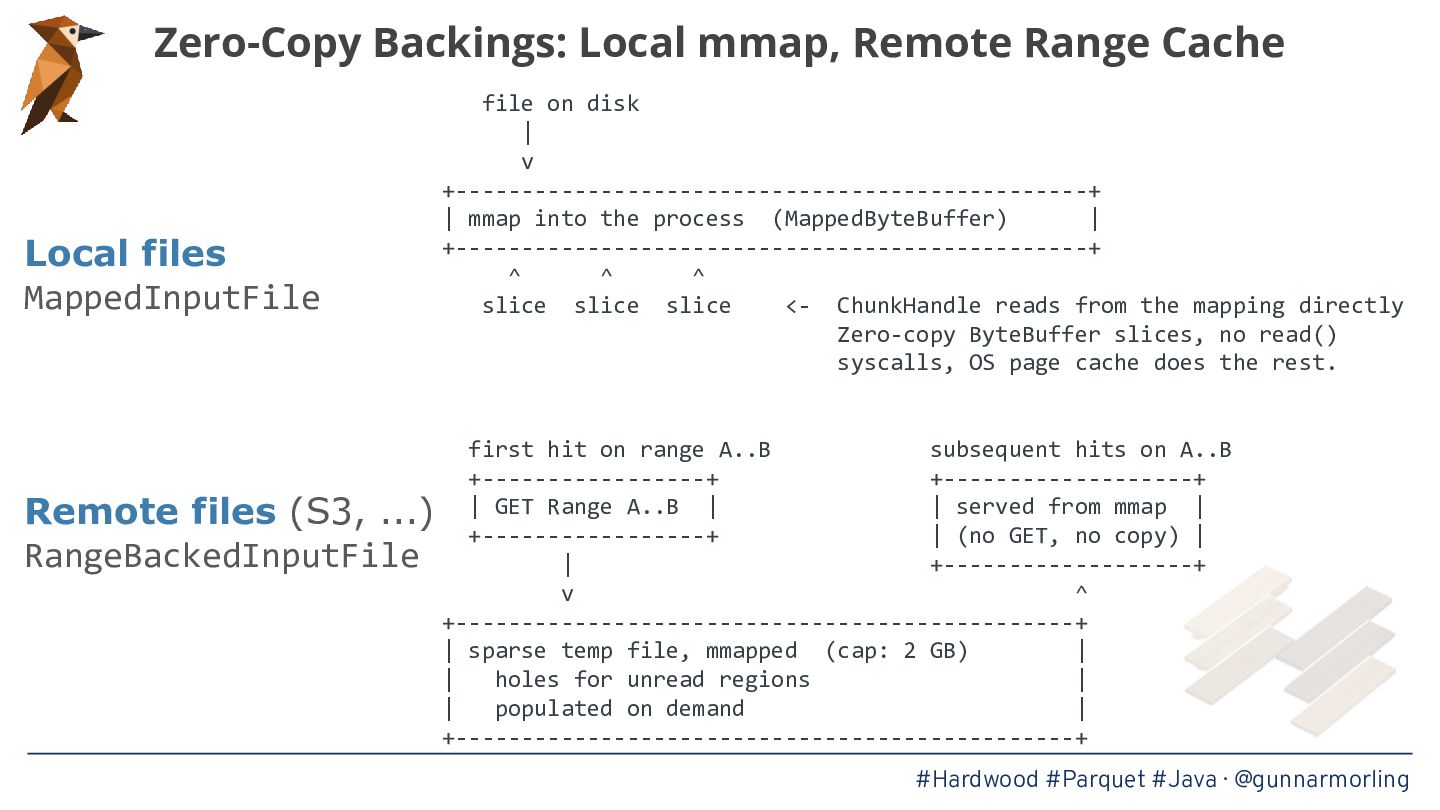
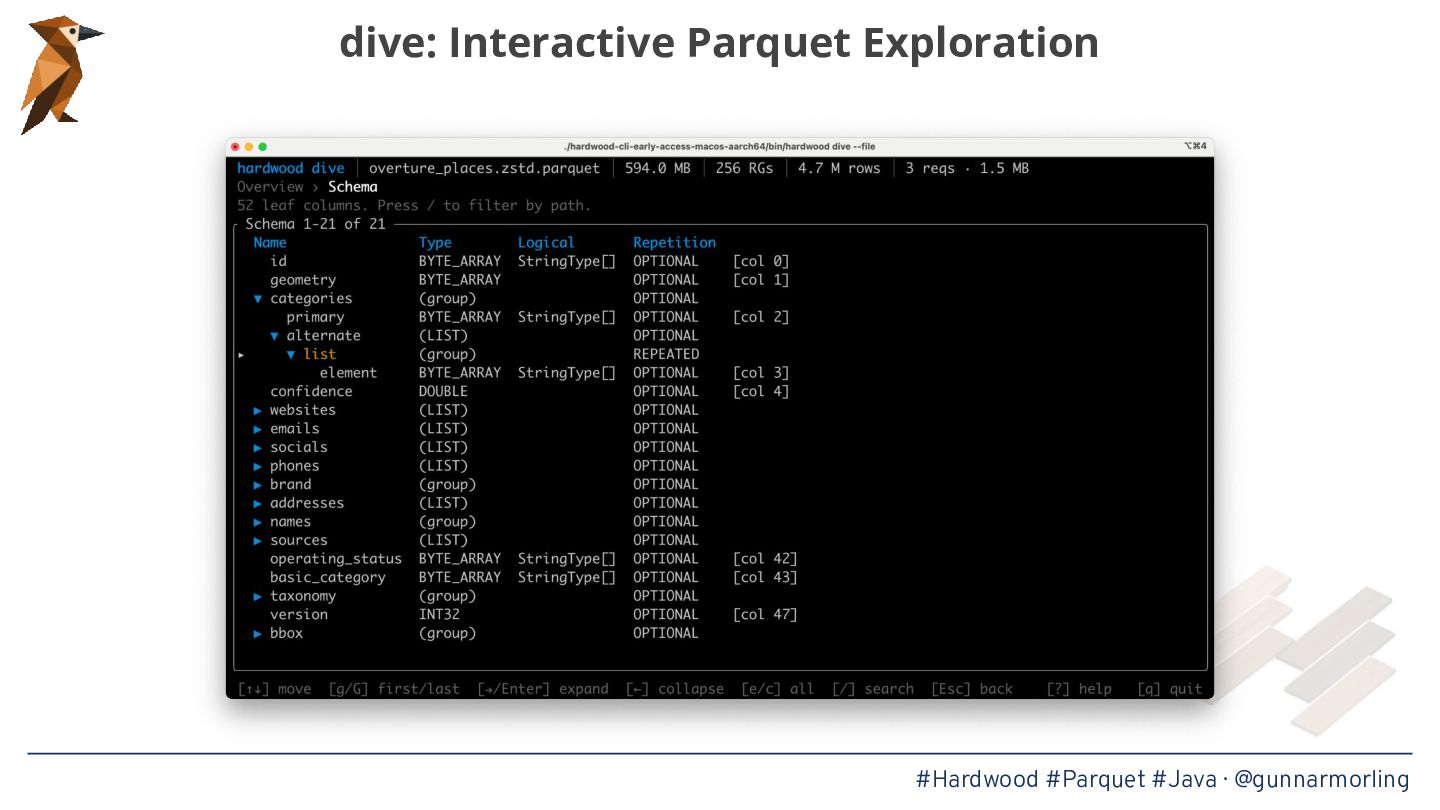
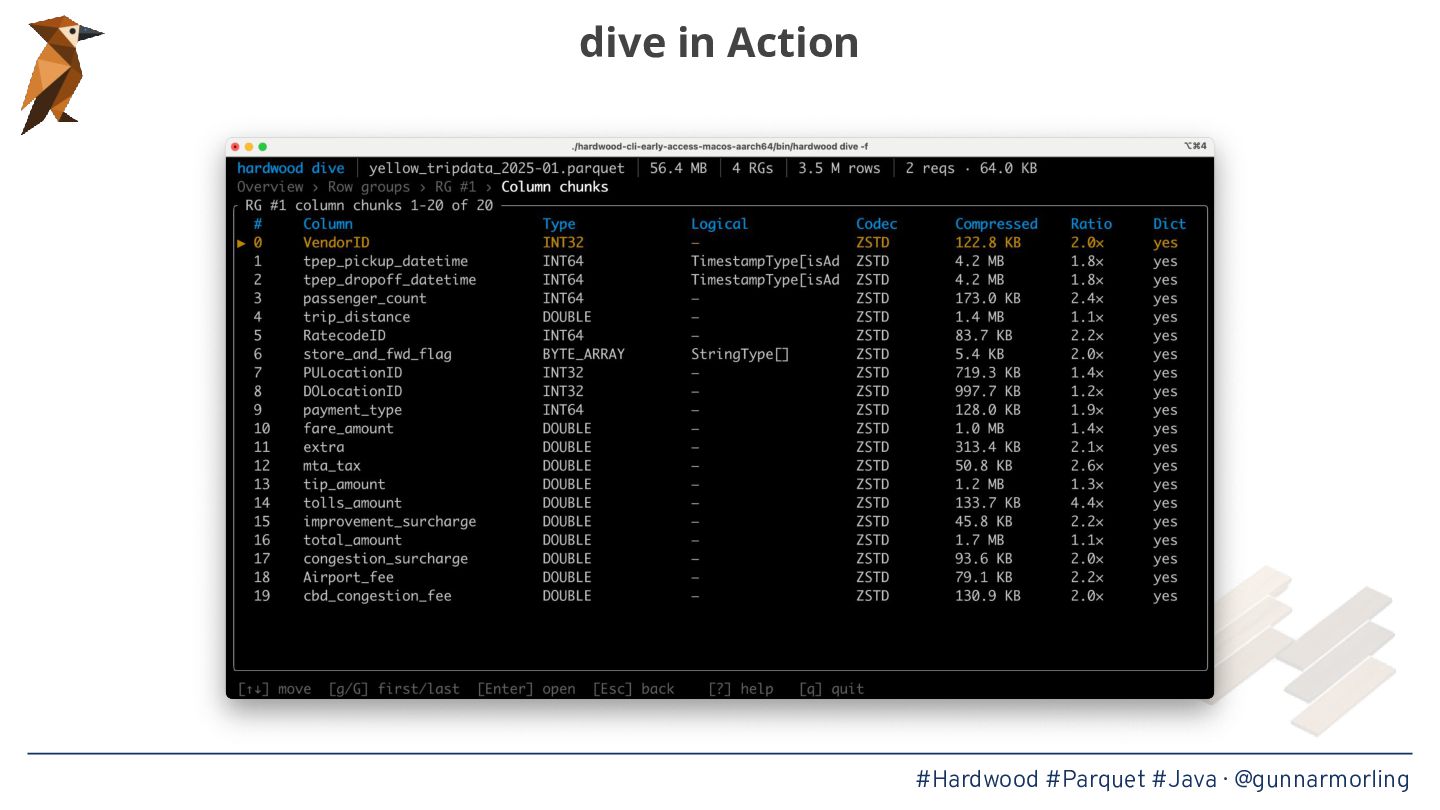
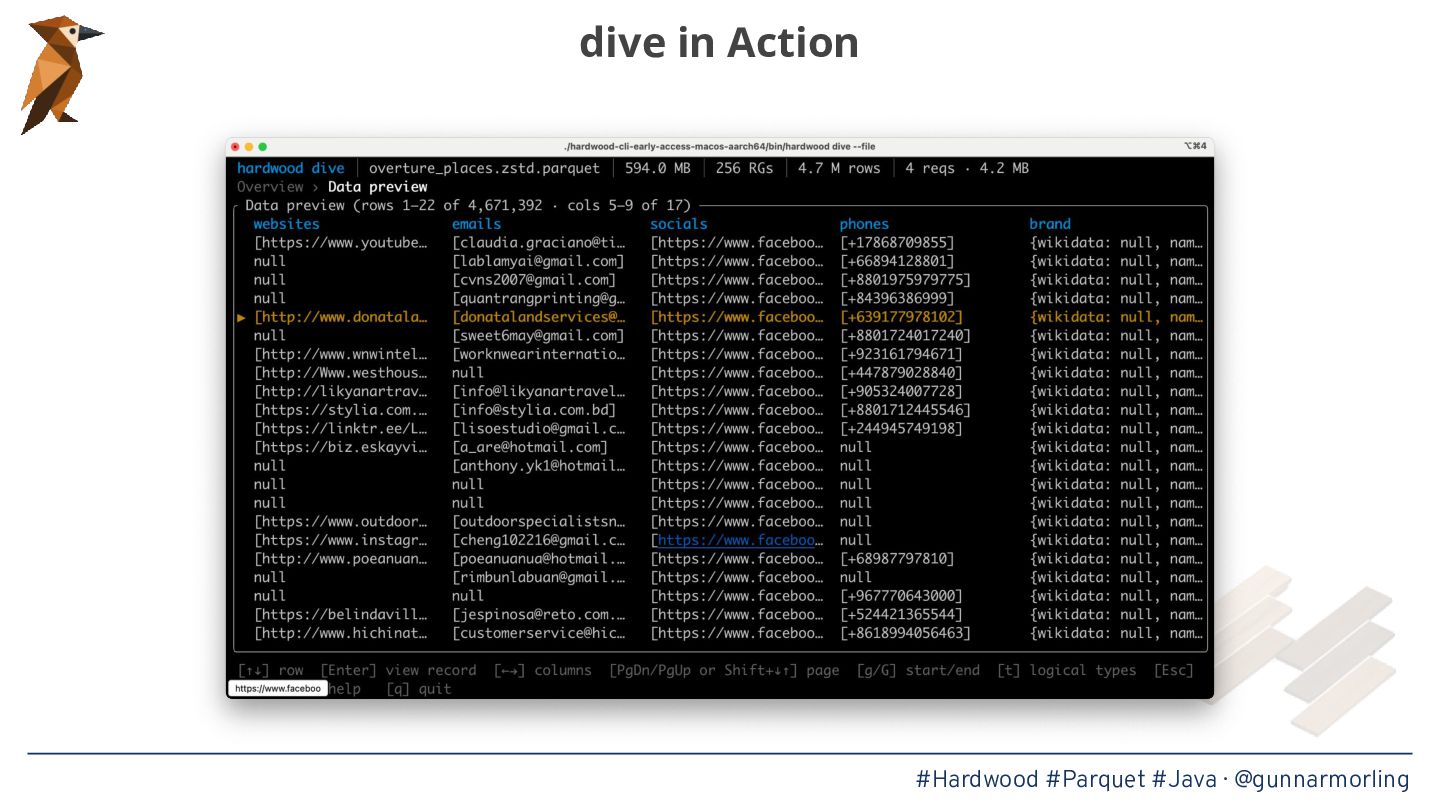
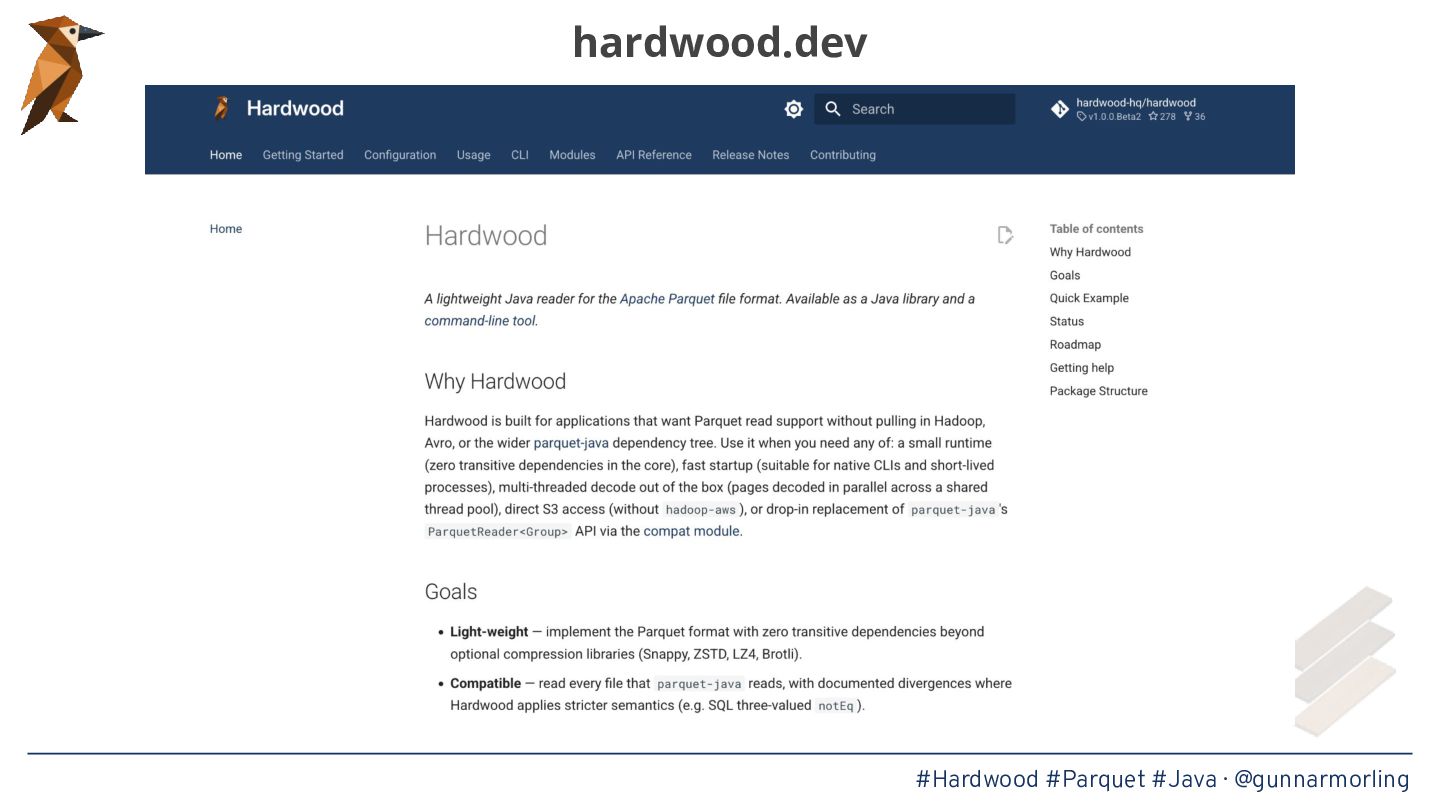
Apache Parquet has become the lingua franca of the modern data ecosystem, powering data lakes and table formats like Apache Iceberg—but for Java, the go-to library parquet-java pulls in Hadoop and a truckload of other dependencies, and its reader is single-threaded. This was bugging me enough to start Hardwood, a brand-new Parquet parser written from scratch in modern Java, applying some of the performance lessons learned from the One Billion Row Challenge.
Come and join me for this session, where we'll look at:
* The internals of the Parquet format and what makes parallelizing its decoding surprisingly tricky
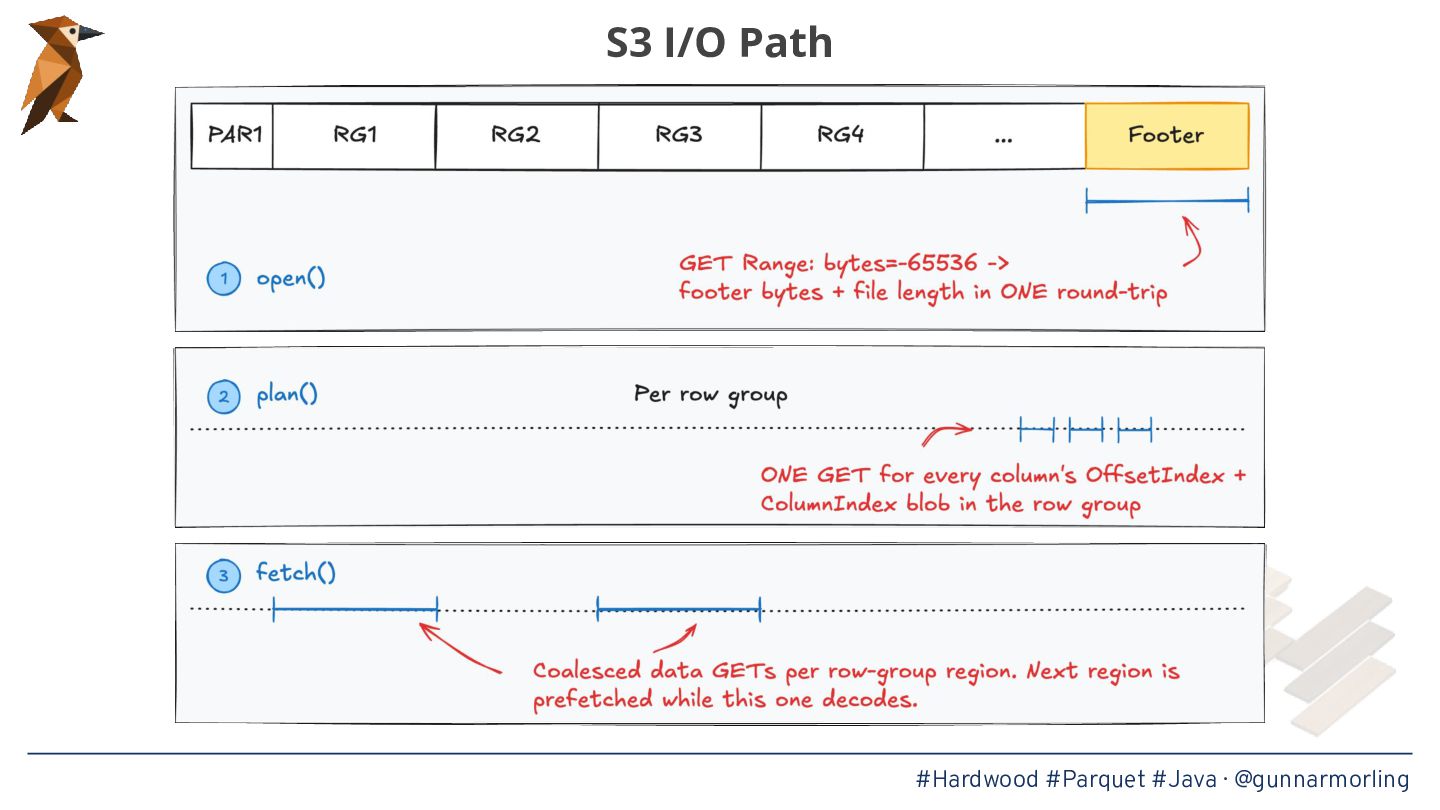
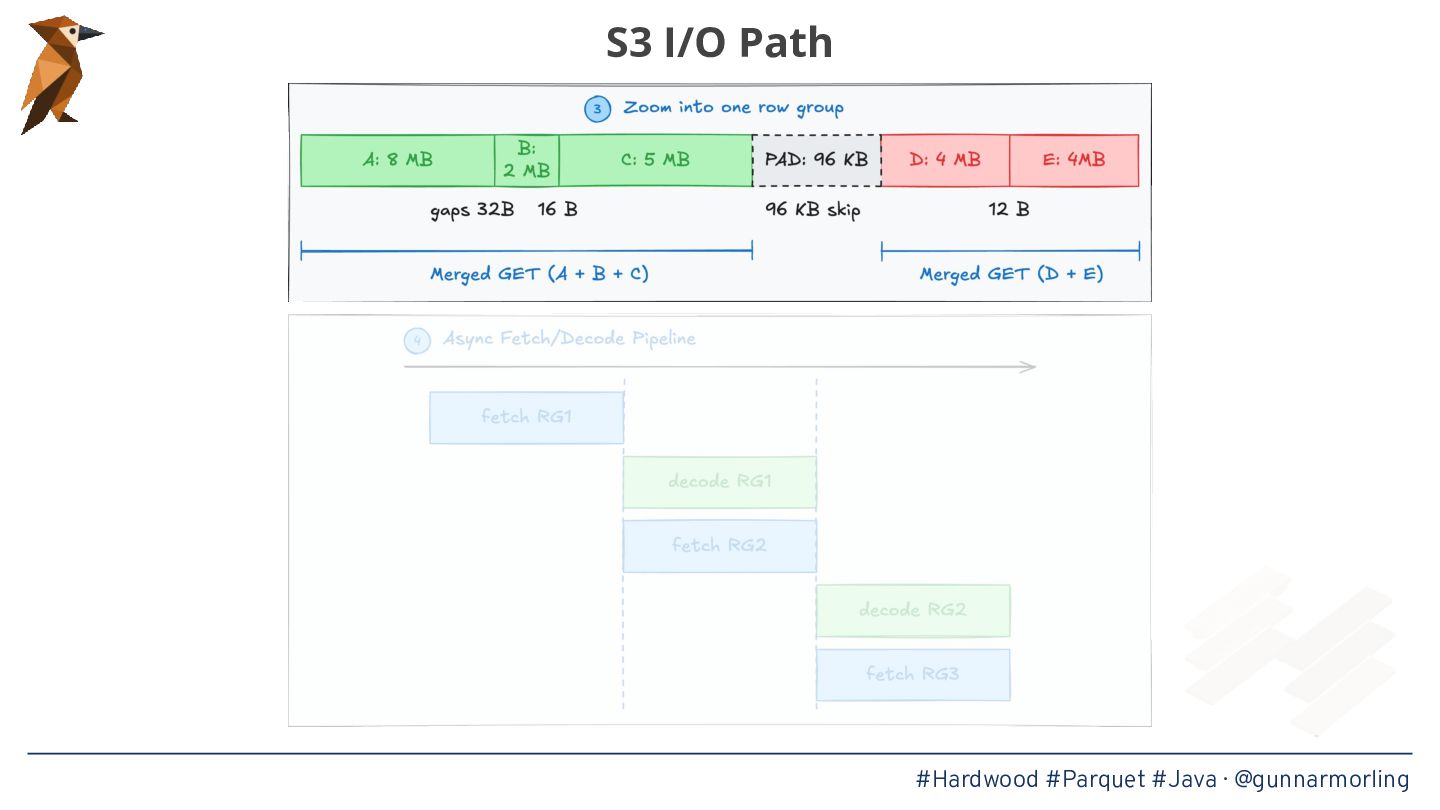
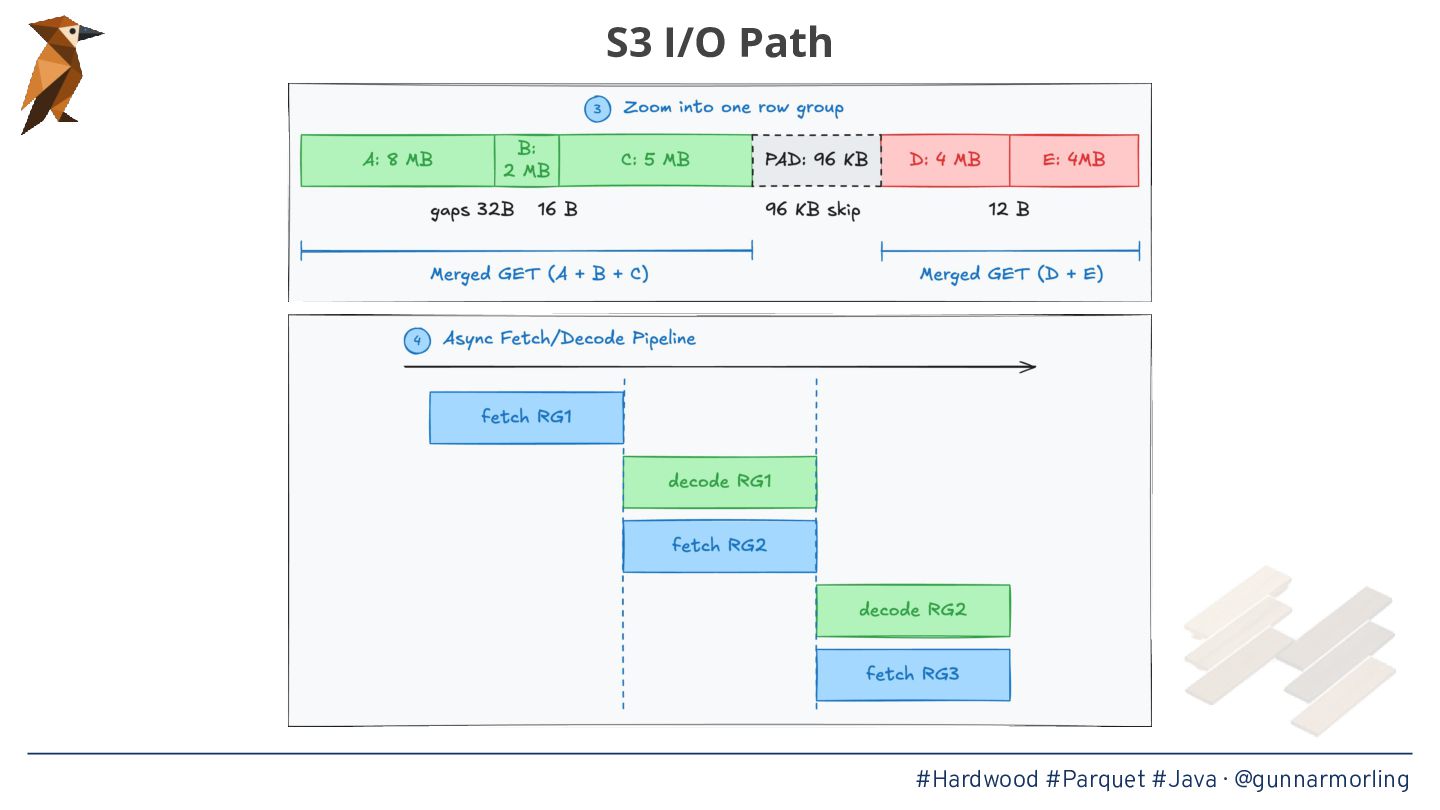
* Techniques for achieving high throughput, such as page-level parallelism, adaptive prefetching, and avoiding auto-boxing in hot loops
* How to use JDK Flight Recorder for identifying performance bottlenecks
* Practical learnings from using AI (specifically, Claude Code) as a coding companion—what works well, where you need to stay sharp, and why "built with AI" doesn't mean "vibe-coded"
Whether you're interested in file formats, Java performance, or getting a realistic take on AI-assisted development, there should be something in here for you.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}