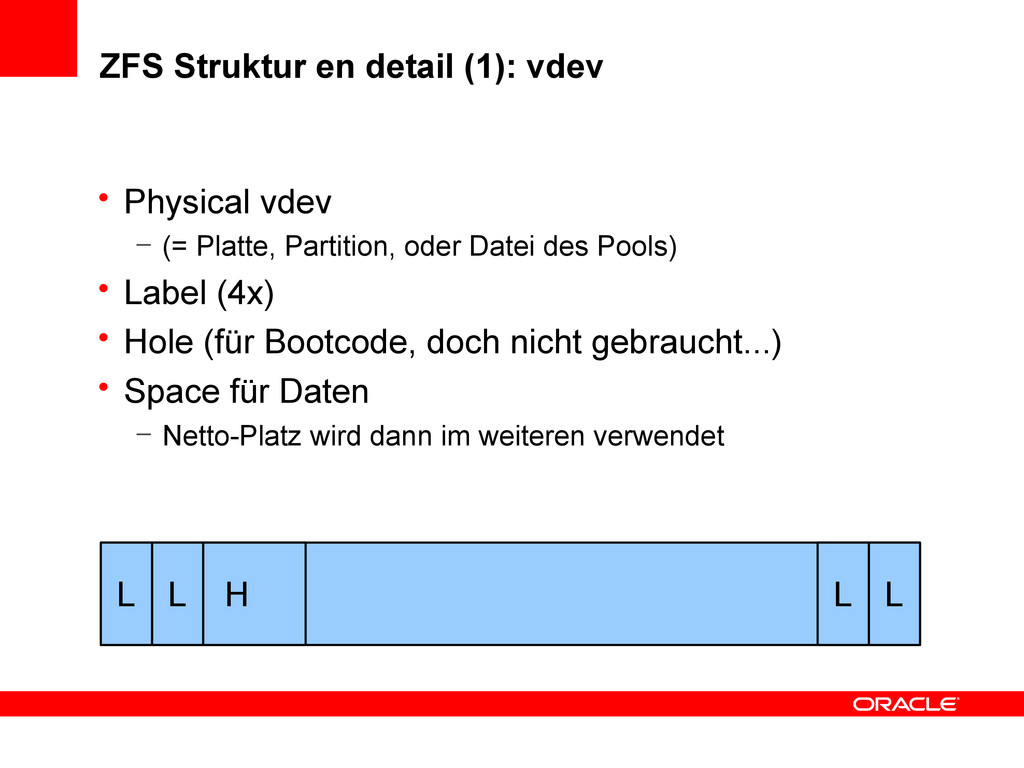
(= Platte, Partition, oder Datei des Pools) • Label (4x) • Hole (für Bootcode, doch nicht gebraucht...) • Space für Daten – Netto-Platz wird dann im weiteren verwendet L L L H L
zpool properties • alle Platten, Konfiguration der vdevs • Name, host, guid, .... – 128 uberblocks (Magic number: 0x00bab10c ;-) • uberblock – checksum, versionsnummer – blockpointer, 128 Byte gross, der neueste valide bp gilt • zeigt auf block im netto-Platz • 3 Adressen haben Platz im – Zeigt auf meta object Set
dnode, wie inode, quasi der Pointer auf ein Objekt – Unix Standard-Attribute (bonus buffer) – 3x blockpointer, dh. 3x 128k (recordsize) direkt adressierbar • ggf. indirekt (1024 blockpointer in einem 128k block) • innere Knoten sind immer 128k (nicht recordsize) • dnode list – Objekt – enthält nur dnodes • ZAP object – Objekt – Hash Struktur (Name -> Wert) – für Directories, ZFS-Hierarchien, Properties, ACLs, xattr, ....
– ist Liste von Objekten (dnode list) • ZFS properties (ZAP object) • Unter-Objecte (ZFS, ZFS Volume, nur nächste Stufe) • Liste der Objekte im ZFS – Alle Dateien, Directories (bei Filesystem) – Pointer auf raw device (bei Volume) • Liste der abhängigen Objekte: snapshot, clone • Pointer auf Log • Pointer auf gelöschte Blöcke – Meta Object Set: nur der oberste Object Set • hat zusätzlich Verwaltungsinfos
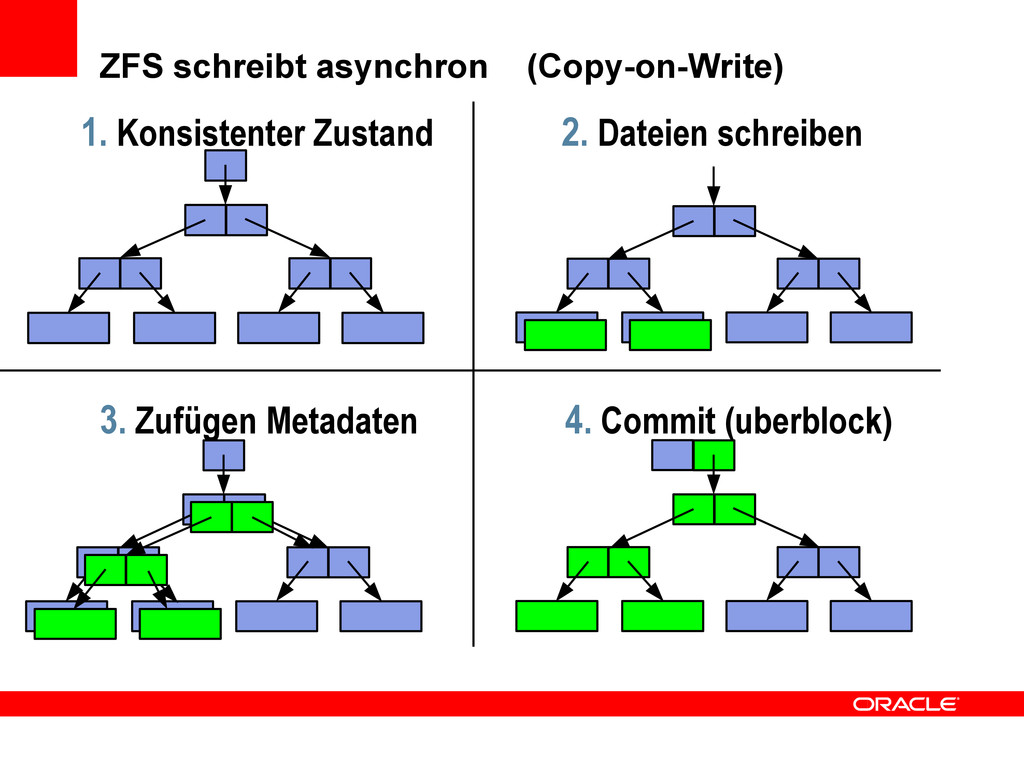
konsistenter Baum – ausgehend vom neuesten konsistenten uberblock – Enthält Baum über die object sets – inclusive der Allokationsinformationen – und freizugebender Blöcke • 2. Geschriebene Daten landen in neuen Blöcken (recordsize) – Bleiben erstmal im Hauptspeicher (ARC) – Dienen auch zum Lesen des (neuen) Inhalts
Transaktion zusammengefasst – Daten mehrerer Dateien in Transaktionsgruppen – Blöcke bis zum root Knoten werden erneuert • Noch gültige Informationen werden kopiert (copy) • Neue Informationen werden hinein geschrieben – Zusammen liegende freie Blöcke im zpool werden ausgewählt ... – ... und effizient (sequentiell) beschrieben – Update Allokationstabellen (frei/benutzt) gleichzeitig
des nächsten uberblock – ca alle 5 - 30 Sekunden – -> alle Labels auf allen physical vdevs – Ist einer geschrieben, gilt der neue Zustand – Der vorige Zustand ist wiederherstellbar – Blöcke gehen nicht verloren • Allokationstabellen werden gleichzeitig aktualisiert • Alle Veränderungen der Transaktionsgruppe auf einen Schlag
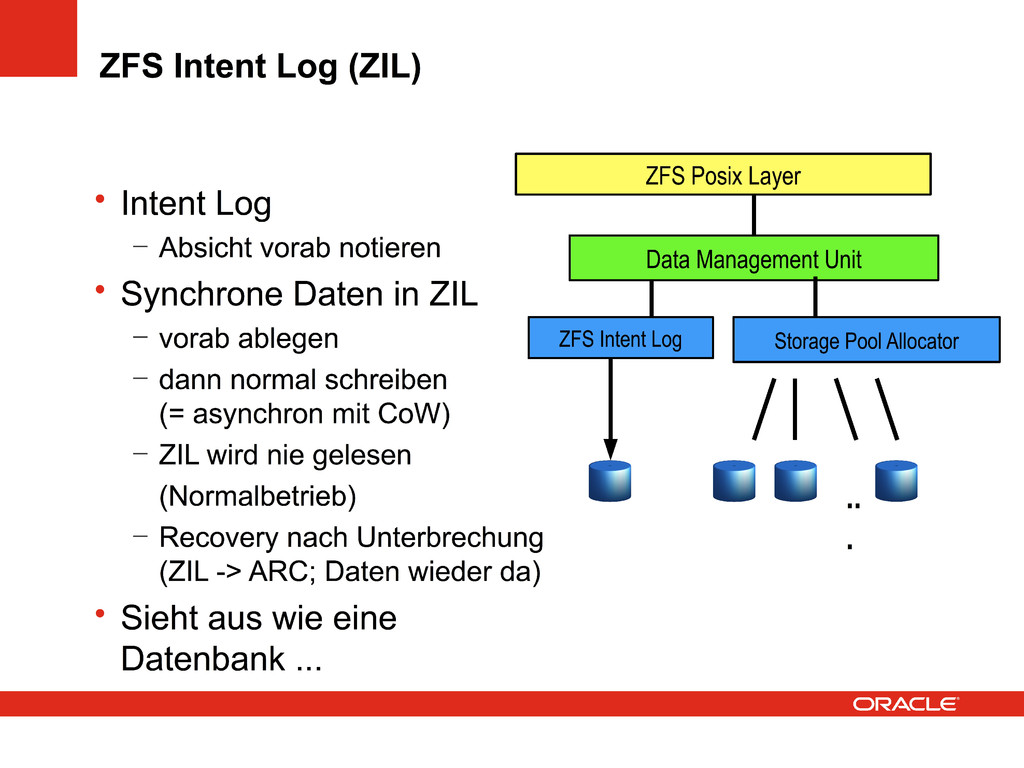
open mit O_SYNC, O_DSYNC – fsync() System call für Datei – sync (für alle Filesysteme) – NFS 3 und 4 (Client sended sync request) • sync on close (Client ggf. konfigurierbar) – Erwartung: Daten sicher geschrieben, wenn die Applikation auf dem Client beendet ist • ggf. fordert viel Schreiben ein sync heraus wenn er Client nichts mehr puffern kann – Samba / CIFS – Blockorientierter Zugriff, ZFS Volumes, iSCSI, FC, iSER
device legen – zpool add log device • SSD kann viele IOs und kann schnell sequentiell schreiben • LUN von Storage Subsystem mit batteriegepuffertem Cache ist auch klasse • Dedizierte Platte (nicht Partition!) geht auch – Dann haben die IOs auf die Datenplatten Zeit – Synchrone Writes erzeugen Last wie asynchrone Writes
ja dann immer 2x geschrieben • log device – zu langsam (Datenrate) oder zuwenig IOs • und man hat viele Platten • Dann: zfs set logbias=throughput • Daten werden dann direkt auf die Datenplatten geschrieben und beim CoW eingehängt – Blöcke < 32kb: sowieso immer default – Daten werden dann nur noch einmal geschrieben – Alle Platten helfen mit...
Cache auf SSD • (SSD wegen der schnellen Positionierung) • Wird aus dem ARC gefüllt • Abgesetzter Algorithmus (nicht exakt...) • Lohnt sich für / und Home-Directory • 240 Bytes pro Block werden in den Metadaten gebraucht...
– oder Hauptspeicher - Applikationen - 1 GB – siehe kstat, oder dtrace • 25% des ARC sind Metadaten – (S11 oder ZFSSA kein Limit mehr) • Dedup: 360 Byte pro Block (recordsize) – kann viel sein • Wenns nicht passt, dann mehr random IO
set bestimmen – Metadaten sollten in den Hauptspeicher passen zur Vermeidung doppelter reads • Genug Hauptspeicher • Anzahl Platten nach Anzahl reads bestimmen – Alles ist random! – Wenn nur Datenrate bekannt ist, mit recordsize in IOs umrechnen
dnode (512 Byte) zählen auch als metadata • Dateien in dieser Größenordnung haben daher anteilig viel Metadata • Beispiel: Telco A – Kunde hat ca. 1 Milliarde Dateien von 500 - 1500 Bytes (Wiki und Message System einer kleineren Telco) • Abschätzung: Annahme: jede Datei ist 1 KB gross. • Jeder dnode ist 512 Byte gross • 1 Millarde Dateien brauchen 1 TB Platz für die Daten und 512 GB Metadaten • Die Performance ist lausig (viele IOs)
ist für Durchsatz optimiert – Datenblöcke werden aufgeteilt – auf möglichst viele Datenplatten verteilt – Lesen von den Platten gleichzeitig => hohe Datenrate – Lesen eines Blockes -> lesen auf verschiedenen Platten – ~raidz liefert soviele IOs wie eine einzelne Platte (Anzahl Vdevs * IOs einer Platte) • mirror: 2 volle Kopien – Lesen wird random verteilt – Lesen eines Blockes -> 1/2 Lesen auf jeder Platte mirror erlaubt mehr IOs (= Anzahl Platten * IOs einer Platte)
der Daten bei Datenbanken • zfs set secondarycache=metadata bei ganz grossen Filesystemen • zfs set atime=off last access date wird sonst häufig upgedatet und erhöht die synchrone Schreibrate
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}