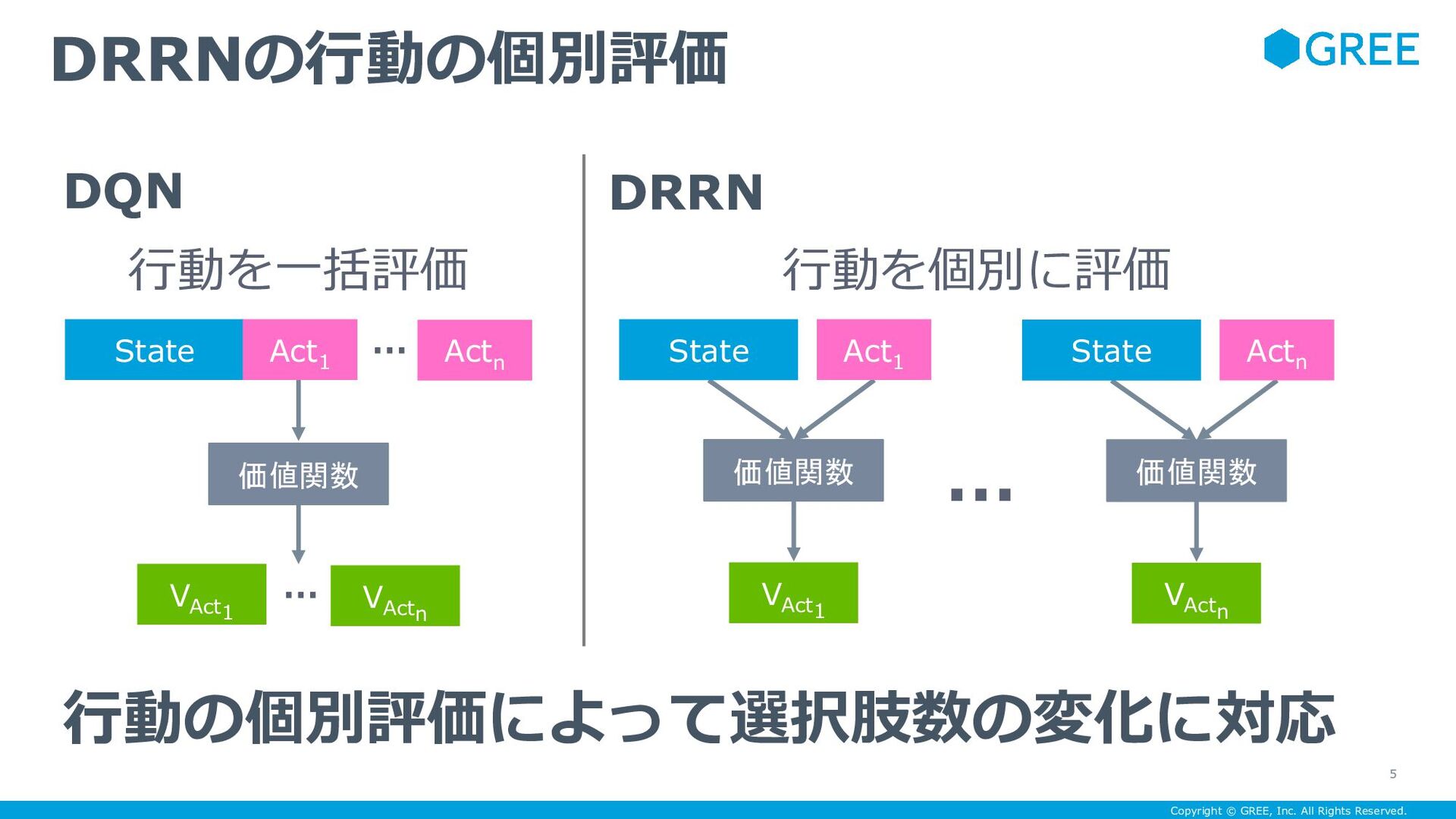
with a Natural Language Action Space He et al., 2016 ゲームの強化学習効率化に関する先行研究 4 • テキストゲームの強化学習効率化 • 状態が自然言語で表される • 行動を自然言語で入力する • Deep Reinforcement Relevance Network (DRRN) • 行動を個別に評価 • 状態と行動をそれぞれ埋め込む あなたは川のそばにいます > 南へ行く 川は5cm程の隙間に流れ込んでいます > 隙間へ行く 隙間は狭すぎて入れません
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}