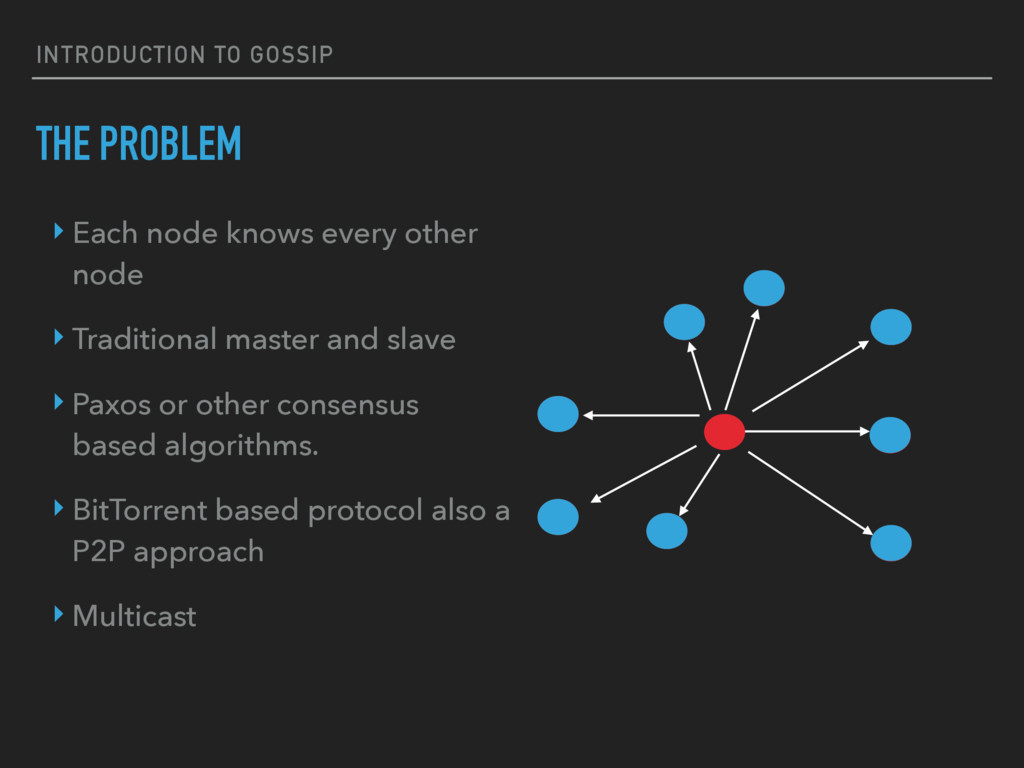
In large Distributed Systems knowing the state of the whole system is a difficult task which becomes harder as we increment the number of nodes. There are too many nodes to communicate with and many algorithms that solve the problem tend to grow linearly with the number of nodes. The underlying network is a problem too, we can’t rely on hardware solutions as they wouldn’t be available in the cloud (e.g. Multicast). It’s also really complex to maintain an updated graph of nodes and even to store the graph itself in large systems.
Many distributed systems nowadays rely on Gossip protocols to share the state of the system among the nodes because they avoid these problems.
A Gossip protocol is a communication protocol, a way of multicasting messages inspired by epidemics, human gossip and social networks.
In this talk we’ll give an introduction to them and we'll show a live demo using flopezluis.github.io/gossip-simulator/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![INTRODUCTION GOSSIP PROPERTIES ▸ They are randomized algorithms. [1] ▸](https://files.speakerdeck.com/presentations/79b9d35241504ba3836161500dd41f0f/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
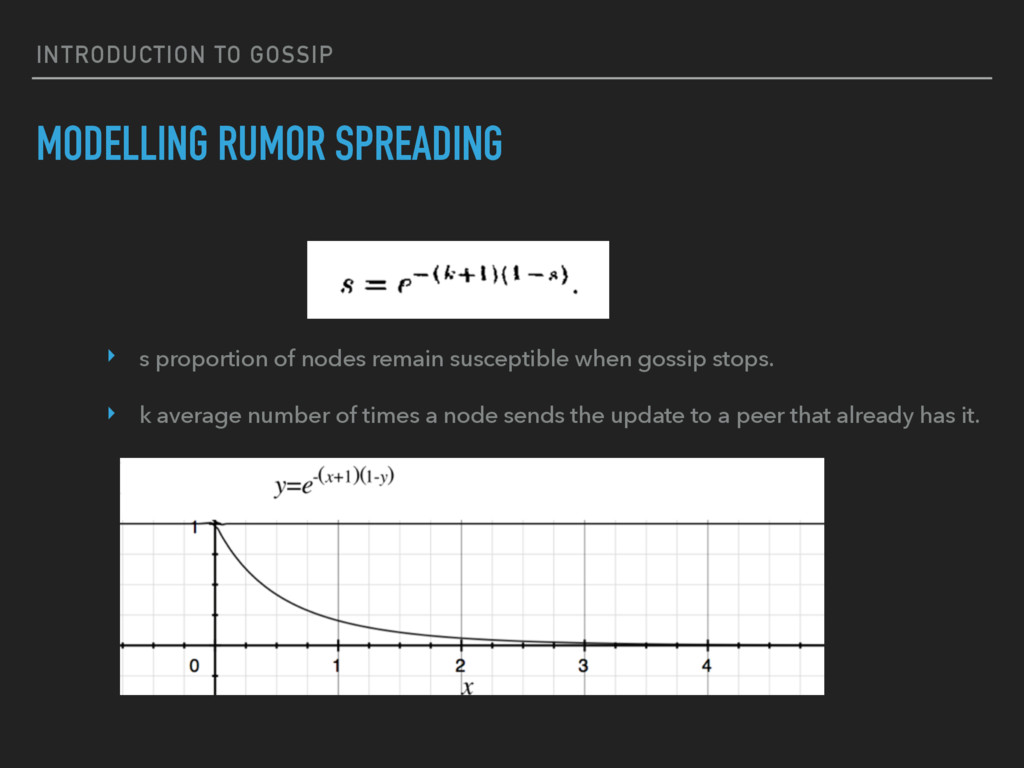{kind=link}
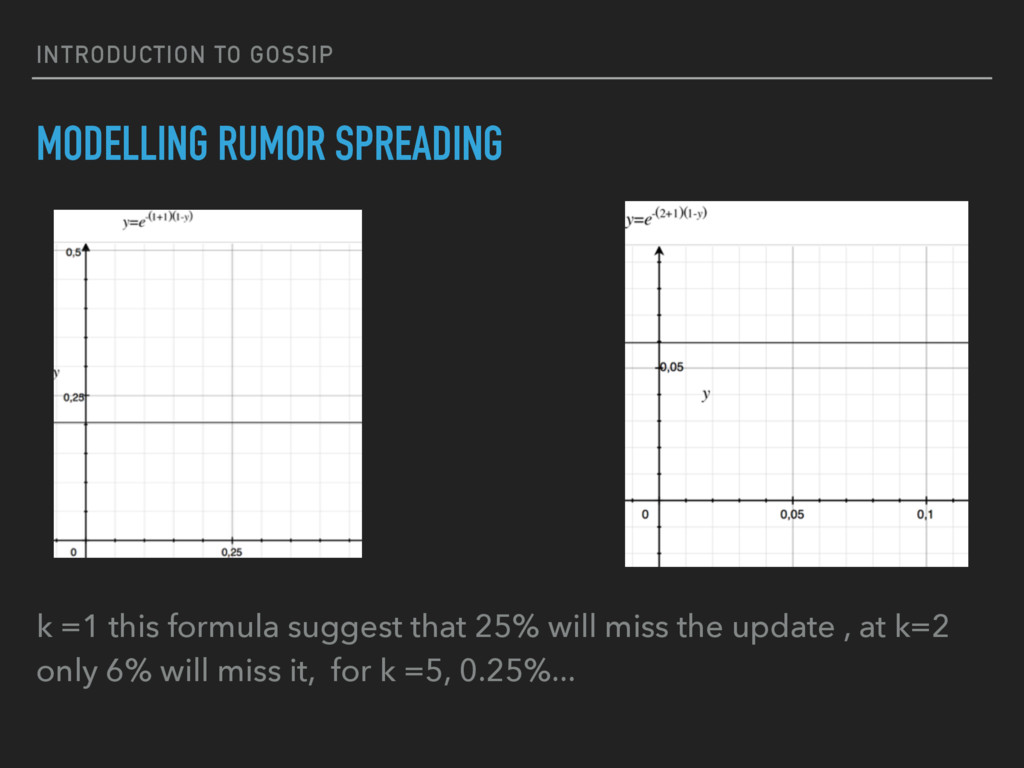{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TEXT REFERENCES ▸ [1] A. Demers, D. Greene, C. Hauser,](https://files.speakerdeck.com/presentations/79b9d35241504ba3836161500dd41f0f/slide_24.jpg){kind=link}
![TEXT REFERENCES ▸ [7] JELASITY, M., GUERRAOUI, R., KERMARREC, A.-M.,](https://files.speakerdeck.com/presentations/79b9d35241504ba3836161500dd41f0f/slide_25.jpg){kind=link}
![TEXT REFERENCES ▸ [13] Montresor, A.: Intelligent Gossip. In: Studies](https://files.speakerdeck.com/presentations/79b9d35241504ba3836161500dd41f0f/slide_26.jpg){kind=link}
{kind=link}