How do you make the process of getting code into production seamless as a developer, without causing difficulties for operations? For example, developers would rather avoid gatekeeping in order to have shorter feedback loops. Ops teams would rather be well prepared for what’s going into production and when, in order to avoid surprises and prepare support training. In this talk you will learn about the process of creating a deployment pipeline for Kubernetes using Gitlab CI, what checks you can use to catch human error early, and ways of validating that changes won't cause the result to tip over. This talk will improve your ability to design deployment processes which avoid developer pain but builds operational trust.
Given at DevOps Days Edinburgh 2017
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
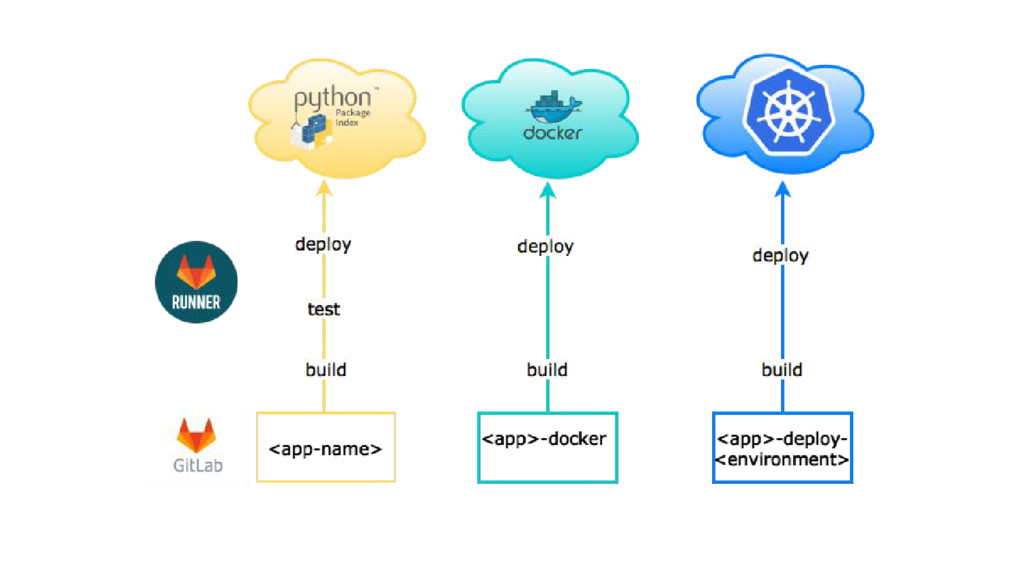{kind=link}
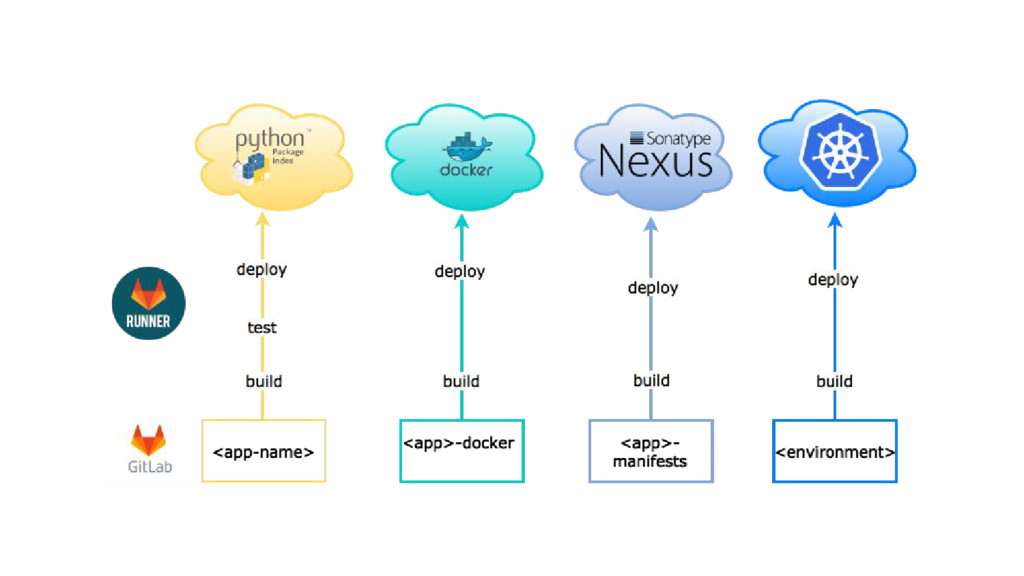{kind=link}
{kind=link}
{kind=link}
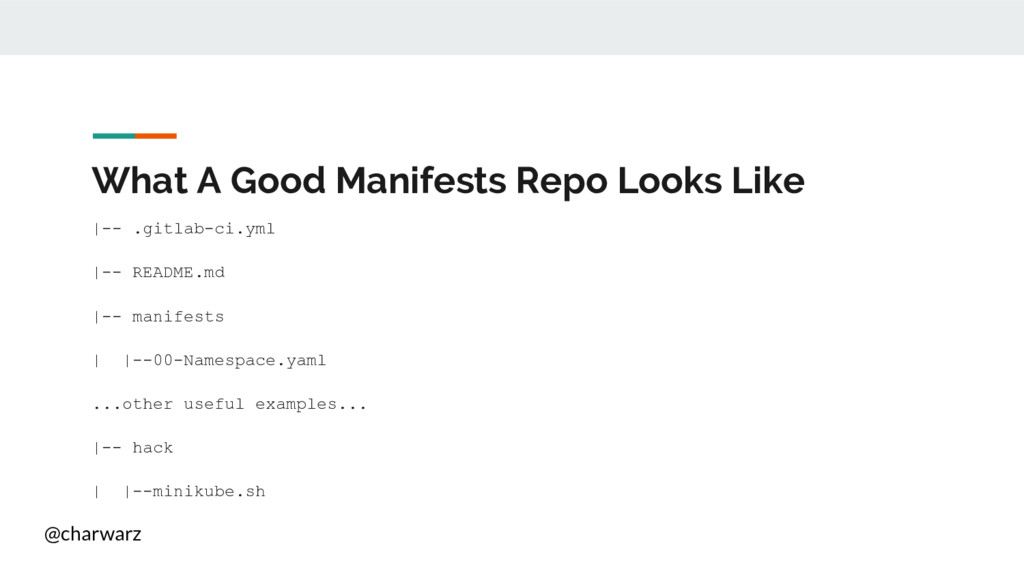{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}