Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
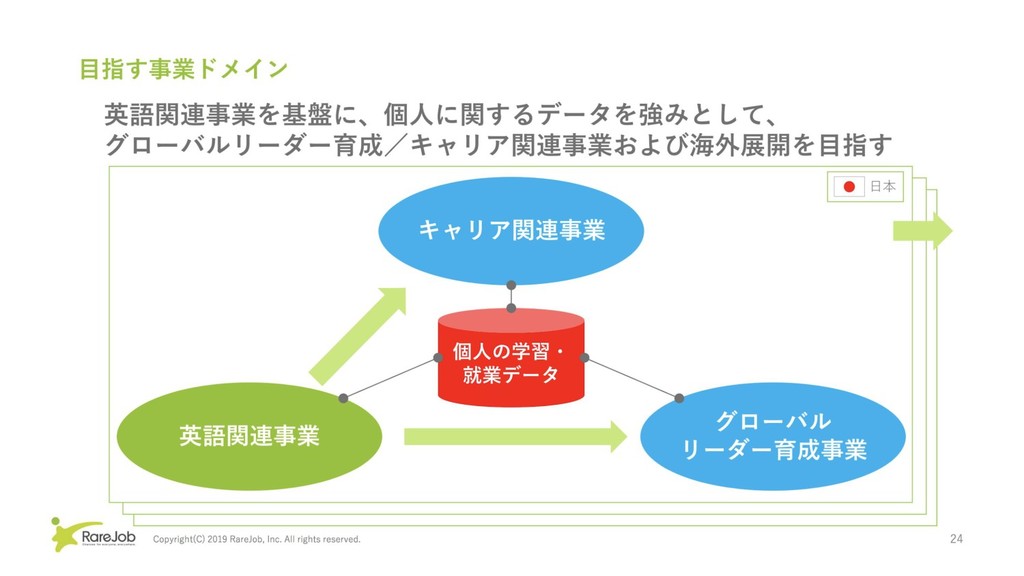
レアジョブのデータ活用の今とこれから
Search
hayata-yamamoto
August 28, 2019
Technology
880
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
レアジョブのデータ活用の今とこれから
#rarejob_medpeer で使いました。
hayata-yamamoto
August 28, 2019
More Decks by hayata-yamamoto
See All by hayata-yamamoto
東京でも_広島でも__ひろしま_でつながる.pdf
hayata_yamamoto
0
17
生成AI動向まとめ 2025年7月
hayata_yamamoto
1
83
テック系起業家のための 会計入門 数字を味方につける経営ガイド
hayata_yamamoto
0
58
バランスト・スコアカード(BSC)
hayata_yamamoto
0
51
データ同化入門
hayata_yamamoto
0
110
中小企業のための 行政デジタルID活用ガイド
hayata_yamamoto
0
55
AIエージェントにおける評価指標と評価方法:本番環境での包括的検証戦略
hayata_yamamoto
0
110
統計的意思決定論の入門
hayata_yamamoto
0
270
コンテキストエンジニアリング入門
hayata_yamamoto
0
270
Other Decks in Technology
See All in Technology
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
160
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
スタートアップにおけるアジャイルの実践について #shibuyagile
murabayashi
3
2.1k
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
180
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
840
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
750
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
1
220
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
1.9k
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
1.6k
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
120
Claude Codeとハーネスについて考えてみる
oikon48
18
8.8k
Featured
See All Featured
Build your cross-platform service in a week with App Engine
jlugia
234
18k
A designer walks into a library…
pauljervisheath
211
24k
A better future with KSS
kneath
240
18k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
Making the Leap to Tech Lead
cromwellryan
135
10k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Fireside Chat
paigeccino
42
4k
Accessibility Awareness
sabderemane
1
150
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Transcript
レアジョブのデータ活用の今とこれから Hayata Yamamoto RareJob.inc
Self-intro - Name: - Hayata Yamamoto (24) - Role: -
Data Scientist @EdTech Lab - Likes: - Natural Language Processing - Data Engineering - Podcast - Recent: - Certificateをとりました
Today’s Theme データ活用の文化を維持しつつ、 より使いやすくするための分析基盤を作っている話
Agenda 1. どのようにデータは使われているか (As Is) 2. どのようにデータを使っていきたいか (To Be) 3.
どのように差分を埋めるか
どのようにデータを使っているか
Pros / Cons Pros: • エンジニアや企画職が SQLを書いて分析している • 分析結果を元に意思決定が行われる •
機械学習を用いた研究開発プロジェクトが進行中 Cons: • データウェアハウス( DWH)が形骸している • マイクロサービスのDBを横断的に利用できていない • 大規模なデータを使ったデータ分析がしにくい • データ分析に必要なドメイン知識が多い
What’s the problem? Pros: • エンジニアや企画職が SQLを書いて分析している • 分析結果を元に意思決定が行われる •
機械学習を用いた研究開発プロジェクトが進行中 Cons: • データウェアハウス( DWH)が形骸している • マイクロサービスのDBを横断的に利用できていない • 大規模なデータを使ったデータ分析がしにくい • データ分析に必要なドメイン知識が多い 技術的に問題を解決するだけで大幅にデータ活用が進むのでは? データ活用の意識がある 技術的に解決できる問題
解決法がわかっている 解決法がわかっていない 顕在化した 問題 データ分析によるプロダクト改善 データを使いやすくする データ活用の文化をつくる 潜在的な 問題 プロトタイピング
データマイニング 研究開発 (パーソナライズ、自動化など) データに関わる問題をマトリックスにまとめたもの
解決法がわかっている 解決法がわかっていない 顕在化した 問題 データ分析によるプロダクト改善 データを使いやすくする データ活用の文化をつくる 潜在的な 問題 プロトタイピング
データマイニング 研究開発 (パーソナライズ、自動化など) データ活用の文化はすでにあるのに、データが使いにくいのは大きな損失 →プロダクト改善がしにくくなってしまう
解決法がわかっている 解決法がわかっていない 顕在化した 問題 データ分析によるプロダクト改善 データを使いやすくする データ活用の文化をつくる 潜在的な 問題 プロトタイピング
データマイニング 研究開発 (パーソナライズ、自動化など) データが使いにくいと、試行錯誤の効率が非常に悪い →成果に結びつきにくくなってしまう
どのようにデータを使っていきたいか
None
None
None
要するに データ使って学習体験を向上させたい
どのように差分を埋めるか
As Is / To Be As Is • データを使って意思決定する文化を十分に活かせてない •
ノウハウやドメイン知識が属人化しがち • データへのアクセスが悪く、研究開発で試行錯誤しにくい To Be • プロダクトを通じてユーザーが英語を話せるようになる • 効率的な学習体験と新しい学習機会を提供する • それぞれの個人に合わせた学習ができるようにする
What’s the gaps? 1. データ分析する文化がある, but データが使いにくい 2. ユーザーに最適化したサービスを提供したい, but
知識が属人化しがち 3. 新しい体験を提供したい, but 研究開発の試行錯誤がしにくい データのアクセスや仕組みで解決できそう
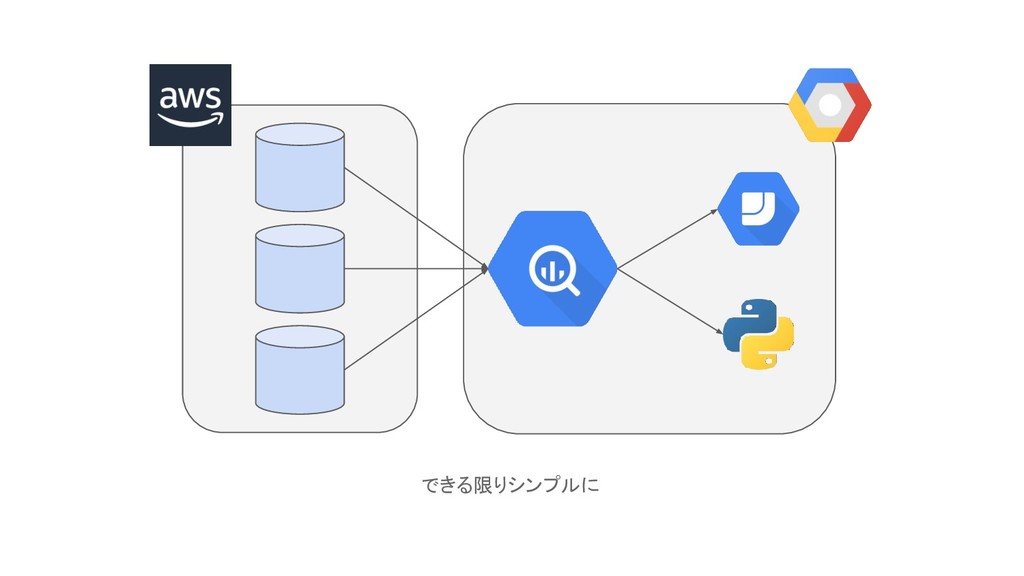
How to solve? • BigQueryをハブにして、マイクロサービスからデータを集める ◦ データの整形やテーブルの整理をしておく • 全社で必要なデータをあらかじめ可視化しておく ◦
知見の共有、認識の統一、属人化の防止 • 集めたデータを再利用できるようにする ◦ 馴染みのあるツールや、新しいツールで使えるようにする (Redashなど) • 大規模なデータが必要な分析ロールはBQを直接叩く ◦ サーバーのスケールアウト問題からの脱却。データの再現性を確保
できる限りシンプルに
ToDo • 既存の仕組みはバッチ処理に最適化された設計になっている ◦ アプリやWebRTCなどもあるので、ストリームデータも将来的には扱いたい • AWSとGCPの使い分け、住み分け ◦ データの頻度や鮮度を求めると費用対効果を損なう懸念 •
マイクロサービスの開発とうまく並走させる ◦ 分析基盤を意識しないで済む設計にしたい • 分析基盤を一緒に作ってくれる仲間を見つける ◦ We’re Hiring!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}