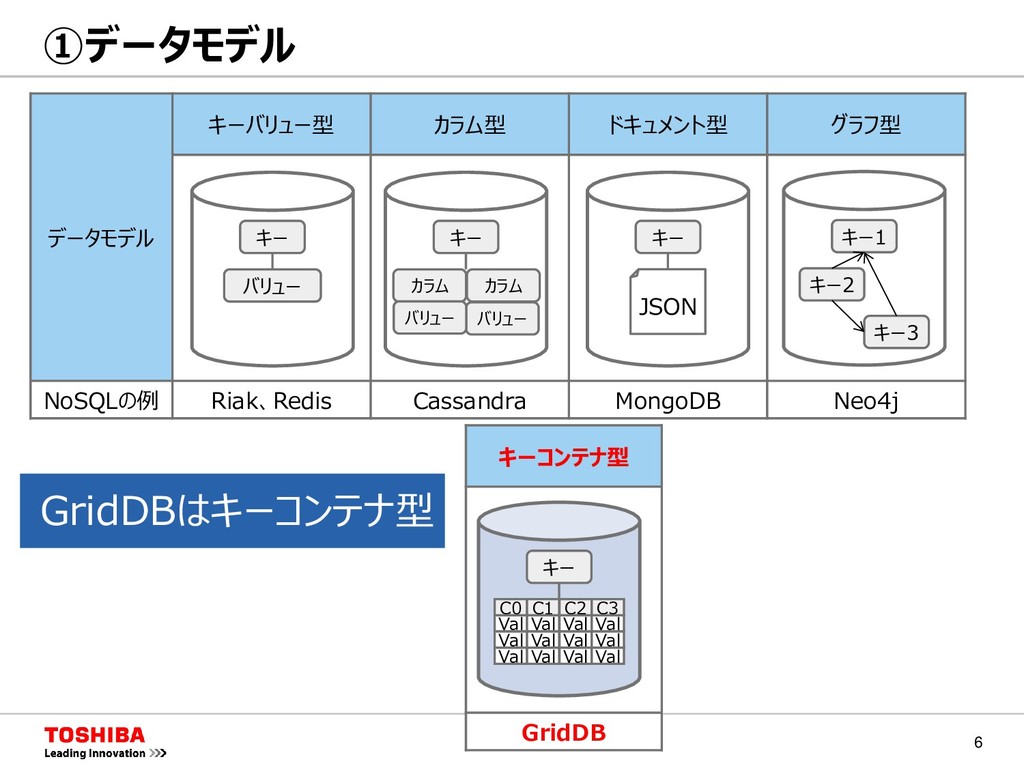
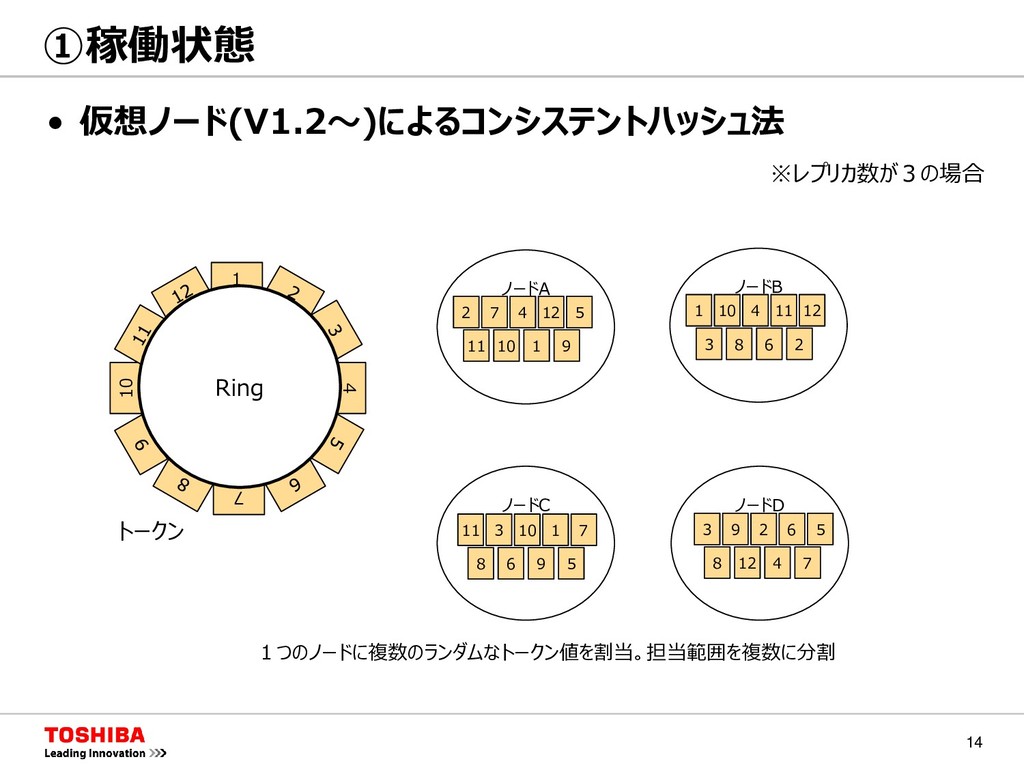
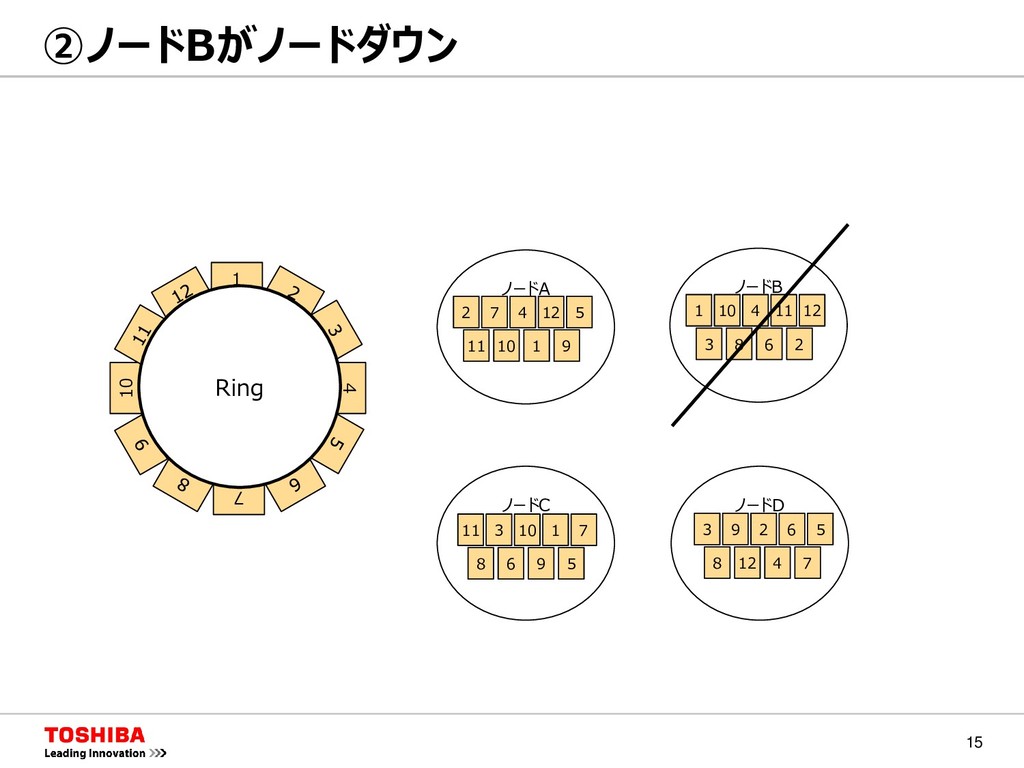
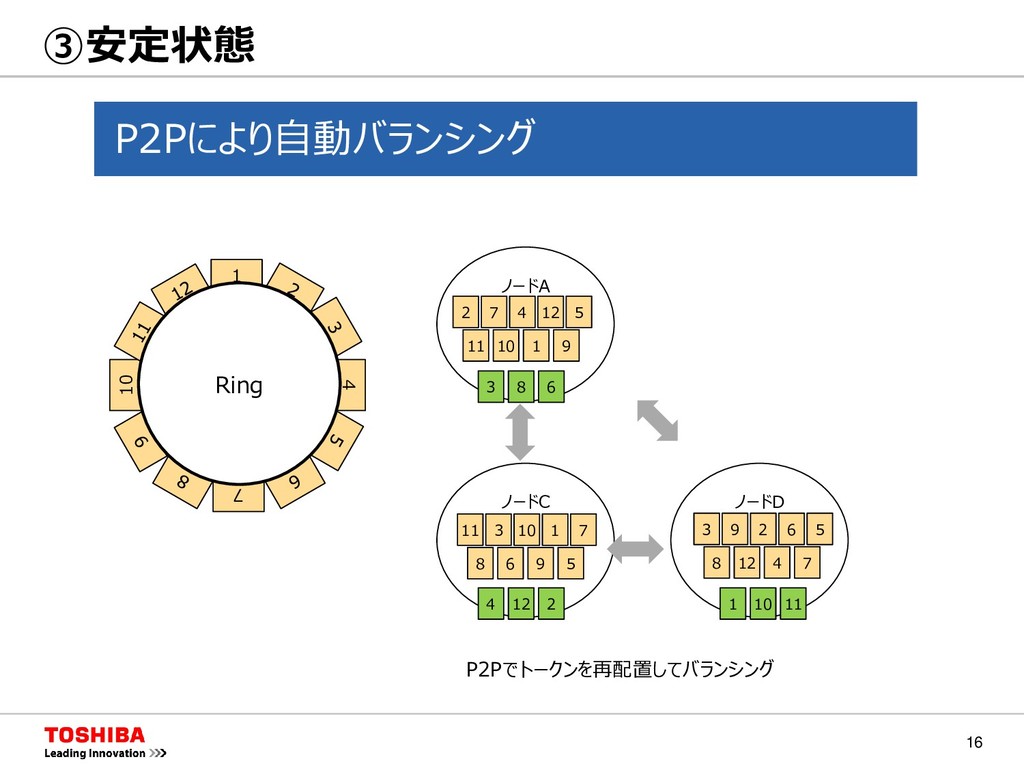
MongoDB Neo4j キー バリュー キー カラム バリュー カラム バリュー キー JSON キーコンテナ型 GridDB キー1 キー2 キー3 キー C0 C1 C2 C3 Val Val Val Val Val Val Val Val Val Val Val Val GridDBはキーコンテナ型
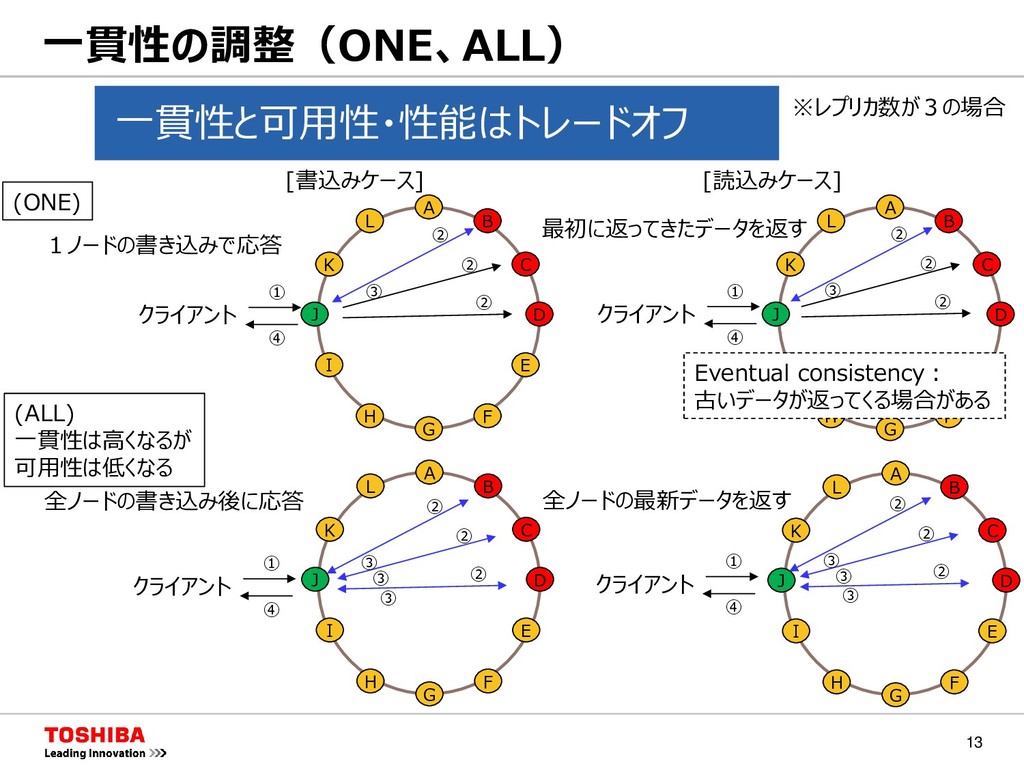
F G H I J K L A B C D E F G H I J K L A B C D E F G H I J K L [書込みケース] [読込みケース] (ONE) 最初に返ってきたデータを返す 全ノードの最新データを返す 全ノードの書き込み後に応答 1ノードの書き込みで応答 A B C D E F G H I J K L クライアント ① ② ③ ② ② ④ クライアント ① ② ③ ② ② ④ クライアント ① ② ③ ② ② ④ ③ ③ クライアント ① ② ③ ② ② ④ ③ ③ Eventual consistency: 古いデータが返ってくる場合がある ※レプリカ数が3の場合 一貫性と可用性・性能はトレードオフ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10 ③一貫性と可用性 • CAP定理: E. Brewer, "Towards Robust Distributed Systems“[1]](https://files.speakerdeck.com/presentations/0a7451fa13964c989415557cb2bc86d3/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
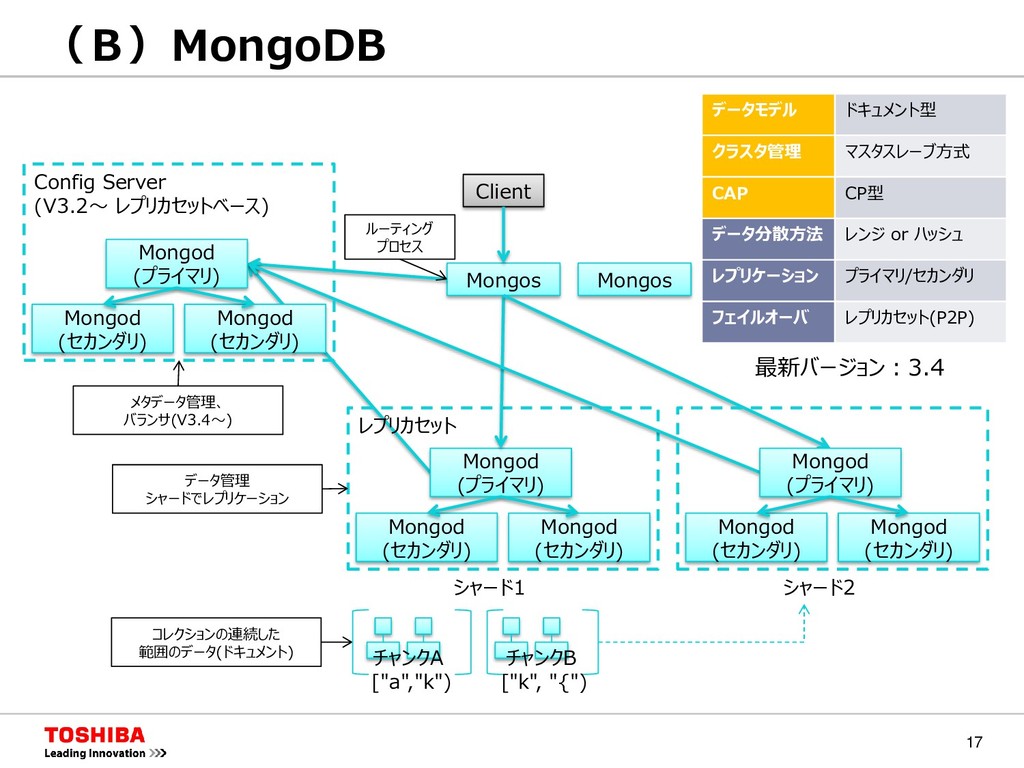{kind=link}
{kind=link}
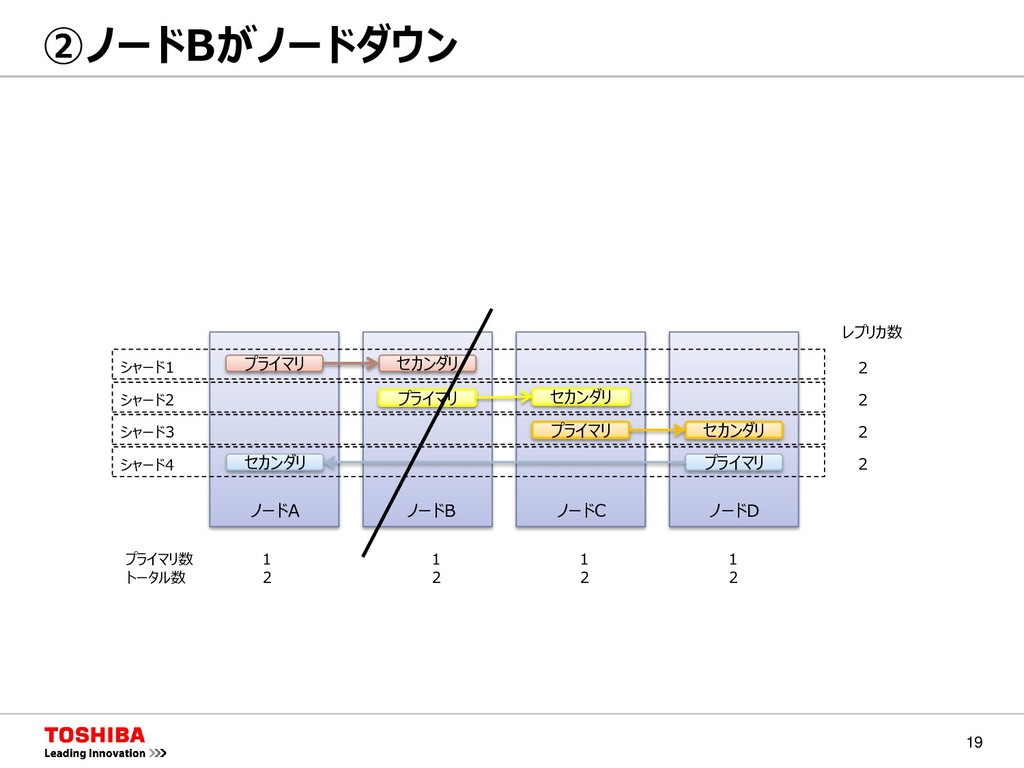{kind=link}
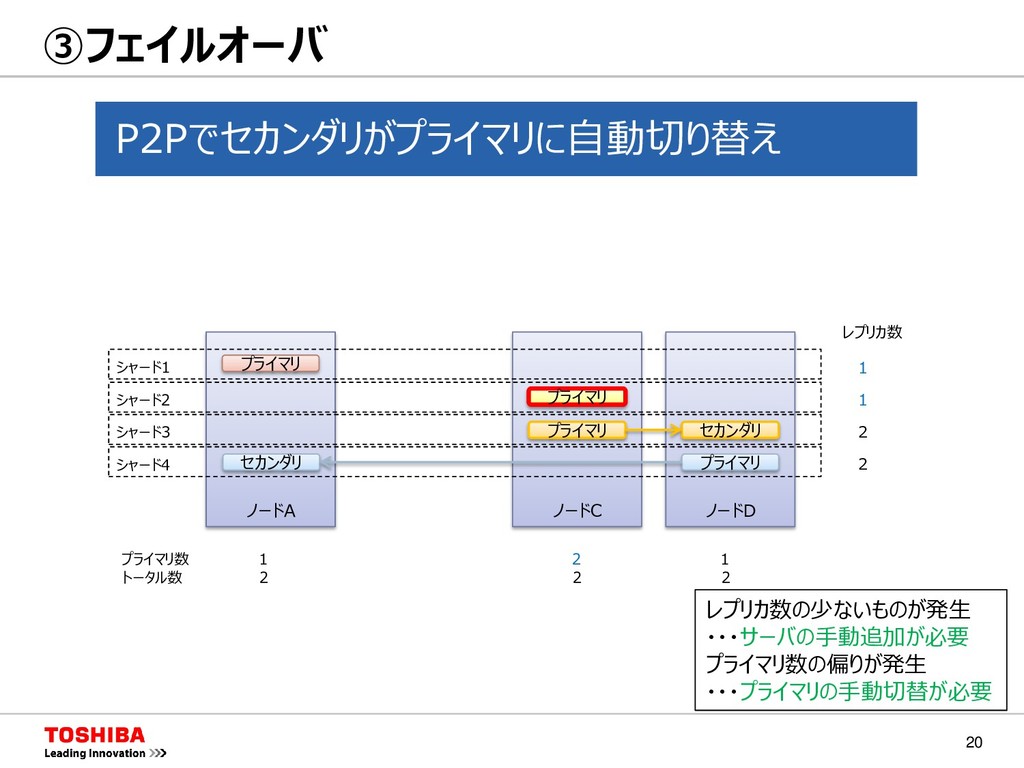{kind=link}
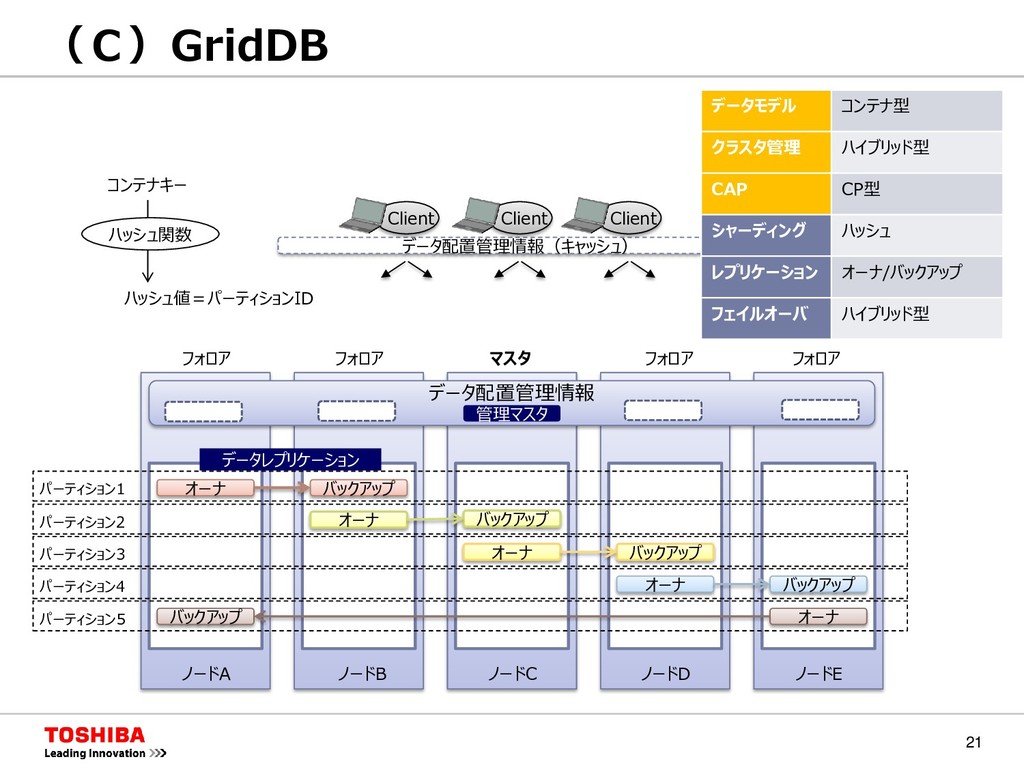{kind=link}
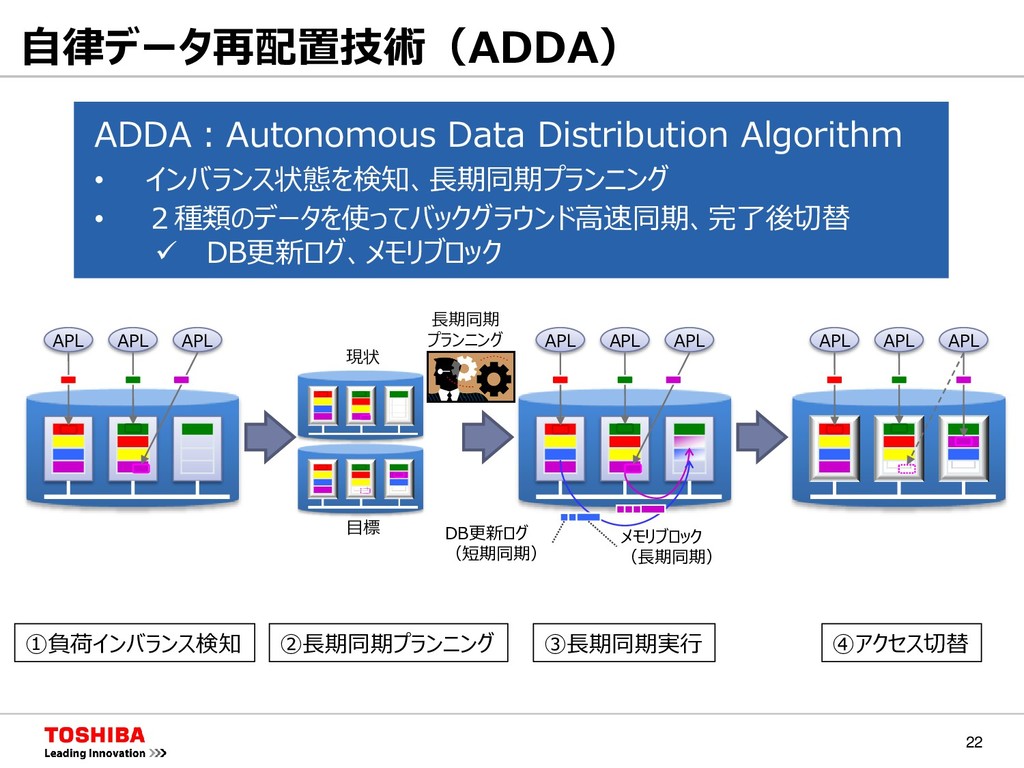{kind=link}
{kind=link}
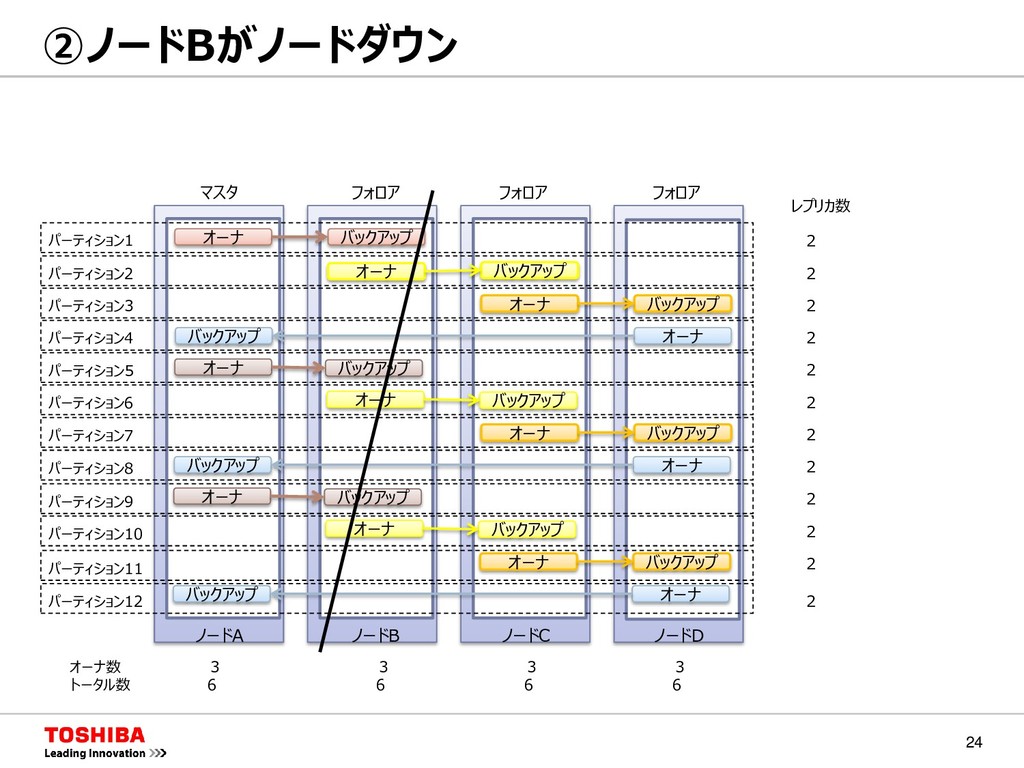{kind=link}
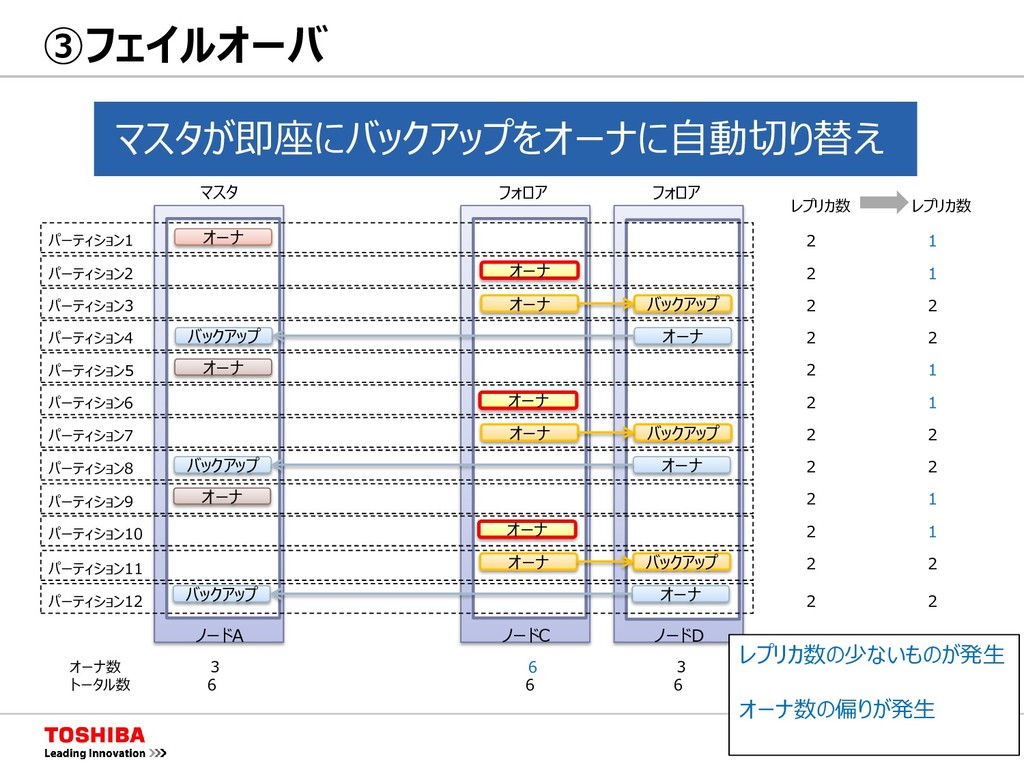{kind=link}
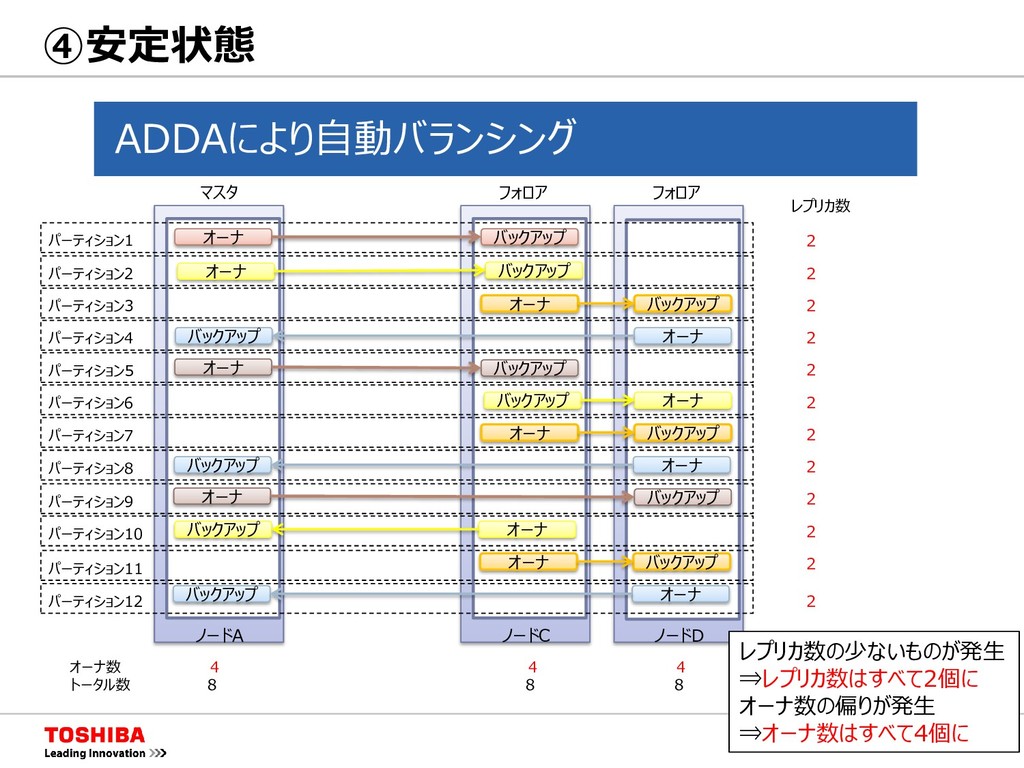{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}