Short presentation on how we use (and *failed* to use properly) elasticsearch at ferret go, a media analysis startup. Given at the ES User Group Berlin, November 2012.
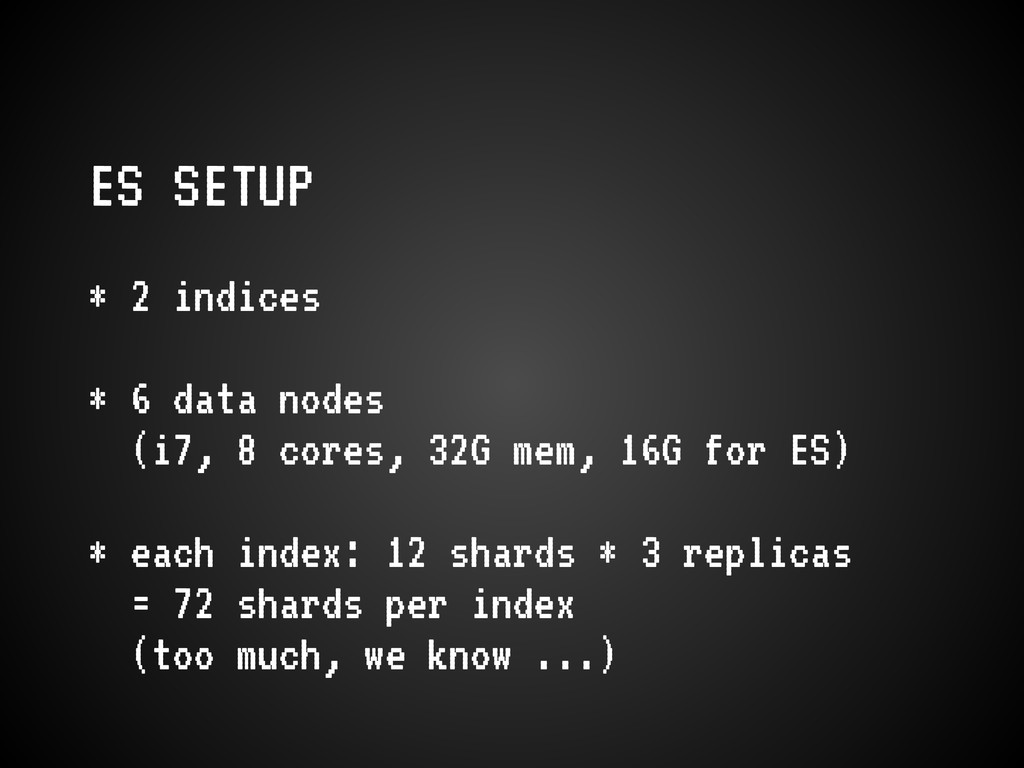
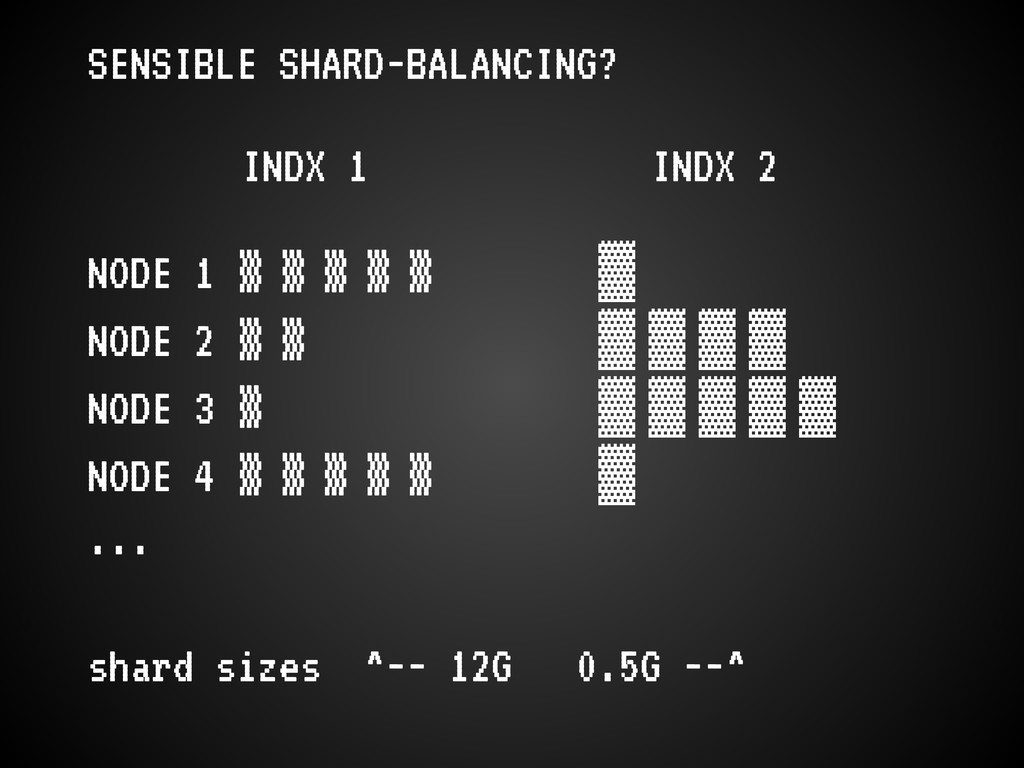
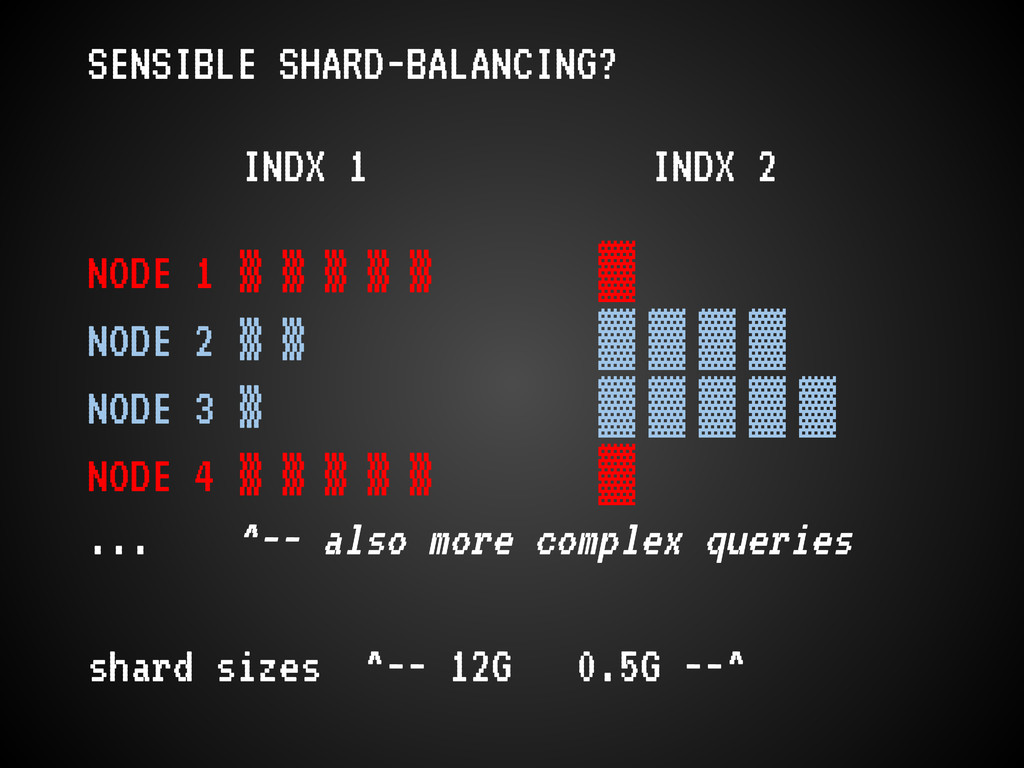
October = 4 Julies) * moving indexes; (bulk) re-indexing * more users * long-term queries now more long-term * config-/brain-less ES setup (which is nice!) only worked for us so long
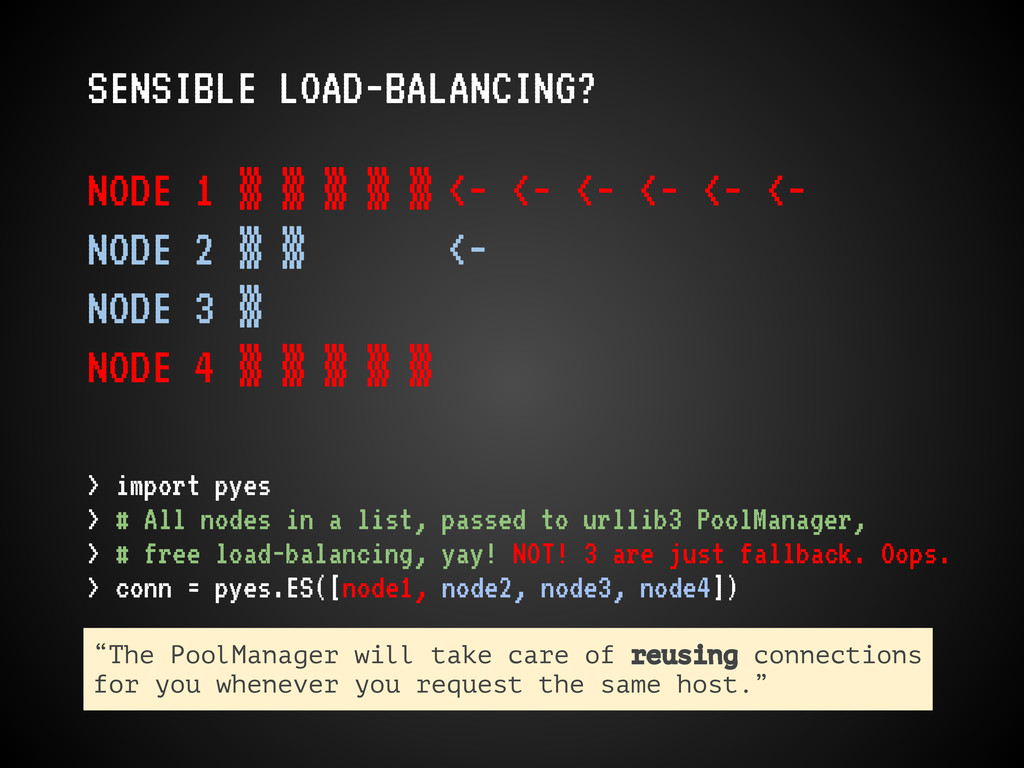
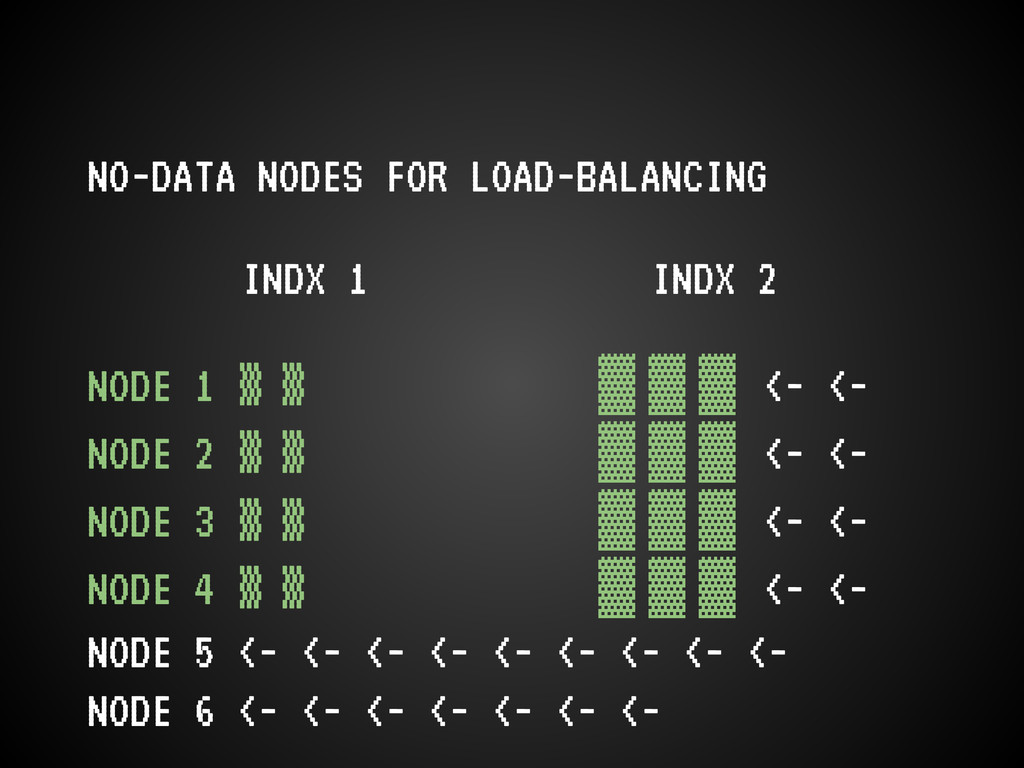
<- <- <- <- <- NODE 2 ▒ ▒ <- NODE 3 ▒ NODE 4 ▒ ▒ ▒ ▒ ▒ > import pyes > # All nodes in a list, passed to urllib3 PoolManager, > # free load-balancing, yay! NOT! 3 are just fallback. Oops. > conn = pyes.ES([node1, node2, node3, node4]) “The PoolManager will take care of reusing connections for you whenever you request the same host.”
ES core devs * some will be fixed * ferret is a faceting-heavy app, which uses lots of memory. we need to be more careful about that. * JVM choice matters * avoid many growing pains, read this: http://asquera.de/opensource/2012/11/25/elasticsearch-pre-flight-checklist/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}