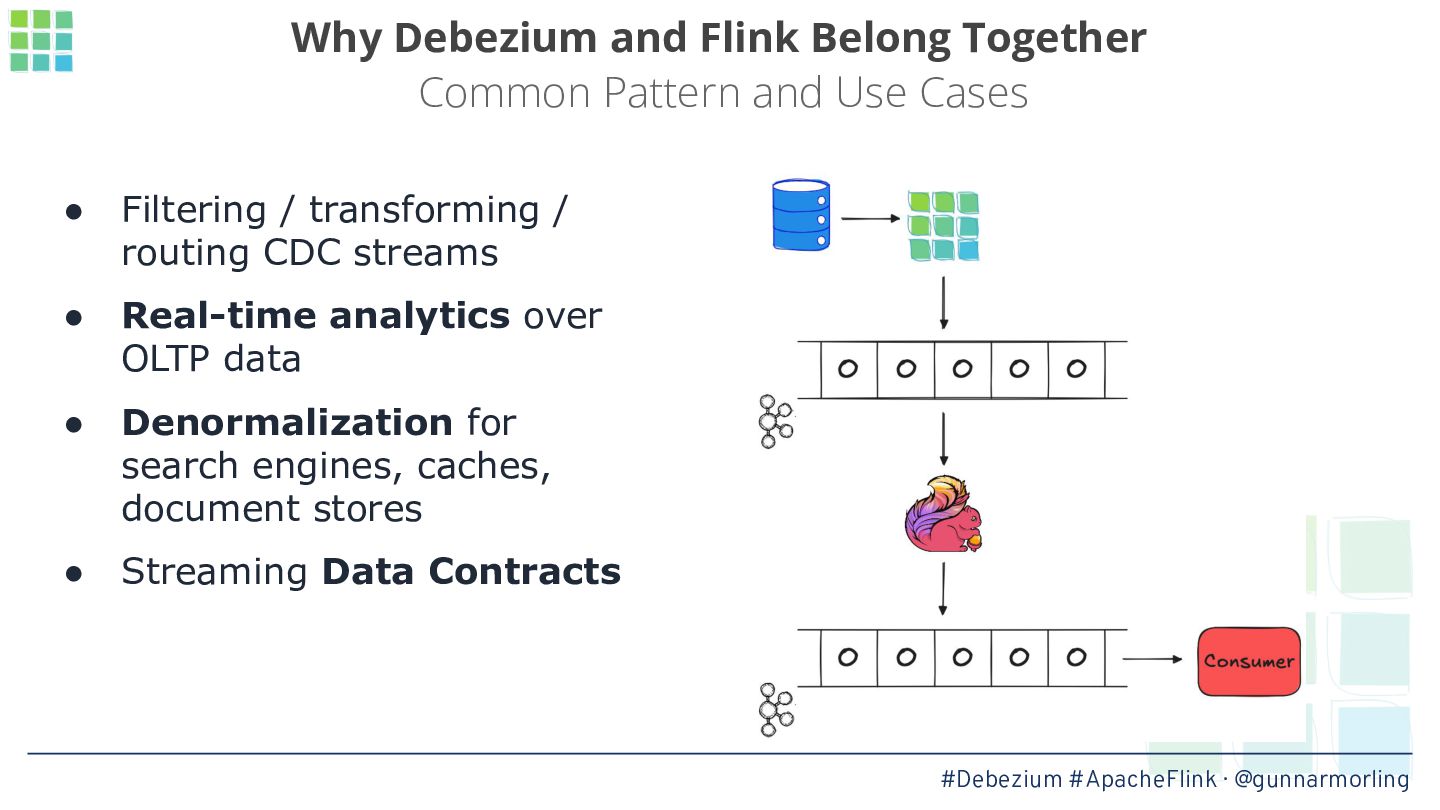
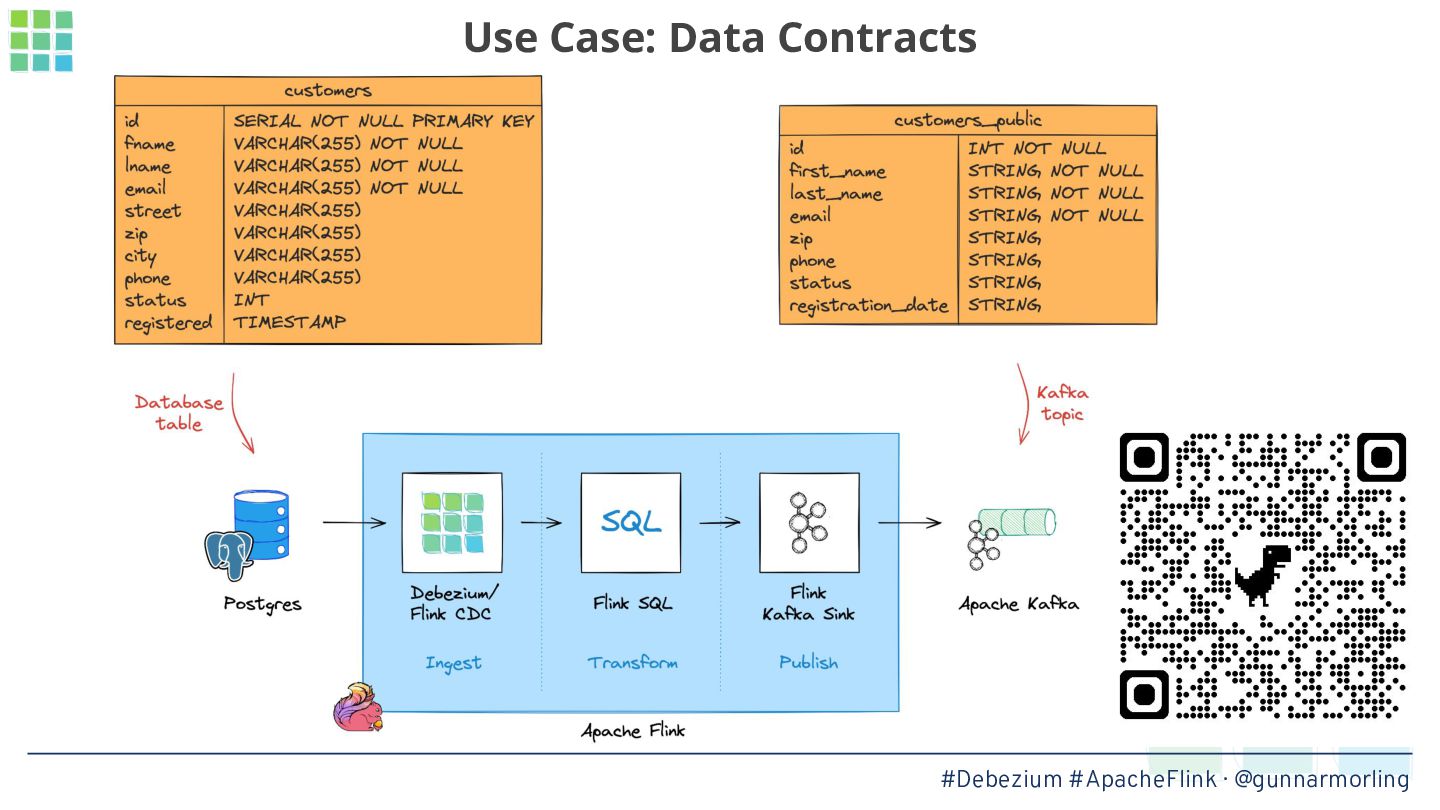
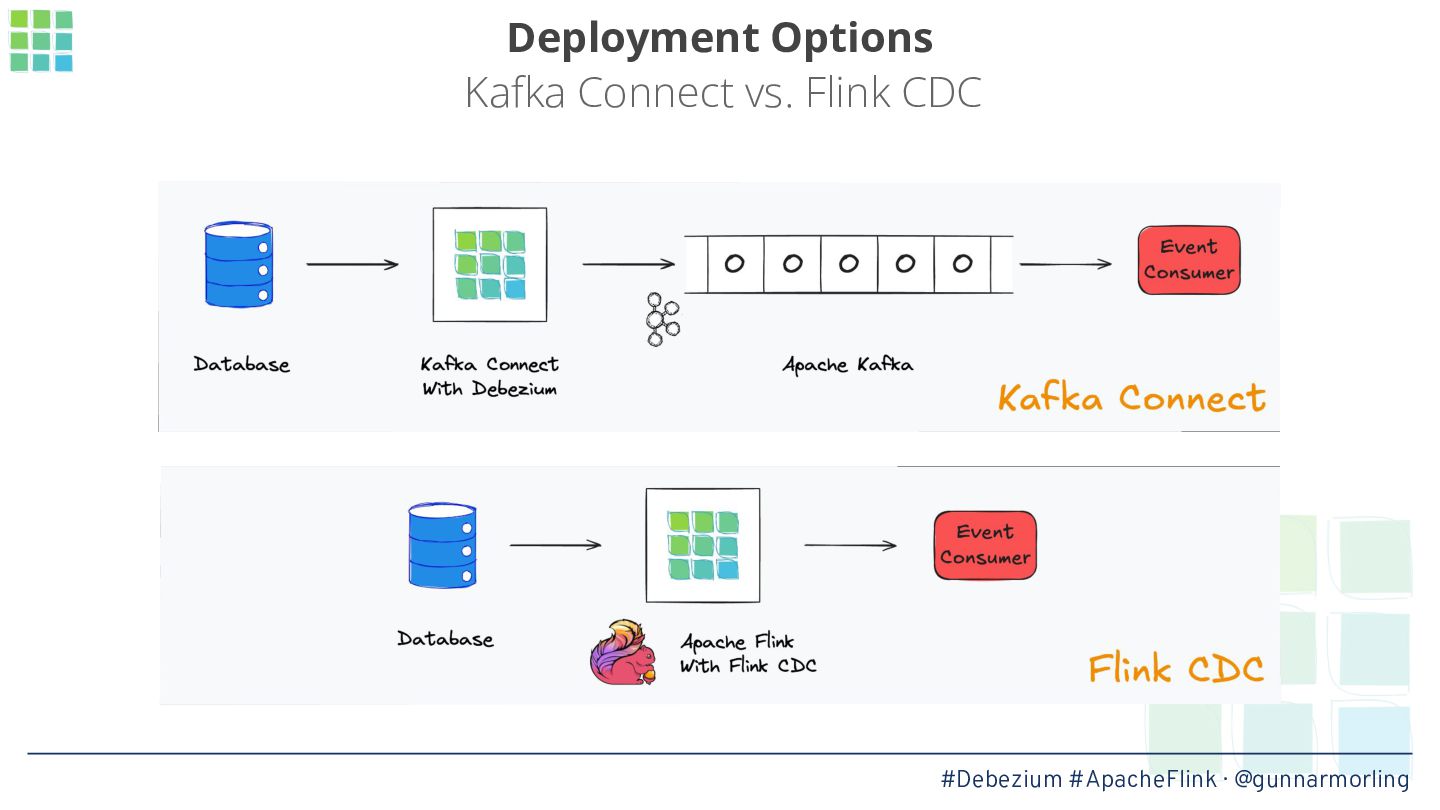
Apache Flink is commonly used for processing Debezium change data events: for running continuous queries enabling real-time analytics as the data in your OLTP store changes, for filtering and transforming change data feeds, or for creating denormalized data views sourced from the change data events of multiple tables.
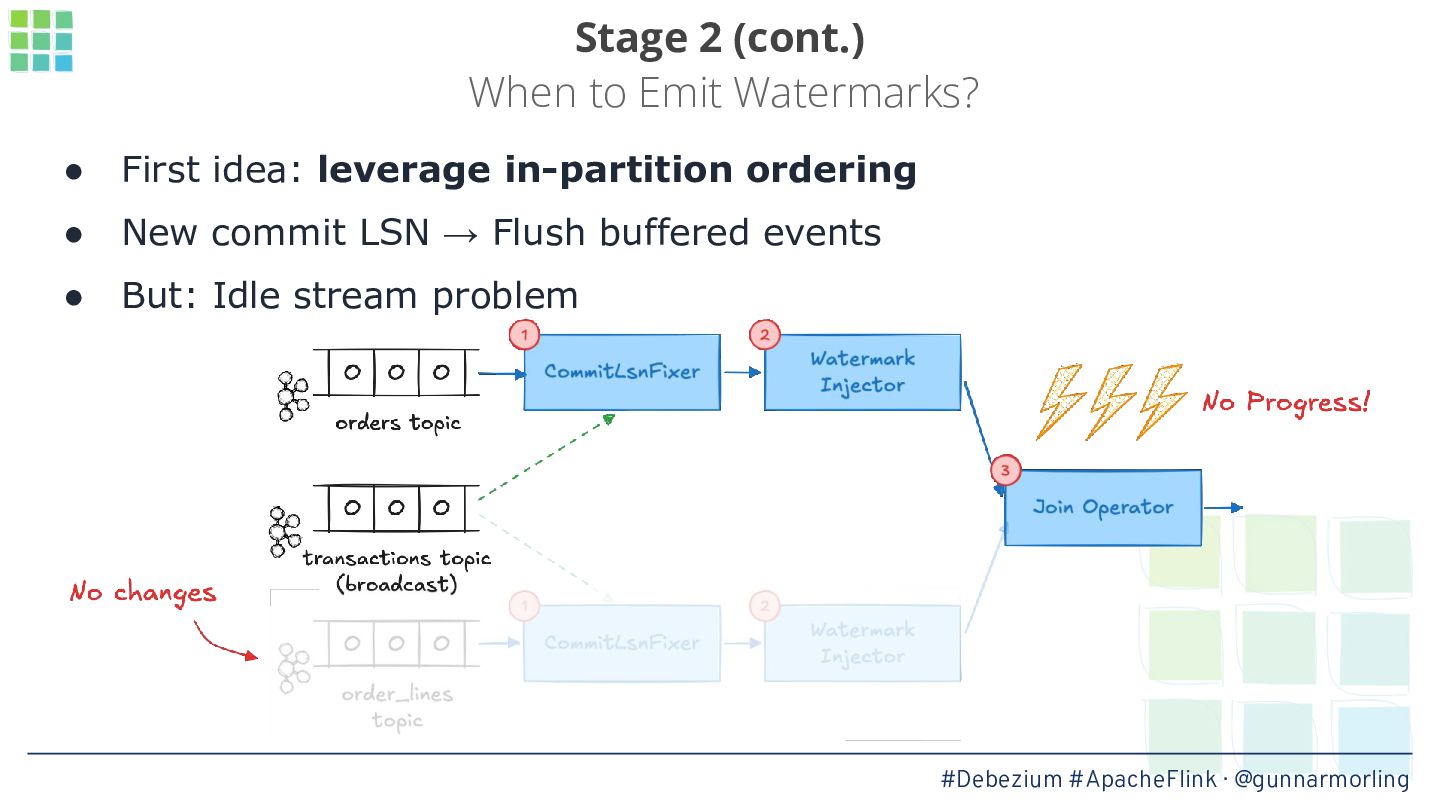
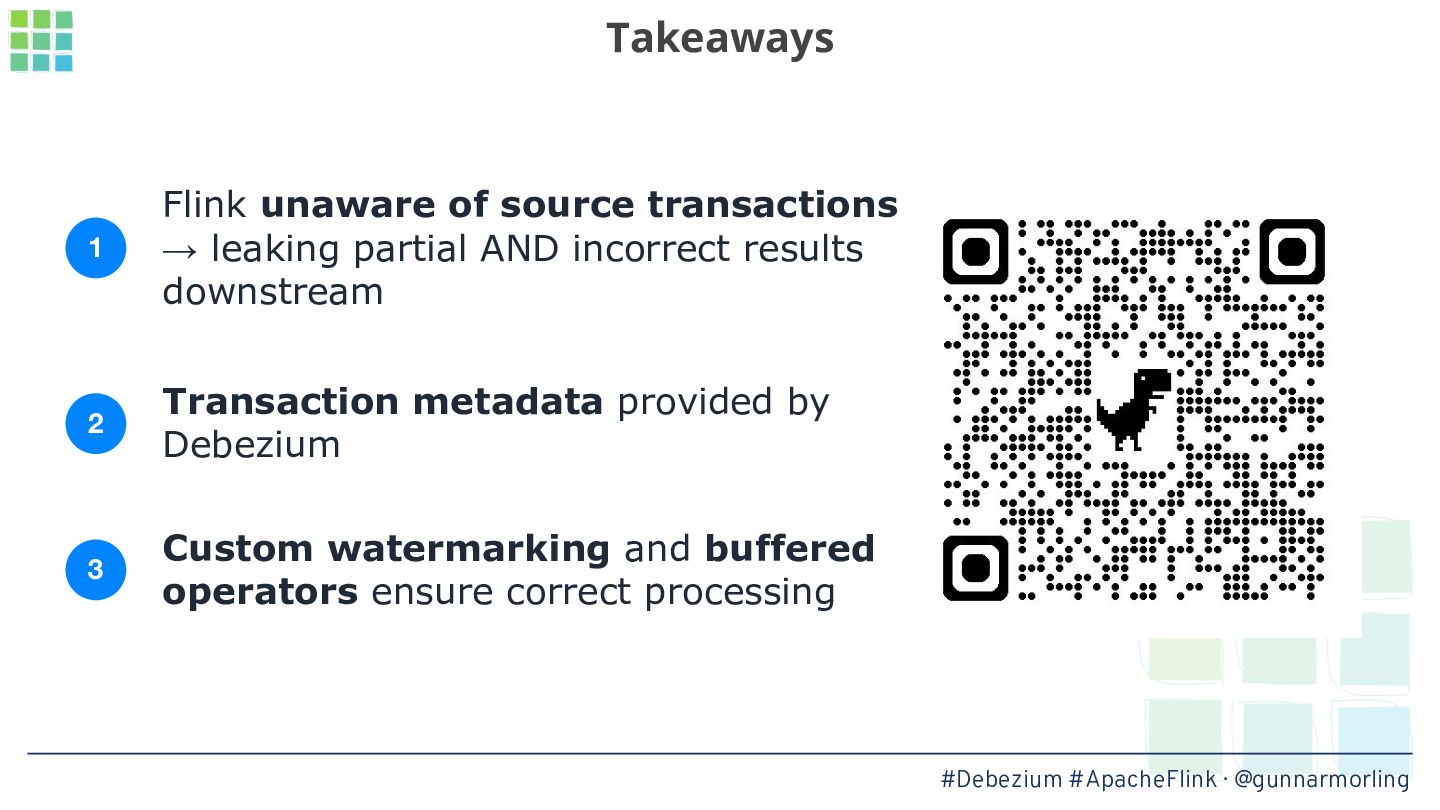
While powerful, this processing happens message by message, resulting in the emission of partial results to downstream consumers while the change events originating from a single transaction in the source database are processed. Oftentimes, that’s not desired: instead, results should only be emitted once all the events from a transaction have been received.
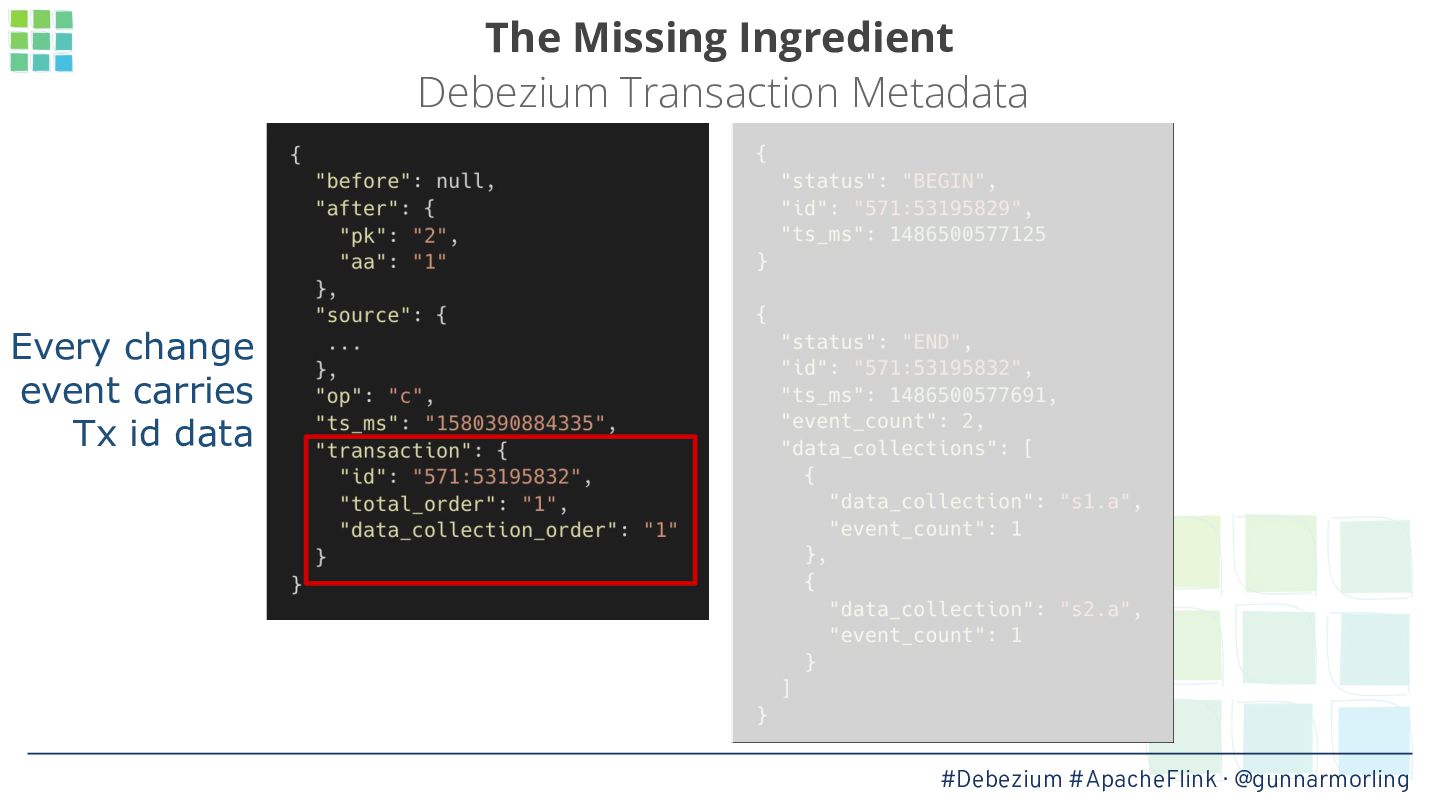
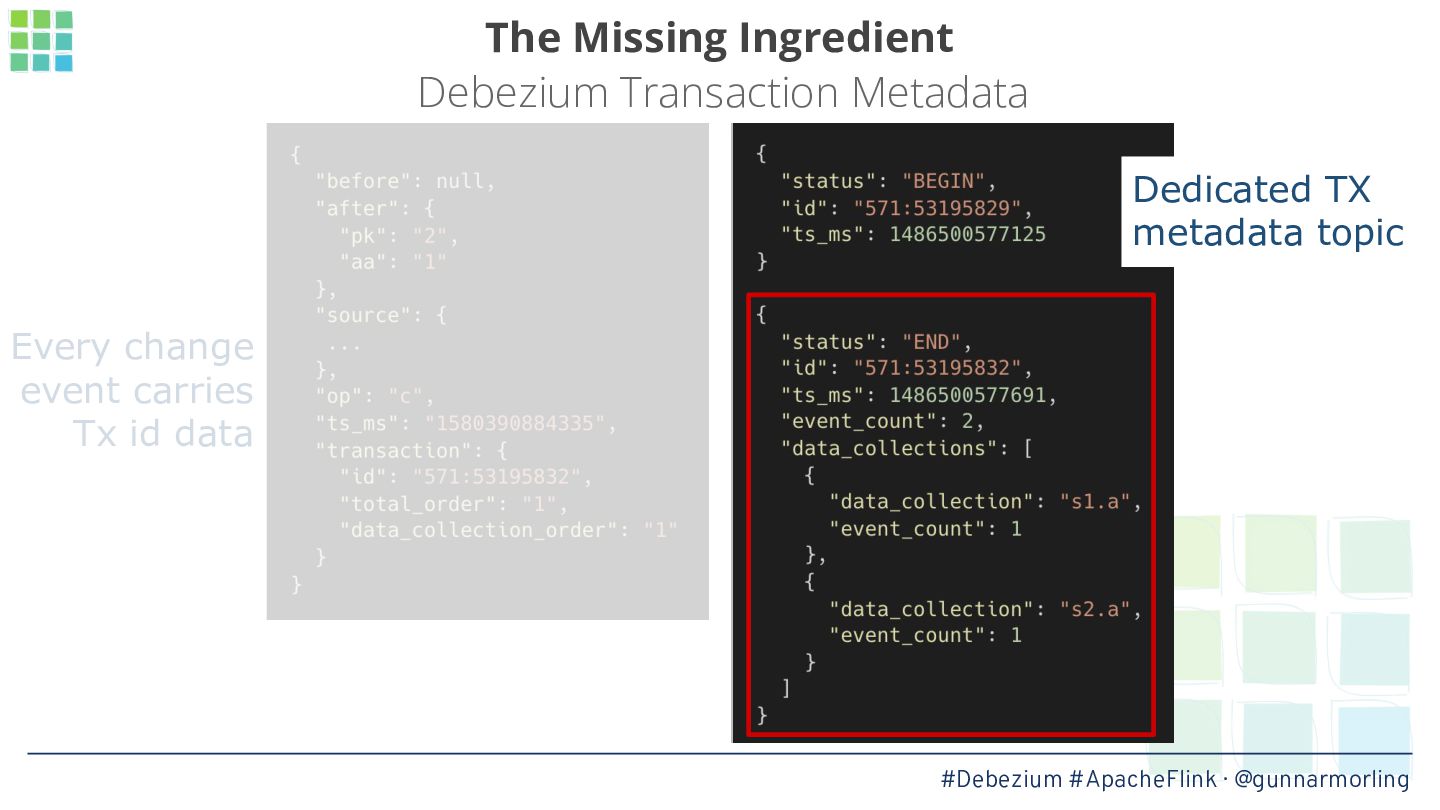
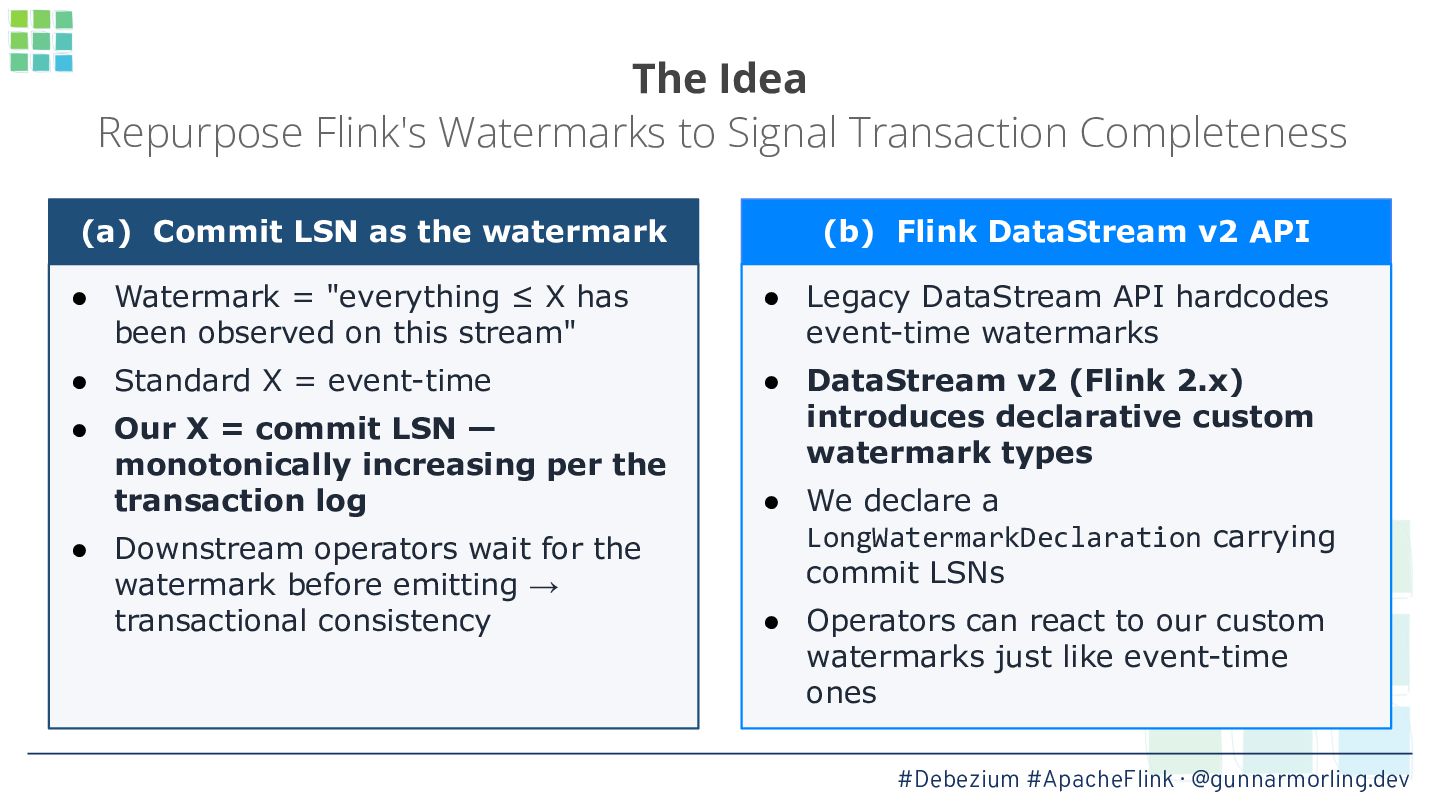
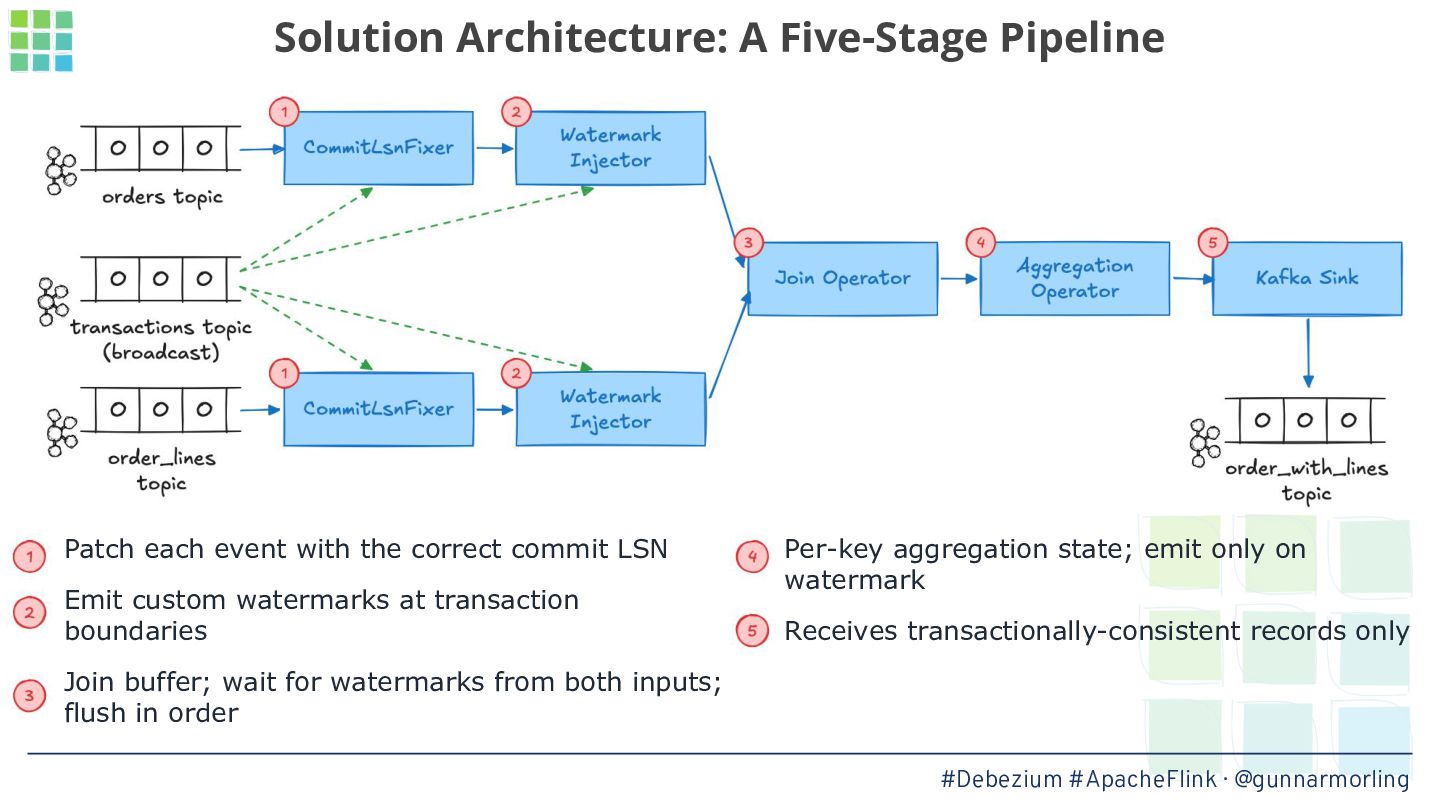
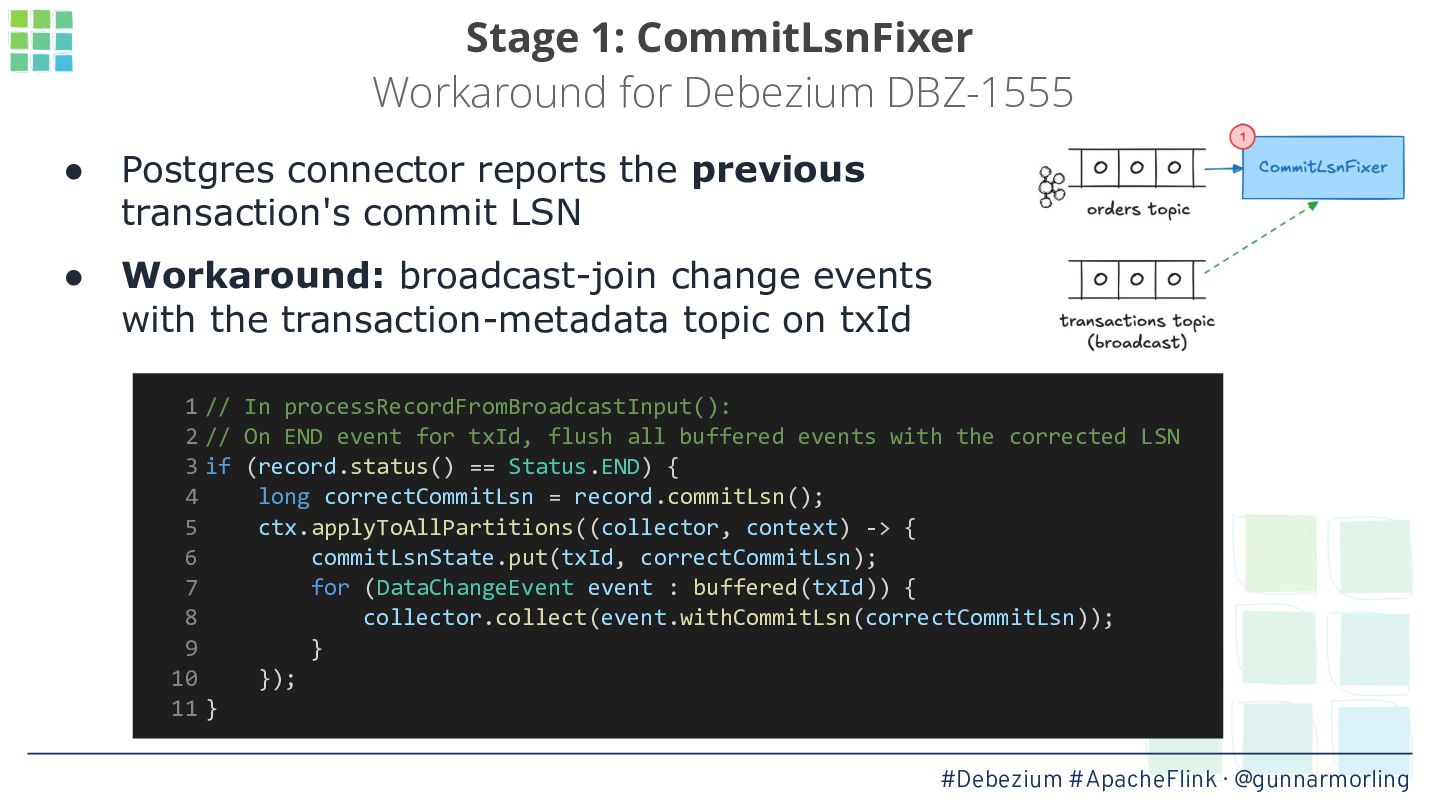
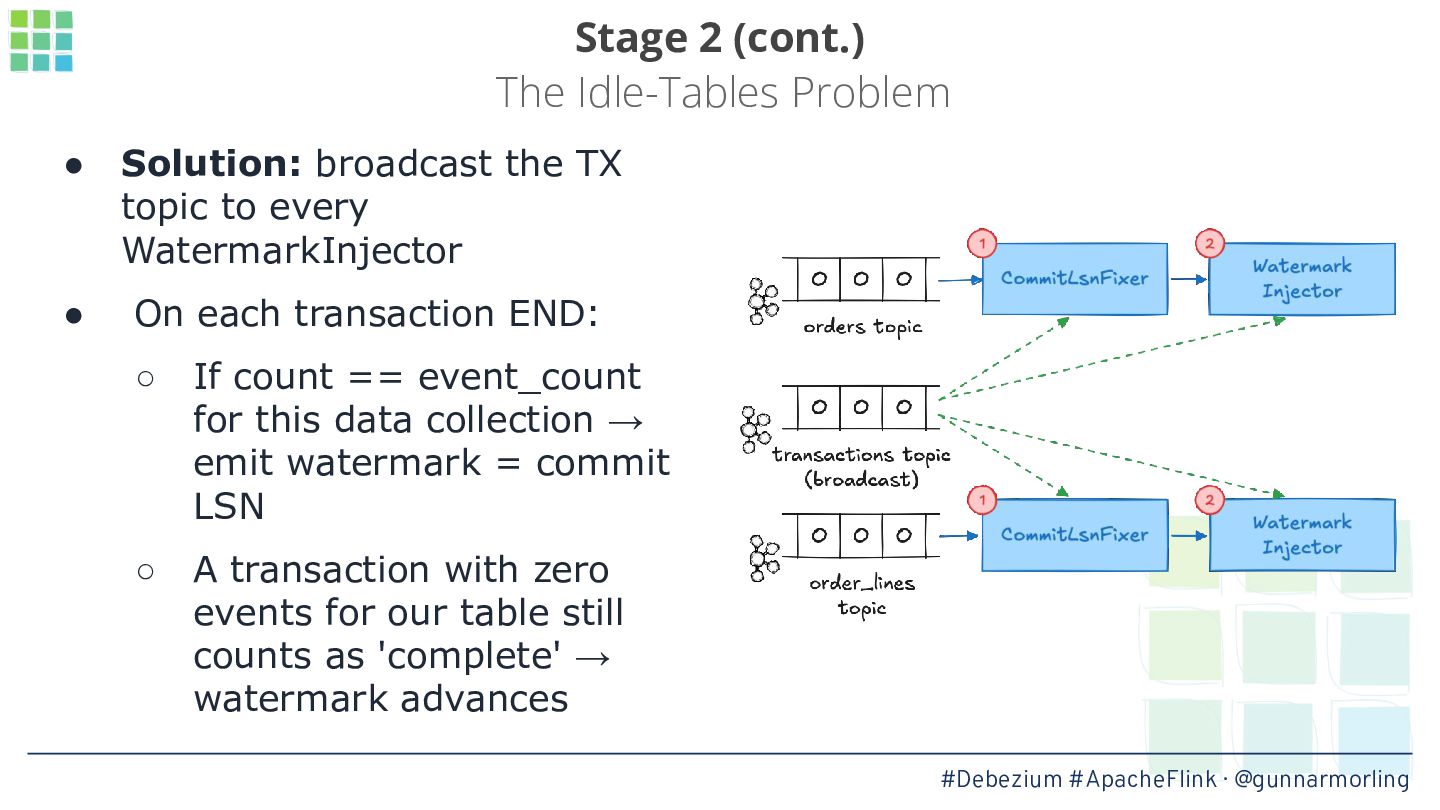
In this talk, we’ll explore how this problem can be solved by leveraging Debezium’s transaction metadata. It describes how many events of which type belong to a given transaction in a database like Postgres or MySQL. We’ll show how to take advantage of this information for implementing an innovative watermarking approach which, together with a custom output buffer, ensures that event consumers will only ever receive transactionally consistent data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}