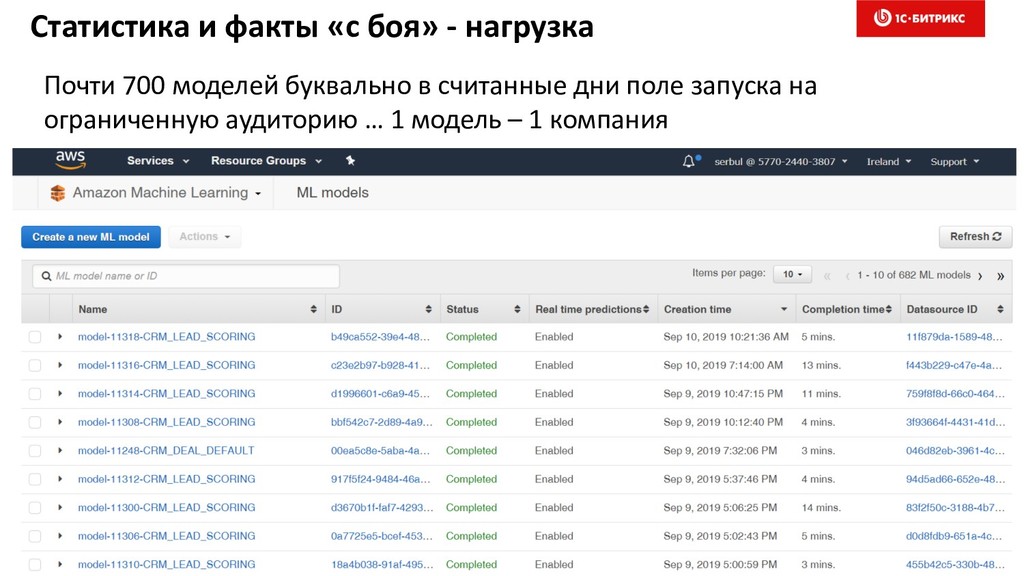
1. Потребности бизнеса, клиентов и рынка в массовом скоринге
2. Первый технологический стек, первый прототип
3. Полезные новейшие возможности облаков для скоринга и других применений ML
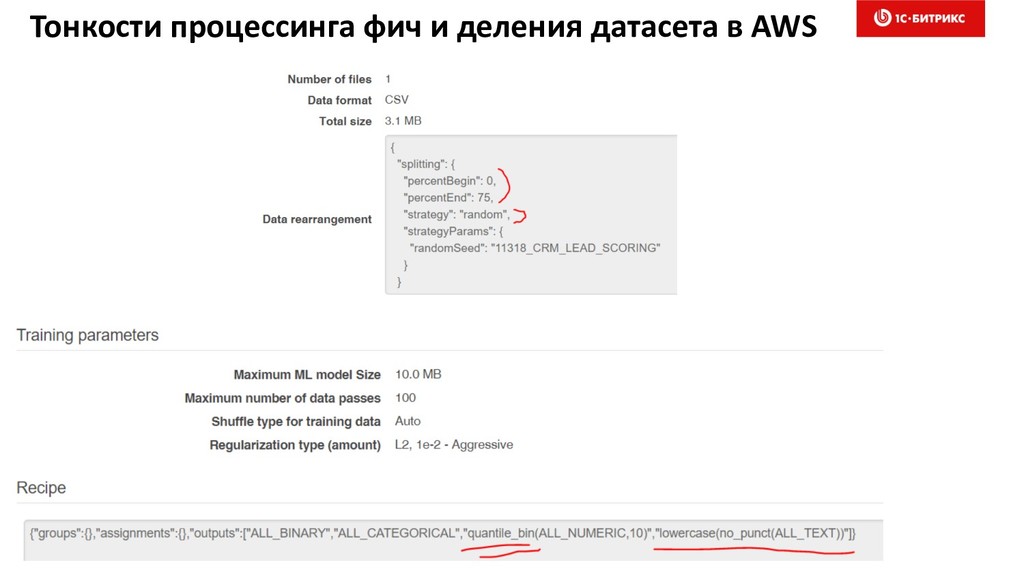
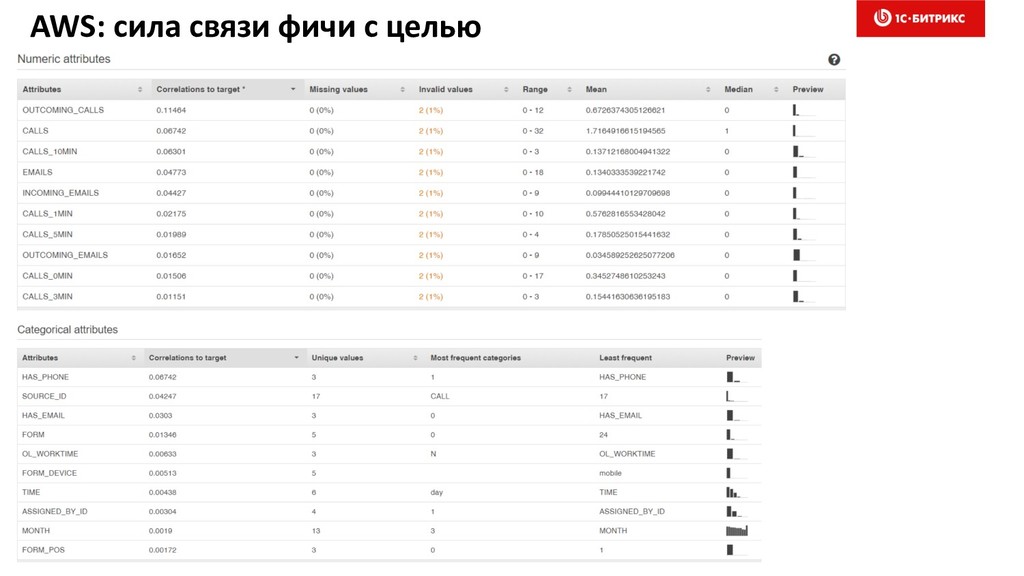
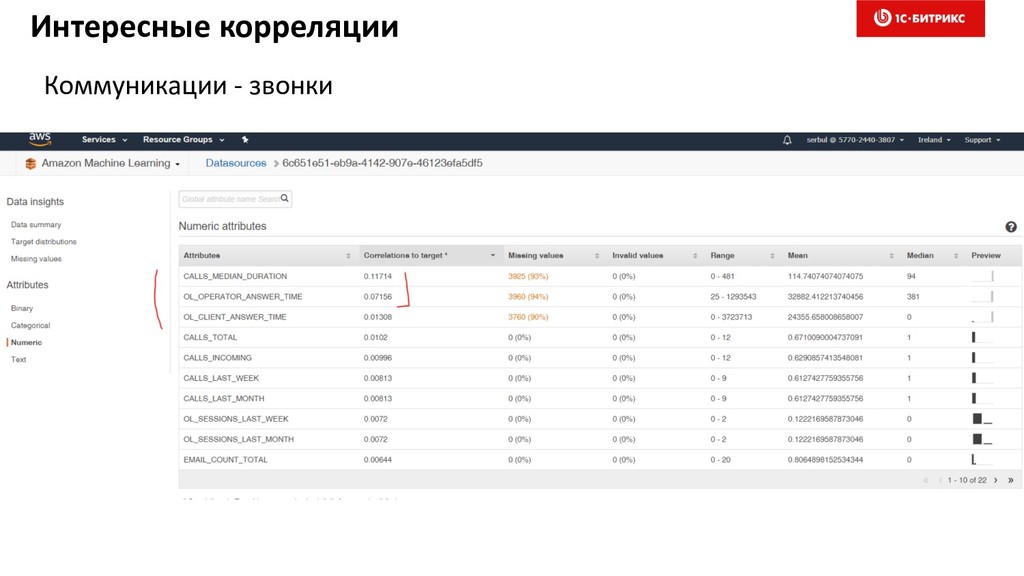
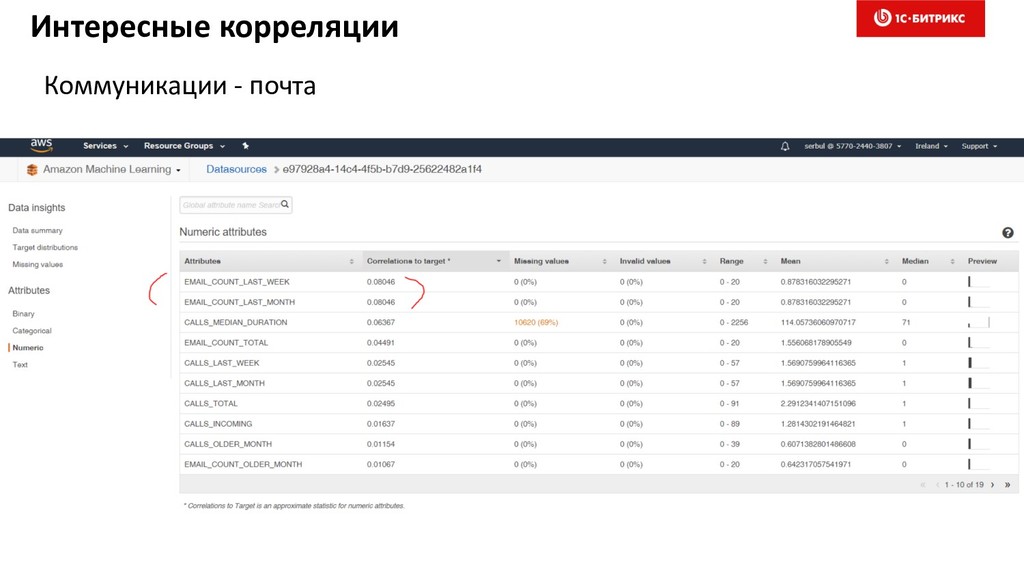
4. Выбор фич
5. Несбалансированные данные - как не сойти с ума
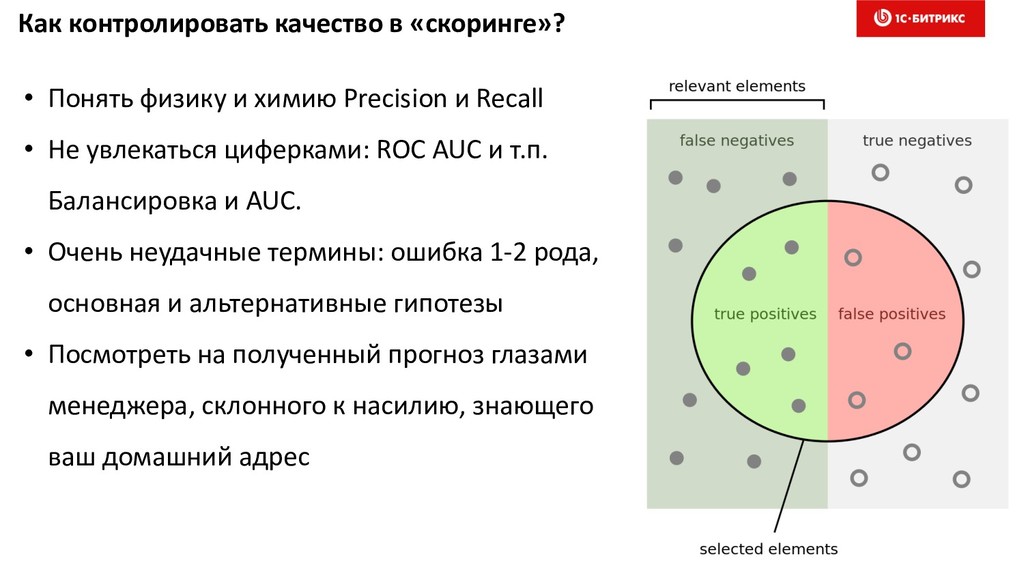
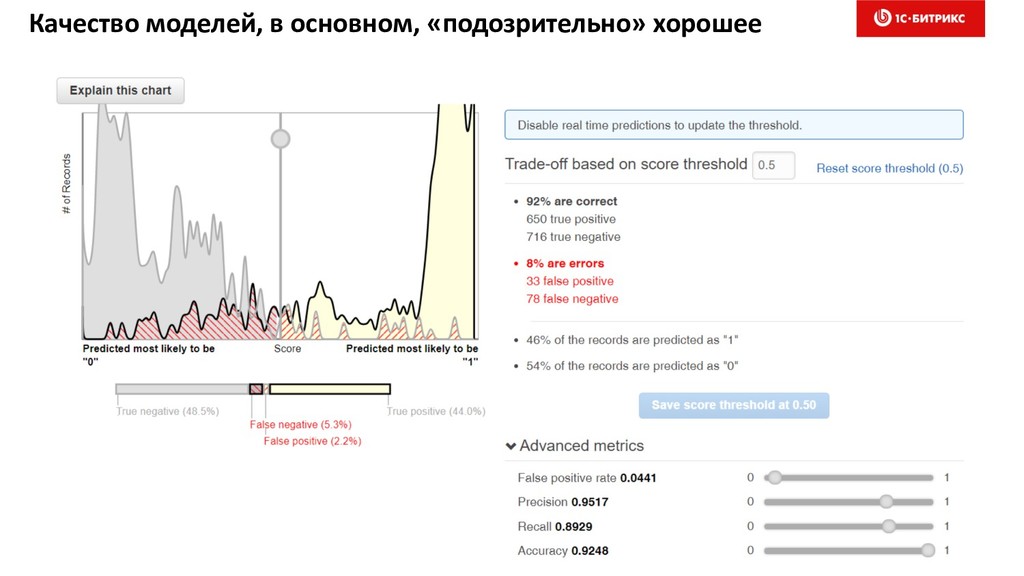
6. Оптимизация моделей скоринга
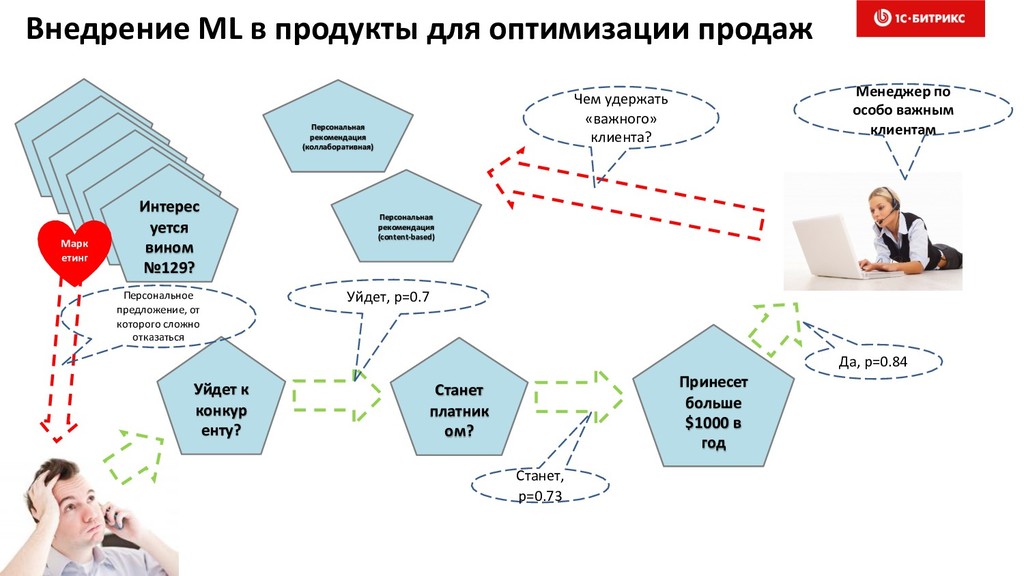
7. Внедрение скоринга в продукт
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! Вопросы? Александр Сербул @AlexSerbul Alexandr Serbul [email protected]](https://files.speakerdeck.com/presentations/8a901322a4dd46b1a5e78785cd95891b/slide_30.jpg){kind=link}