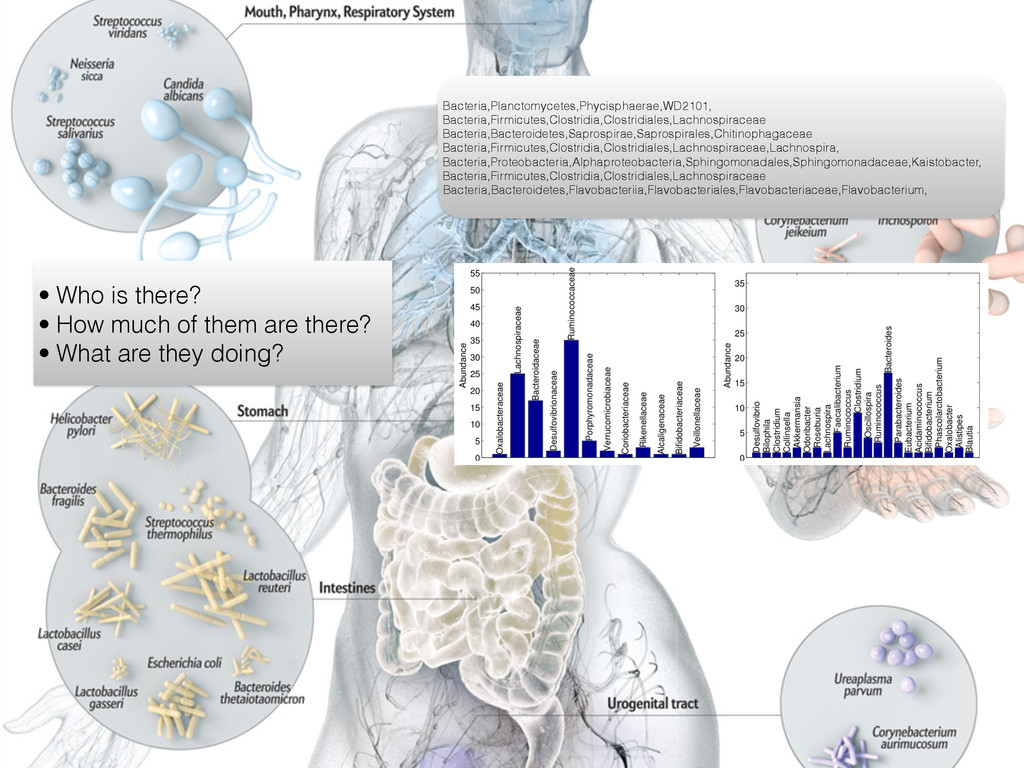
there? • What are they doing? Bacteria,Planctomycetes,Phycisphaerae,WD2101, Bacteria,Firmicutes,Clostridia,Clostridiales,Lachnospiraceae Bacteria,Bacteroidetes,Saprospirae,Saprospirales,Chitinophagaceae Bacteria,Firmicutes,Clostridia,Clostridiales,Lachnospiraceae,Lachnospira, Bacteria,Proteobacteria,Alphaproteobacteria,Sphingomonadales,Sphingomonadaceae,Kaistobacter, Bacteria,Firmicutes,Clostridia,Clostridiales,Lachnospiraceae Bacteria,Bacteroidetes,Flavobacteriia,Flavobacteriales,Flavobacteriaceae,Flavobacterium,
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}