• iOS/AndroidはGoogleAnalyticsに飛ばしていたイベントを FirebaseAnalyticsにも飛ばすようにした。 • GoogleAnalyticsのEventは、パラメータにactionとlabelという物を付 けていた。それをそのままFirebaseAnalyticsにも飛ばした。 イベントログ 2017年12月開始の施策 13 select event_name, (select value.string_value FROM UNNEST(event_params) WHERE key = 'action') as action, (select value.string_value FROM UNNEST(event_params) WHERE key = 'label') as label, from `analytics_1234.events_*` where _TABLE_SUFFIX = REPLACE(CAST(DATE_SUB(CURRENT_DATE, INTERVAL 1 day) AS string), '-', '')
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
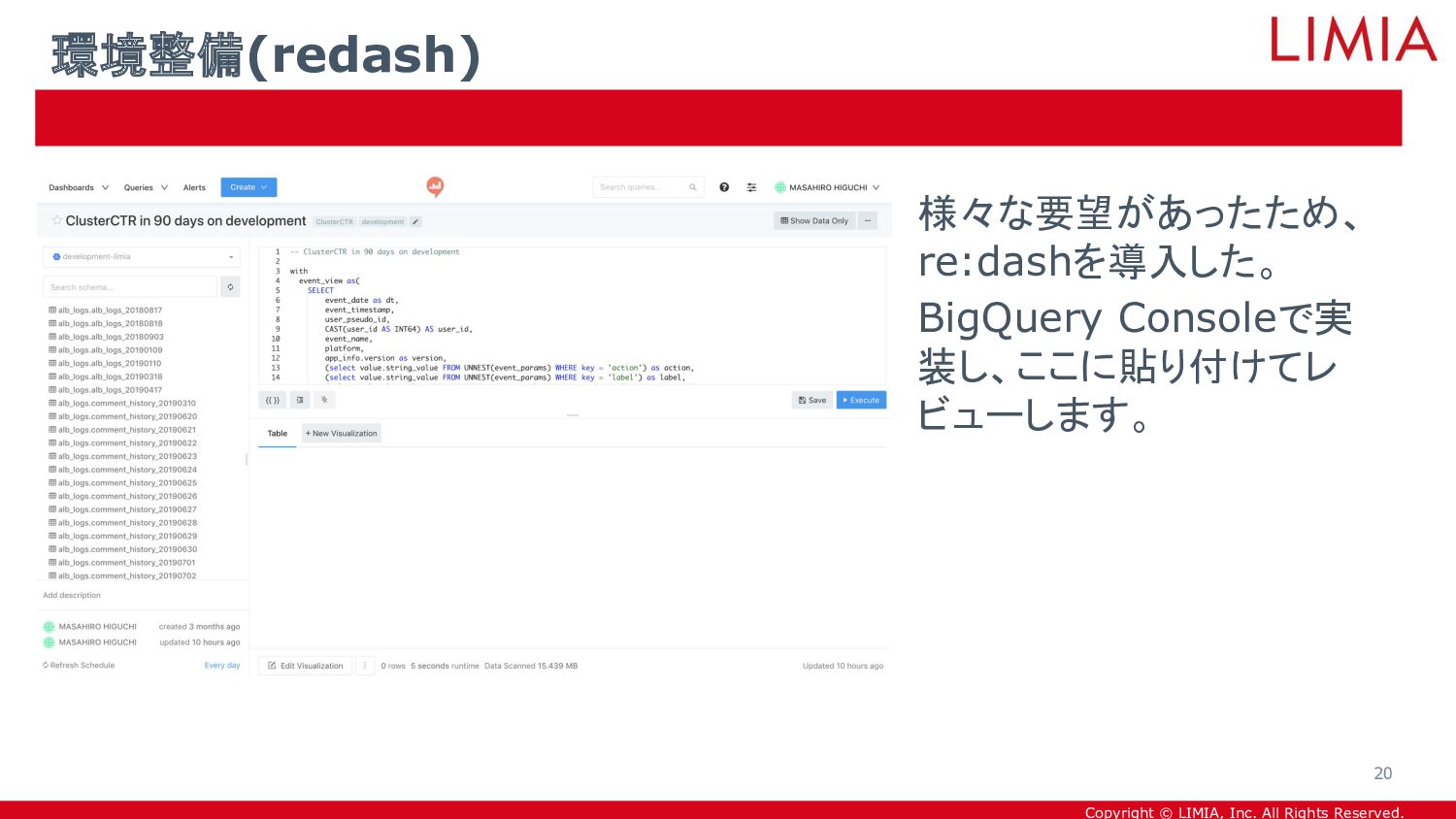{kind=link}
{kind=link}
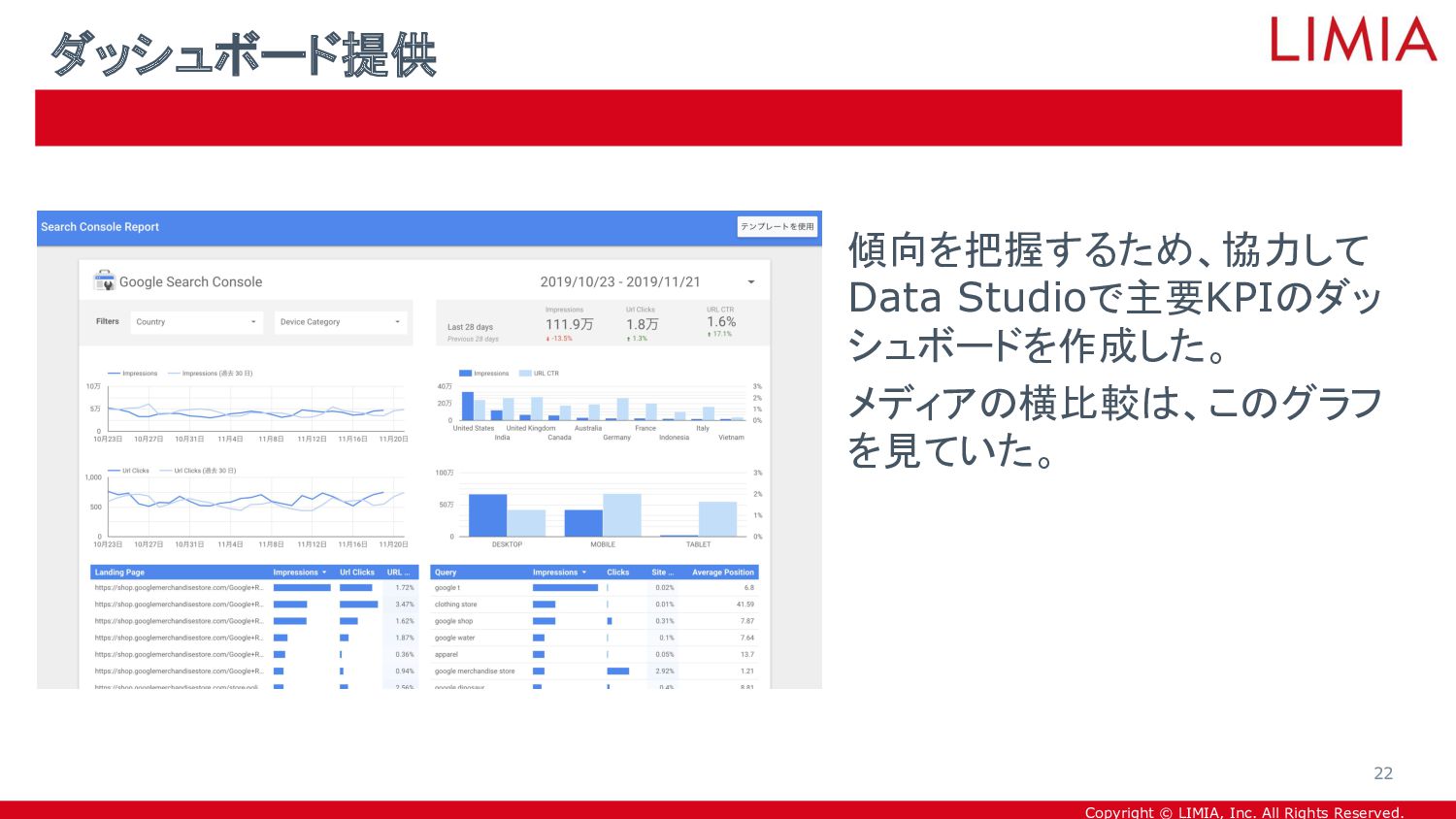{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
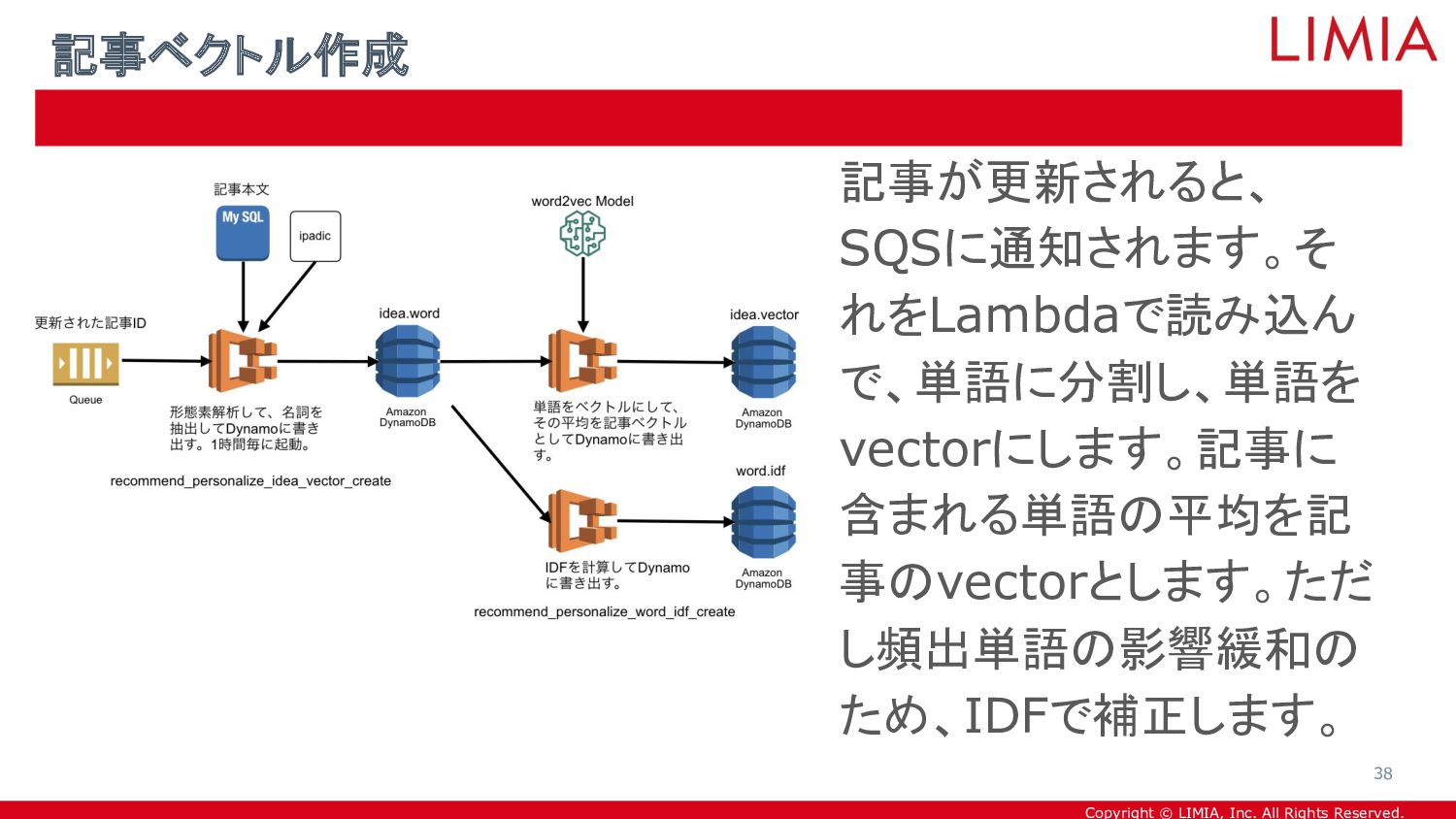{kind=link}
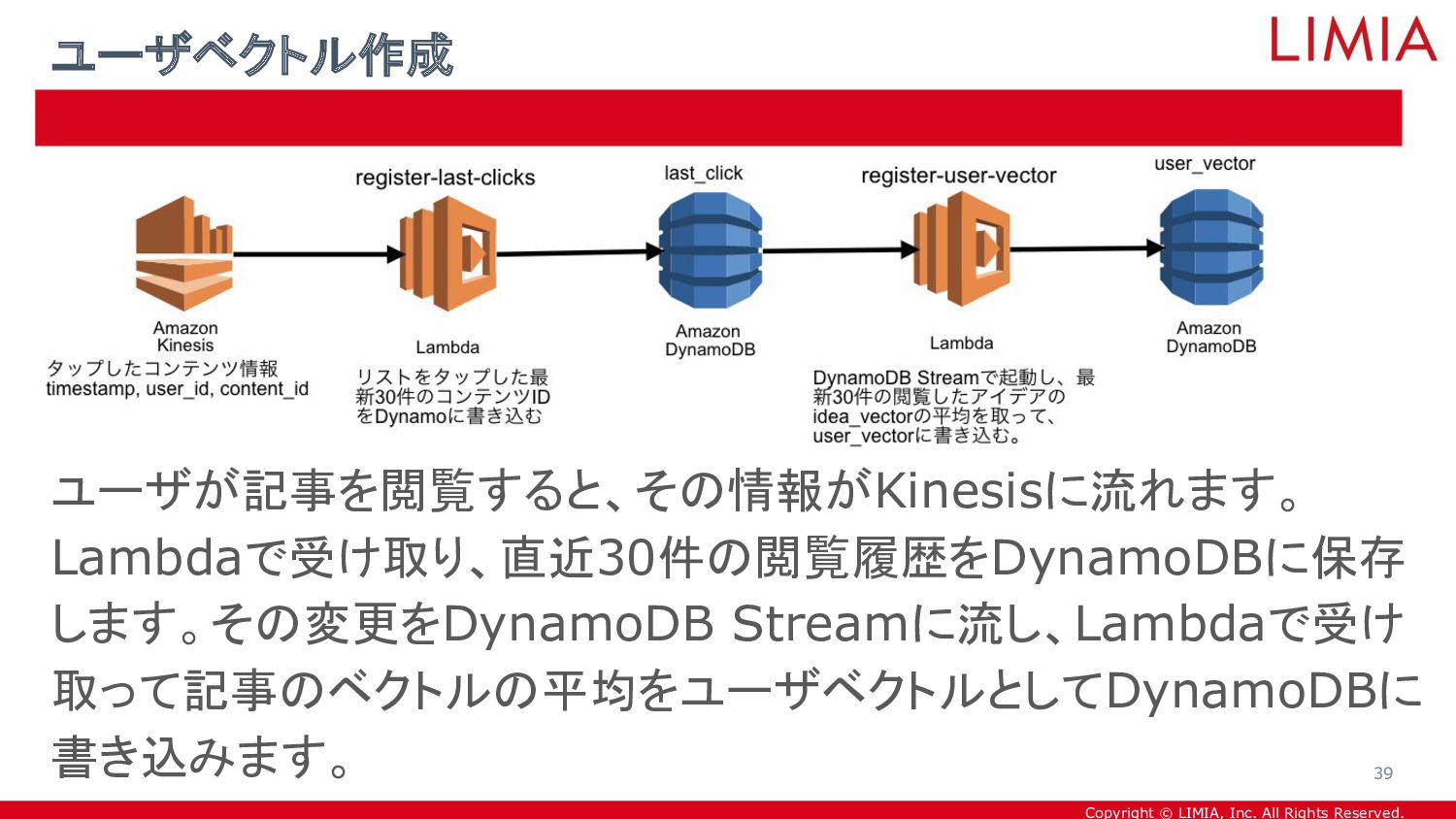{kind=link}
{kind=link}
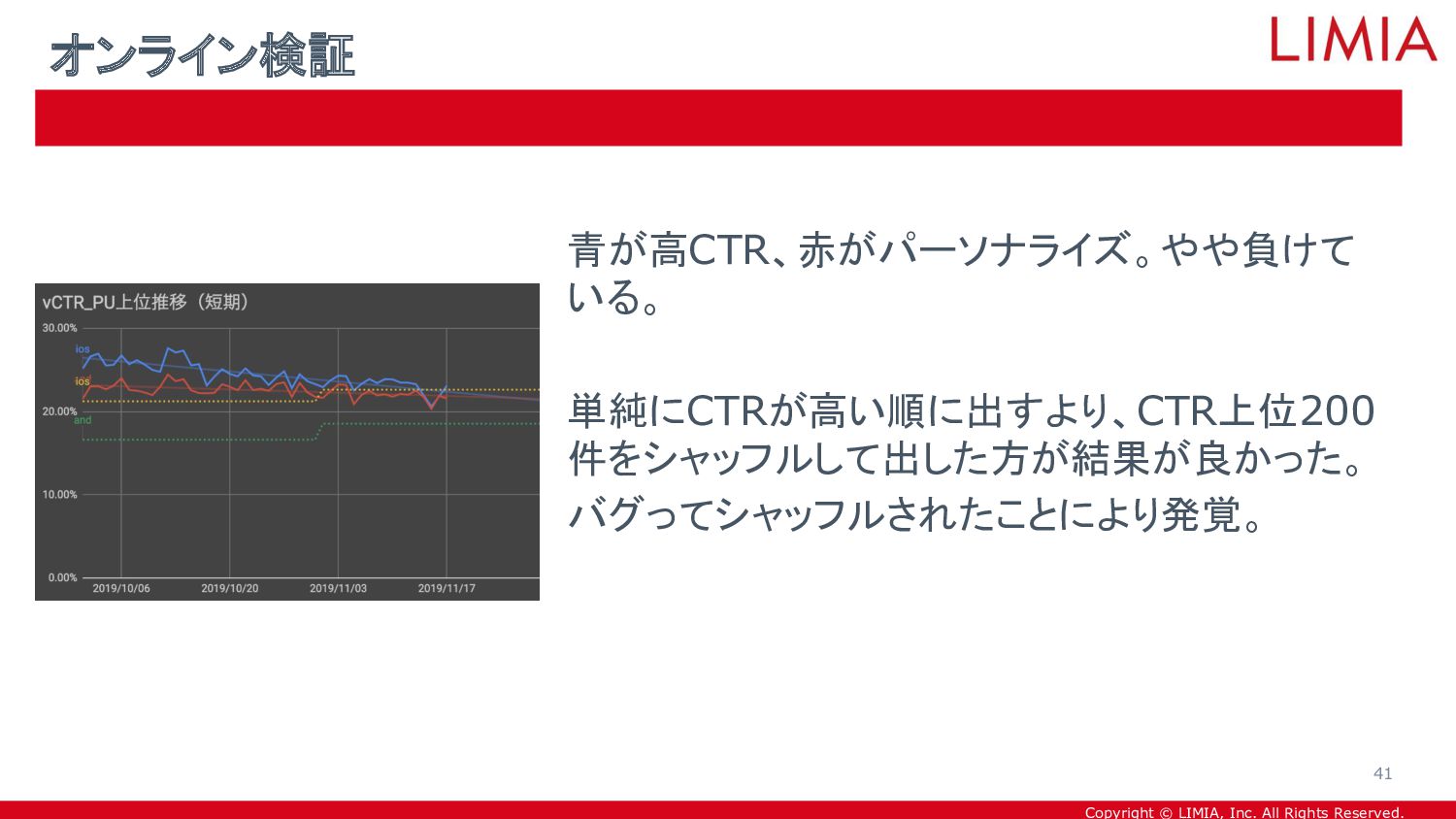{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}