Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
B3 勉強会 第八回
Search
gumigumi7
February 25, 2016
0
100
B3 勉強会 第八回
gumigumi7
February 25, 2016
Tweet
Share
More Decks by gumigumi7
See All by gumigumi7
文献紹介 1月24日
gumigumi7
0
250
文献紹介 11月7日
gumigumi7
0
140
文献紹介 10月3日
gumigumi7
0
330
文献紹介 9月3日
gumigumi7
0
270
文献紹介 8月10日
gumigumi7
0
130
文献紹介 7月16日
gumigumi7
0
260
文献紹介 6月12日
gumigumi7
0
330
文献紹介 5月16日
gumigumi7
0
190
文献紹介 4月18日
gumigumi7
0
150
Featured
See All Featured
YesSQL, Process and Tooling at Scale
rocio
174
15k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
2.1k
First, design no harm
axbom
PRO
2
1.1k
エンジニアに許された特別な時間の終わり
watany
106
230k
jQuery: Nuts, Bolts and Bling
dougneiner
65
8.4k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.4k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
450
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
1
58
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.1k
Deep Space Network (abreviated)
tonyrice
0
64
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.2k
Transcript
B3 勉強会 第八回 (2016/02/25) 長岡技術科学大学 B3 桾澤 優希 機械翻訳 (1)
機械翻訳 ▪ ある言語(原言語)から別の言語(目的言語)へのコン ピュータ処理による翻訳 ▪ 対訳コーパスを用いた方法によって、英語とフランス語のよ うに類似した言語間では解釈可能な翻訳が可能 ▪ しかし、言語は社会の慣習であり、慣習は言語依存であ るため、言語間に存在するズレによって機械翻訳は難しい
物になっている
機械翻訳の難しさ ▪ 語彙のズレ ▪ 言語間の語句の対応は1対1ではないことに起因する。 ▪ 英語の「put on」は日本語では目的語によって「帽子をかぶる」「めが ねをかける」「服を着る」などになる。 ▪
一般的には「飲む=drink」であるが、「スプーンでスープを飲む」を翻 訳すると「eat soop with a spoon」となる。 ▪ 語順の違い ▪ 言語によって語順が異なる ▪ 日本語は述語が文末で、項の語順が比較的自由であるのに対して、 英語は主語、動詞、目的語の順で固定である
機械翻訳の難しさ ▪ 構造のズレ ▪ 単純な語順の違いは構文解析によって吸収できるが、さらに構造が 異なる翻訳関係も少なくない ▪ 「AがBによってCになった」と「B makes A
C」では意味が同じである が、主語が異なる ▪ 明示する表現の違い ▪ 英語では単数・複数を区別し、冠詞を用いるが、日本語ではこれらが ないため日本語から英語への翻訳で問題となる ▪ 逆に日本語では「二枚」「三枚」と様々な助数詞が用いられるが、英 語ではこれらがないため、英日翻訳では問題となる
機械翻訳の歴史 ▪ 構文トランスファー方式 (syntactic transfer) ▪ 規則によって原言語文の構文を解析、目的言語への構造的翻訳を 行うもの ▪ アナロジーに基づく翻訳
(translation by analogy) ▪ 過去の翻訳用例を用い、組み合わせることで新たな翻訳文を作る ▪ 現在では用例翻訳と呼ばれる ▪ 統計的機械翻訳 (statistical machine translation) ▪ 大量の対訳文データを用いて語の対応や語順の並び替えを統計的 に学習し、それに基づき翻訳 ▪ コーパスに基づく翻訳 (corpus-based machine translation) ▪ 対訳データ中の言語の対応を自動学習し翻訳
統計的機械翻訳 ▪ 大量の対訳文データを用いて語の対応や語順の並び替 えを統計的に学習し、それに基づき翻訳 ▪ 翻訳のプロセスを暗号解読(decode)としてとらえる ▪ 与えられた原言語の文jに対して、目的言語の様々な文 eの中から、jがeに翻訳される確率P(e|j)が最大になる をその翻訳と考える
= arg max (|) = arg max () () = arg max (|)()
統計的機械翻訳 ▪ ある確率P(e)で目的言語の文eが生成され,それが P(j|e)の影響を受け、我々が観測できるのはjであると解 釈できる → 雑音のある通信路モデル = arg max
(|) = arg max () () = arg max (|)()
統計的機械翻訳 ▪ P(e) : 言語モデル ▪ 目的言語の文eのもっともらしさを計算するモデル ▪ P(j|e) :
翻訳モデル ▪ 目的言語文eが原言語文jに翻訳される確率 ▪ P(j|e)のモデル化の方法が問題となる = arg max (|) = arg max () () = arg max (|)()
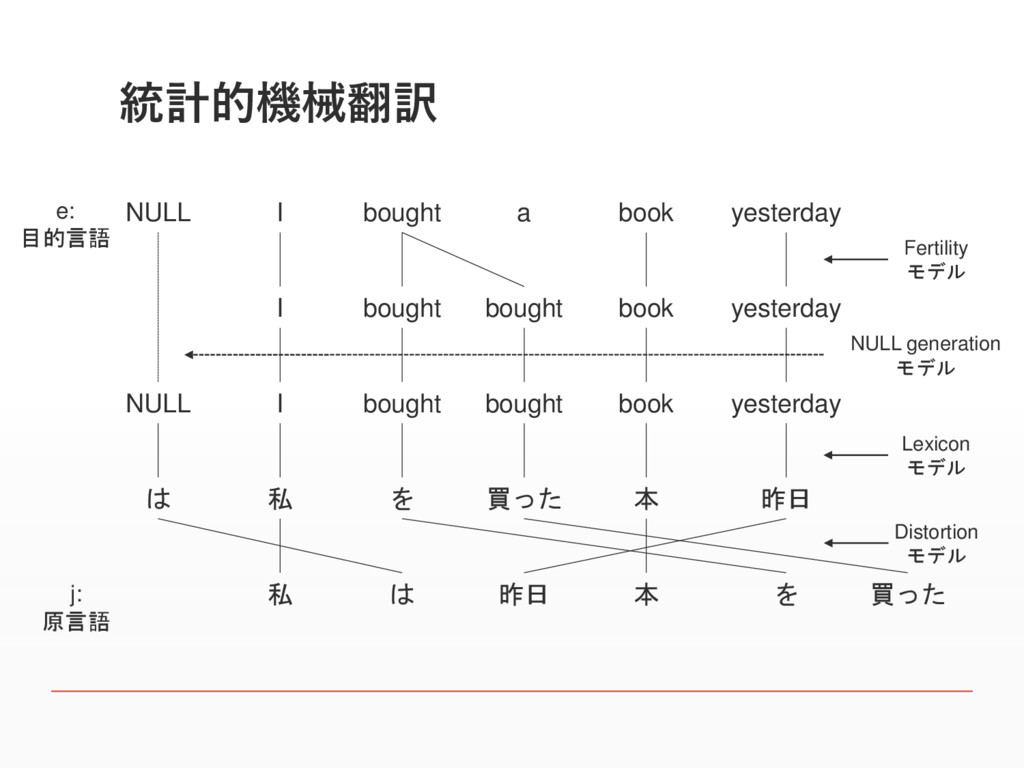
統計的機械翻訳 NULL I bought a book yesterday I bought bought
book yesterday NULL I bought bought book yesterday は 私 を 買った 本 昨日 私 は 昨日 本 を 買った Fertility モデル NULL generation モデル Lexicon モデル Distortion モデル e: 目的言語 j: 原言語
統計的機械翻訳 ▪ 目的言語の文を英語文 e={e1,e2,e3,・・・,el} 原言語の文を日本語文 j={j1,j2,j3,・・・,jm} とする ▪ Fertilityモデル ▪
英語の各単語eiがΦi個の日本語単語を生成すると考える ▪ 0個の場合や複数個の場合もある ▪ この確率をPn(ei|Φi)とする ▪ NULL generationモデル ▪ 生成する文章の長さを合わせるためe0=NULLという仮想的な語から Φ0個の日本語単語を生成する。
統計的機械翻訳 ▪ Lexiconモデル ▪ 翻訳は1対1の単語単位で考え、ある単語eiがある日本語単語jkに 翻訳される確率をPt(jk|ei)とする ▪ Distortionモデル ▪ 翻訳における語順の並び替えを実現するモデル
▪ 長さlの英語文のi番目の単語が長さmの日本語文のk番目の単語と なる確率をPd(k|I,l,m)で表す
統計的機械翻訳 ▪ 単語アライメント ▪ 翻訳生成過程の単語の対応付け NULL I bought a book
yesterday 私 は 昨日 本 を 買った e: 目的言語 a: アライメント j1 j2 j3 j4 j5 j6 j: 原言語 1, 0, 5, 4, 2, 2 ( )
統計的機械翻訳 ▪ 単語アライメントが大量にあれば、モデルのパラメータは最 尤推定で簡単に計算可能 ▪ 対訳コーパス中にbookが100回出現し,そのうち70回が本にアライメ ントされていればLexiconのモデルのPt(本|book)は0.7 ▪ 統計翻訳では100万文規模の対訳分が必要 ▪
人手での単語アライメントの付与は非現実的 ▪ 対訳コーパスを用いて単語アライメントとパラメータ推定を同時に行う ▪ 対訳コーパスの尤度を最大化することを目標にパラメータを自動調整 → EMアルゴリズム
参考文献 ▪ 黒橋 禎夫, 自然言語処理, 放送大学教育振興会 (2015.3.20) pp.167-174
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}