There are some massive sources of data: Google, Skype, Yahoo! Facebook, Twitter. Classical data mining & machine learning: single machine How can we easily and efficiently distribute computation? In general, performing distributed computing is not always straight forward. Case & Point: Proteus. MapReduce was adopted from Google’s computation & data manipulation model Motivation Google: 20+ Billion webpages × 20kB = 400+TB, and 1 computer reads 30-35MB/sec from disk That means it would take 4 months to read the data from the web! And even longer to do something with it! EESI Group Meeting (February 2015) An Introduction to MapReduce
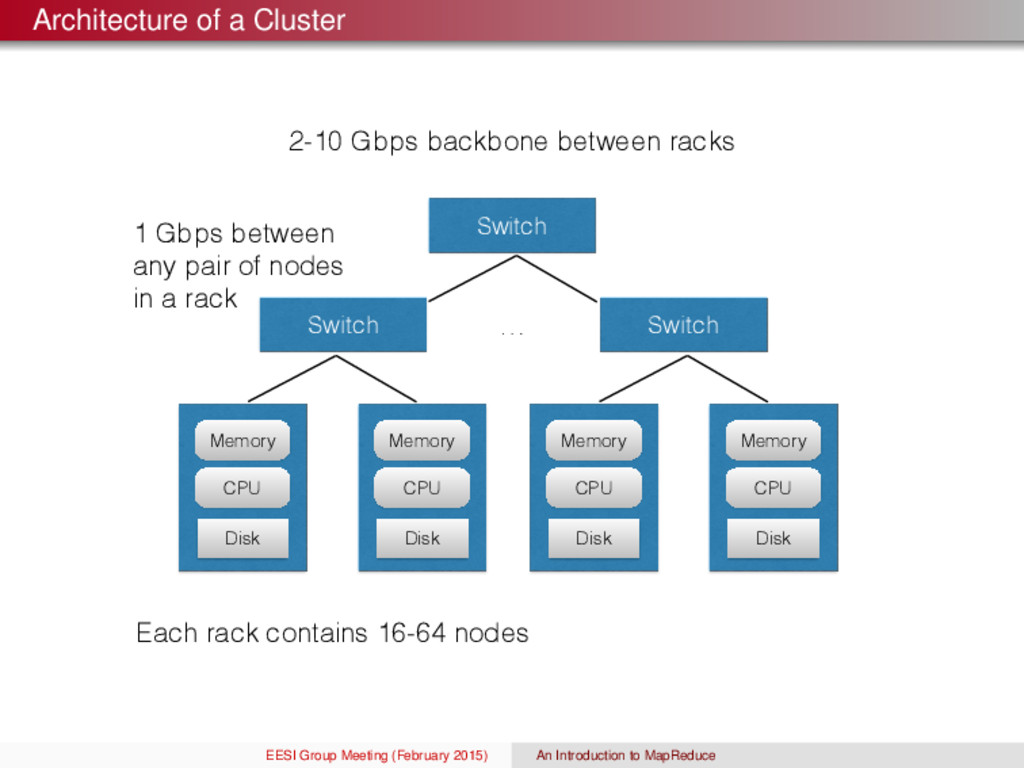
Gbps between any pair of nodes in a rack Switch Switch Switch … Each rack contains 16-64 nodes Memory CPU Disk Memory CPU Disk Memory CPU Disk Memory CPU Disk EESI Group Meeting (February 2015) An Introduction to MapReduce
on big data is that you cannot bring the data to the computation. Hadoop via MapReduce brings the computation to the data! EESI Group Meeting (February 2015) An Introduction to MapReduce
project that enables the distributed processing of large data sets across clusters of servers Servers are not specific, rather they are commercial off the shelf (COTS) Think of Hadoop as the operating system for big data Works with one machine. . . Works with thousands of machines! And extending a Hadoop cluster is easy. Core of any OS: (i) ability to store file, and (ii) ability to run applications. The Cornerstones of Hadoop YARN (Yet Another Resource Negotiator): Assigns CPU, memory, and storage to applications running on a Hadoop cluster. Its a bit like a scheduler and YARN allows the use of applications other than MapReduce. HDFS (Hadoop Distributed File System): file system that spans all the nodes in a Hadoop cluster for data storage. It links together the file systems on many local nodes to make them into one big file system. EESI Group Meeting (February 2015) An Introduction to MapReduce
needed and there is no need to change data formats or how distributed programs are written. Cost effective: Hadoop is free! Sizeable decrease in the cost per terabyte of storage, which in turn makes it affordable to model all of the data. Flexible: Hadoop is schema-less, and can absorb any type of data, structured or not, from any number of sources. Fault tolerant: When you lose a node, the system redirects work to another location of the data and continues processing without missing a beat. EESI Group Meeting (February 2015) An Introduction to MapReduce
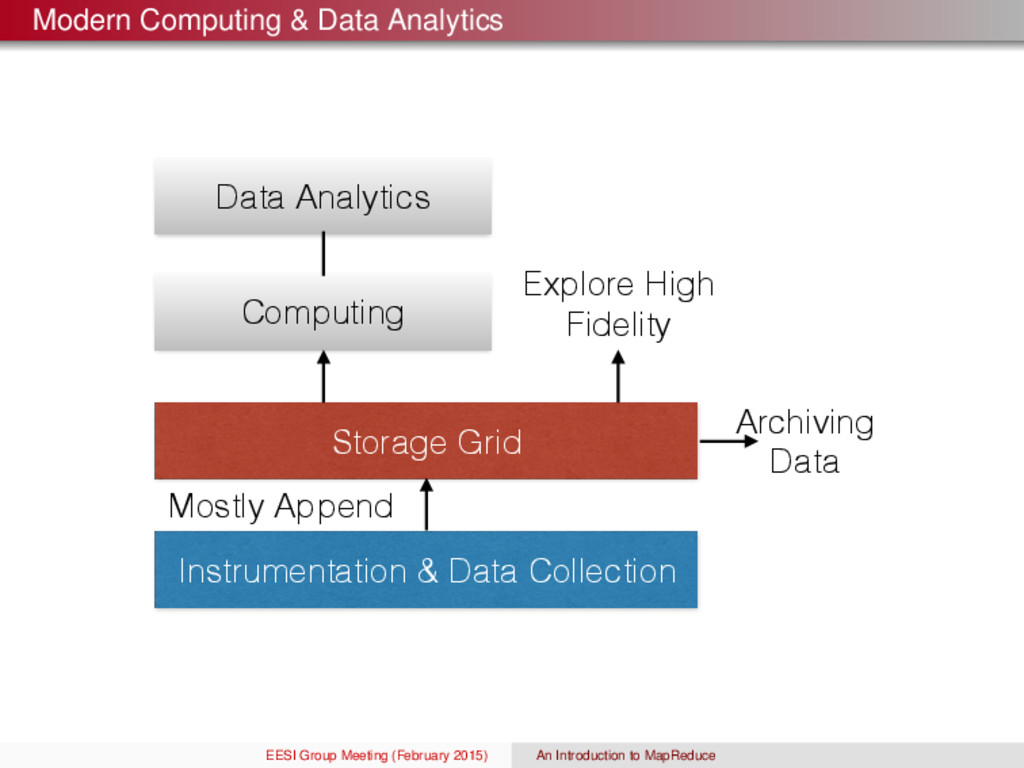
System? Copying data over a network is extremely slow and can be a huge bottle neck during computation Idea: instead of bringing the data to the computation, bring the computation to the data. MapReduce addresses these problems by using a DFS and a new programming model. If nodes fail, how to store data persistently? Distributed File System! Data are rarely updated in place. Reads and appends are far more common What Makes Up a Hadoop Cluster? Chunk servers: Files are split into contiguous chunks (e.g., 16-64MB) and each chunk replicated (e.g., 2x or 3x). Replicas would be stored in different racks Master node (Name Node in Hadoop’s HDFS): Stores metadata about where files are stored Client library for file access: Talks to master to find chunk servers and connects directly to chunk servers to access data EESI Group Meeting (February 2015) An Introduction to MapReduce
the challenges of cluster computing Store data redundantly on multiple nodes for persistence and availability Move the computation close to the data to minimize data movement Simple programming model to hide the complexity of distributed computing Example We have a huge text document that cannot be loaded into memory. Goal: count the number of times each distinct word appears in the file. Applications count k-mers for a potentially large k analyze web server logs to find popular URLs language models EESI Group Meeting (February 2015) An Introduction to MapReduce
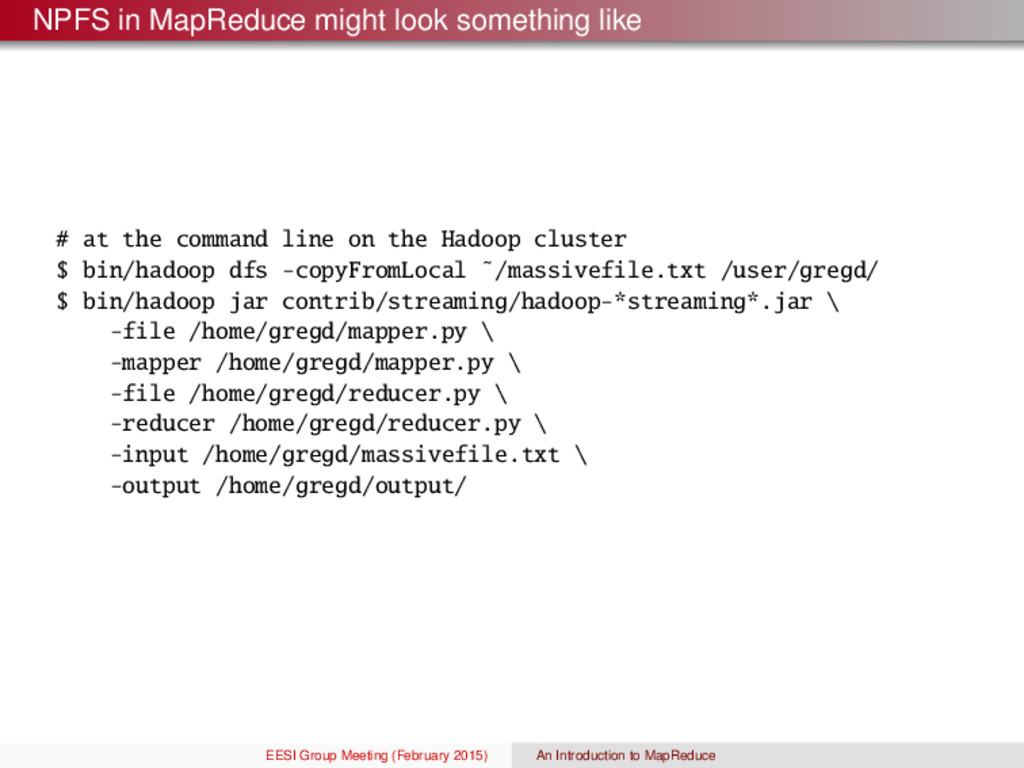
memory, but all of the (word, count) pairs fit into memory Build a hash table by sweeping through the file and incrementing a counter in the hash table every time we come across a word. Case 2: Not even the (word, count) pairs fit into memory $ words document.txt | sort | uniq -c Captures the essence of MapReduce. Map scan the input file one record at a time extract something you care about from each record (key) Group by key sort and shuffle Reduce aggregate, summarize, filter or transform write the result The Map and Reduce function need to be changed to deal with the problem you’re solving EESI Group Meeting (February 2015) An Introduction to MapReduce
and more vulnerable years my father gave me some advice that I’ve been turning over in my mind ever since. “Whenever you feel like criticizing any one,” he told me, “just remember that all the people in this world haven’t had the advantages that you’ve had.” He didn’t say any more, but we’ve always been unusually communicative in a reserved way, and I understood that he meant a great deal more than that. In consequence, I’m inclined to reserve all judgments, a habit that has opened up many curious natures to me and also made me the victim of not a few veteran bores. The Raw Text in 1 my 1 younger 1 and 1 more 1 vulnerable 1 years 1 my 1 father 1 gave 1 me 1 some 1 advice 1 that 1 i've 1 been 1 turning 1 over 1 in 1 my 1 mind 1 ever 1 since. 1 "whenever 1 you 1 feel 1 like 1 criticizing 1 any 1 Map a 1 a 1 a 1 a 1 a 1 abnormal 1 about 1 advantages 1 advice 1 all 1 all 1 also 1 always 1 and 1 and 1 and 1 and 1 and 1 any 1 any 1 appears 1 attach 1 been 1 been 1 Group by Key 1 1 a 5 abnormal 1 about 1 advantages 1 advice 1 all 2 also 1 always 1 and 5 any 2 appears 1 attach 1 been 2 bores. 1 but 1 came 1 chapter 1 college 1 communicative 1 consequence 1 criticizing 1 curious 1 deal 1 Reduce EESI Group Meeting (February 2015) An Introduction to MapReduce
rule to be hθ(x) = n i=0 θi xi and a cost function to be J(θ) = 1 2 m j=1 (hθ(x(j)) − y(j))2, we can use the Widrow-Hoff learning rule to find θ, which is given by: θi ← θi + η m j=1 (hθ(x(j)) − y(j))x(j) i Time consuming for large m . Map: compute the errors for each point and their update contribution (key) Reduce: sum the returned values EESI Group Meeting (February 2015) An Introduction to MapReduce
the input data Scheduling the program’s execution across a – potentially large – set of machines Perform the group by key step Handling node failures Managing required inter-machine communication User’s need to choose M map tasks and R reduce tasks. Rule of thumb: M > # of nodes in the cluster and R < M. EESI Group Meeting (February 2015) An Introduction to MapReduce
node that were completed or idle are all reset to idle The idle tasks are eventually rescheduled on other workers Reducer node failure Only the in-progress tasks are reset to idle. Completed tasks on the worker are saved to the distributed file system – not the local file system. Idle reduce tasks are restarted on other workers Master node failure The MapReduce task is aborted and the client is notified. Remember, node failures are rare! EESI Group Meeting (February 2015) An Introduction to MapReduce
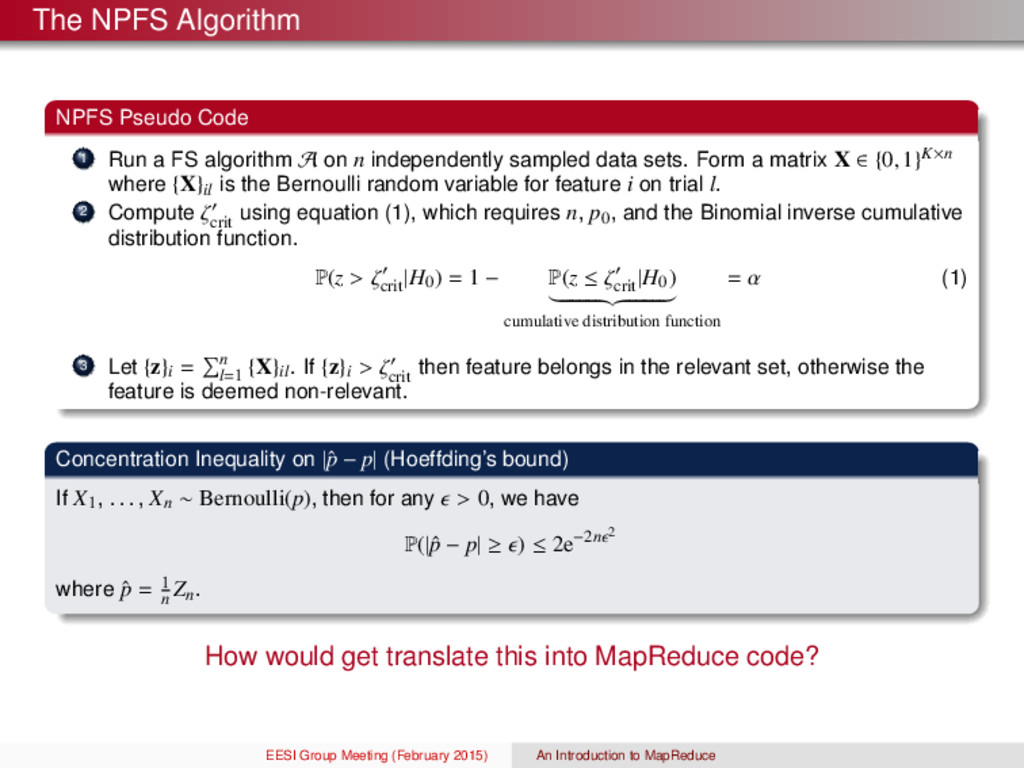
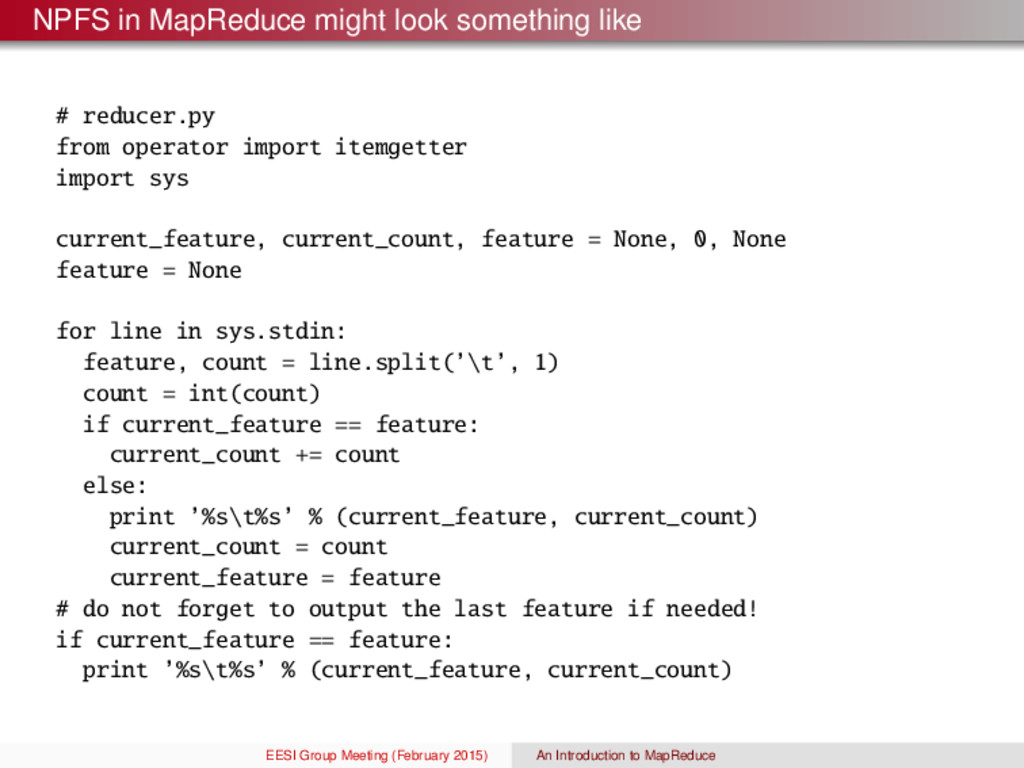
algorithm A on n independently sampled data sets. Form a matrix X ∈ {0, 1}K×n where {X}il is the Bernoulli random variable for feature i on trial l. 2 Compute ζ crit using equation (1), which requires n, p0, and the Binomial inverse cumulative distribution function. P(z > ζ crit |H0) = 1 − P(z ≤ ζ crit |H0) cumulative distribution function = α (1) 3 Let {z}i = n l=1 {X}il. If {z}i > ζ crit then feature belongs in the relevant set, otherwise the feature is deemed non-relevant. Concentration Inequality on |ˆ p − p| (Hoeffding’s bound) If X1, . . . , Xn ∼ Bernoulli(p), then for any > 0, we have P(|ˆ p − p| ≥ ) ≤ 2e−2n 2 where ˆ p = 1 n Zn. How would get translate this into MapReduce code? EESI Group Meeting (February 2015) An Introduction to MapReduce
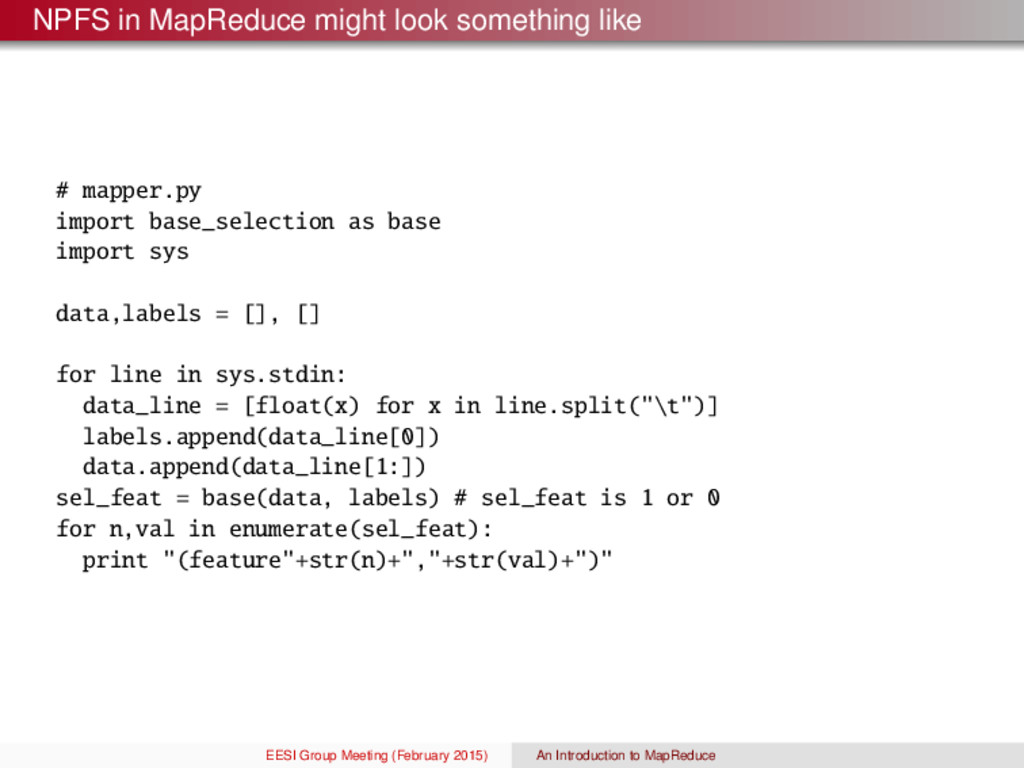
base_selection as base import sys data,labels = [], [] for line in sys.stdin: data_line = [float(x) for x in line.split("\t")] labels.append(data_line[0]) data.append(data_line[1:]) sel_feat = base(data, labels) # sel_feat is 1 or 0 for n,val in enumerate(sel_feat): print "(feature"+str(n)+","+str(val)+")" EESI Group Meeting (February 2015) An Introduction to MapReduce
collection of machine learning algorithms, most of which use MapReduce, and run on Hadoop What’s there?: collaborative filters, classification (LR, NB, RF, HMM & MLP), clustering, dimensionality reduction, topic models, and more! Apache has many more Hadoop tools: http://projects.apache.org/indexes/category.html EESI Group Meeting (February 2015) An Introduction to MapReduce
advanced DAG execution engine that supports cyclic data flow and in-memory computing Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk Write applications quickly in Java, Scala or Python Spark runs on Hadoop, Mesos, standalone, or in the cloud. Applications that can run on Spark MLib: Machine learning library that fits into Spark’s APIs and interoperates with NumPy in Python. Spark SQL: Lets you query structured data as a distributed dataset (RDD) in Spark GraphX: Unifies Extract, Transform and Load (ETL), exploratory analysis, and iterative graph computation within a single system Spark Streaming: lets you reuse the same code for batch processing, join streams against historical data, or run ad-hoc queries on stream state EESI Group Meeting (February 2015) An Introduction to MapReduce
or Spark to distribute your data and processing across a resizable cluster of Amazon EC2 instances. Web GUI allows to to configure the cluster and transfer data to the cloud using AWS Works with code written in Perl, Python, R, PHP, C++, Pif, Java or Hive Cluster can be shutdown after the program has been completed to avoid wasting $$ The idea is that Amazon takes care of the management of the Hadoop cluster and you spend your time analyzing the data. Amazon EMR allows a user to choose nodes optimized for different levels of computation, memory, or features, such as a GPU A 10-node Hadoop cluster can be used for approximately $0.15 per hour EESI Group Meeting (February 2015) An Introduction to MapReduce
and J. D. Ullman, “Mining of Massive Datasets,” Cambridge University Press, 2nd Ed., 2014. J. Dean and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters,” Symposium on Operating System Design and Implementation, 2004. Coursera, “Mining Massive Datasets,” 2015. EESI Group Meeting (February 2015) An Introduction to MapReduce
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}