既存データセットは画像とキャプションの規模に欠ける 問題設定: Fully open MLLMの画像キャプション生成性能 向上のためのPreference Optimization (PO) データセット 概要 FOIL [Shekhar+, ACL17] 10万画像/約60万キャプション 単語置換により生成 Polaris [Wada+, CVPR24] 世界最大の画像キャプション 評価データ 1万画像のみ “Two giraffes and a bird are in a fenced area.” “Two giraffes and an ostrich are standing in a zoo.”
outdoor scene where several people are engaged in a game of frisbee. In the foreground, a man wearing a green shirt and plaid shorts …” Pangea: (VELA: 64.5) ”The image shows a group of people playing a game of volleyball on a court. The court is surrounded by trees and there are people in the background watching the game.” 提案手法: (VELA [松田+, MIRU25] : 72.1) volleyballをfrisbee と誤って認識
{kind=link}
{kind=link}
![3 ◼ PO: ペアサンプルからより望ましい出力を学習 ◼ 数十万サンプル規模のPreference Dataが必要 [Ethayarajh+, ICML24] ](https://files.speakerdeck.com/presentations/c70abc80a20f428a8a775ef8e5becd19/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![実験設定:約12万ペア含むPolos FB datasetを構築 6 ◼ Pangea-7B [Yue+, ICLR25] をPolos FB](https://files.speakerdeck.com/presentations/c70abc80a20f428a8a775ef8e5becd19/slide_5.jpg){kind=link}
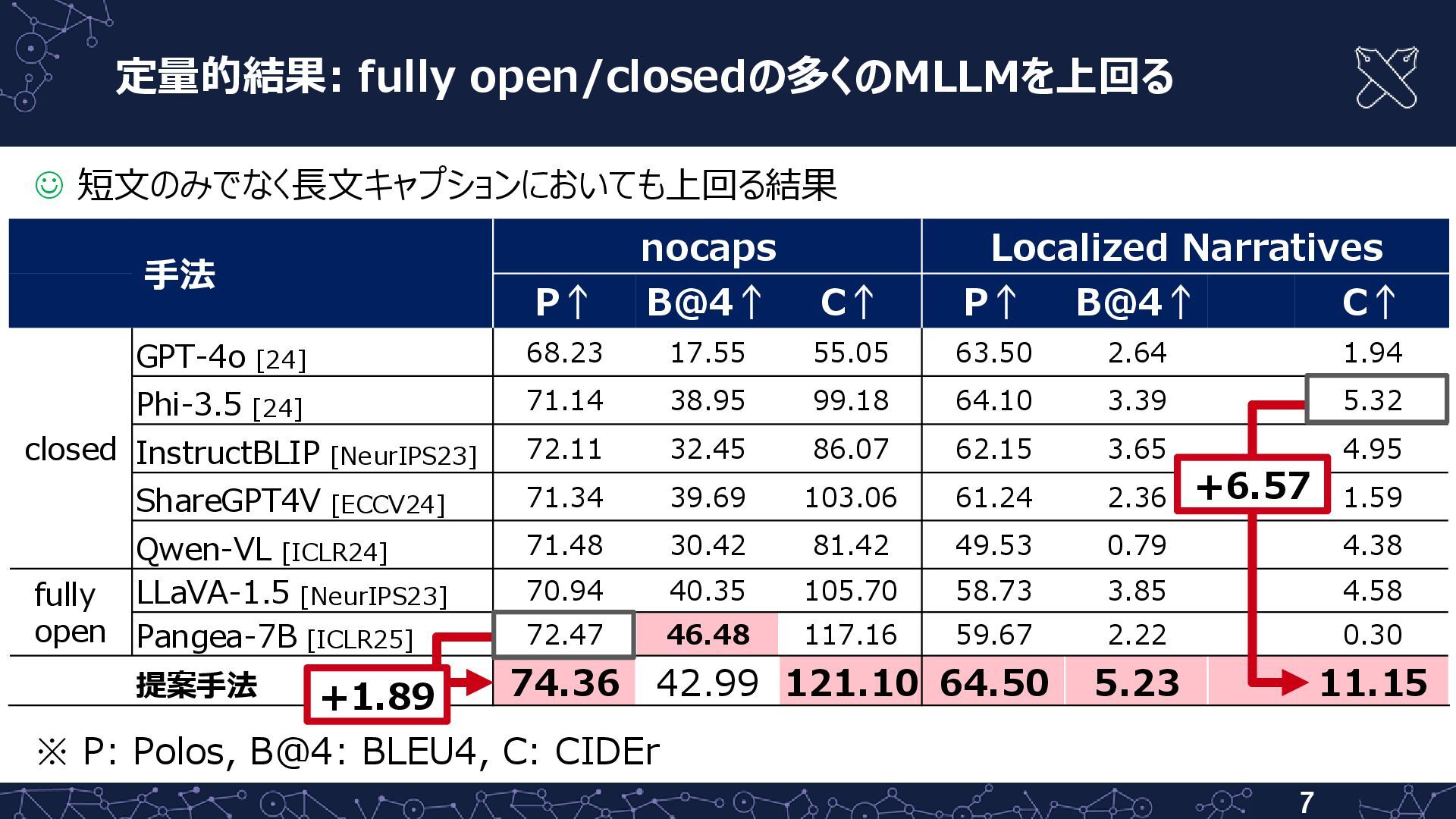{kind=link}
{kind=link}
{kind=link}
{kind=link}
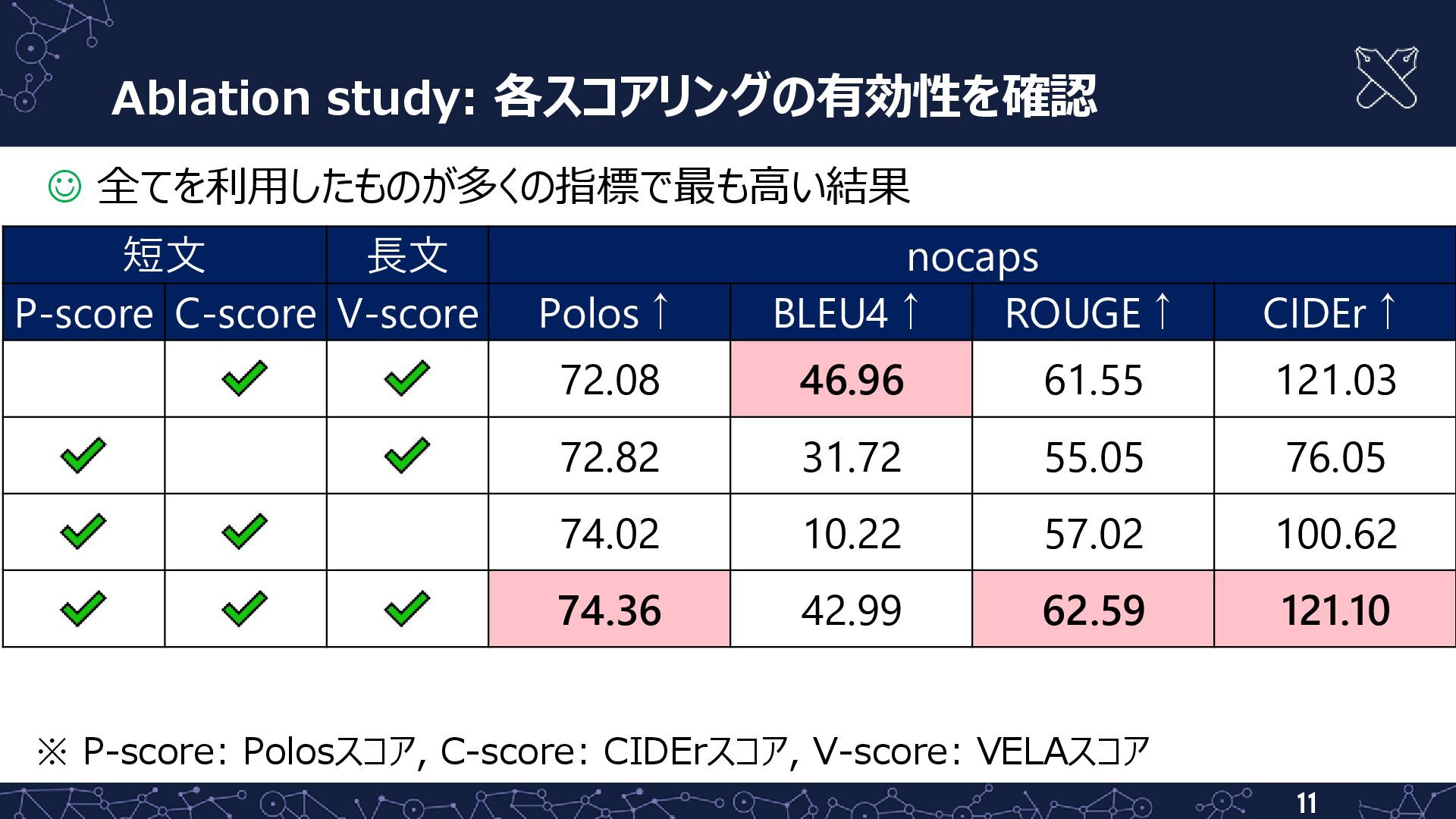{kind=link}
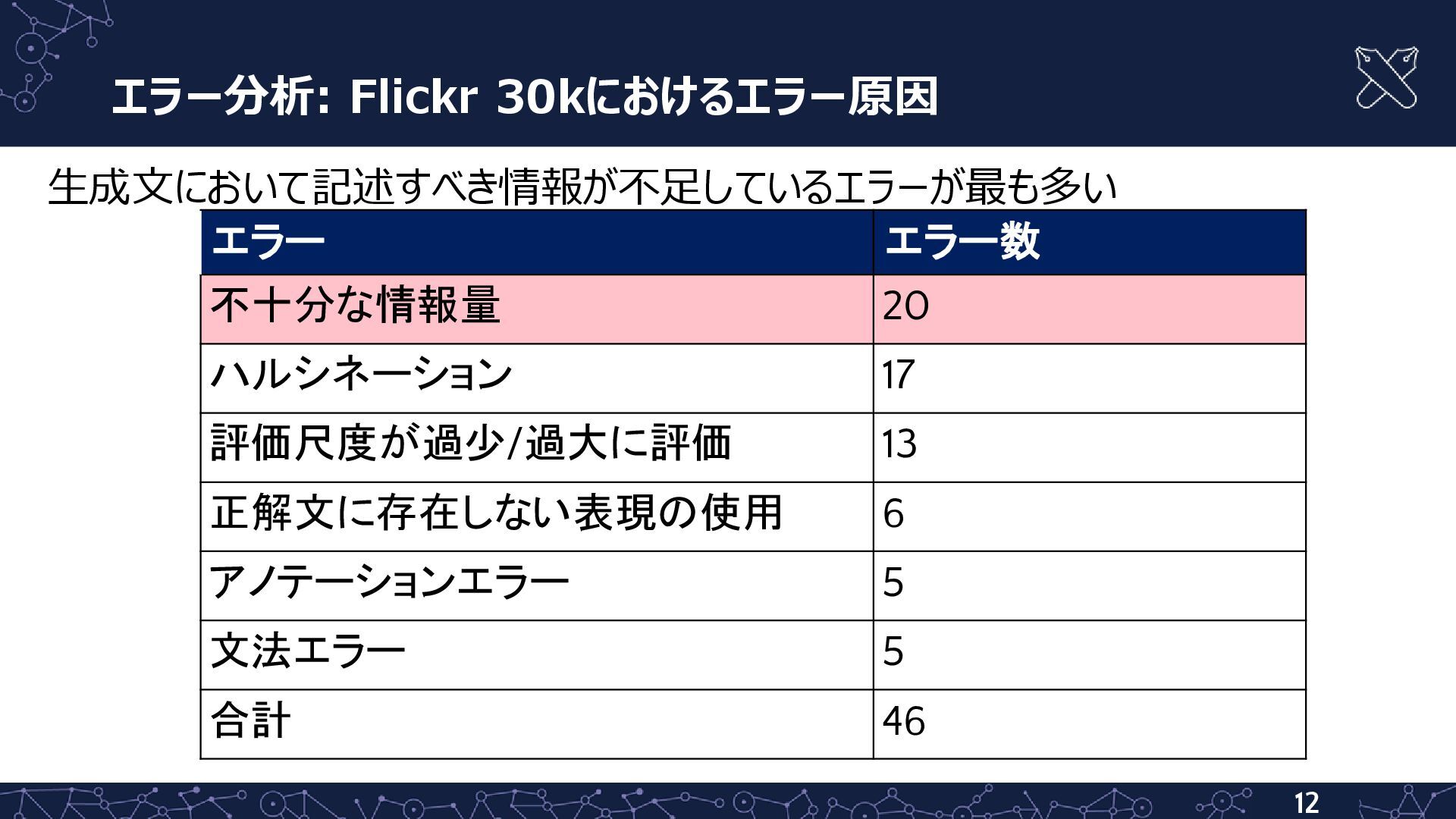{kind=link}