Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「変化していくユーザを検知し改善を行う分析基盤の話」@「Gunosyの急成長を支えた技術チーム...
Search
Gunosy
September 26, 2014
Technology
4.5k
3
Share
「変化していくユーザを検知し改善を行う分析基盤の話」@「Gunosyの急成長を支えた技術チームの取り組み実例を大公開!」
「【人気のため増席しました!】Gunosyの急成長を支えた技術チームの取り組み実例を大公開!」での発表資料
http://eventdots.jp/event/160791
Gunosy
September 26, 2014
Other Decks in Technology
See All in Technology
Mastering Ruby Box
tagomoris
3
150
新アーキテクチャ「TiDB X」解説とDedicated比較 TiDB Cloud Premiumのゲーム運用活用を検証
staffrecruiter
0
110
noUncheckedIndexedAccess、3時間、1万円。 / noUncheckedIndexedAccess, 3 Hours, 10,000 JPY.
kaonavi
1
270
Unlocking the Apps
pimterry
0
210
[モダンアプリ勉強会]今更聞けないGit/GitHub入門
tsukuboshi
0
240
さきさん文庫の書籍ができるまで
sakiengineer
0
350
React、まだ楽しくて草
uhyo
7
4k
プラットフォームエンジニア ワークショップ/ platform-workshop
databricksjapan
1
260
チームで実践する AI-DLC 思考の軌跡を残すチェックポイント設計
belongadmin
0
2.5k
探して_入れて_作って_使う_Agent_Skills___LT.pdf
peintangos
2
160
新規事業を牽引する技術選定 〜フルスタックTypeScript開発の実践事例〜
nullnull
2
310
BigQuery の Cross-cloud Lakehouse への歩み
phaya72
2
550
Featured
See All Featured
Navigating Weather and Climate Data
rabernat
0
210
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
5.9k
A Soul's Torment
seathinner
6
2.9k
Balancing Empowerment & Direction
lara
6
1.1k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
250
Writing Fast Ruby
sferik
630
63k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
360
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.5k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
150
Scaling GitHub
holman
464
140k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
65
55k
Transcript
変化していくユーザを検知し 改善を行う分析基盤の話 GUNOSY INC. 吉田 宏司
自己紹介 吉田 宏司(よしだ こうじ) • 開発本部 DAUチーム エンジニア • 業務
データ分析、KPI管理 記事評価・配信ロジック、推薦システム、クローラ APIサーバ、Webサーバ その他雑用
DAUチームとは DAUチームとは • 「数字は神より正しい」を支える、KPI算出、分析、改善策立案、実 装を行うチーム • 業務 • 分析基盤つくり •
記事評価ロジック、推薦システム、記事収集 • KPI算出、データ分析、改善策立案 • 4~5人
今日のお話 1. グノシーの分析基盤、インフラの歴史 2. グノシーでの分析と改善の流れ 3. グノシーでの分析と改善事例
今日のお話 1. グノシーの分析基盤、インフラの歴史 2. グノシーでの分析と改善の流れ 3. グノシーでの分析と改善事例
グノシーの分析基盤、インフラの歴史 KPI算出とアドホックな分析を行う • 定常的な夜間KPI算出 • 朝起きると集計が終わってて欲しい • 非定常的に発生するアドホックな分析 • 古いデータもいつでもすぐに触りたい
サービスの成長に伴い、大きく3回リニューアルしてきた 1. 創業当初 • MySQL 2. アプリリリース直前 • fluentd + mongoDB + S3 3. データ多すぎ対策後 • 2 + Redshift 4. ネクストフェーズ… • リアルタイム、Amazon Kinesis、、、
創業当初の分析基盤 1. 創業当初 • 状況 • ユーザ数1万人程度 • iOS/Androidアプリリリース前のWebとメールのみの時代 •
同時アクセス数は少ない。何とかKPI算出できるもの。 • やってたこと • MySQLのloginsテーブルに、アクセス時に同期処理でインサート • 必要なKPIを夜間バッチでPythonで算出 • KPIツールはRailsで構築
アプリリリース直前の分析基盤 2. アプリリリース直前 • 状況 • ユーザ数、数万~数十万程度 • iOS/Androidアプリユーザがほとんど •
毎日定刻に大量のアクセスがくる。アクセスの度にMySQLにイン サートするのやばい。 • やってたこと • MySQLを用いたKPI算出の排除 • fluentd + MongoDB + S3導入 • KPI集計は毎日1回の夜間バッチJavaScript+ Python。 MongoDBのmap reduce多用していた。
データ多すぎ対策後の分析基盤 3.データ多すぎ対策後の分析基盤 • 状況 • ユーザ数、数十万~数百万 • Mongoのmap reduce遅すぎ。朝になっても終わらないKPI集計。 •
あふれだすデータ • いつからかWAUの伸びが鈍化し始める… • Mongo見てみると、消えていっていた(capped collection) • あふれたデータを使用するのが面倒 • 古いデータを分析する時に、S3に上がったデータを一回落として きて、ゴニョゴニョ。。 • やってたこと • MongoDBからのKPI算出の排除(本当は少し残ってる) • MongoDBは一時データ保管場所として、軽く触りたい時に使用 • KPI集計、過去データを用いた分析はRedshiftを用いて行う
ネクストフェーズの分析基盤 4. ネクストフェーズ • 状況 • ユーザ数、数千万~ • やろうとしていること •
リアルタイムに数値算出 • 「ログをAPIで受けるのはもうやめる。アプリ to Amazon Kinesis だ」
今日のお話 1. グノシーの分析基盤、インフラの歴史 2. グノシーでの分析と改善の流れ 3. グノシーでの分析と改善事例
グノシーでの分析と改善タスクの流れ 基本方針 • 「数字は神より正しい」(Gunosy Way) • 分析と改善の目標を数字で明確にする。 • 「迷ったら挑戦しよう」(Gunosy Way)
• 小規模に進めて、数値を見ながら拡大していく。 • 複数の施策を並行しながら、どんどん進め、効果の大きそうなものがあれば全力注入する。 タスクの流れ • 目標設定 • 仮設立案 • 簡易実験 • 自動化 参照 「B to Cサービスの現場から考える機械学習活用 #MLCT by ysekky」 https://speakerdeck.com/ysekky/b-to-csabisufalsexian-chang-karakao-eruji-jie-xue-xi- huo-yong-number-mlct
今日のお話 1. グノシーの分析基盤、インフラの歴史 2. グノシーでの分析と改善の流れ 3. グノシーでの分析と改善事例
グノシーでの分析と改善事例 実際にグノシーで実施した分析と改善事案について 1. 新規ユーザの定着率向上施策 2. DAUの伸びを確認するための数値作成
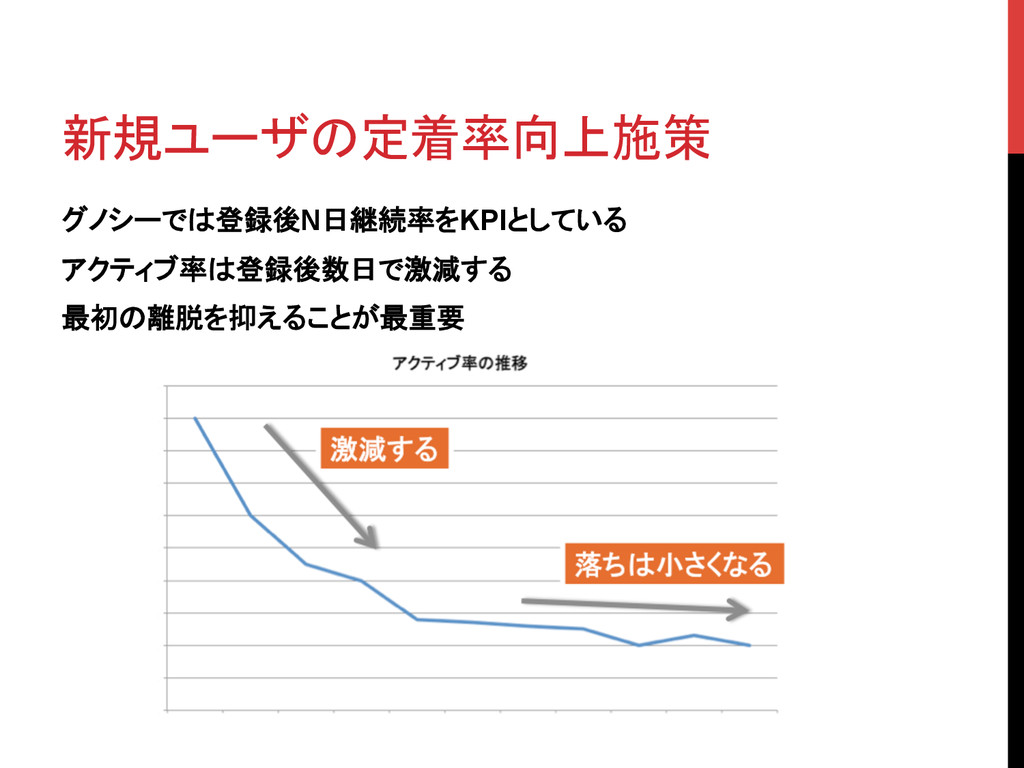
新規ユーザの定着率向上施策 グノシーでは登録後N日継続率をKPIとしている アクティブ率は登録後数日で激減する 最初の離脱を抑えることが最重要
新規ユーザの定着率向上施策 離脱の穴を埋めていく • リリースしたばかりのアプリは、離脱しやすい穴がたくさんある • 新機能開発前に、既存機能の穴を埋めきることが重要 • 昨年1月のアプリリリース後に1個1個見つけて潰していくことに 注力した 以下のスライドで説明する施策例
1. 登録フロー簡略化 2. データの少ないユーザ対策 3. グノシーの苦手分野攻略
登録フロー簡略化 かつて、グノシーは登録が必須のアプリだった(今は登録無しで大丈夫) • しかも、登録にはSNSアカウントとメールアドレスの2つが必要。 • Web + メールのみだった時は、メールによってユーザにグノシー を呼び戻す効果が大きかった •
「グノシーって、メールで来るのがいいよね〜。」
登録フロー簡略化 アプリでも、SNS + メールは必須にした • 「アプリ単体だとユーザ定着しなそう。」 登録ユーザ数 / インストール数 が低いことに気づく
• リリース直後は、Webで使用していたユーザがアプリをダウンロー ドする割合が多かったため、登録ユーザ数 / インストール数が低 いことを問題視していなかった アプリユーザにメールによる呼び戻しは効いていなかった • メールを開封しただけのユーザもDAUに加算していた • アプリで登録したユーザはメールを開封していても記事を閲覧す るユーザは少なかった => メールは開いてもそのまま削除が大半
登録フロー簡略化 メールアドレス無しでも登録可能にした • 登録ユーザ数 / インストール数 は向上 そもそも継続率の定義を誤っていた • 登録ユーザ数を分母にした継続率(アクティブ数
/ 登録ユーザ 数)は低下した • インストール数を分母にした継続率(アクティブ数 / 登録ユーザ 数)は向上した • 実際に伸ばすべきは後者 Web時代と違う登録フローと用意し、インストールしたらすぐニュース が読めるカタチに落ち着く
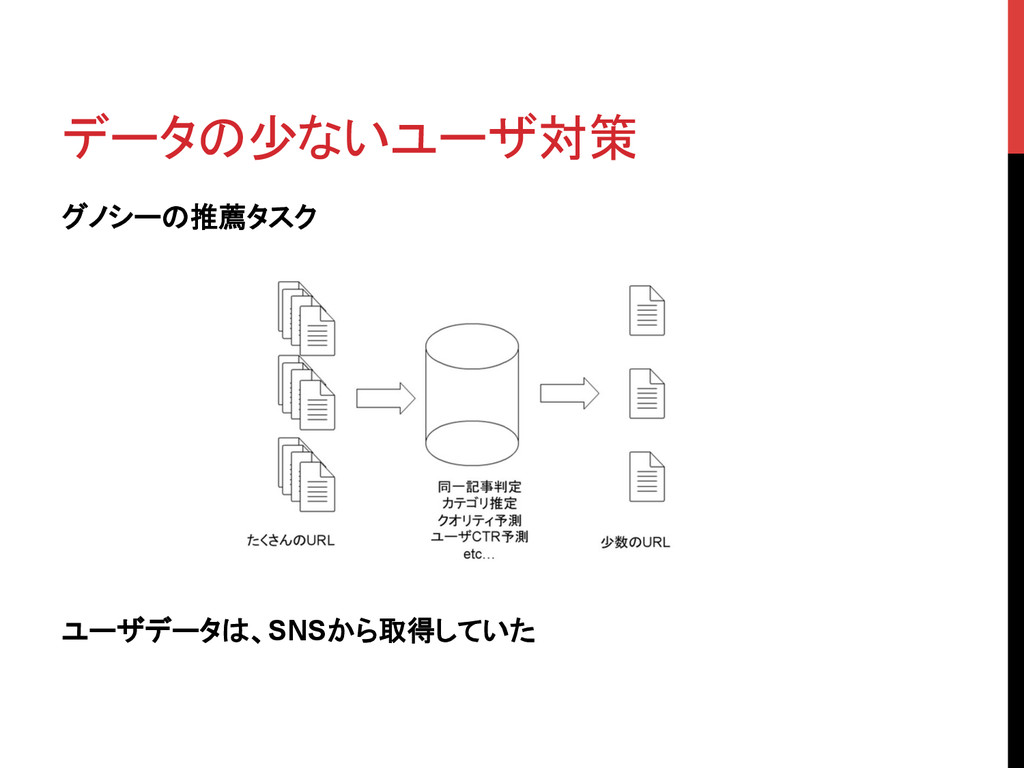
データの少ないユーザ対策 グノシーの推薦タスク ユーザデータは、SNSから取得していた
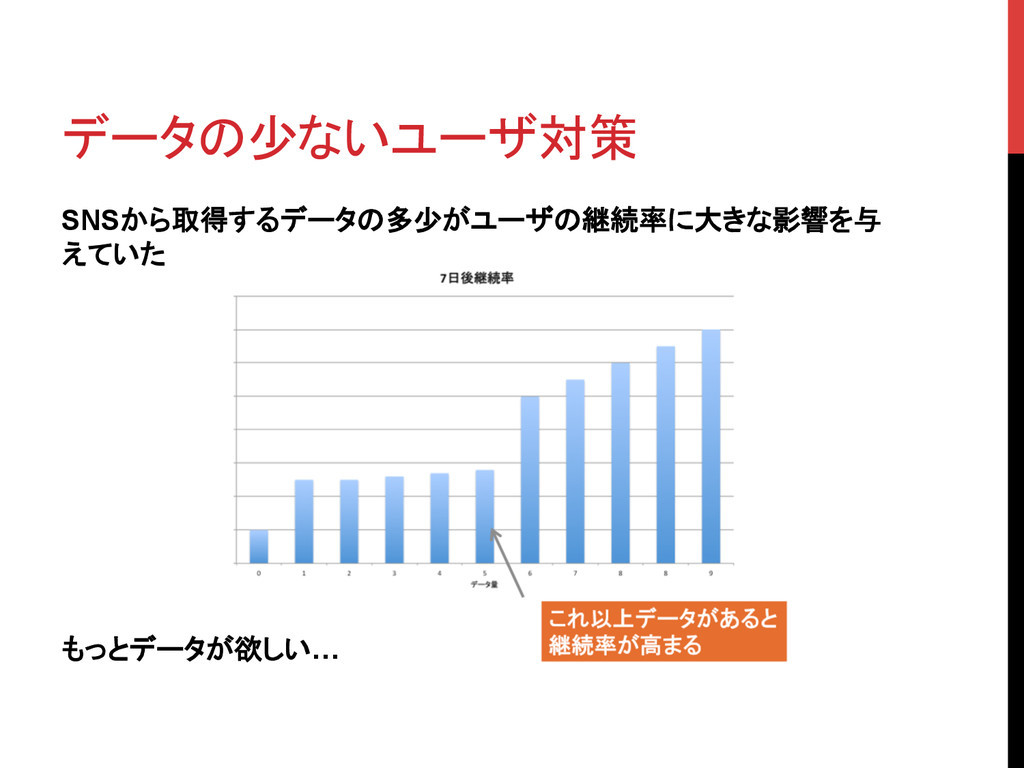
データの少ないユーザ対策 SNSから取得するデータの多少がユーザの継続率に大きな影響を与 えていた もっとデータが欲しい…
データの少ないユーザ対策 SNS単体から取得出来るデータ量には制限がある • 分析手法を変更し、データ量を増やそうとした • データは増えたが、継続率は向上せず… 登録後のアンケートで足りないデータを補充することにした • アンケート画面を追加すると、そこでの離脱も当然生まれる •
複数のアンケート方法、デザインをテストした • 推薦精度の向上による継続定着 > アンケート画面での離脱 グノシーといえば全自動みたいな考えがあったが、自動化にユーザに 入力を混ぜて継続率向上させることが出来た
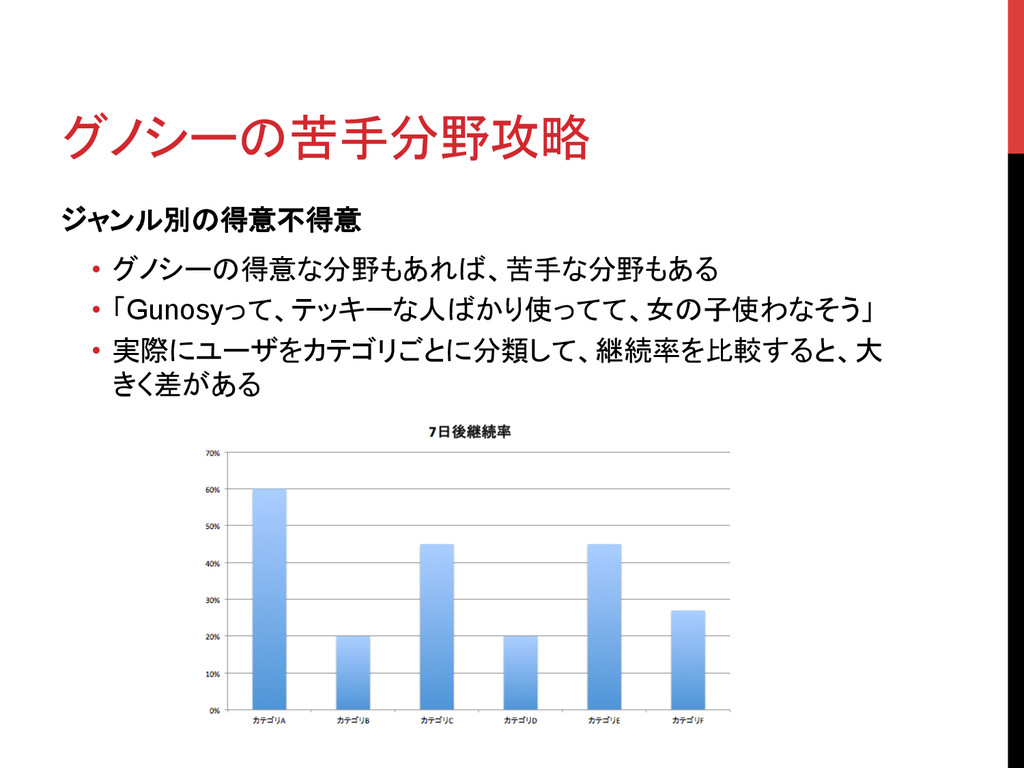
グノシーの苦手分野攻略 ジャンル別の得意不得意 • グノシーの得意な分野もあれば、苦手な分野もある • 「Gunosyって、テッキーな人ばかり使ってて、女の子使わなそう」 • 実際にユーザをカテゴリごとに分類して、継続率を比較すると、大 きく差がある
グノシーの苦手分野攻略 苦手分野はなぜ苦手なのか? • そもそも記事収集できてないのでは? • 面白い記事が推薦されにくいのでは? 推薦ロジック改修する…? コスト大きそう… →人力でもいいから、上の問題を解決しよう!
グノシーの苦手分野攻略 記事収集できてないのでは? • ジャンル別の記事数を可視化して毎日チェック • 少ない分野はTwitter観察したり、雑誌見てみたりして、記事 ソースを探していった 面白い記事が推薦されにくいのでは? • 推薦されやすい記事とクリック率の高い記事があっていなかっ
た • ロジックを変更するのは大変 • とりあえずクリック率が高い記事が推薦されやすいように、クソ ヒューリスティックスを多数導入 • 謎の係数かけたり、人力で記事データ変更したり 機械学習使ってロジック作るのもいいけど、スピード優先で人力で試す
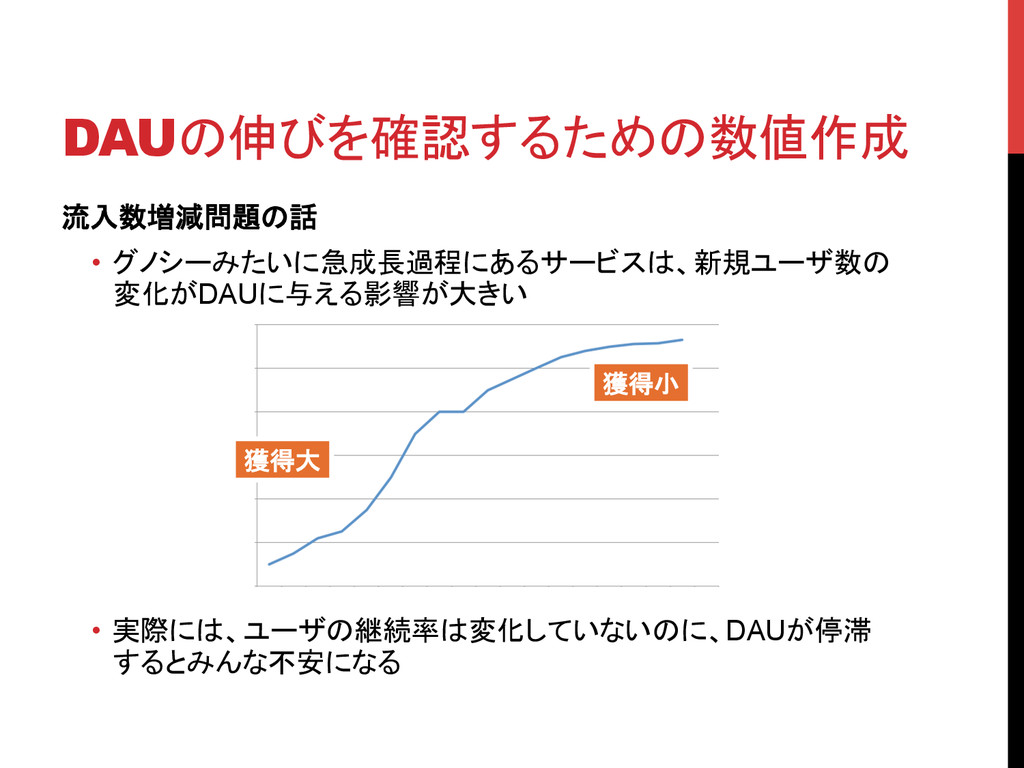
DAUの伸びを確認するための数値作成 流入数増減問題の話 • グノシーみたいに急成長過程にあるサービスは、新規ユーザ数の 変化がDAUに与える影響が大きい • 実際には、ユーザの継続率は変化していないのに、DAUが停滞 するとみんな不安になる 獲得大 獲得小
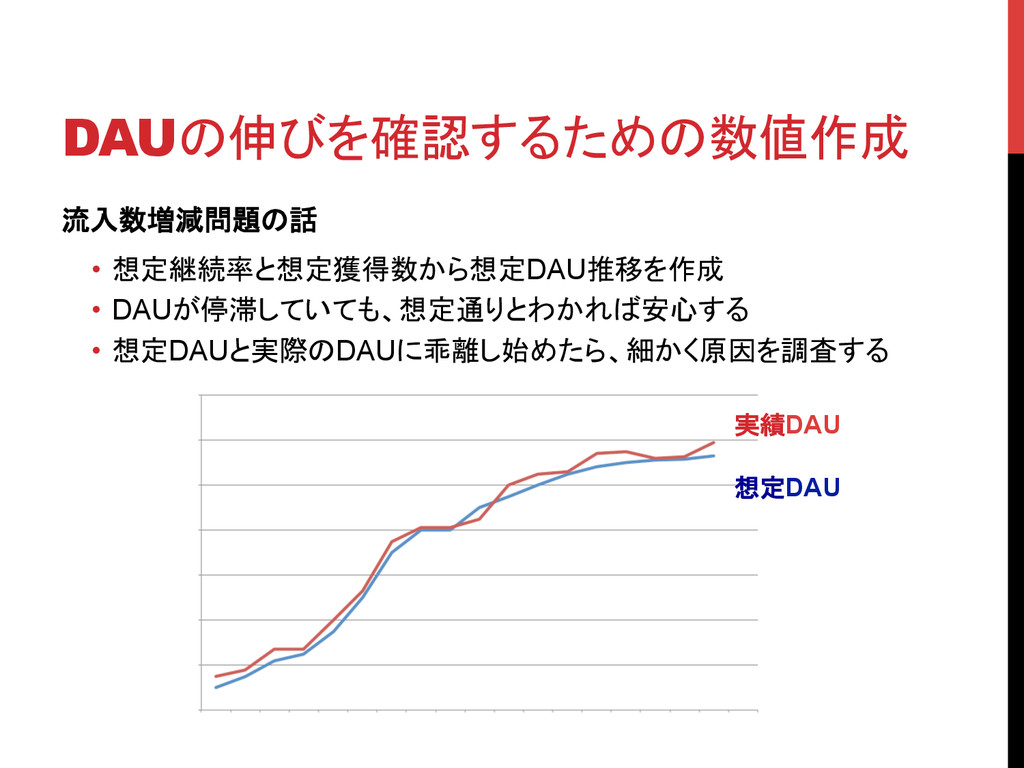
DAUの伸びを確認するための数値作成 流入数増減問題の話 • 想定継続率と想定獲得数から想定DAU推移を作成 • DAUが停滞していても、想定通りとわかれば安心する • 想定DAUと実際のDAUに乖離し始めたら、細かく原因を調査する 実績DAU 想定DAU
最後に 他にも話せないことがたくさんあります! 分析も推薦もやりたいことはたくさんあります! We’re hiring!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}