0.2 0.4 0.6 0.5 1 1.5 2 p = 1/2 p = 1 p = 3/2 p = 2 Figure 5.1: Top: examples of semi-discrete ¯ c-transforms g ¯ c in 1-D, for ground d the useful indicator function notation (4.42). alternate minimization on either f or g leads to the im- n of c-transform: ’ y œ Y, fc(y) def. = inf xœX c(x, y) ≠ f(x), (5.1) ’ x œ X, g¯ c(x) def. = inf yœY c(x, y) ≠ g(y), (5.2) oted ¯ c(y, x) def. = c(x, y). Indeed, one can check that œ argmax g E(f, g) and g¯ c œ argmax f E(f, g). (5.3) ese partial minimizations define maximizers on the sup- tively – and —, while the definitions (5.1) actually define he whole spaces X and Y. This is thus a way to extend in ay solutions of (2.22) on the whole spaces. When X = Rd Îx ≠ yÎp, then the c-transform (5.1) fc is the so-called n between ≠f and ηÎp. The definition of fc is also often a “Hopf-Lax formula”. (f, g) œ C(X) ◊ C(Y) ‘æ (g¯ c, fc) œ C(X) ◊ C(Y) replaces s by “better” ones (improving the dual objective E). Func- be written in the form fc and g¯ c are called c-concave and ctions. In the special case c(x, y) = Èx, yÍ in X = Y = Rd, n coincides with the usual notion of concave functions. turally Proposition 3.1 to a continuous case, one has the operations are replaced by a “soft-min”. Using (5.3), one can reformulate (2.22) as an unconstrained program over a single potential Lc (–, —) = max fœC ( X ) ⁄ X f(x)d–(x) + ⁄ Y fc(y)d—(y), = max gœC ( Y ) ⁄ X g¯ c(x)d–(x) + ⁄ Y g(y)d—(y). Since one can iterate the map (f, g) ‘æ (g¯ c, fc), it is possible to these optimization problems the constraint that f is ¯ c-concave is c-concave, which is important to ensure enough regularity on potentials and show for instance existence of solutions to (2.22) 5.2 Semi-discrete Formulation A case of particular interest is when — = q j bj ” yj is discrete (of the same construction applies if – is discrete by exchanging the (–, —)). One can adapt the definition of the ¯ c transform (5.1) setting by restricting the minimization to the support (y j ) j of — ’ g œ Rm, ’ x œ X, g ¯ c(x) def. = min jœJmK c(x, y j ) ≠ gj . This transform maps a vector g to a continuous function g ¯ c œ Note that this definition coincides with (5.1) when imposing th space X is equal to the support of —. Figure 5.1 shows some ex of such discrete ¯ c-transforms in 1-D and 2-D. Using this discrete ¯ c-transform, in this semi-discrete case, ( equivalent to the following finite dimensional optimization
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![µ f]µ f f ' Measures: push-forward Functions: pull-back f]'](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Monge Transport min ⌫=f]µ Z X c(x, f(x))dµ(x) f X](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_16.jpg){kind=link}
![Monge Transport min ⌫=f]µ Z X c(x, f(x))dµ(x) f X](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_17.jpg){kind=link}
![Monge Transport min ⌫=f]µ Z X c(x, f(x))dµ(x) f X](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_18.jpg){kind=link}
![Monge Transport min ⌫=f]µ Z X c(x, f(x))dµ(x) f X](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![OT Between General Measures Couplings: P1]⇡(S) def. = ⇡(S, X)](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![29 The Word Mover’s Distance [Kusner’15] dist(D1, D2) = W2(µ,](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MRI Data Procesing [with A. Gramfort] L2 barycenter W2 2](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_63.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Topic Models [Rolet’16]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_93.jpg){kind=link}
{kind=link}
{kind=link}
![Unbalanced Transport [Liereo, Mielke, Savar´ e 2015] [Chizat, Schmitzer, Peyr´](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_96.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Wasserstein Gradient Flows Implicit Euler step: [Jordan, Kinderlehrer, Otto 1998]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_100.jpg){kind=link}
![Wasserstein Gradient Flows Implicit Euler step: [Jordan, Kinderlehrer, Otto 1998]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_101.jpg){kind=link}
![Wasserstein Gradient Flows Implicit Euler step: [Jordan, Kinderlehrer, Otto 1998]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_102.jpg){kind=link}
![Wasserstein Gradient Flows Implicit Euler step: [Jordan, Kinderlehrer, Otto 1998]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_103.jpg){kind=link}
![Wasserstein Gradient Flows Implicit Euler step: [Jordan, Kinderlehrer, Otto 1998]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_104.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Generalized Entropic Regularization Primal: min ⇡ hdp, ⇡i + f1(P1]⇡)](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_108.jpg){kind=link}
![Generalized Entropic Regularization Primal: min ⇡ hdp, ⇡i + f1(P1]⇡)](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_109.jpg){kind=link}
![Generalized Entropic Regularization Primal: min ⇡ hdp, ⇡i + f1(P1]⇡)](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_110.jpg){kind=link}
![Generalized Entropic Regularization Primal: min ⇡ hdp, ⇡i + f1(P1]⇡)](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_111.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Examples of Image Generation [Credit ArXiv:1511.06434] g✓ Z X](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_139.jpg){kind=link}
{kind=link}
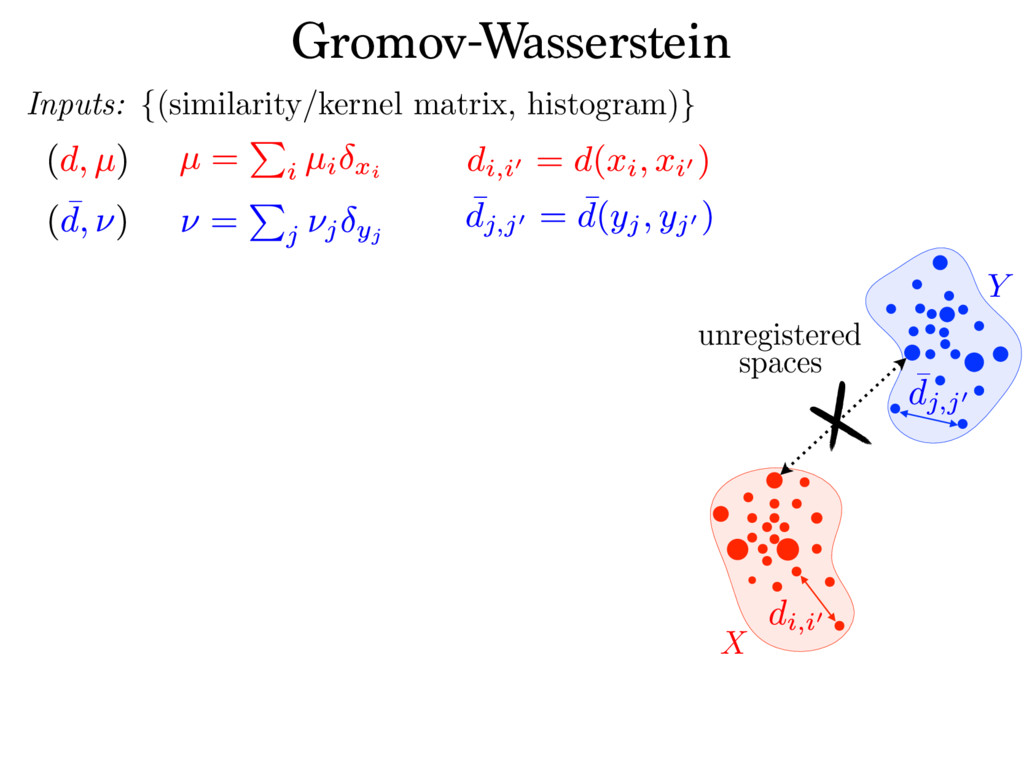{kind=link}
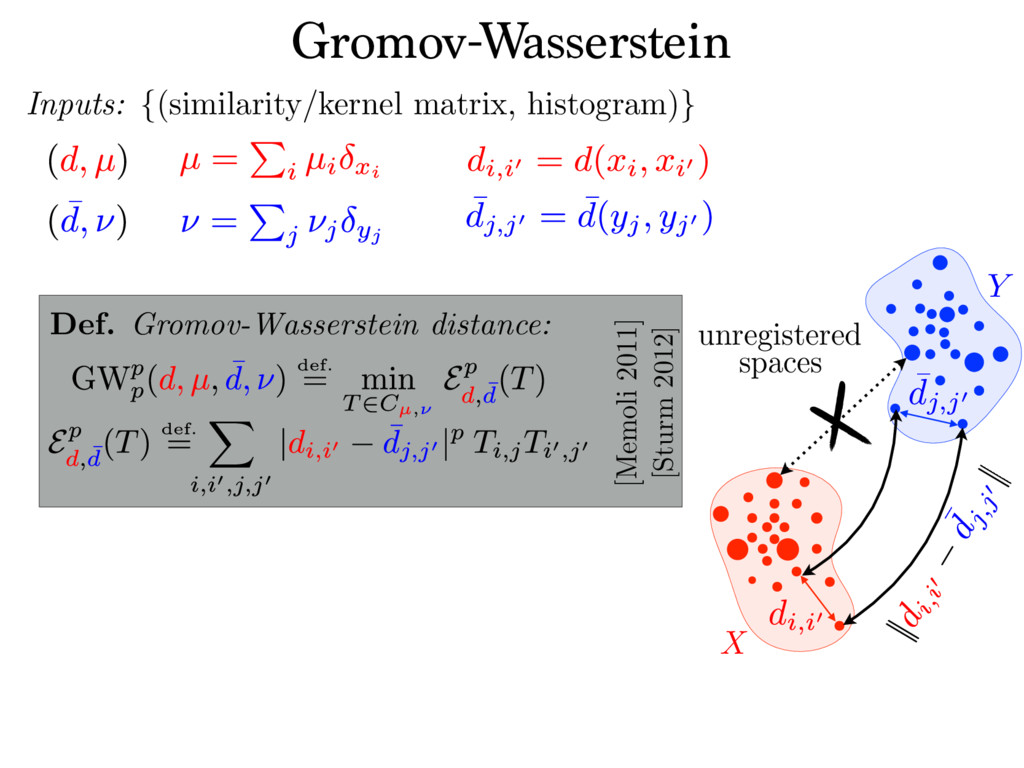{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gromov-Wasserstein Geodesics Def. Gromov-Wasserstein Geodesic Prop. [Sturm 2012]](https://files.speakerdeck.com/presentations/322fda33356748a8b56ffb9b3e65972b/slide_159.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}