with Bayes and were able to derive our first classifier: Bayes linear/quadratic discriminant classifier. • Our goal in this lecture set is to learn a new set of empirical tools to build a classifier that is linear • The objective is to focus on the mapping from the input to the output g(x) : X → Y • Note this mapping does not make an explicit choice to model p(x|Y ) • This lecture also introduces us to stochastic gradient descent which is an optimization technique that is very important in machine learning and one you will become very familiar. 4 / 44
the data to estimate probabilities/probability distributions of each quantity such as priors: p(ω), likelihoods: p(x|ω), and evidence p(x). • This is equivalent to attempting to directly estimate the joint distribution p(x, ω) and normalizing to obtain posterior probabilities • Hence why these are called generative models because it is possible, using the estimated quantities, to generate synthetic data in the input space. Discriminative Models • Discriminative models are map the input–output g(x) : X → Y and are generally lower complexity, since we do not attempt to model the joint distribution p(ω, x) • This direct estimation of the posterior prevents us from determining certain attributes of the data that could be provided with using a generative method, such as outlier detection. 5 / 44
D := {(xi, yi)}n i=1 • Define the model: g(x) = wTx + w0 • Define the loss: J(w, w0) = 1 2n n i=1 (yi − g(xi))2 = 1 2n ∥y − Xw∥2 2 where w ∈ Rd, x ∈ Rd, w0 ∈ R, y ∈ Rn and X ∈ Rn×d. Goal Our goal is to find the parameters that minimize the loss J. How do we minimize a function? That is right! Take with derivative! 7 / 44
we were provided X and y we can minimize the function by taking the derivative w.r.t. the parameters and set the derivative equal to zero. J(w, w0) = 1 2n ∥y − Xw∥2 2 = 1 2n (y − Xw)T(y − Xw) ∂J ∂w = − 1 n XT(y − Xw) = 0 −→ w = (XTX)−1XTy In Code: def linreg(X, y): return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), y) 8 / 44
Train: w = (XT T r XT r )−1XT T r yT r • Test: y = wTx • XTX must be invertible, which is not guaranteed for any arbitrary dataset. • If either d or n (or both) are large, it would be computationally expensive to implement this model. • We can add regularization into the cost function (e.g., +λ∥w∥2 2 ). • Regularization can be used to reduce overfitting • ℓ1 regularization can be used to induce sparsity in the solution. • This is going to be a future homework question. . . 9 / 44
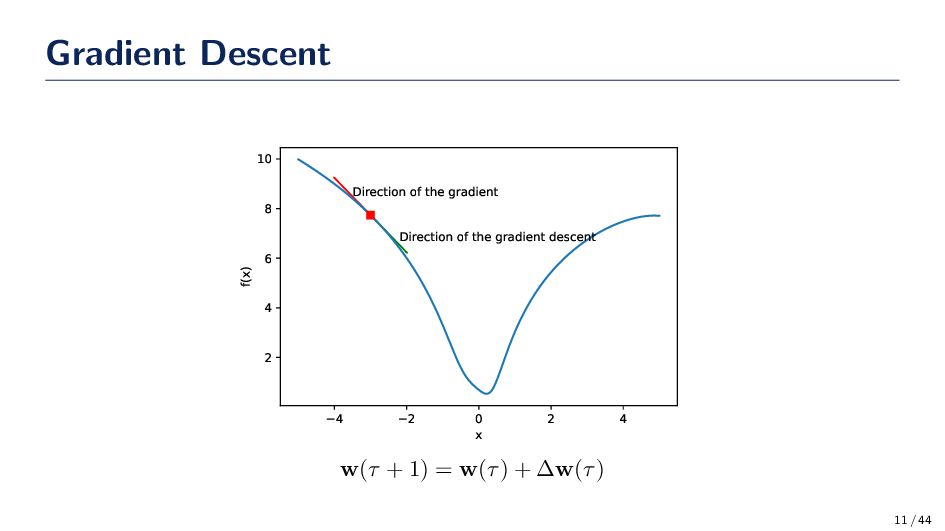
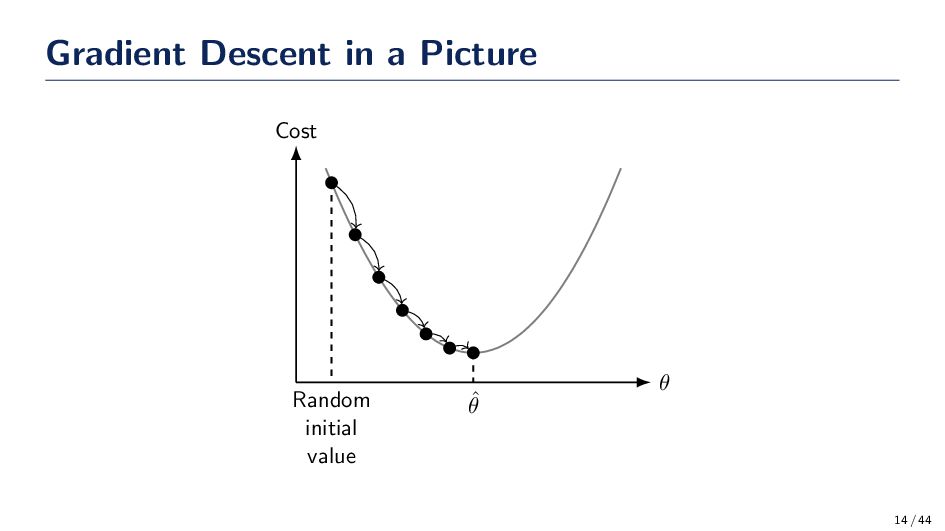
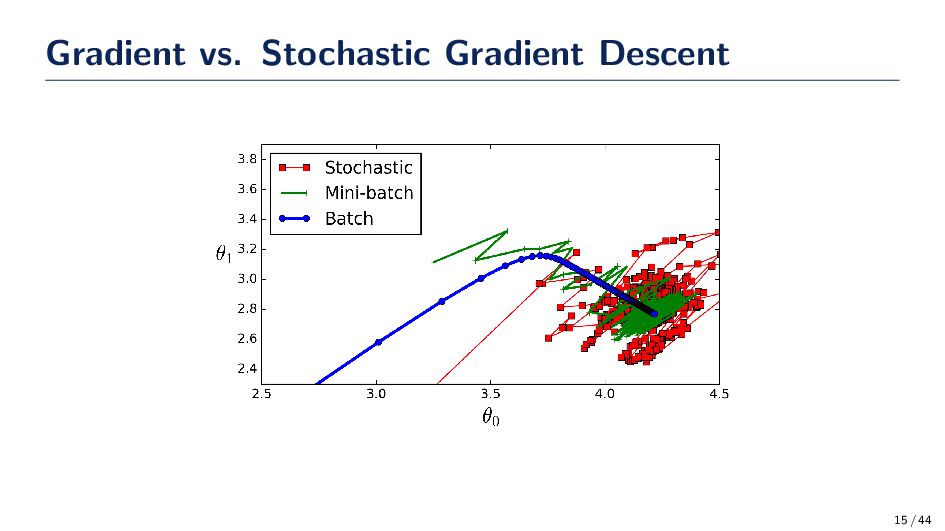
a closed-form solution to find the parameters w; however, we can see there are situations where using the closed-form expression is not going to be feasible. • Gradient Descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function. In the closed-form scenario, we take one step! • With stochastic gradient descent, we can average the gradients of a few data to take a small step in the direction of the parameters that reduces the cost function. 10 / 44
w in the direction opposite the gradient of the cost. Hence, gradient descent! We choose the direction to be ∆w(τ) = −η ∂J ∂w where η > 0 is the learning rate. Therefore, w(τ + 1) = w(τ) − η ∂J ∂w How do we find the gradient? We can find the gradient of the loss w.r.t. a single data sample xi. ∇J(xi, w) = −2(yi − g(xi))xi If we accumulate all gradients in D to do the update, then it is gradient descent. If we use a random sample xi to update w then we’re doing stochastic gradient descent. 12 / 44
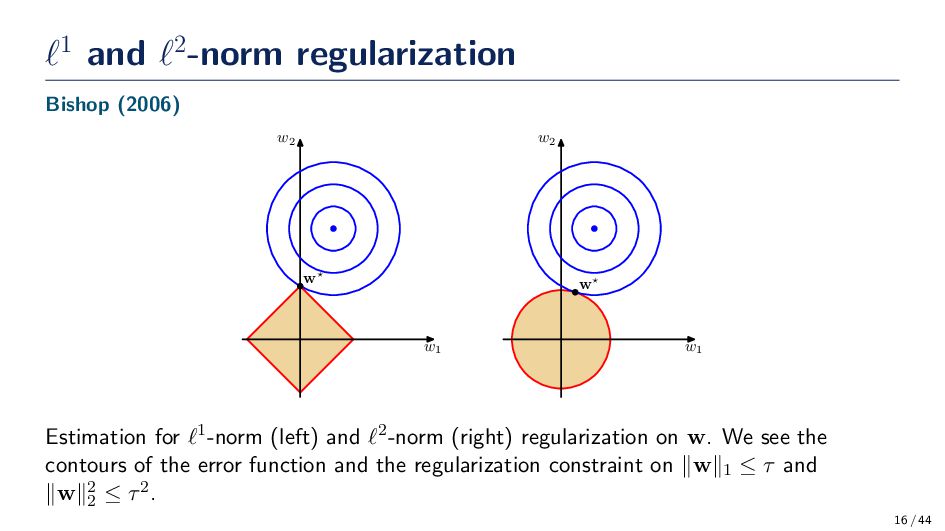
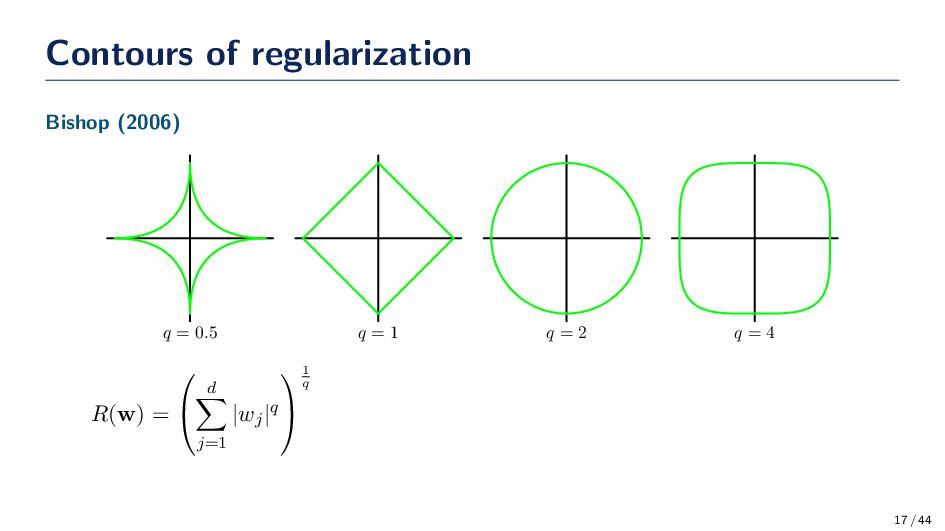
w2 w Estimation for ℓ1-norm (left) and ℓ2-norm (right) regularization on w. We see the contours of the error function and the regularization constraint on ∥w∥1 ≤ τ and ∥w∥2 2 ≤ τ2. 16 / 44
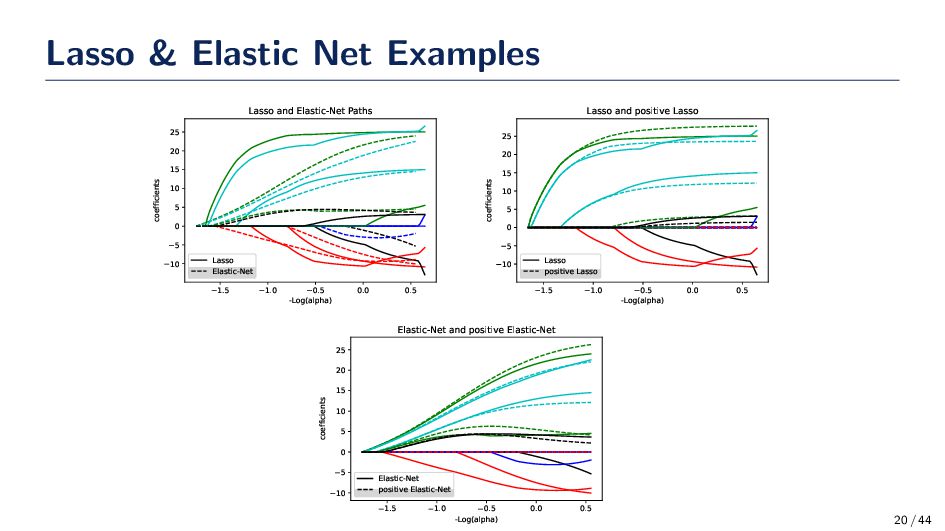
net regression are widely used in many fields for constructing a linear model. • LASSO and elastic nets can be used for feature selection too since many of the wj ’s will go to zero. • LASSO works best when d ≫ n and elastic nets should be used if d > n. • Linear and ridge regression have closed for solutions; however, LASSO and elastic nets require that gradient-based methods be used to numerically find the solution. 21 / 44
of how close a sample is to the decision boundary from the function g(x). That is the larger |g(x)| the farther a sample is from the plane. • Unfortunately, this score does not directly correspond to the probability that a sample belongs to a class. • We could try to think of a heuristic to connect g(x) to a probability; however, let us try to derive a relationship. • We’re going to need to go back to the lecture on Bayes to get the conversation of logistic regression started. • Linear regression ended up having a very convenient solution (i.e., it was a convex optimization task) and we want to try to obtain a similar results – if possible. • Goal: Start with Bayes theorem to find a linear predictive model that can provide an estimate of the posterior probability. 23 / 44
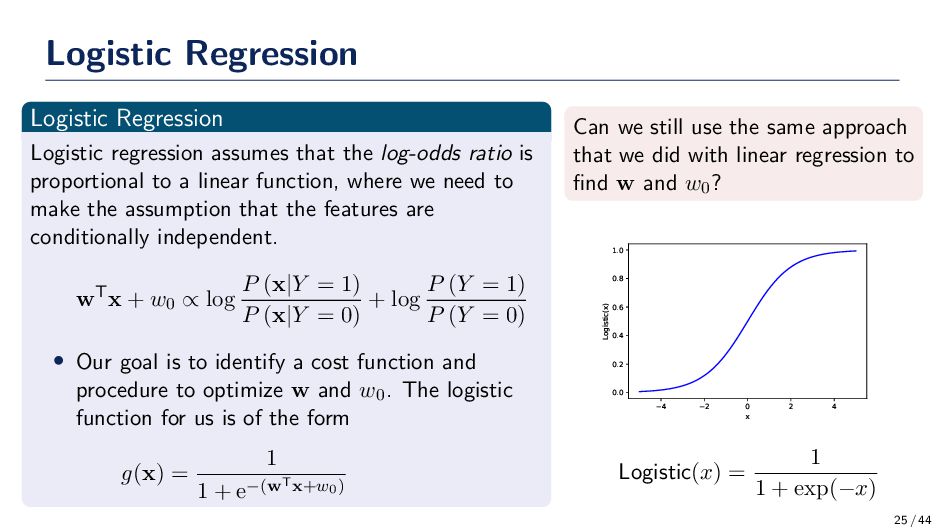
ratio is proportional to a linear function, where we need to make the assumption that the features are conditionally independent. wTx + w0 ∝ log P (x|Y = 1) P (x|Y = 0) + log P (Y = 1) P (Y = 0) • Our goal is to identify a cost function and procedure to optimize w and w0. The logistic function for us is of the form g(x) = 1 1 + e−(wTx+w0) Can we still use the same approach that we did with linear regression to find w and w0? 4 2 0 2 4 x 0.0 0.2 0.4 0.6 0.8 1.0 Logistic(x) Logistic(x) = 1 1 + exp(−x) 25 / 44
as linear regression? In linear regression, we minimized the mean-squared error over all the samples in the dataset, which is given by J(w, w0) = 1 2n n i=1 (yi − g(xi))2 where g(x) is a logistic function with parameters w and w0. The problem with this approach • Unfortunately, optimizing J(w, w0) is a nonconvex task which is undesirable. Nonconvex tasks are difficult to analyze theoretically and more difficult to work because we would always find a local minima. • Goal: Convert the task of finding w and w0 to a convex optimization problem. 26 / 44
leads to a nonconvex optimization task, we can use an approach that maximizes the likelihood function for the parameters w and w0. • The cost function, shown below, needs to be manipulated quite a bit to get the optimization problem into a form that we can work with to find the parameters. • Note: We need to get the likelihood function to use g(x) which is why it is factored this way below. This because we want (1 − g(x)) to be close to one when y = 0. L(w) = n i=1 P (Y = yi|xi; w) = i:yi=1 g(xi) · i:yi=0 (1 − g(xi)) 27 / 44
is determined by minimizing the cross-entropy loss. arg min w∈Rd − n i=1 [yi log (g(xi)) + (1 − yi) log (1 − g(xi))] About the Cross Entropy Loss • The cross entropy loss is a convex optimization problem that can be solved relatively easily in software. • Unlike the solution to linear regression, there is no closed form solution to the cross-entropy loss. Therefore, we need to use gradient descent to find the parameters. • The good news is that the update equations for logistic regression are nearly identical to linear regression! 29 / 44
code up using stochastic gradient descent. You’ll need an approach to determine when to stop training. • Input: D := {(xi, yi)}n i=1 , η, T • Initialize: w = 0 and w0 = 0 % or initialize from N(0, σ) • for t = 1, . . . , T • for j = 1, . . . , n • i = np.random.randint(n) • w = w + η(yi − g(xi ))xi • w0 = w0 + η(yi − g(xi )) • if CONVERGED, STOP ∥wt+1 − wt∥2 2 ≤ ϵ, or CrossEntropy(t) − CrossEntropy(t + 1) ≤ ϵ 30 / 44
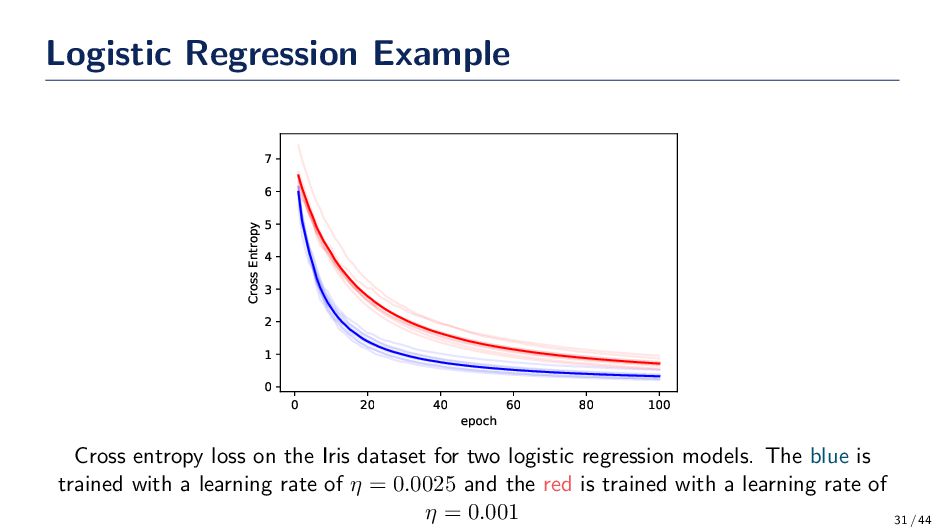
0 1 2 3 4 5 6 7 Cross Entropy Cross entropy loss on the Iris dataset for two logistic regression models. The blue is trained with a learning rate of η = 0.0025 and the red is trained with a learning rate of η = 0.001 31 / 44
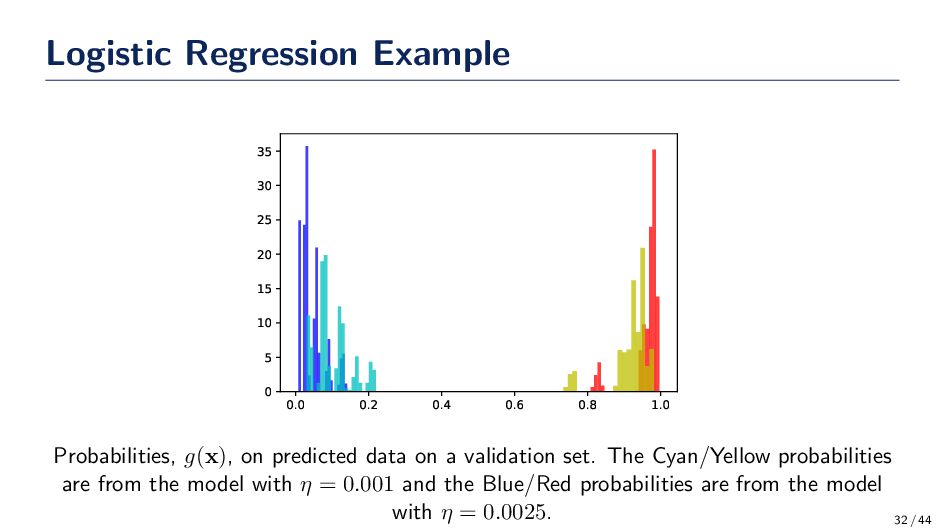
5 10 15 20 25 30 35 Probabilities, g(x), on predicted data on a validation set. The Cyan/Yellow probabilities are from the model with η = 0.001 and the Blue/Red probabilities are from the model with η = 0.0025. 32 / 44
complex pattern-classification problem, cast in a high-dimensional space non-linearly, is more likely to be linearly separable than in the low-dimension space, provided that the space is not densely populated. 38 / 44
feature representation • Note that you can use the preprocessing function PolynomialFeatures in sklearn to implement this feature mapping. • It is also important to be aware that the dimensionality of the data can become extremely large by performing this operation. • In a later lecture, we will learn about how to use Cover’s theorem more efficiently when we discuss support vector machines (SVMs). 40 / 44
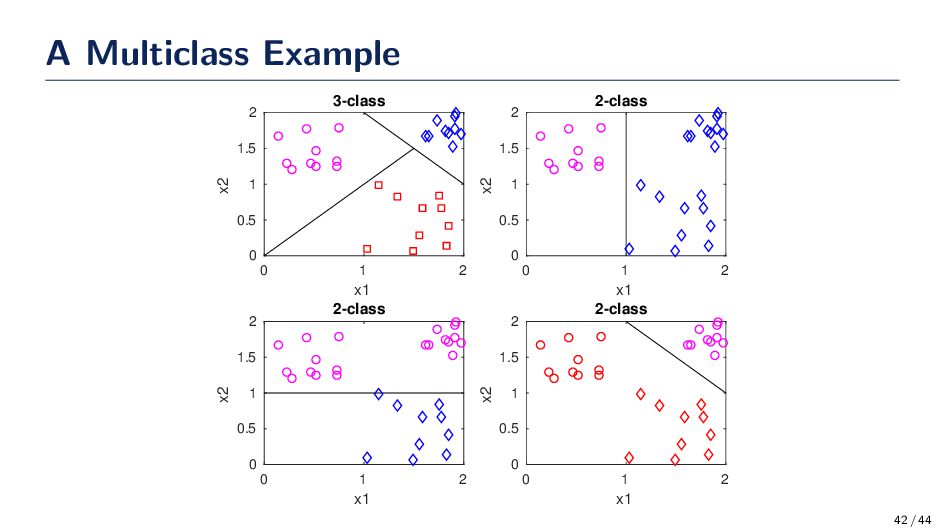
All of the models presented so far are for two class problems. We need a way to extend these classification methods to multiple classes • Mathematically, this means that the class label, yi, for each datum is now yi ∈ {1, 2, ..., c}, where c is the number of possible classifications. Split the data into c two-class problems. • For example, if we have c classes then we will have c different classifiers: class 1 against classes {2, 3, ..., c}, class 2 against classes {1, 3, ..., c}, etc. Multiclass Prediction with Logistic Regression P(Y = k|x; w1, w2, · · · , wc) = exp(wT k x) c j=1 exp(wj Tx) 41 / 44
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Logistic Regression (in code) def predict(self, X): return 1.0*(self.score(X[i]) >=](https://files.speakerdeck.com/presentations/45d5c5db9d1248d19fd0476863e0740d/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}