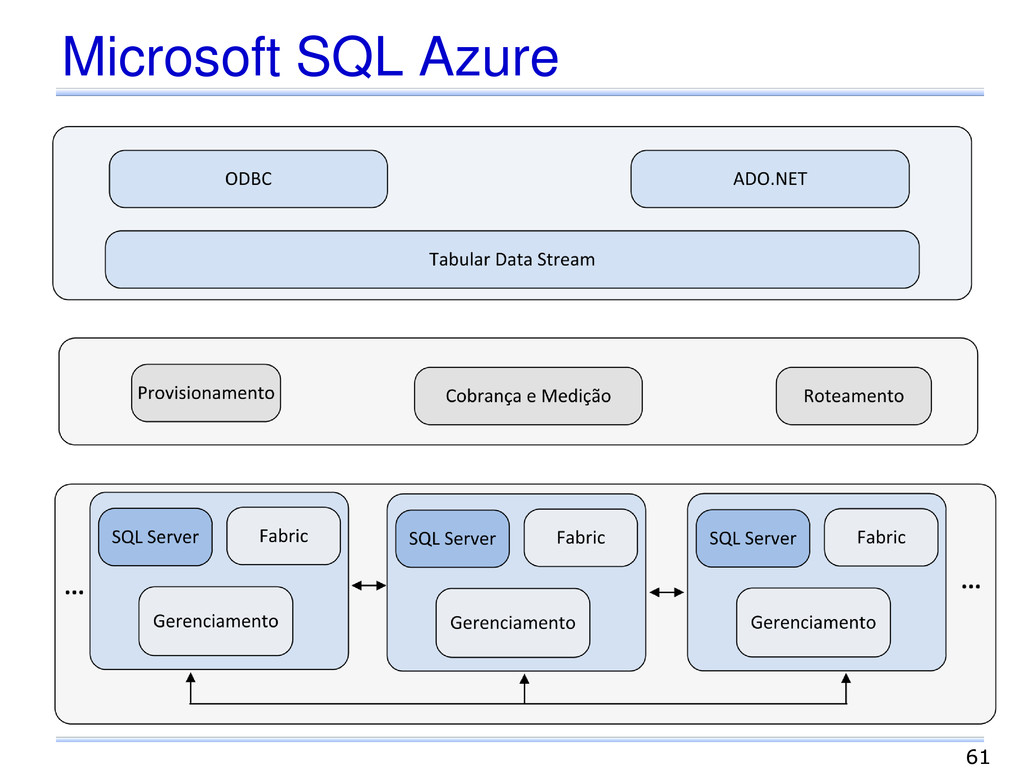
dados Ambiente Recursos homogêneos em centros de dados Operações API simples, SQL ou variações Transações ACID ou variações Replicação Garantias de QoS e transparência Controle Global Central ou distribuído Alterações Dinâmicas Escalabilidade e elasticidade
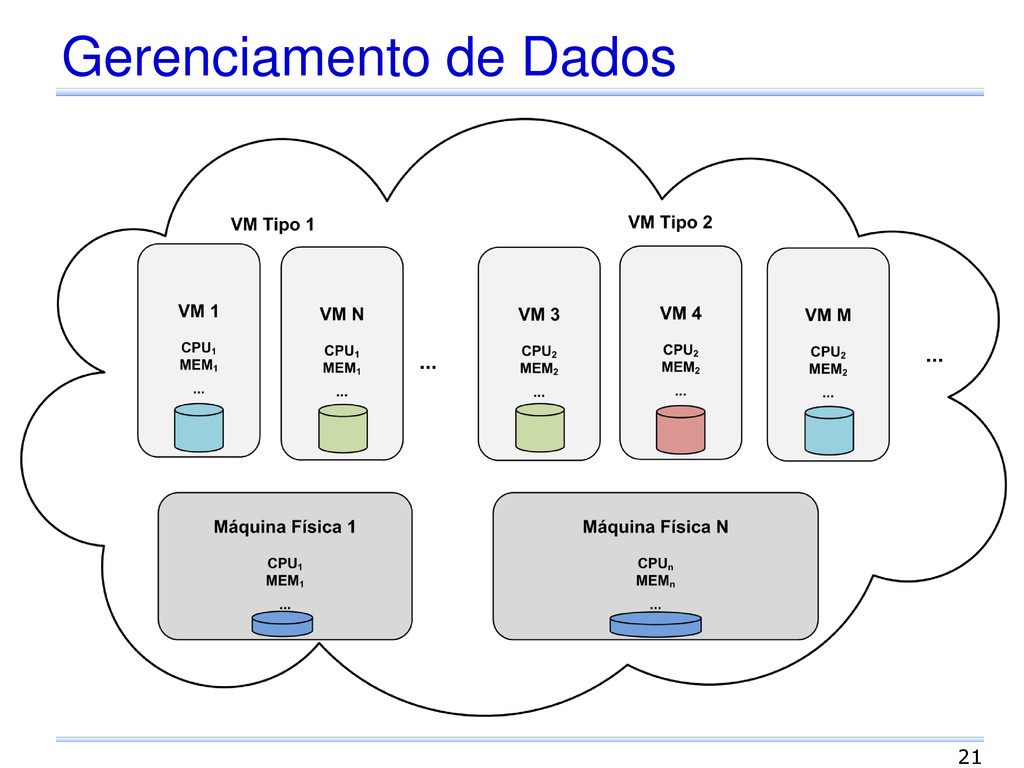
humana limitada Alta alternância na carga de processamento Variedade de infraestruturas compartilhadas Mais recursos disponíveis para administração Atualizações de software mais frequentes 18
são importantes e não-triviais Automação é essencial Experimentação para coletar dados Testes Administração interativa Mudança com a carga de trabalho envolvida 19
e provisionamento flexível de SGBDs Recursos dedicados recursos compartilhados Melhorar a utilização de recursos Simplificar a administração Reduzir custos Introduz pouco overhead no sistema [Minhas et at. 2008] 20
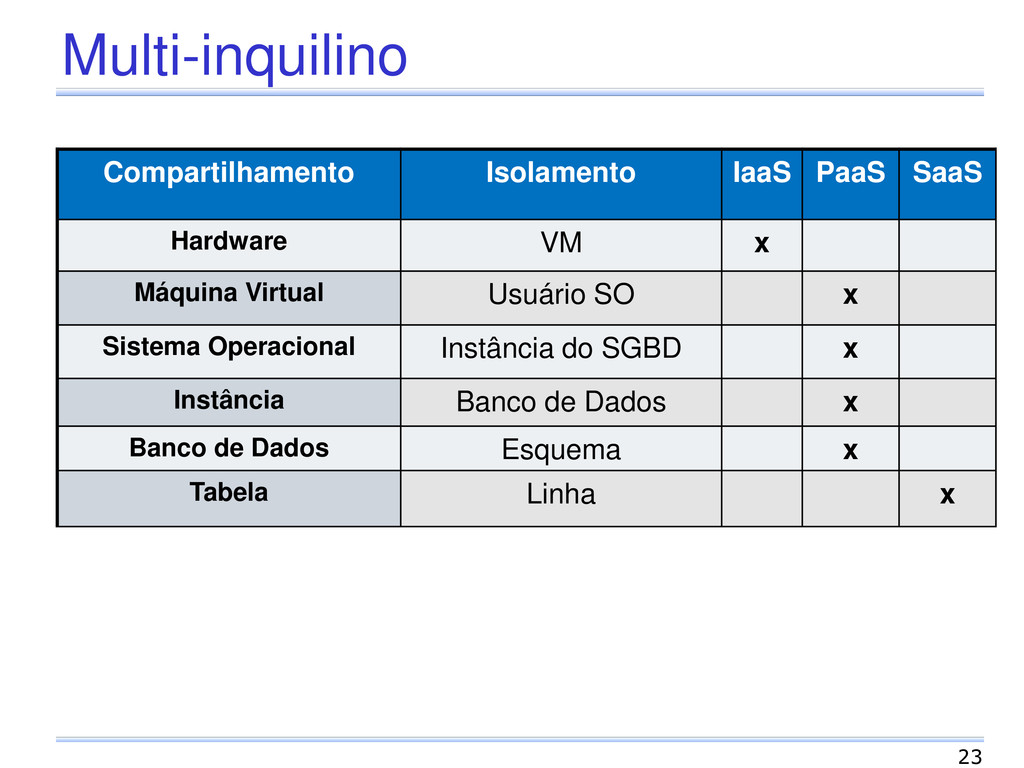
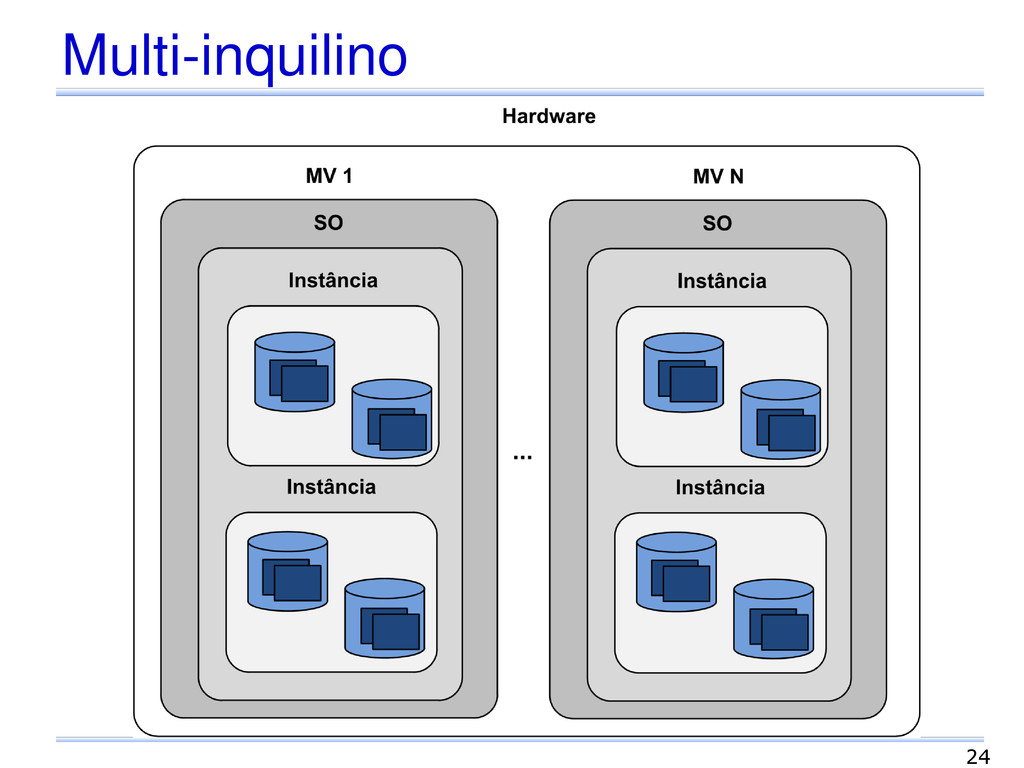
de múltiplos inquilinos em um único sistema Inquilino Um usuário que utiliza uma aplicação SGBD instalado em uma infraestrutura Compartilhamento de infraestruturas entre inquilinos Diferentes níveis de abstração e isolamento 22
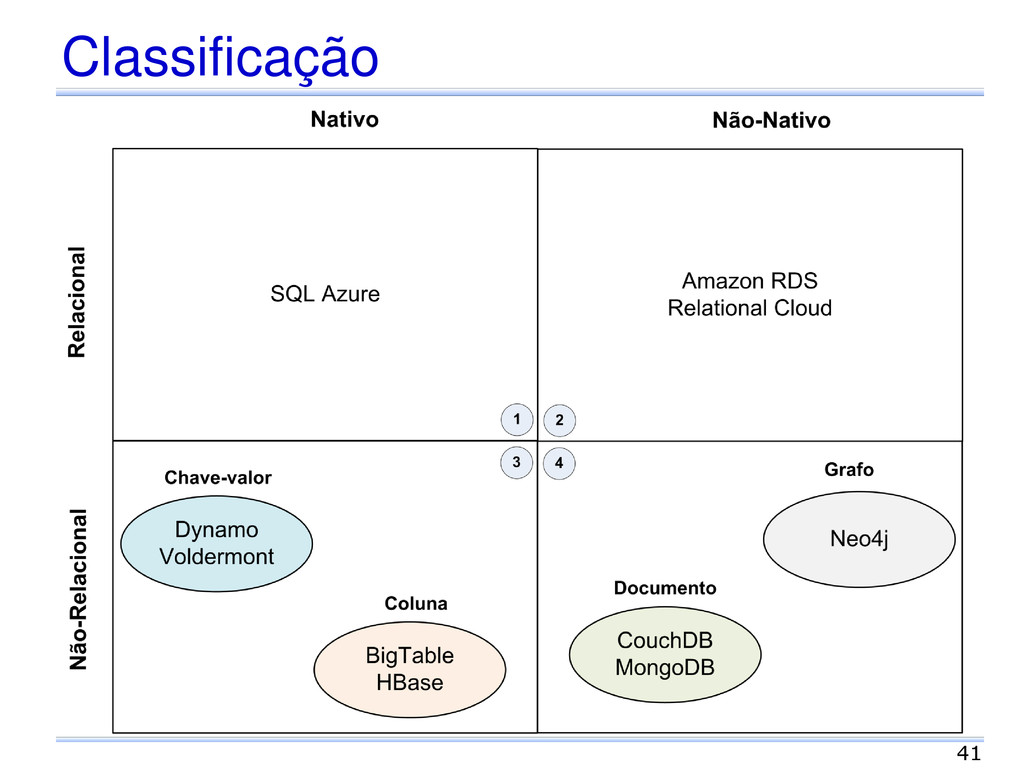
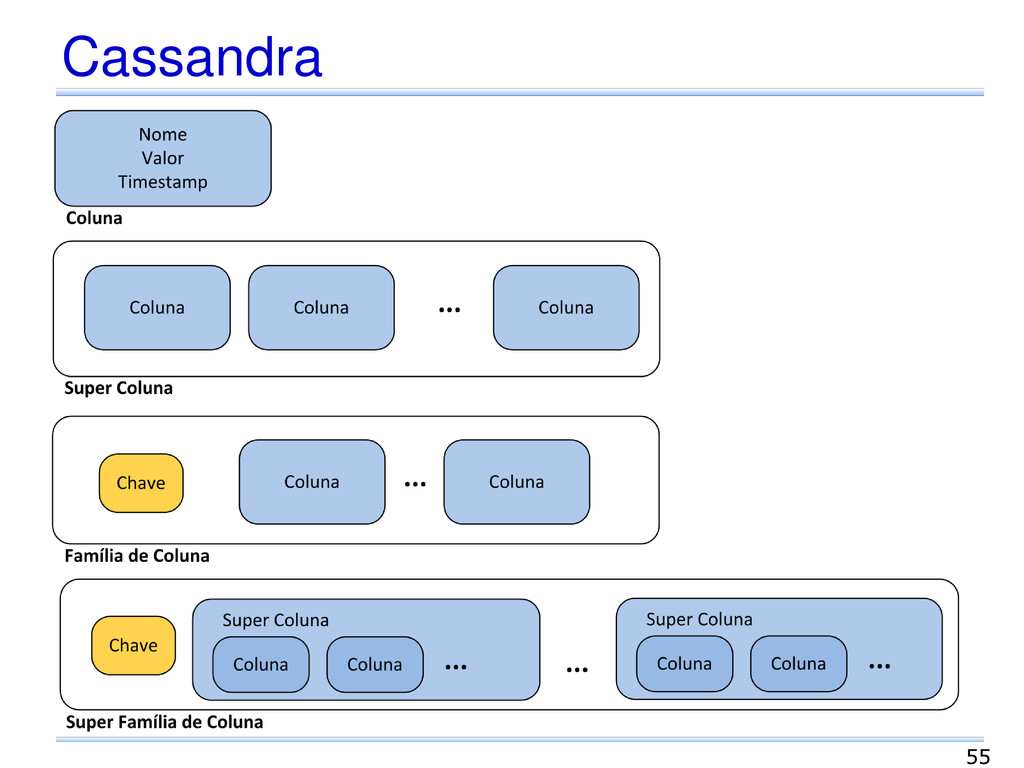
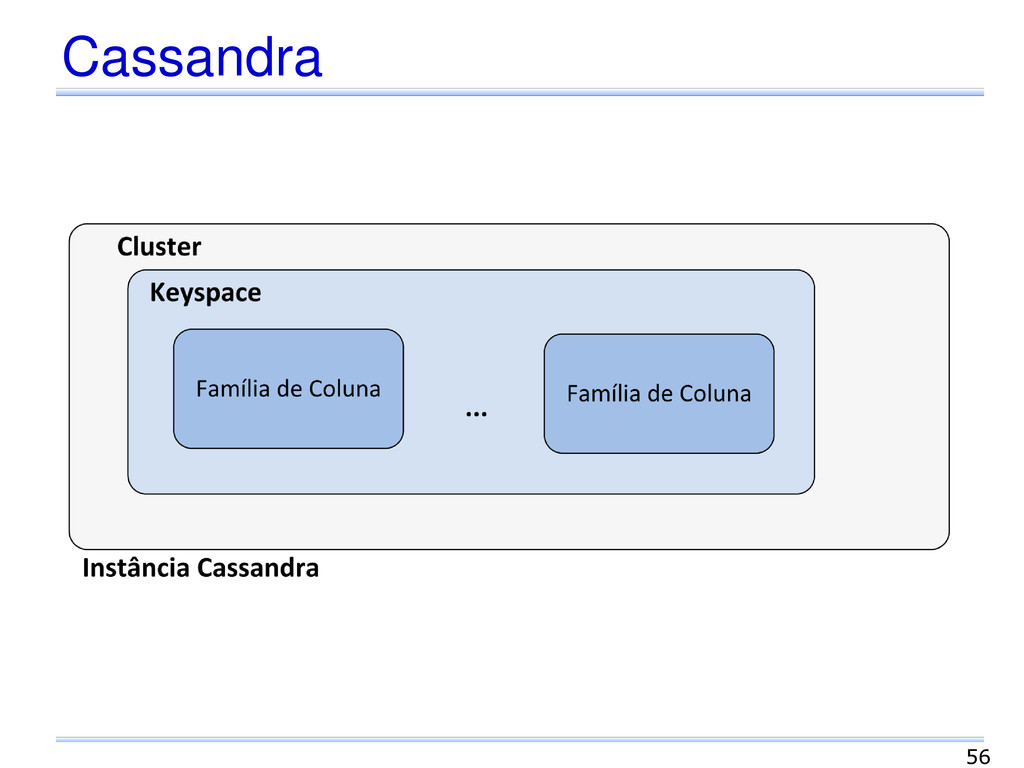
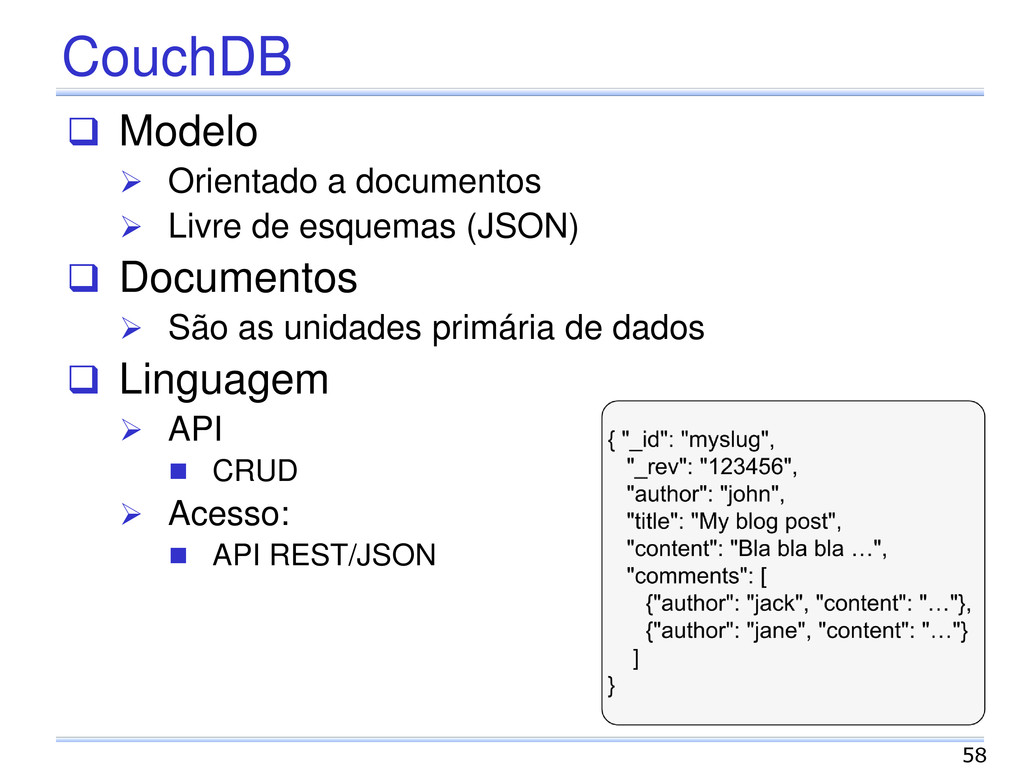
documento Coleção de pares chave-valor Esquema flexível Diferentes formatos: JSON, XML, outros. Grafo Vértices, arestas e propriedades Gerenciamento de dados com estruturas diferenciadas e consultas complexas. 30
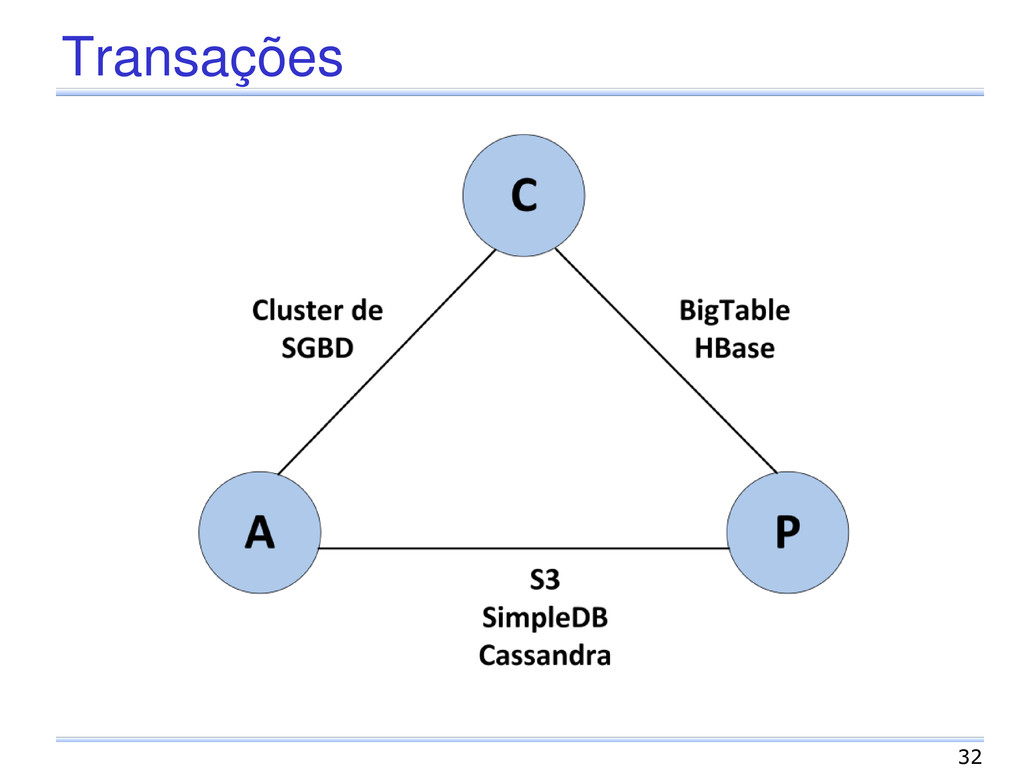
[Gilbert & Lynch, 2002] Um sistema distribuído não pode assegurar as seguintes propriedades de um vez: Consistência Disponibilidade Tolerância a partições 31
consistent) BASE Basicamente disponível Estado leve Eventualmente consistente Consistência eventual O sistema garante que, se nenhuma atualização for feita ao dado, todos os acessos irão devolver o último valor atualizado 34
soluções eficazes Pode comprometer o desempenho no processamento de consultas executadas de forma paralela Garantias de QoS De acordo com o SLA definido Tempo de resposta, disponibilidade, penalidades para o provedor 37
Hardware de baixo custo Máquinas e redes podem falhar As soluções para gerenciamento de dados Devem ser construídas para tratar falhas Técnicas de distribuição Fragmentação Replicação 38
e orientada a coluna Facilita a distribuição dos dados Replicação Diferentes protocolos Cópia primária, Réplica ativa, Paxos, Gossip Técnicas para trabalhar com máquinas virtuais 39
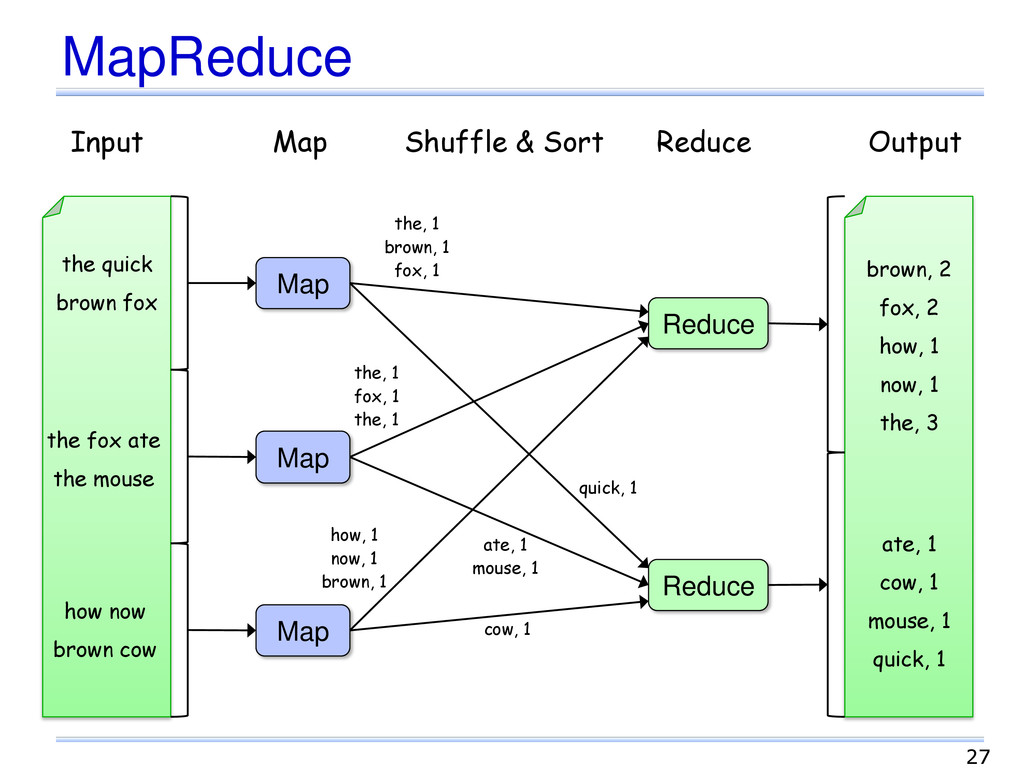
API simples Escalabilidade Consistência eventual O desempenho depende da remoção das sobrecargas [Stonebraker 2010] Logging, bloqueio, gerenc. de buffer, entre outras Tem pouco a ver com o SQL 42
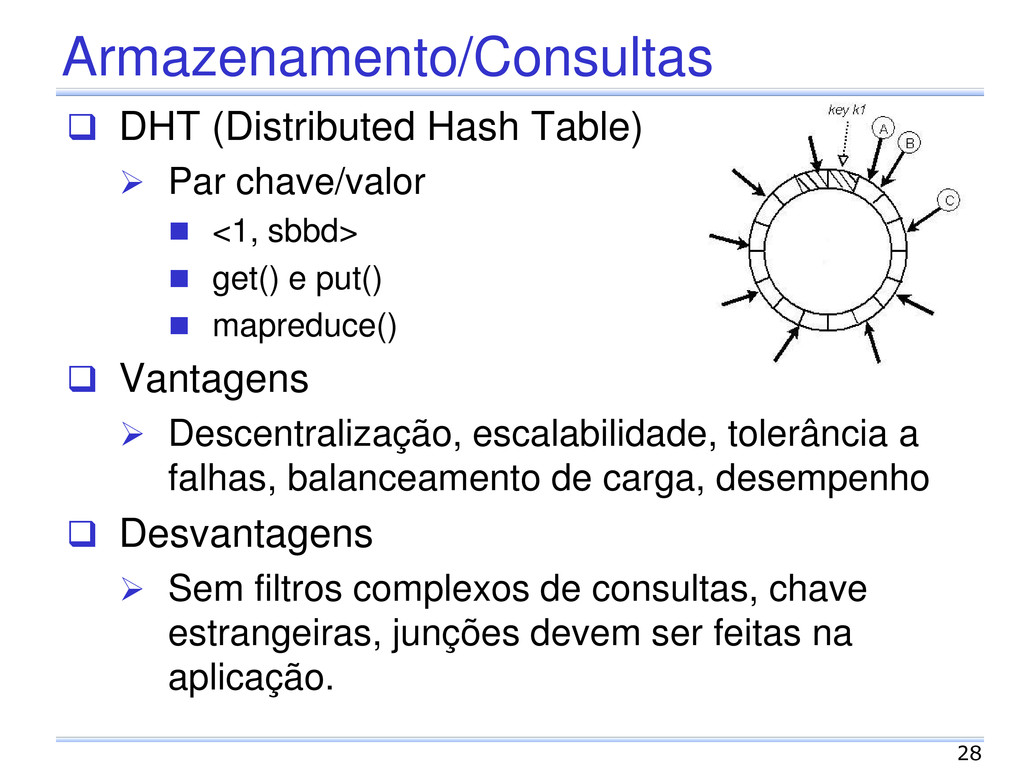
Baseado no Amazon Dynamo Modelo chave valor DHT Escalabilidade, disponibilidade, balanceamento de carga e heterogeneidade Linguagem get() e put() Ausência de transações Consistência eventual 46
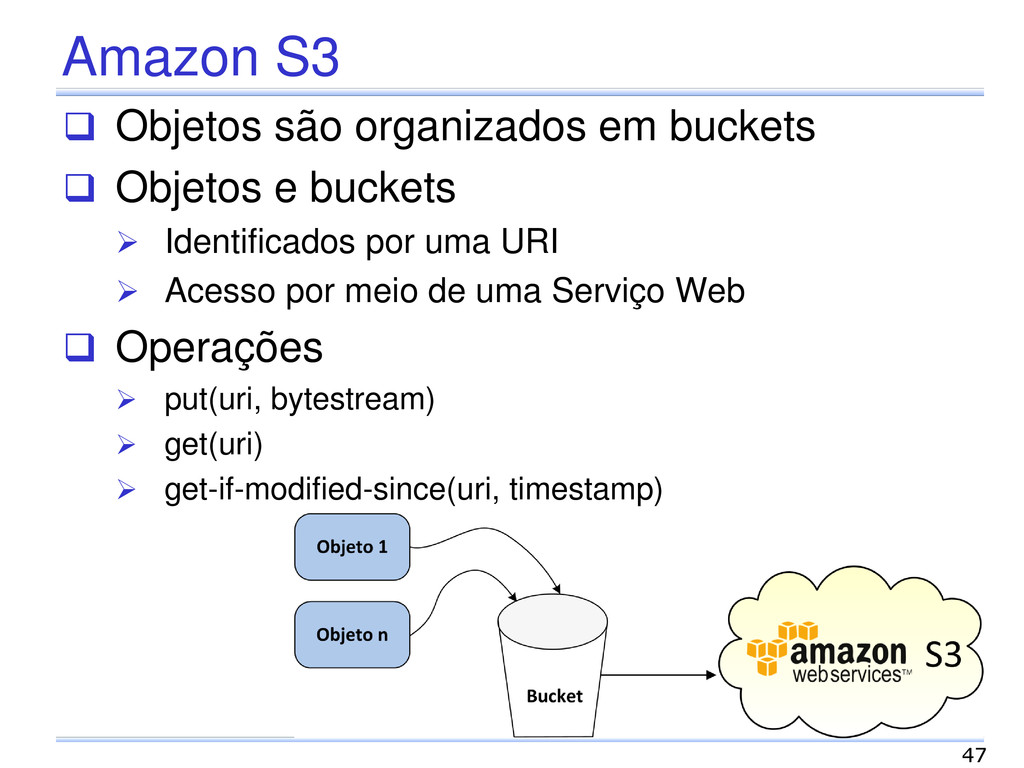
Objetos e buckets Identificados por uma URI Acesso por meio de uma Serviço Web Operações put(uri, bytestream) get(uri) get-if-modified-since(uri, timestamp)
dados estruturados Simples, flexível e escalável Modelo Sem esquema Domínios Similar a uma tabela Item Linhas da tabela acessada por ID (chave primária) Atributo Colunas da tabela 48
domain_name [where expression] [sort_instructions] [limit limit] Sem suporte Junções Transações Esquemas de dados complexos Limitações de tamanho/tipo de domínios e atributos Consistência eventual 49
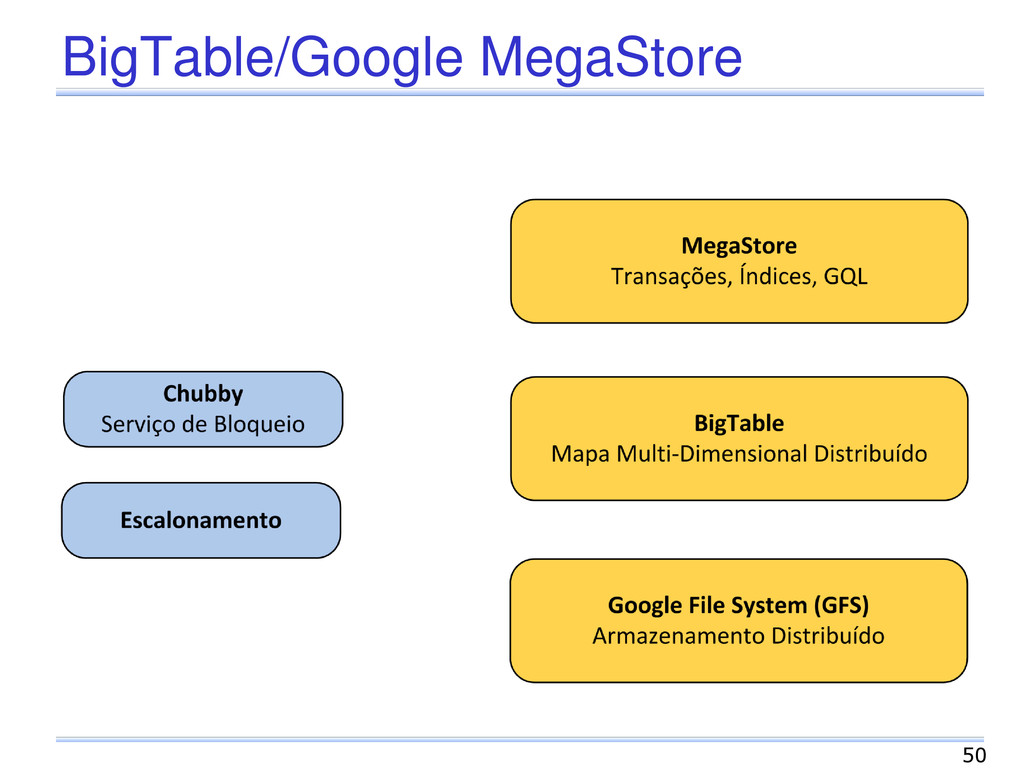
Acesso: API Python e Java GQL (Google Query Language) Select, Where Order By, Limit e In. Transação Suporte a transações por meio das APIs Transações aplicadas a entidades Unidade de consistência, escalabilidade, replicação 53
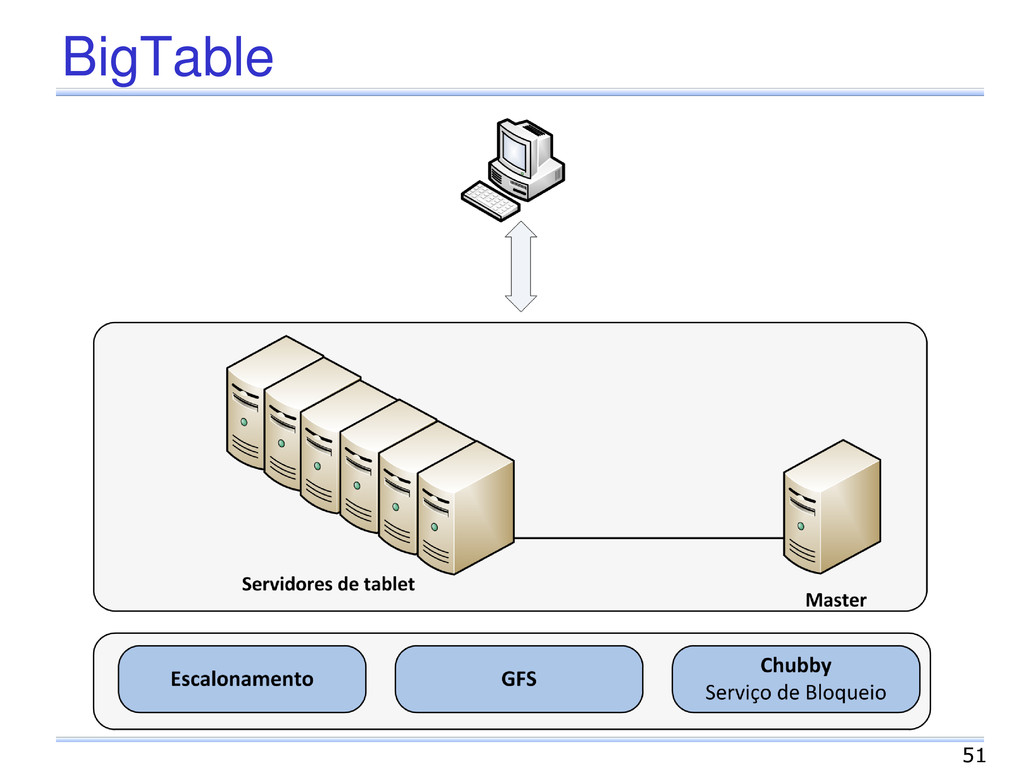
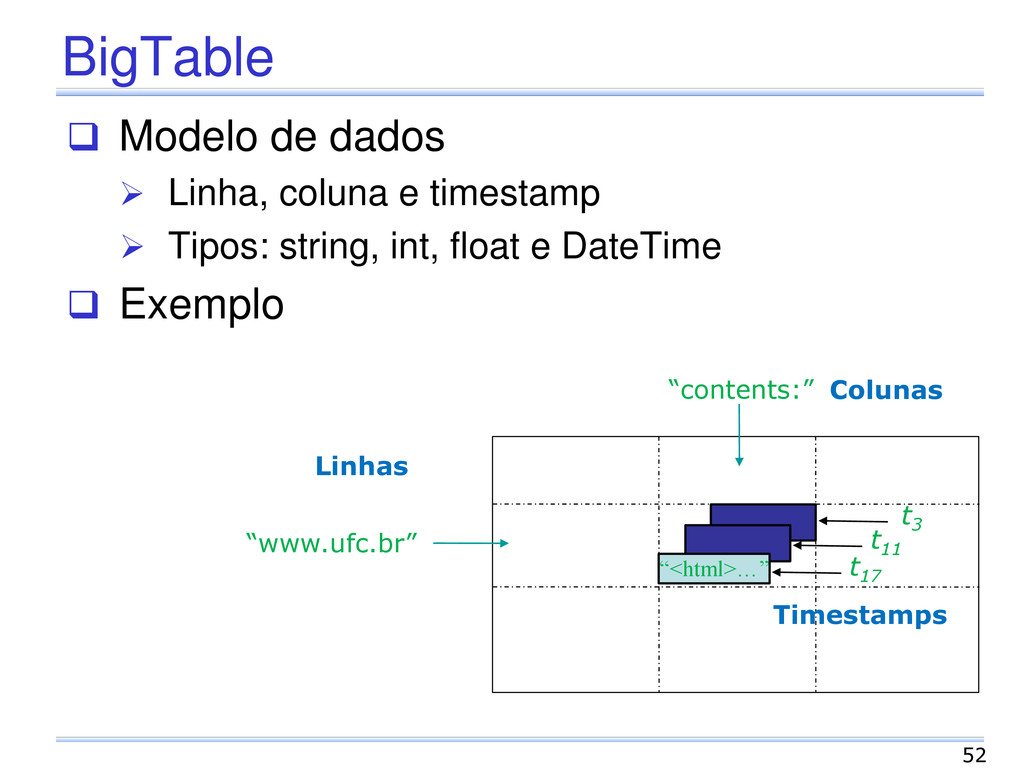
Características de 2 sistemas Arquitetura descentraliza do Dynamo Modelo de dados do BigTable Armazenamento Baseado em índices Linguagem API Simples Instruções de seleção, inserção, atualização e remoção de dados 54
Não suporta transações distribuídas Consistência forte Alta disponibilidade e tolerância a falhas Azure Data Center Implementa o modelo multi-inquilino 62
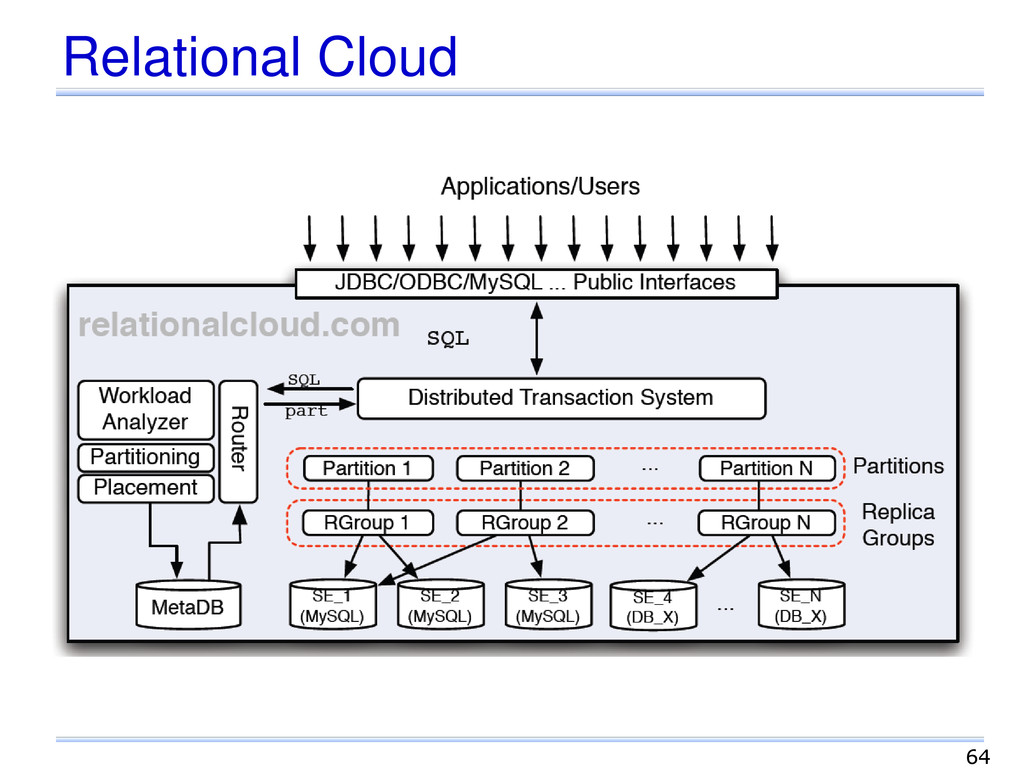
principais do projeto Fragmentação e alocação Análise da carga de trabalho Migração em tempo de execução Linguagem SQL Transação Suporte a transações distribuídas Tratamento de falhas Consistência forte Problemas Escalabilidade e disponibilidade 63
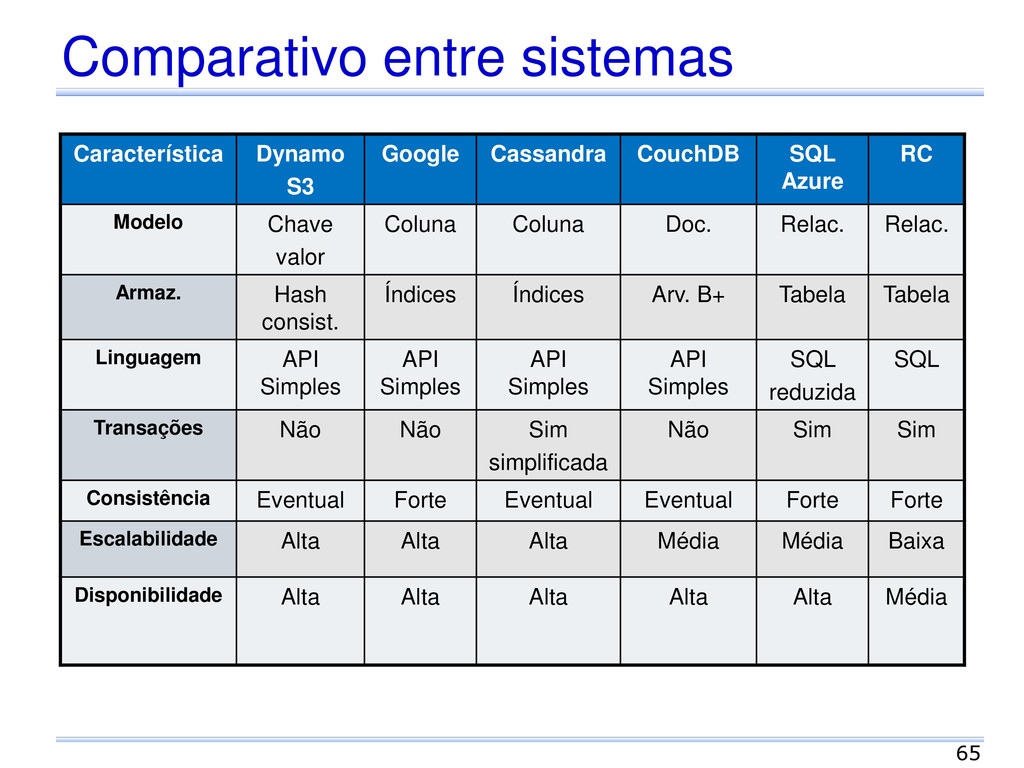
Azure RC Modelo Chave valor Coluna Coluna Doc. Relac. Relac. Armaz. Hash consist. Índices Índices Arv. B+ Tabela Tabela Linguagem API Simples API Simples API Simples API Simples SQL reduzida SQL Transações Não Não Sim simplificada Não Sim Sim Consistência Eventual Forte Eventual Eventual Forte Forte Escalabilidade Alta Alta Alta Média Média Baixa Disponibilidade Alta Alta Alta Alta Alta Média 65
Consistência SGBDs Virtualizados Qualidade dos Serviços de Dados SGBDs Multi-Inquilino Segurança dos Serviços de Dados Desc., Descoberta e Integração de Serviços Avaliação de Serviços de Dados em Nuvem 67
dados e necessidade de gerenciar e analisar Novas arquiteturas para paralelizar o processamento OLAP Desenvolver sistemas que combinem as abordagens OLAP e OLTP Interação com novos sistemas de arquivos e sistemas legados Linguagens com restrições Novas linguagens de consultas API comum para vários serviços 68
diferentes Desenvolver técnicas para prover escalabilidade e elasticidade Construir soluções com suporte a consistência forte Desenvolver soluções para garantir escalabilidade, disponibilidade e consistência 69
utilização dos SGBDs em nuvem Integração das tecnologias de virtualização com SGBDs Tratar cargas de trabalho inesperadas Replicação e fragmentação Provisionar e alocar recursos 70
deve fornecer qualidade Desenvolver soluções com QoS mesmo em condições extremas Técnicas adaptativas e dinâmicas Auto sintonia de parâmetros baseada na carga de trabalho Compreensão automática da carga de trabalho Experimentação 71
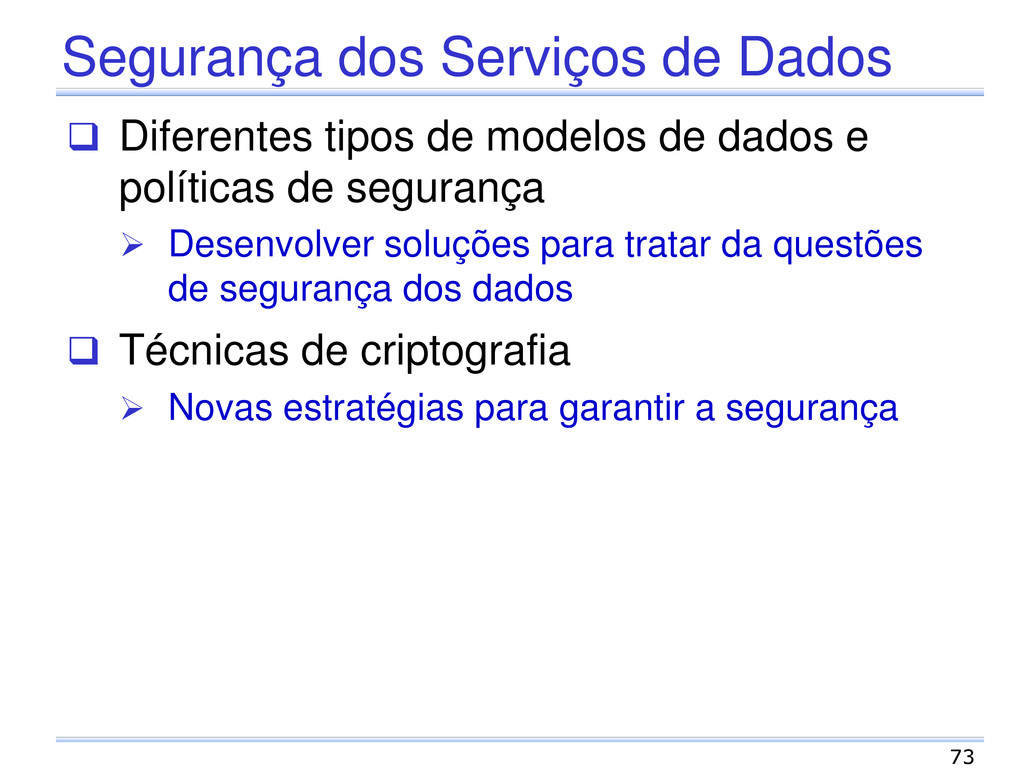
de dados e políticas de segurança Desenvolver soluções para tratar da questões de segurança dos dados Técnicas de criptografia Novas estratégias para garantir a segurança 73
serviços Técnicas para descrever, descobrir e compor serviços Ontologias Diferentes modelos e não existe um padrão de integração Técnicas de integração Desempenho e evolução 74
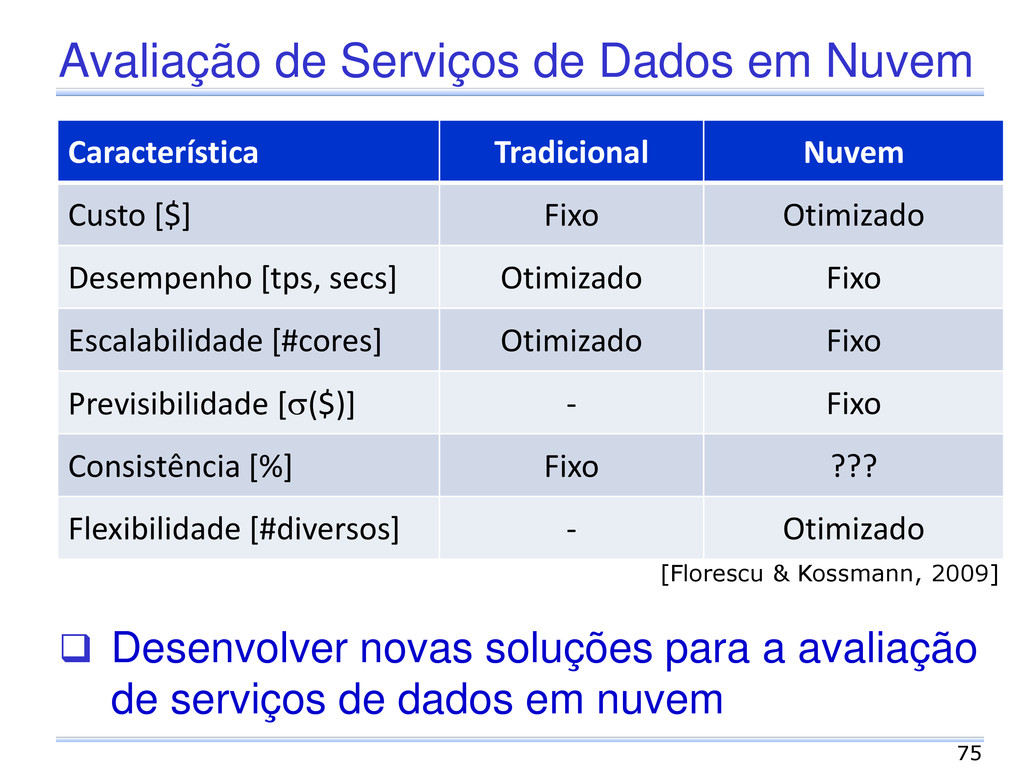
novas soluções para a avaliação de serviços de dados em nuvem Característica Tradicional Nuvem Custo [$] Fixo Otimizado Desempenho [tps, secs] Otimizado Fixo Escalabilidade [#cores] Otimizado Fixo Previsibilidade [s($)] - Fixo Consistência [%] Fixo ??? Flexibilidade [#diversos] - Otimizado Desenvolver novas soluções para a avaliação de serviços de dados em nuvem [Florescu & Kossmann, 2009]
serviços Computação em nuvem está em evolução Muitas iniciativas mas ainda não existe consenso e padrões O gerenciamento de dados em nuvem é um ponto fundamental Existe uma grande quantidade de sistemas para o gerenciamento de dados em nuvem Vários desafios Escalabilidade, segurança, consistência dos dados, elasticidade 76
estes desafios Necessidade de compreender as características das novas aplicações Infraestruturas terão suporte a vários modelos Relacional, chave-valor, entre outros. Comunidade científica e indústria devem interagir Consolidação e ampla utilização da computação em nuvem 77
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Computação em Nuvem Nuvem [Buyya et al. 2009] ](https://files.speakerdeck.com/presentations/847f3ac01ef501307bca1231381a70f4/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Transações Teorema CAP (Consistency, Availability, Partition Tolerance) [Brewer, 2000]](https://files.speakerdeck.com/presentations/847f3ac01ef501307bca1231381a70f4/slide_30.jpg){kind=link}
{kind=link}
![Transações 33 [MongoDB 2010]](https://files.speakerdeck.com/presentations/847f3ac01ef501307bca1231381a70f4/slide_32.jpg){kind=link}
{kind=link}
![Transações 35 ] little.html - yahoos - and - cap](https://files.speakerdeck.com/presentations/847f3ac01ef501307bca1231381a70f4/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigado! Flávio R. C. Sousa [email protected] @flaviosousa www.es.ufc.br/~flavio Perguntas?](https://files.speakerdeck.com/presentations/847f3ac01ef501307bca1231381a70f4/slide_77.jpg){kind=link}