talk a little about what a pragma is, and their history. Many languages have the notion of an attribute, or directive, that changes the way source code is interpreted during compilation.
strict “subs"; use strict; no strict "vars"; Perl has the ‘use’ keyword Which enable features, or make the compiler interpret the source of the program differently. Maybe it makes the compiler more pedantic or enables a new syntax mode.
extended the language with _optional_ modes When the javascript interpreter comes across the words “use strict” it enables "Strict Mode" when parsing your javascript source.
mod macos_only { … } Rust is similar, they use their attributes and features syntax to enable unstable features in the compiler or standard library The inline always attribute tells the compiler that it _must_ inline the super_fast_fn. The target_os attribute tells the compiler to only compile the macos_only module on OS X.
double k; }; When they were adopted by C in the 1970’s, the name was shortened again, to #pragma, and due to the widespread use of C, became enshrined as the popular name This example says to the compiler that the structure should be packed to a two byte boundary; so the double, k, will start at an offset of 6 bytes, not the usual 8, from the address of T. The #pragma directive spawned a host of compiler specific extensions, like gcc’s double underscore builtin.
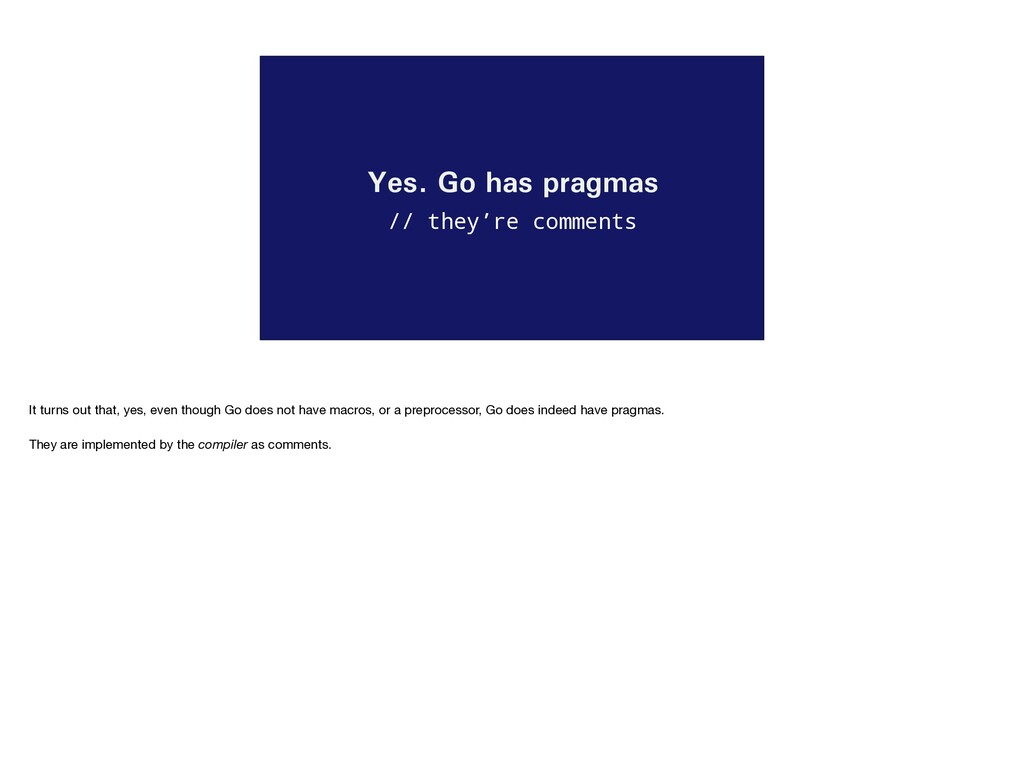
bit of the history of pragmas, maybe we can now ask the question Does Go have pragmas? You saw earlier that pragmas are often implemented as macros or preprocessors in in C style languages. But, Go does not have a preprocessor, or macros. So, the question is does Go have pragmas?
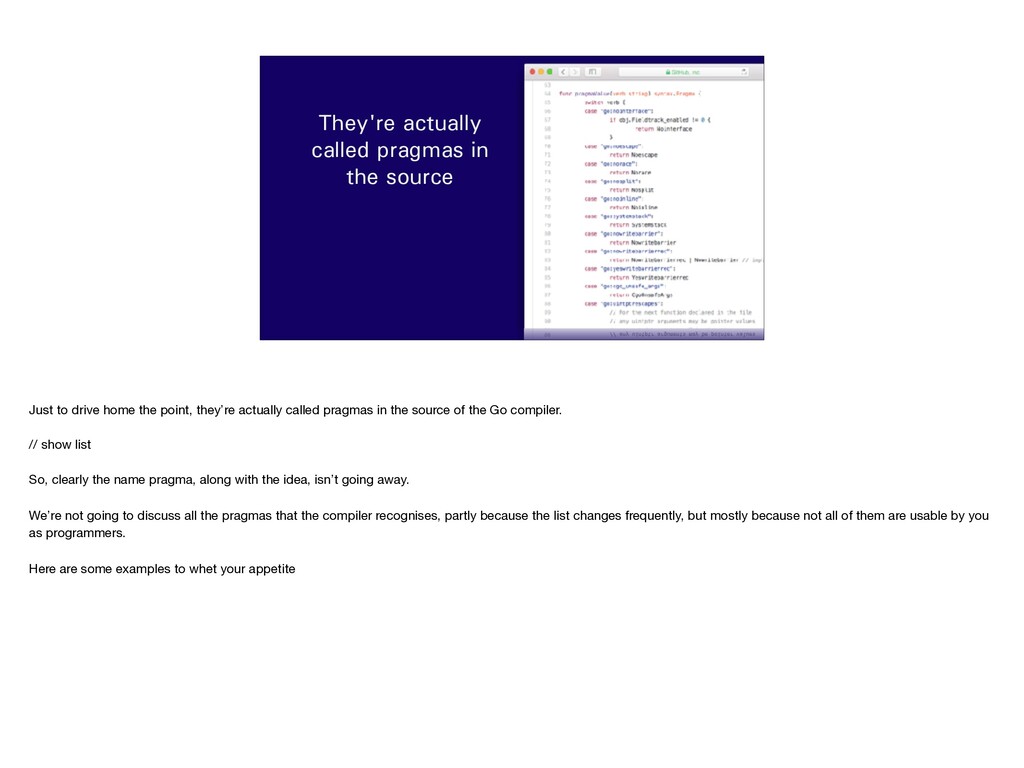
home the point, they’re actually called pragmas in the source of the Go compiler. // show list So, clearly the name pragma, along with the idea, isn’t going away. We’re not going to discuss all the pragmas that the compiler recognises, partly because the list changes frequently, but mostly because not all of them are usable by you as programmers. Here are some examples to whet your appetite
atomic.StorepNoWB(noescape(ptr), new) } This is an example of the nosplit directive inside the runtime’s atomic support functions. Don’t worry if this was all a bit quick, we’re going to explore these pragmas, and more, in detail throughout this presentation.
to offer a word of caution. Pragmas are not part of the language, they might be in the compiler. but you will not find them in the spec. At a higher level, the idea of adding pragmas to the language caused considerable debate, especially after the first few created a precedent.
The question is, does the usefulness justify the cost? The cost here is continued proliferation of magic comments, which are becoming too numerous already. In a debate about adding the //go:noinline directive Rob Pike opined in August 2015 // read quote I'll leave you to decide at the end of this presentation if adding pragmas was a good idea.
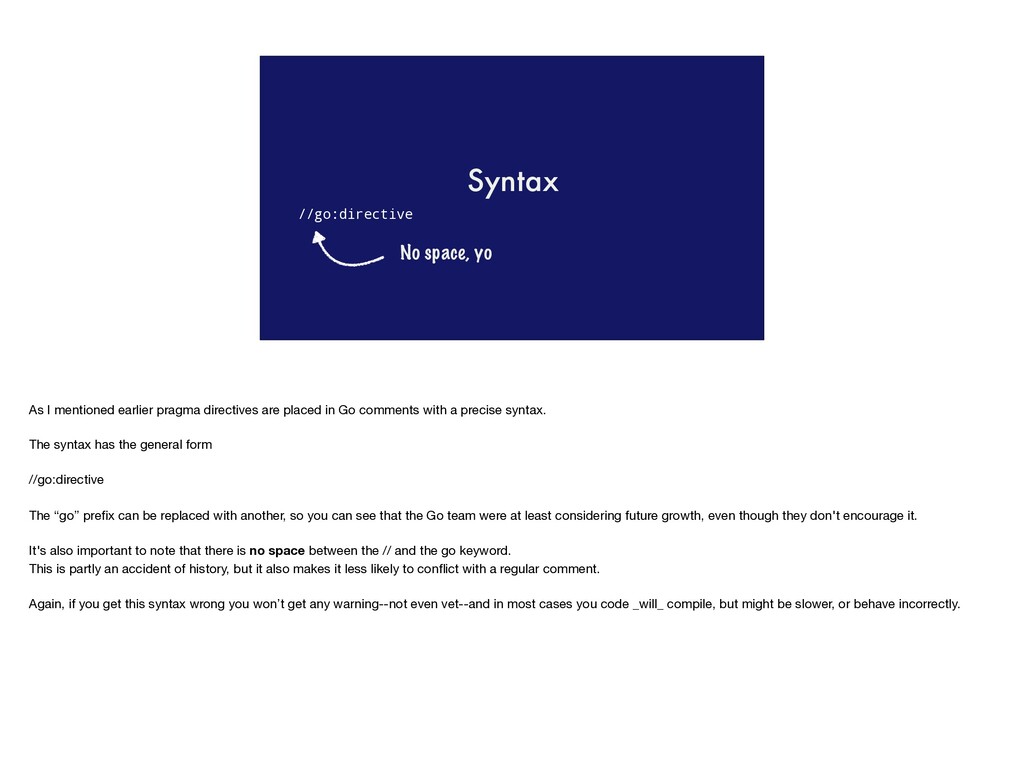
directives are placed in Go comments with a precise syntax. The syntax has the general form //go:directive The “go” prefix can be replaced with another, so you can see that the Go team were at least considering future growth, even though they don't encourage it. It's also important to note that there is no space between the // and the go keyword. This is partly an accident of history, but it also makes it less likely to conflict with a regular comment. Again, if you get this syntax wrong you won’t get any warning--not even vet--and in most cases you code _will_ compile, but might be slower, or behave incorrectly.
Go's life, the parts that went into a complete Go program would include Go code, obviously, some C code from the runtime, and some assembly code, again from the runtime and also the syscall package. The thing to take away is, while not common, it was understood that in a single Go package, you'd occasionally find functions which were not implemented in Go. Now, normally this mixing of languages wouldn't be a problem, except when it interacts with escape analysis.
Men: 9} return &b } Who knows what I mean when I talk about escape analysis? In Go it's very common to do something like this That is, inside `NewBook` we declare and initalise a new `Book` variable b, then return the _address_ of `b`. We do this so often inside Go it probably doesn't sink in that if you were to do something like this in C, the result would be massive memory corruption, as the address returned from `NewBook` would point to the location on the stack where `b` was temporarily allocated. What the compiler is doing is detecting when a variable's lifetime will live beyond the lifetime of the function it is declared, and moves the location where the variable is allocated from the stack to the heap. Technically we say that `b` _escapes_ to the heap. Is everyone comfortable with this idea? Obviously there is a cost; heap allocated variables have to be garbage collected when they are no longer reachable, stack allocated variables are automatically free'd when their function returns. Keep that in mind.
Men: 3} AddToCollection(&b) } Now, lets consider a slightly different version of what we saw above In this silly example, `BuildLibrary` declares a new `Book`, b, and passes its address to `AddToCollection`. So, the question for you is, "does `b` escape to the heap"?
"fiction" } If AddToCollection did something like this Then that's fine, `AddToCollection` can address those fields in `Book` irrispective of if `b` points to an address on the stack or on the heap. Escape analysis would conclude that the b declared in BuildLibrary did not escape, and can be allocated cheaply on the stack. This is a key performance optimisation, something that was missing from gccgo for many years.
= append(AvailableForLoan, b) } However, if `AddToCollection` did something like this That is, keep that pointer to a `b` and store it in some long lived slice, then that will have an impact on the `b` declared in `BuildLibrary`, it will be allocated on the heap so that it lives beyond the lifetime of AddToCollection and BuildLibrary. This is the essence of Escape Analysis. The Escape Analyser analyses the program and chooses to store variables on the stack or the heap. And the analysis, as we saw, depends on where an address of a variable is passed to. Escape analysis has to know what `AddToCollection` does, what functions it calls, and so on, to know if a value should be heap or stack allocated.
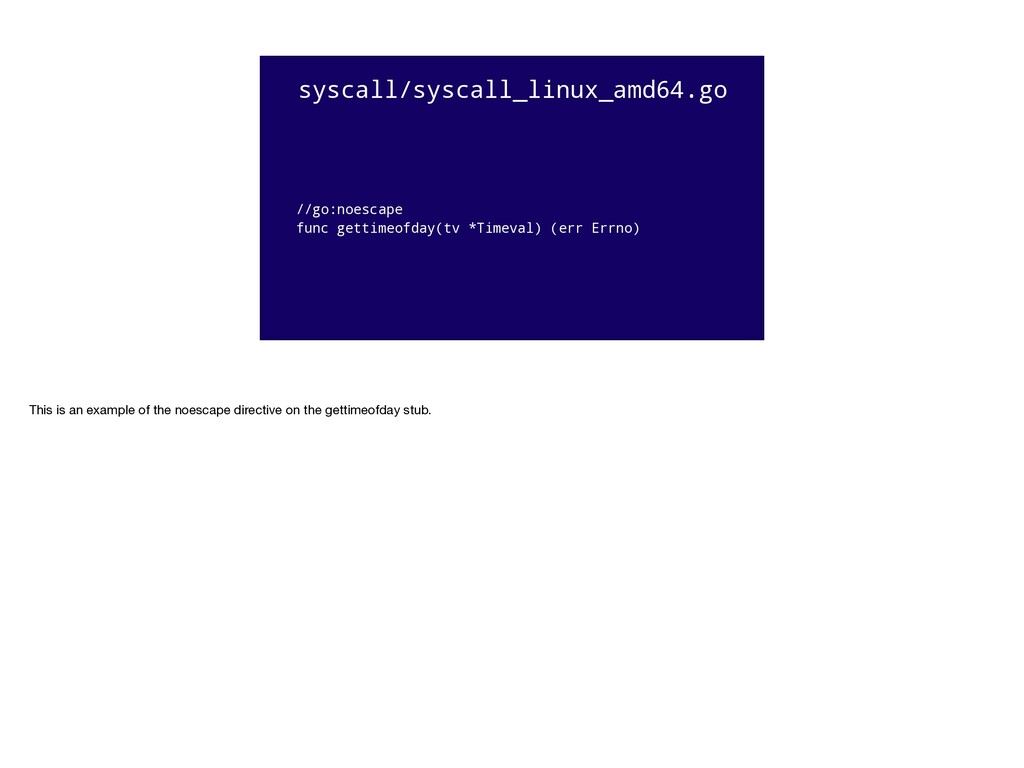
_ := f.Read(buf) Ok, that's a lot of background. So let's get back to the `//go:noescape` pragma Now we know that the tree of functions below a single function affect whether a value escapes or not, consider this _very_ common situation. We open a file, we make a buffer, and we read into that buffer. Is `buf` allocated on the stack, or on the heap?
File. // It returns the number of bytes read and any error encountered. // At end of file, Read returns 0, io.EOF. func (f *File) Read(b []byte) (n int, err error) { if err := f.checkValid("read"); err != nil { return 0, err } n, e := f.read(b) if e != nil { if e == io.EOF { err = e } else { err = &PathError{"read", f.name, e} } } return n, err } It depends on what happens inside `os.File.Read`, which it turns out calls down through a few layers to `syscall.Read`. And this is where it gets complicated, because `syscall.Read` calls down into `syscall.Syscall` to do the raw operating system syscall, and sys call.Syscall is implemented in assembly. And because it’s implemented in assembly, the compiler, which works on Go code, cannot "see" into that function, so it cannot "see" if the values passed to `syscall.Syscall` escape or not. And because the compiler cannot _know_ if the value might escape, it must, pessimistically, assume it will escape.
5 07:00:38 2013 -0500 cmd/gc: add way to specify 'noescape' for extern funcs A new comment directive //go:noescape instructs the compiler that the following external (no body) func declaration should be treated as if none of its arguments escape to the heap. Fixes #4099. R=golang-dev, dave, minux.ma, daniel.morsing, remyoudompheng, adg, agl, iant CC=golang-dev https://golang.org/cl/7289048 This was the situation in https://github.com/golang/go/issues/4099. If you wanted to write a small bit of glue code in asm, like the bytes package, or md5 package, or the syscall package, or time.Now, anything you passed to it would be forced to allocated on the heap even if you know that it doesn’t.
the index of the first instance of c in s, // or -1 if c is not present in s. func IndexByte(s []byte, c byte) int // ../runtime/asm_$GOARCH.s And this is precisely what the `//go:noescape` pragma does. It says to the compiler, "the next function declaration you see, assume that none of the arguments escape" This is an example from Go 1.5. You can see that `bytes.IndexByte` is implemented in assembly, technically we call this a stub or _forward declaration_, after the concept from C. By marking this function `//go:noescape`, it will not cause small stack allocated `[]byte` slices from escaping to the heap unnecessarily. We’ve said to the compiler; trust us, IndexByte and it’s children do not keep a reference to the byte slice.
only be used on the forward declarations. examples/noescape.go Note, you're bypassing the checks of the compiler, if you get this wrong you'll corrupt memory and no tool will be able to spot this.
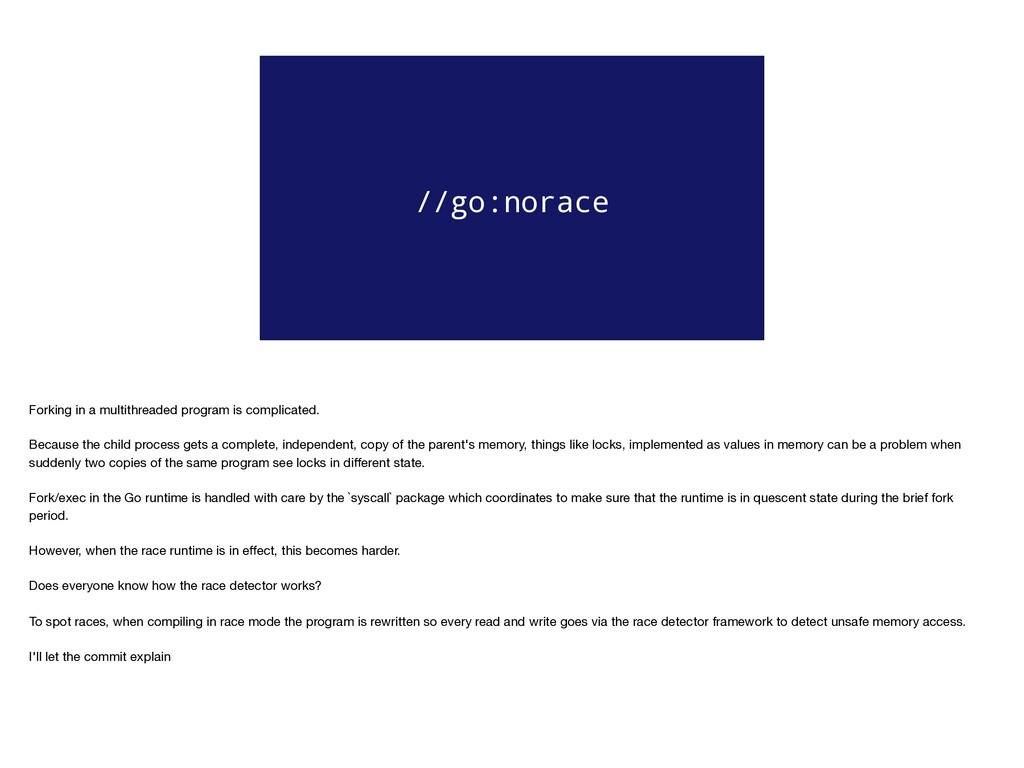
child process gets a complete, independent, copy of the parent's memory, things like locks, implemented as values in memory can be a problem when suddenly two copies of the same program see locks in different state. Fork/exec in the Go runtime is handled with care by the `syscall` package which coordinates to make sure that the runtime is in quescent state during the brief fork period. However, when the race runtime is in effect, this becomes harder. Does everyone know how the race detector works? To spot races, when compiling in race mode the program is rewritten so every read and write goes via the race detector framework to detect unsafe memory access. I'll let the commit explain
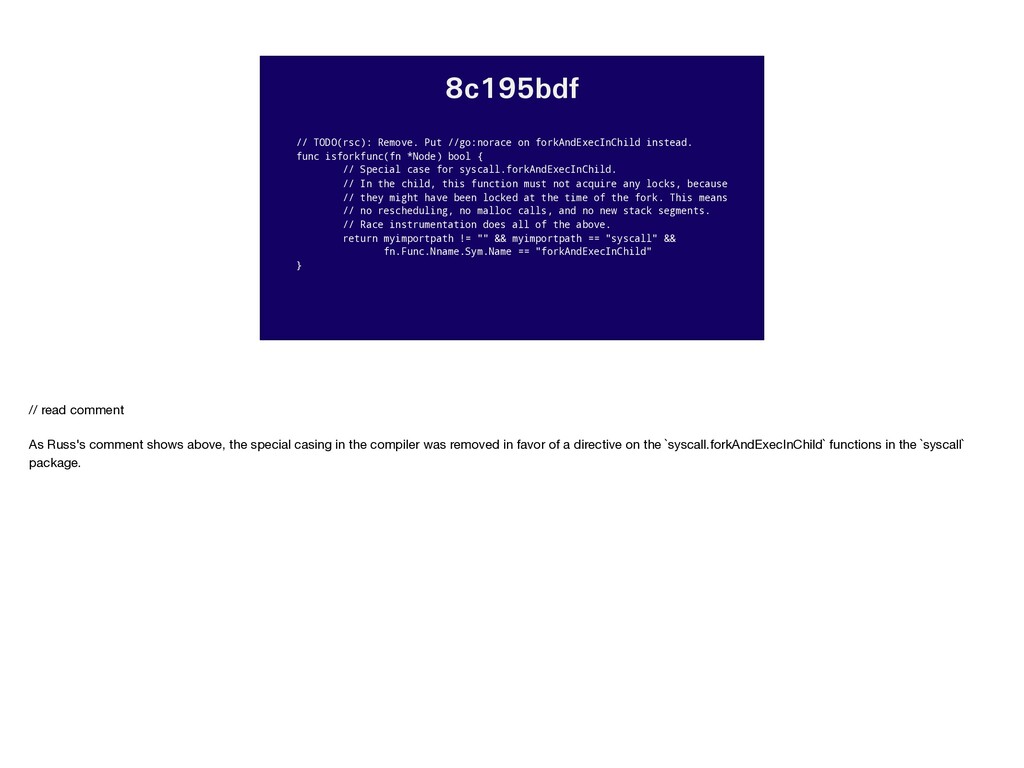
isforkfunc(fn *Node) bool { // Special case for syscall.forkAndExecInChild. // In the child, this function must not acquire any locks, because // they might have been locked at the time of the fork. This means // no rescheduling, no malloc calls, and no new stack segments. // Race instrumentation does all of the above. return myimportpath != "" && myimportpath == "syscall" && fn.Func.Nname.Sym.Name == "forkAndExecInChild" } // read comment As Russ's comment shows above, the special casing in the compiler was removed in favor of a directive on the `syscall.forkAndExecInChild` functions in the `syscall` package.
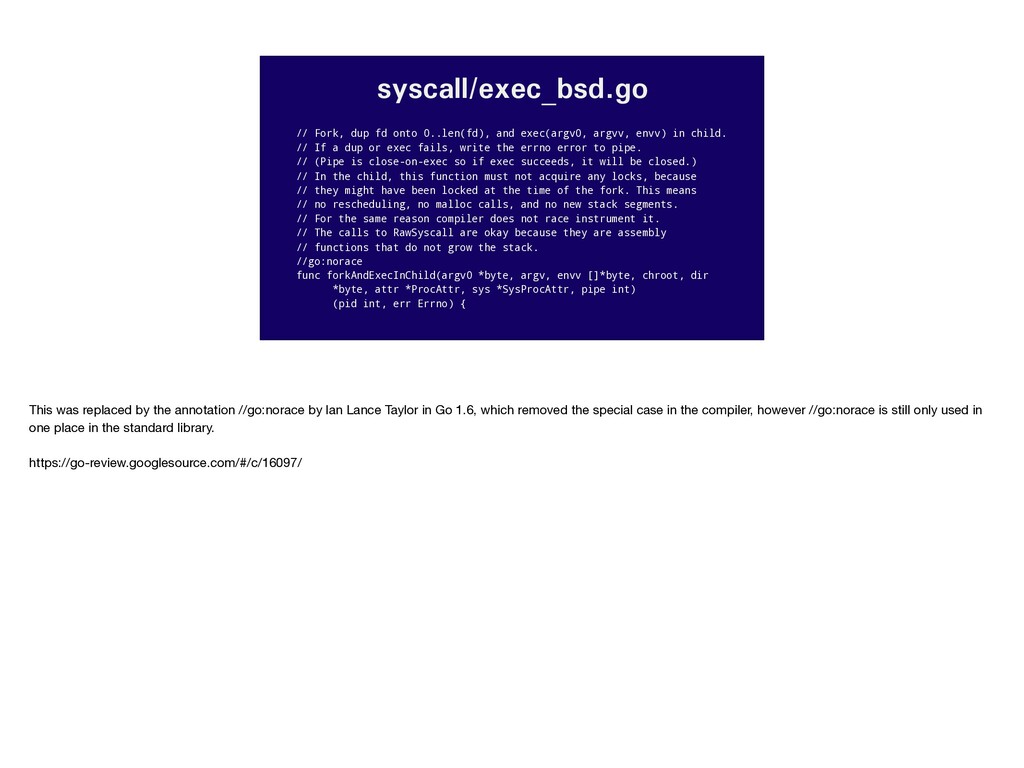
envv) in child. // If a dup or exec fails, write the errno error to pipe. // (Pipe is close-on-exec so if exec succeeds, it will be closed.) // In the child, this function must not acquire any locks, because // they might have been locked at the time of the fork. This means // no rescheduling, no malloc calls, and no new stack segments. // For the same reason compiler does not race instrument it. // The calls to RawSyscall are okay because they are assembly // functions that do not grow the stack. //go:norace func forkAndExecInChild(argv0 *byte, argv, envv []*byte, chroot, dir *byte, attr *ProcAttr, sys *SysProcAttr, pipe int) (pid int, err Errno) { This was replaced by the annotation //go:norace by Ian Lance Taylor in Go 1.6, which removed the special case in the compiler, however //go:norace is still only used in one place in the standard library. https://go-review.googlesource.com/#/c/16097/
//go:norace will instruct the compiler to not annotate the function, thus will not detect any data races if they exist. Given the race detector has no known false positives, there should be very little reason to exclude a function from its scope. examples/norace.go
not a static allocation. Instead each goroutine starts with a few kilobytes of stack and if necessary will grow. The technique that the runtime uses to manage a goroutine’s stack relies on each goroutine keeping track of its current stack usage.
TEXT "".fn(SB), $128-0 0x0000 00000 (main.go:5) MOVQ (TLS), CX 0x0009 00009 (main.go:5) CMPQ SP, 16(CX) 0x000d 00013 (main.go:5) JLS 113 Load current g stack limit Compare current stack use, branch if more stack needed During the function preamble a check is made to ensure there is enough stack space for the function to run. If not, the code traps into the runtime to grow, by copying, the current stack allocation. Now, this preamble is quite small, only a few instructions - a load from an offset of the current g register, which holds a pointer to the current goroutine - a compare against the stack usage for this function, which is a constant known at compile time - and a branch to the slow path, which is rare and easily predictable. But sometimes even this overhead is unacceptable, and occasionally, unsafe, if you’re the runtime package itself. So a mechanism exists to tell the linker, via an annotation in the compiled form of the function to skip the stack check preamble. It should also be noted that the stack check is inserted _by the linker_, not the compiler, so it applies to assembly functions and, while they existed, C functions.
The name `NOSPLIT` harks back to the time when stack growths was handled not by copying, but by a technique called _segmented stacks_, the stack was _split_ over several segments. This technique was abandoned in Go 1.3, but the name remains as a historic curio. https://groups.google.com/d/topic/golang-dev/riFzqp8AXRU/discussion
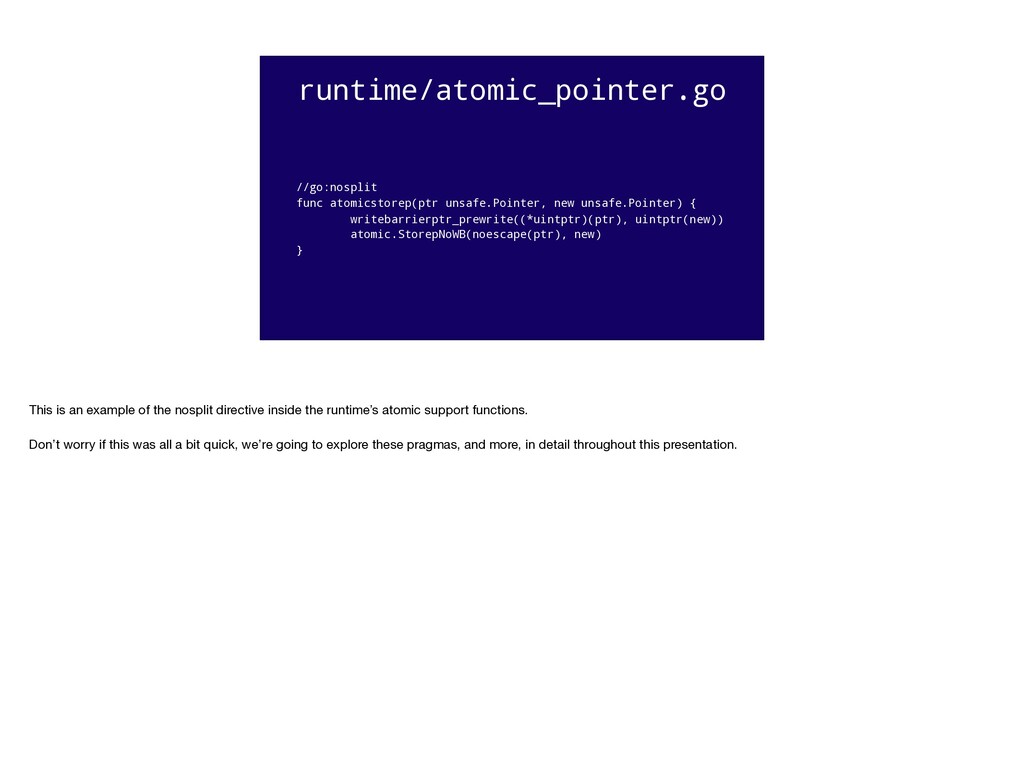
go through readgstatus, casgstatus // castogscanstatus, casfromgscanstatus. #pragma textflag NOSPLIT uint32 runtime·readgstatus(G *gp) { return runtime·atomicload(&gp->atomicstatus); } No stack preamble please Up until Go 1.4, the runtime was implemented in a mix of Go, C and assembly. In this example `runtime.readgstatus` we can see the C style #pragma textflag NOSPLIT
go through // readgstatus, casgstatus, castogscanstatus, // casfrom_Gscanstatus. //go:nosplit func readgstatus(gp *g) uint32 { return atomic.Load(&gp.atomicstatus) } When the runtime was rewritten in Go, we needed some way to say that a particular function should not have the stack split check. This was often because taking a stack split inside the runtime was forbidden because a stack split implicitly needs to allocate memory, which would lead to recursive behaviour. Hence #pragma textflag nosplit became go:nosplit But this leads to a problem.
If a function, written in Go or otherwise, uses nosplit to say “i don’t want to grow the stack at this point”, the compiler still has to ensure it's safe to run the function--we cannot let functions use more stack than they are allowed just because they want to avoid the overhead of the stack check, as they will almost certainly corrupt the heap or another goroutine's memory. To do this, the compiler maintains a buffer called the redzone, a 768 byte allocation at the bottom of each goroutines’ stack frame which is guaranteed to be available. The compiler keeps track of the stack requirements of each function and when it encounters a nosplit function it accumulates that functions stack needs against the redzone. In this way, carefully written nosplit functions can execute safely against the redzone buffer while avoiding stack growth at inconvenient times. examples/redzone.go We occasionally hit this in the `-N`, no optimisation, build on the dashboard as the redzone is enough when optimisations are on, generally inlining small functions, but when inlining is disabled, stack frames are deeper and contain more allocations which are not optimised away.
it probably isn’t necessary) Small functions would benefit most from this optimisation are already good candidates for inlining. And inlining is far more effective at eliminating the overhead of function calls than `//go:nosplit`. You'll note in the example I showed I had to use //go:noinline to disable inlining which otherwise would have detected that `D` actually did nothing - and optimised away the call tree. Of all the pragmas this one is the safest to use, as it will get spotted at compile time, and should generally not affect the correctness of your program, only the performance.
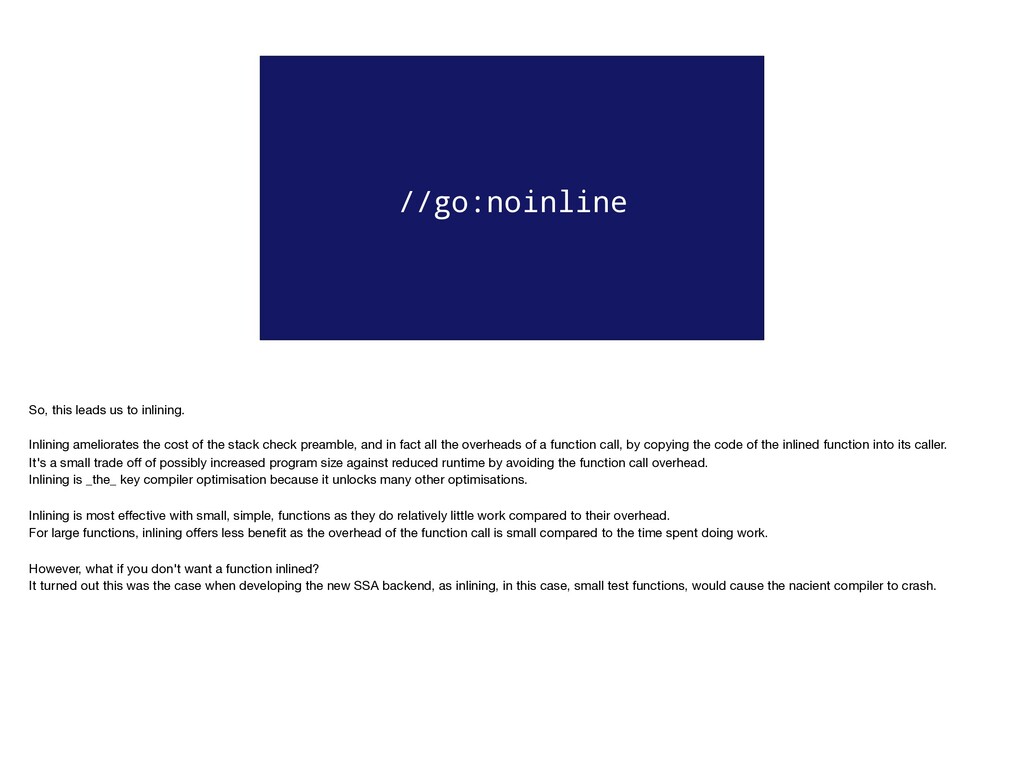
cost of the stack check preamble, and in fact all the overheads of a function call, by copying the code of the inlined function into its caller. It's a small trade off of possibly increased program size against reduced runtime by avoiding the function call overhead. Inlining is _the_ key compiler optimisation because it unlocks many other optimisations. Inlining is most effective with small, simple, functions as they do relatively little work compared to their overhead. For large functions, inlining offers less benefit as the overhead of the function call is small compared to the time spent doing work. However, what if you don't want a function inlined? It turned out this was the case when developing the new SSA backend, as inlining, in this case, small test functions, would cause the nacient compiler to crash.
branch because if a function is inlined, the code contained in that function might switch from being SSA-compiled to old-compiler- compiled. Without some sort of noinline mark the SSA-specific tests might not be testing the SSA backend at all. I’ll let Keith Randall explain
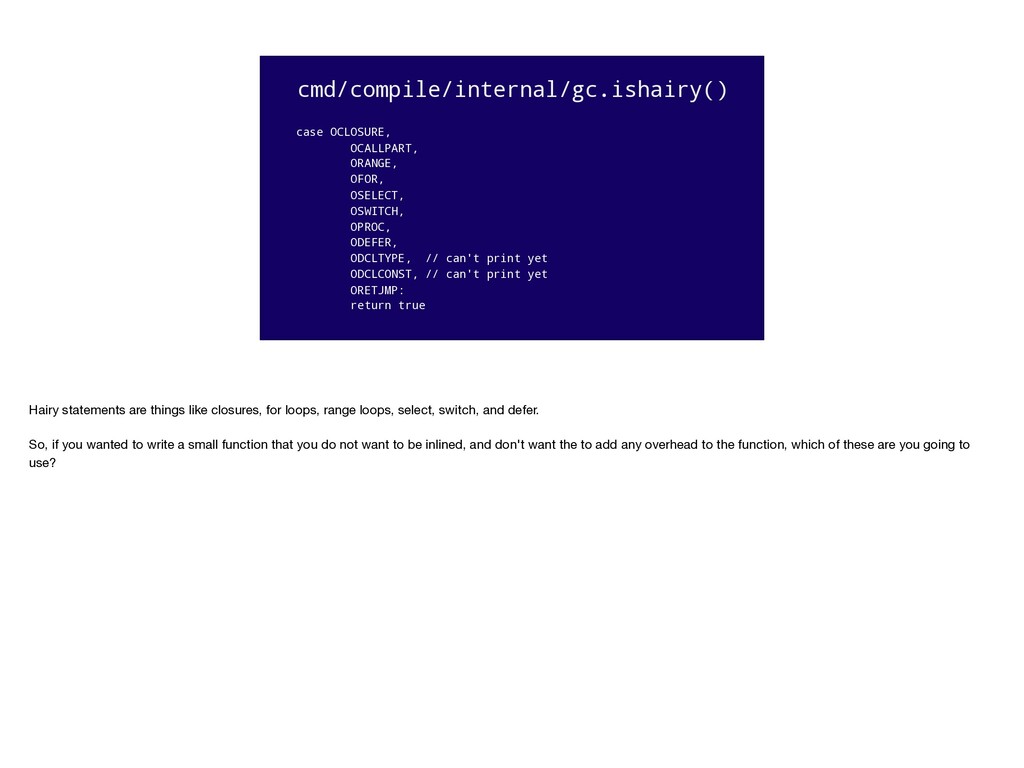
ODCLTYPE, // can't print yet ODCLCONST, // can't print yet ORETJMP: return true Hairy statements are things like closures, for loops, range loops, select, switch, and defer. So, if you wanted to write a small function that you do not want to be inlined, and don't want the to add any overhead to the function, which of these are you going to use?
} Prior to the SSA compiler, `switch {}` would prevent a function being inlined, whilst also optimising to nothing, and this was used heavily in compiler test fixtures to isolate individual operations. With the introduction of the SSA form `switch` was no longer considered _hairy_, as switch is logically the same as a list of `if ... else if` statements. So `switch{}` stopped being a placeholder to prevent inlining. The compiler devs debated how to represent the construct "please don't inline this function, ever", and settled on a new pragma.
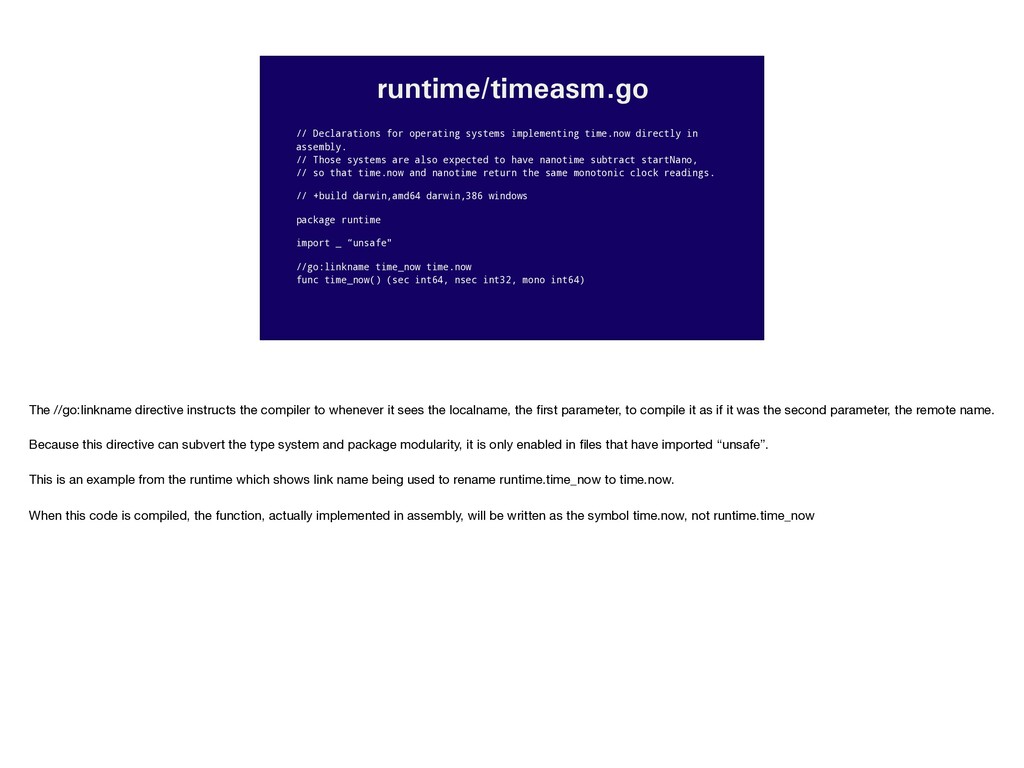
assembly. // Those systems are also expected to have nanotime subtract startNano, // so that time.now and nanotime return the same monotonic clock readings. // +build darwin,amd64 darwin,386 windows package runtime import _ “unsafe" //go:linkname time_now time.now func time_now() (sec int64, nsec int32, mono int64) The //go:linkname directive instructs the compiler to whenever it sees the localname, the first parameter, to compile it as if it was the second parameter, the remote name. Because this directive can subvert the type system and package modularity, it is only enabled in files that have imported “unsafe”. This is an example from the runtime which shows link name being used to rename runtime.time_now to time.now. When this code is compiled, the function, actually implemented in assembly, will be written as the symbol time.now, not runtime.time_now
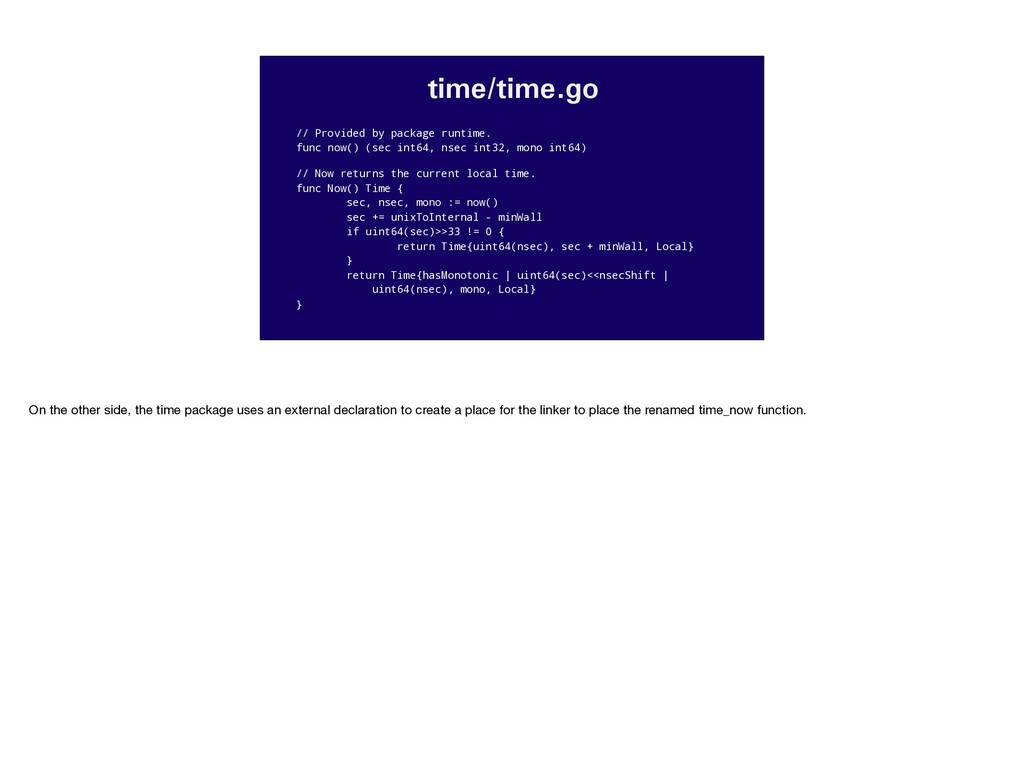
nsec int32, mono int64) // Now returns the current local time. func Now() Time { sec, nsec, mono := now() sec += unixToInternal - minWall if uint64(sec)>>33 != 0 { return Time{uint64(nsec), sec + minWall, Local} } return Time{hasMonotonic | uint64(sec)<<nsecShift | uint64(nsec), mono, Local} } On the other side, the time package uses an external declaration to create a place for the linker to place the renamed time_now function.
look in the standard library there is quite a bit of use of linkname. It’s used to expose runtime functions to other packages without having to make the runtime symbol public. So, can you use go:linkname in your code? Yes, although because it allows you to side step the module system, you are required to import unsafe as a marker.
an internal identifier. This identifier is not exposed to Go code for good reason — we don’t want you writing your own version of thread local storage. But .. say, as an experiment, you want to find out the id of a goroutine.
the retelling of this history has been interesting to you. The wider story arc of Go’s pragmas is they are used inside the standard library to gain a foothold to implement the runtime, including the garbage collector, in Go itself. Pragmas allowed the runtime devs to extend, the language just enough to meet the requirements of the problem. You’ll find pragmas used, sparingly, inside the standard library, although you'll never find them listed in godoc. Should you use these pragmas in your own programs? Possibly, //noescape is useful when writing assembly glue, which we do quite often in the crypto packages. For the other pragmas, outside demos and presentations like this, I don’t think there is much call for using them.
breaks, you get to keep both pieces.” But please remember, magic comments are _not_ part of the language spec, if you use gopherjs, or llgo, or gccgo, your code will still compile, but may operate differently. So please use this advice sparingly. https://groups.google.com/d/msg/golang-nuts/UoYT9Y8tRwE/_G8a9ooS-P4J Thank you.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Rust #[inline(always)] fn super_fast_fn() { ... } #[cfg(target_os = "macos")]](https://files.speakerdeck.com/presentations/b0c2ea6c52c24572be02716be109afda/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![b escapes var AvailableForLoan []*Book func AddToCollection(b *Book) { AvailableForLoan](https://files.speakerdeck.com/presentations/b0c2ea6c52c24572be02716be109afda/slide_23.jpg){kind=link}
![os.File.Read f, _ := os.Open("/tmp/foo") buf := make([]byte, 4096) n,](https://files.speakerdeck.com/presentations/b0c2ea6c52c24572be02716be109afda/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![golang.org/issue/4099 commit fd178d6a7e62796c71258ba155b957616be86ff4 Author: Russ Cox <[email protected]> Date: Tue Feb](https://files.speakerdeck.com/presentations/b0c2ea6c52c24572be02716be109afda/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}