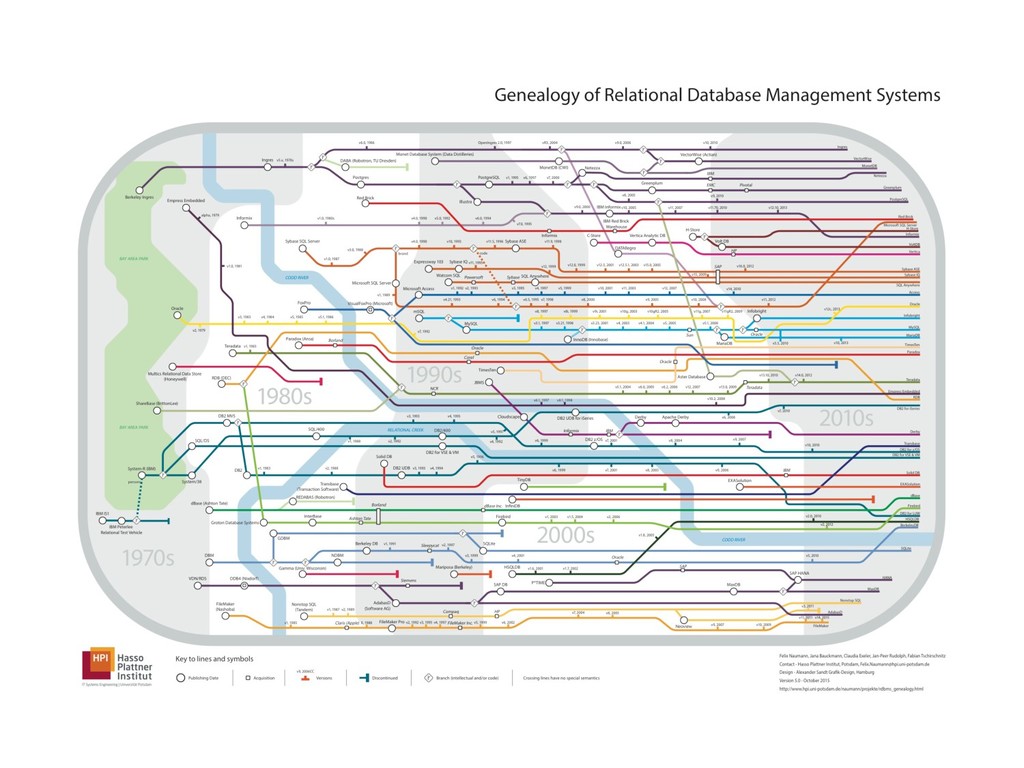
Databases have been around for decades and were highly optimised for data aggregations during that time. Not only Big data has changed the landscape of databases massively in the past years - we nowadays can find many Open Source projects among the most popular dbs.
After this talk you will be enabled to decide if a database can make your work more efficient and which direction to look to.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
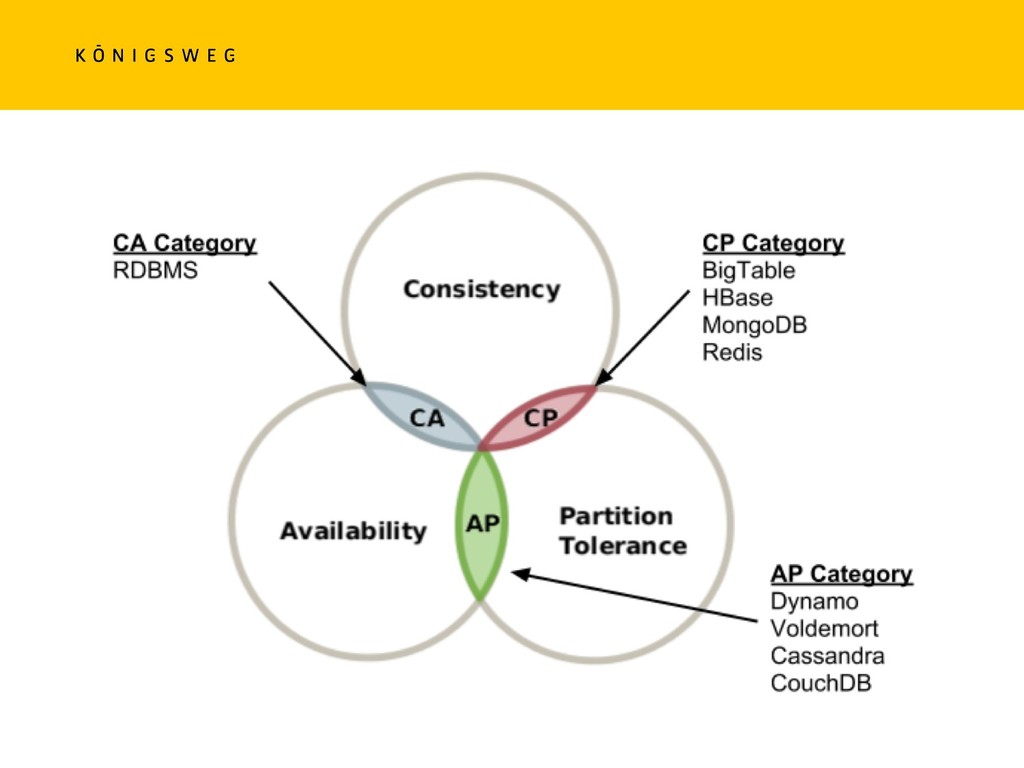{kind=link}
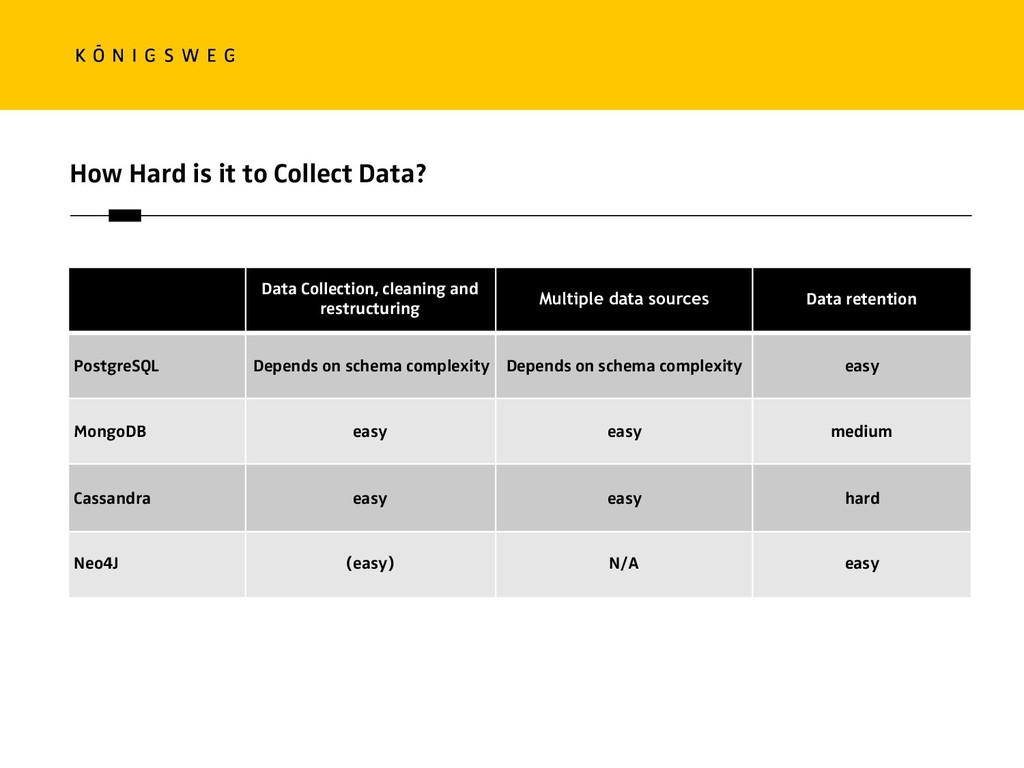{kind=link}
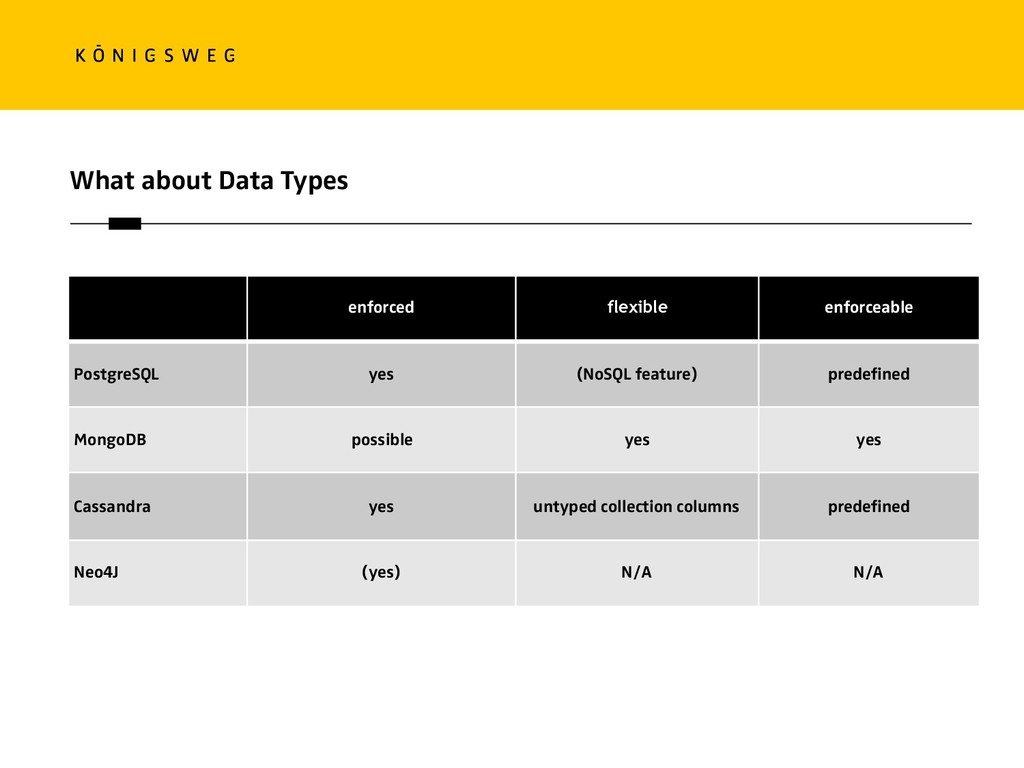{kind=link}
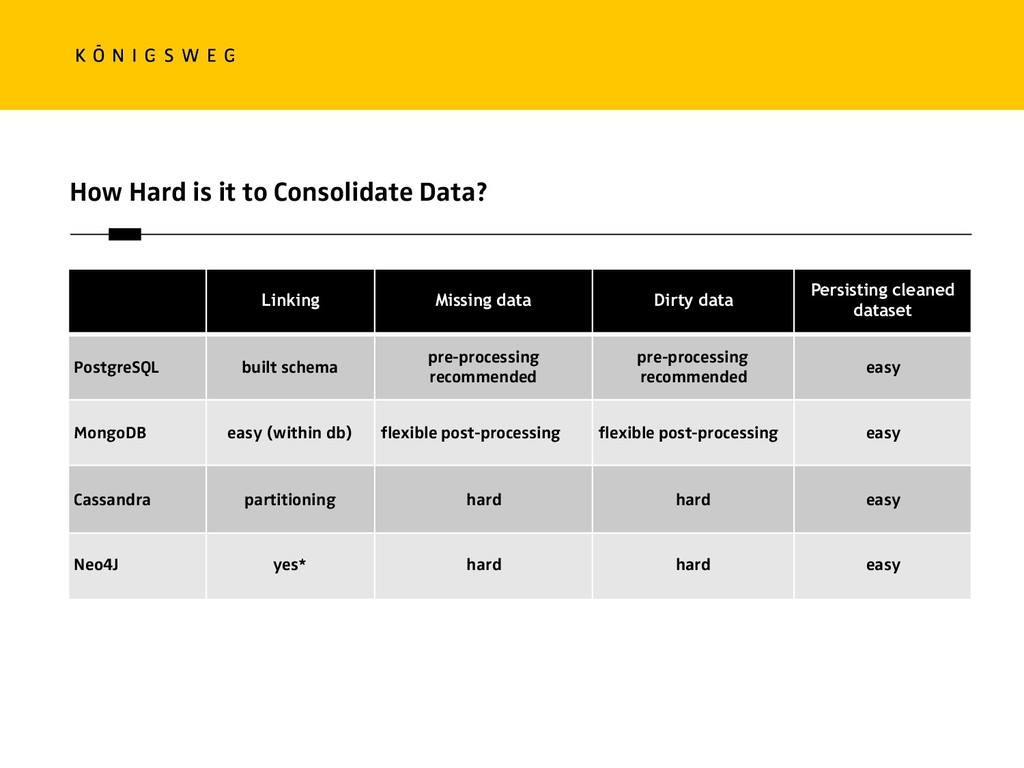{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MATCH (c:Customer {companyName:"Drachenblut Delikatessen"}) OPTIONAL MATCH (p:Product)<-[pu:PRODUCT]-(:Order)<-[:PURCHASED]-(c) RETURN p.productName, toInt(sum(pu.unitPrice](https://files.speakerdeck.com/presentations/bdb38e07769b4b4aad1bd0359c1a6e47/slide_46.jpg){kind=link}
![pipeline = [ {"$match": {"artistName": “Suppenstar"}}, {"$sort": {„info.releaseDate: 1)])}, {"$group":](https://files.speakerdeck.com/presentations/bdb38e07769b4b4aad1bd0359c1a6e47/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
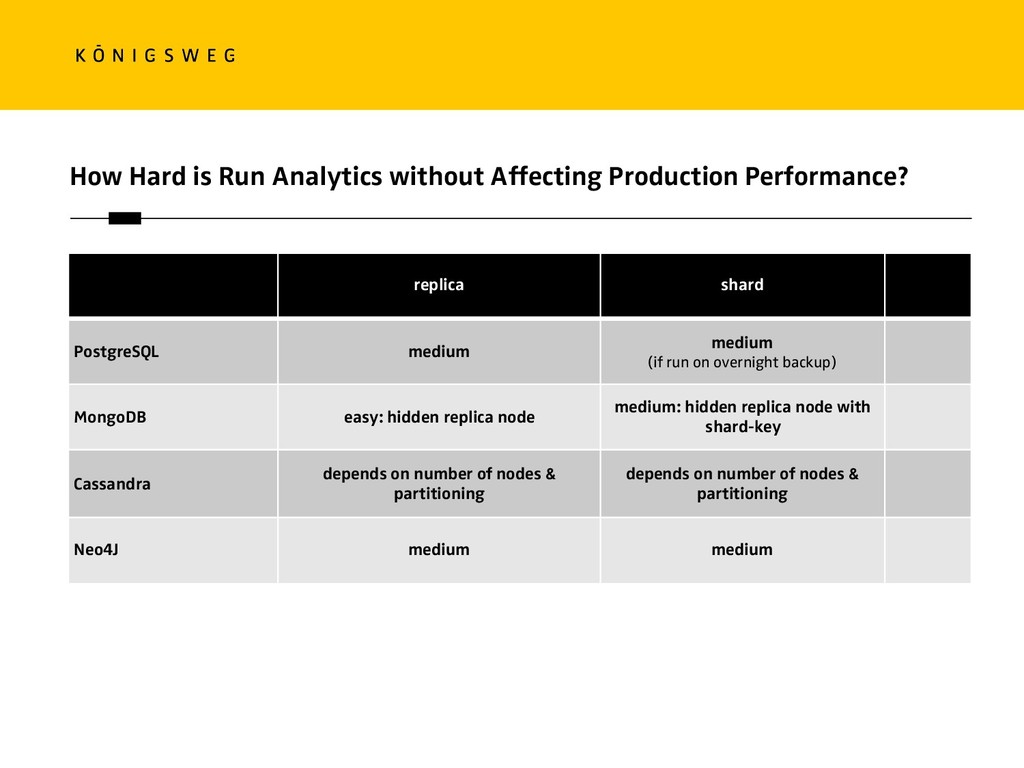{kind=link}
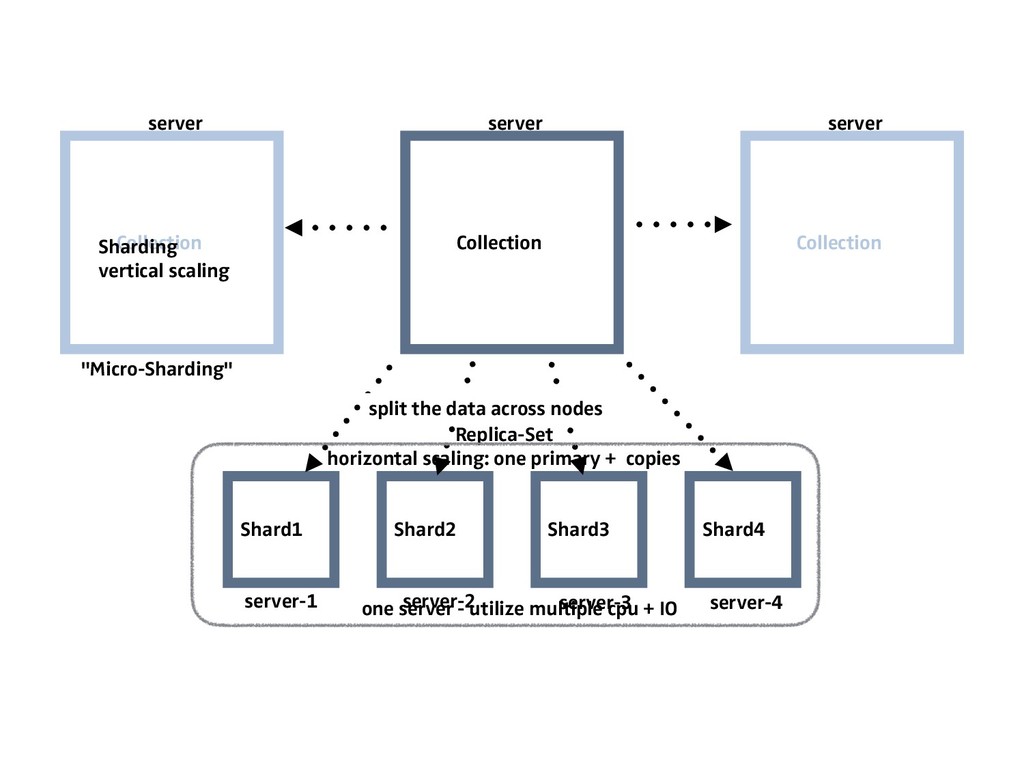{kind=link}
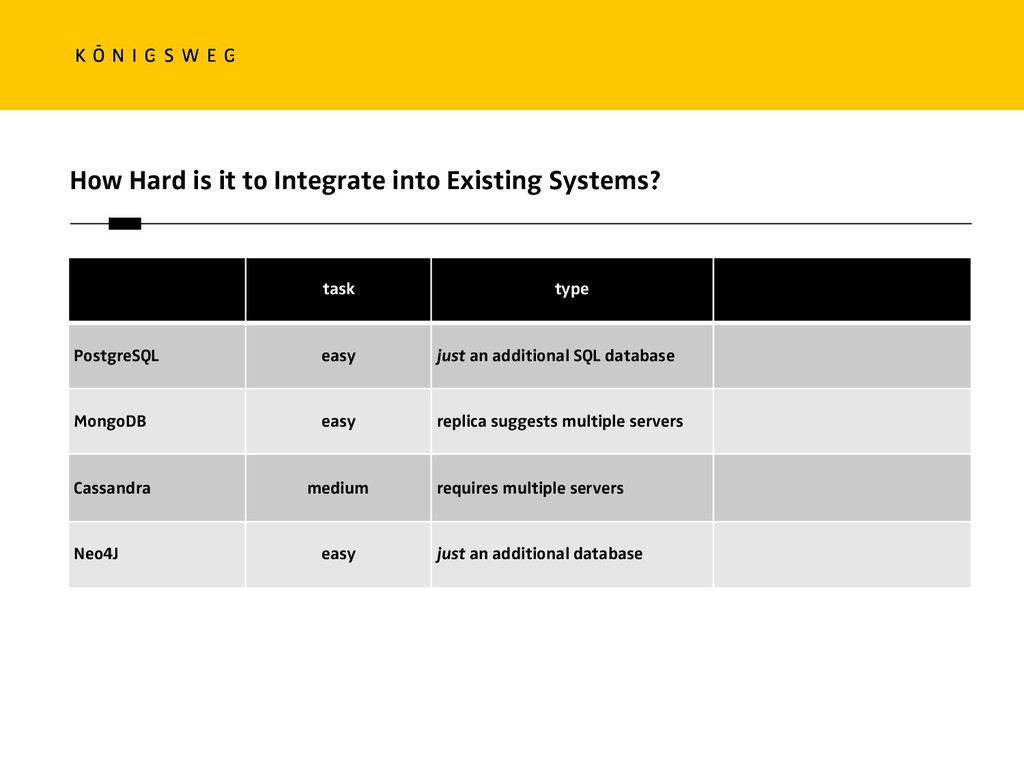{kind=link}
{kind=link}
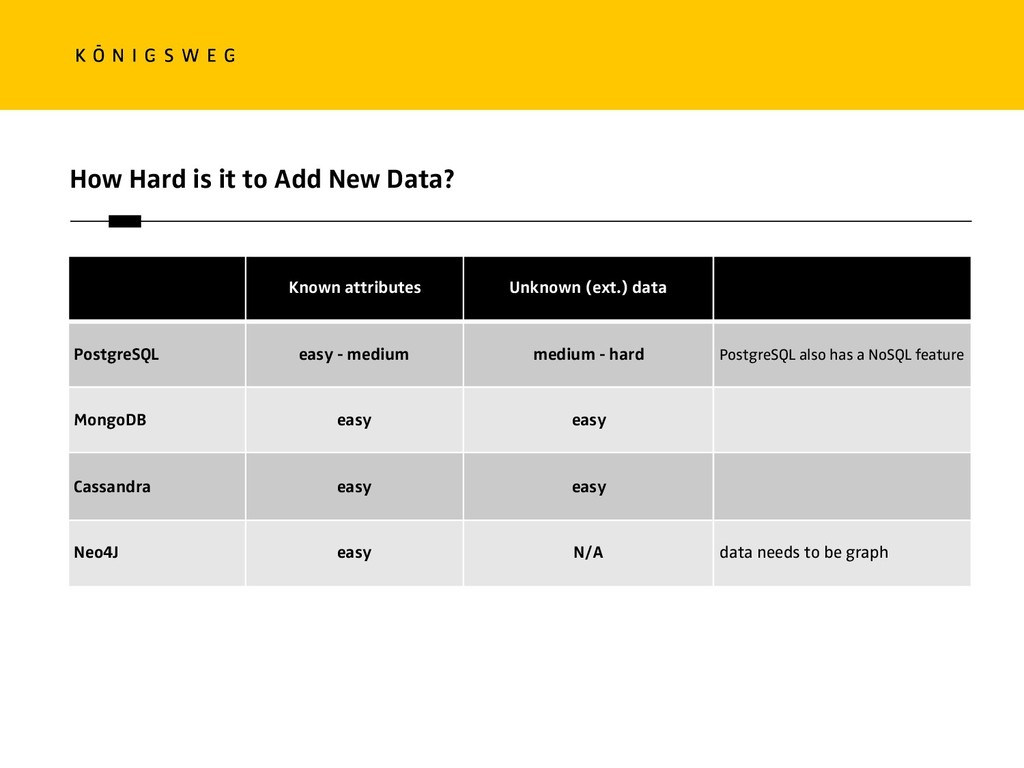{kind=link}
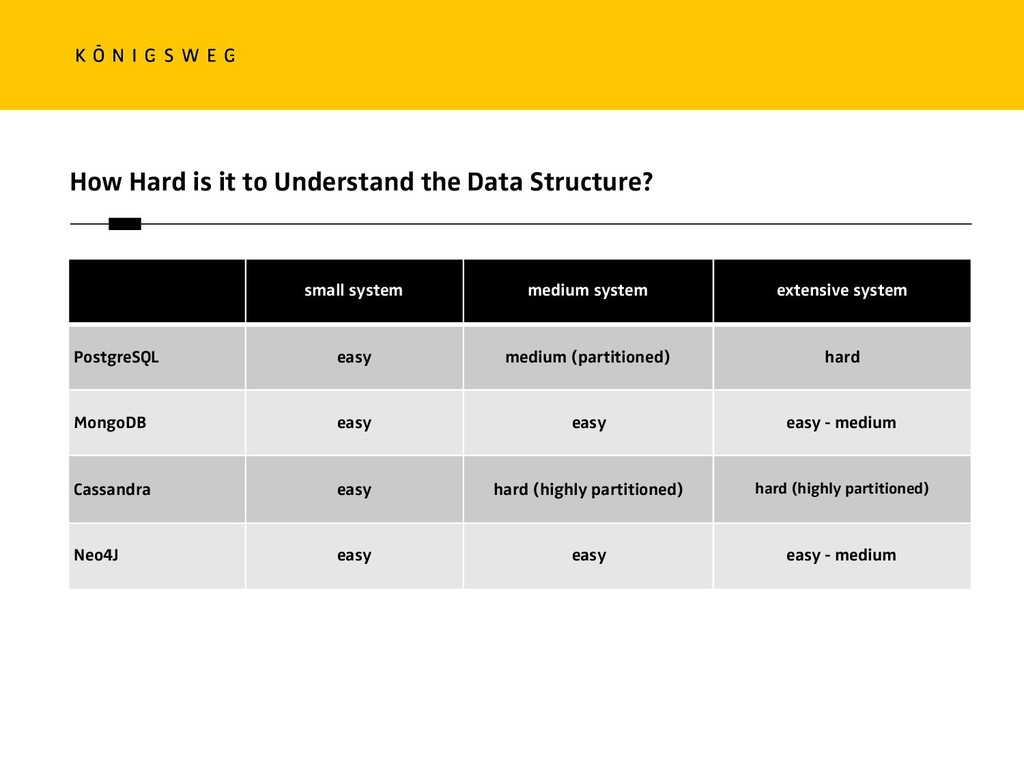{kind=link}
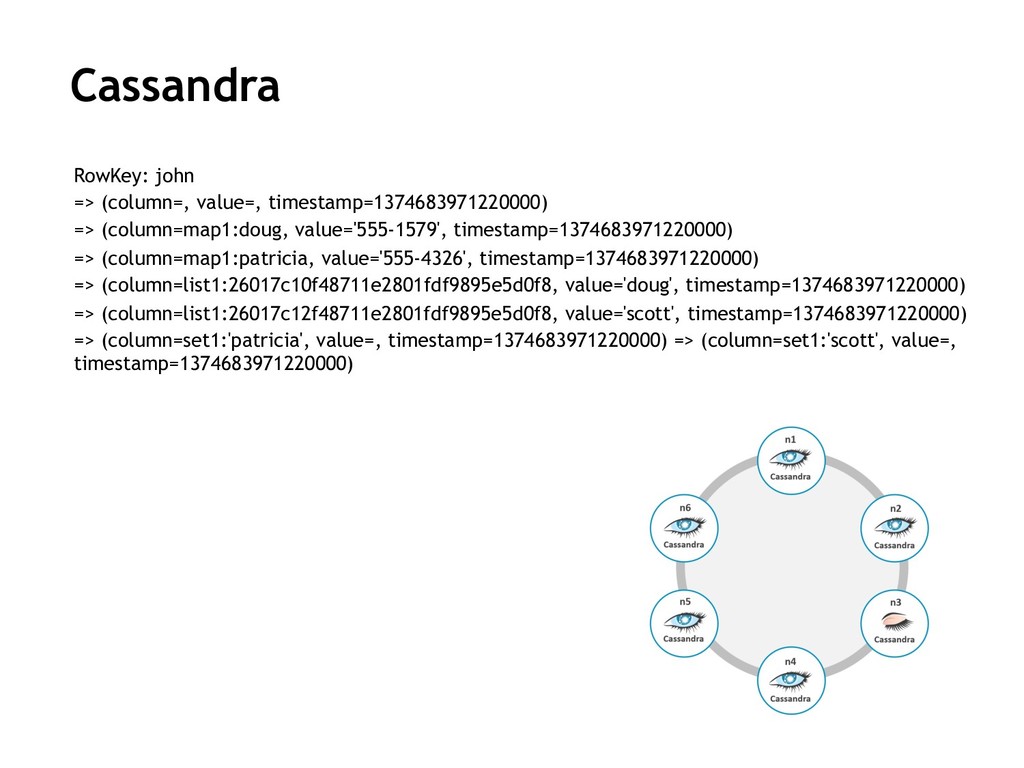{kind=link}
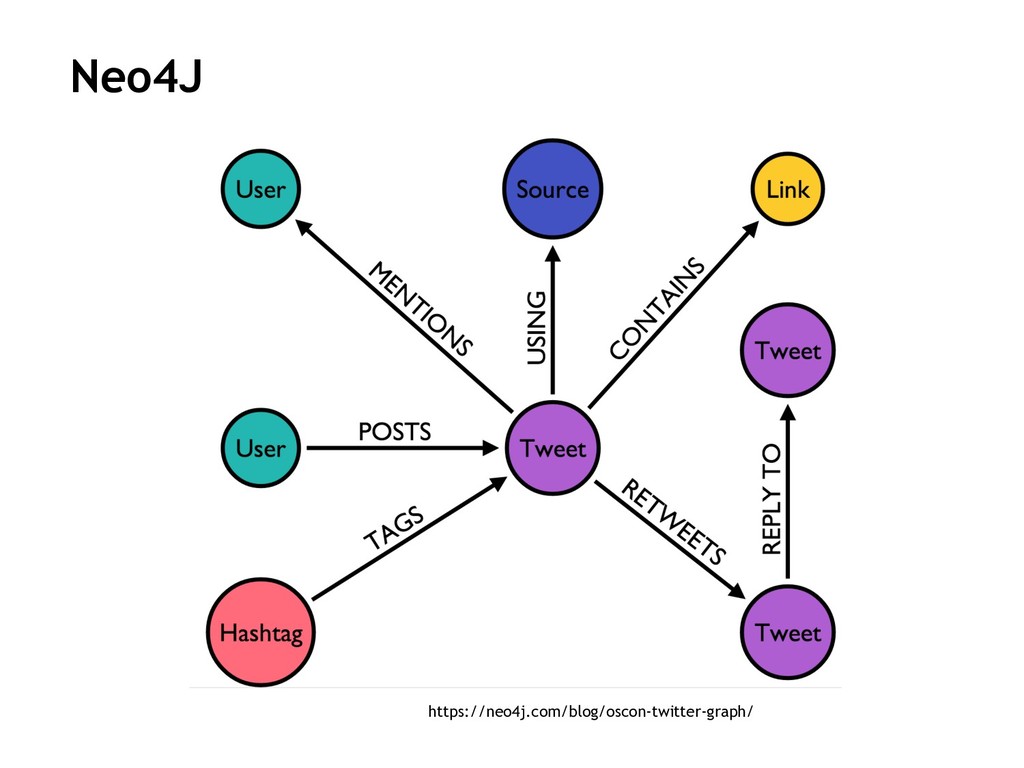{kind=link}
{kind=link}
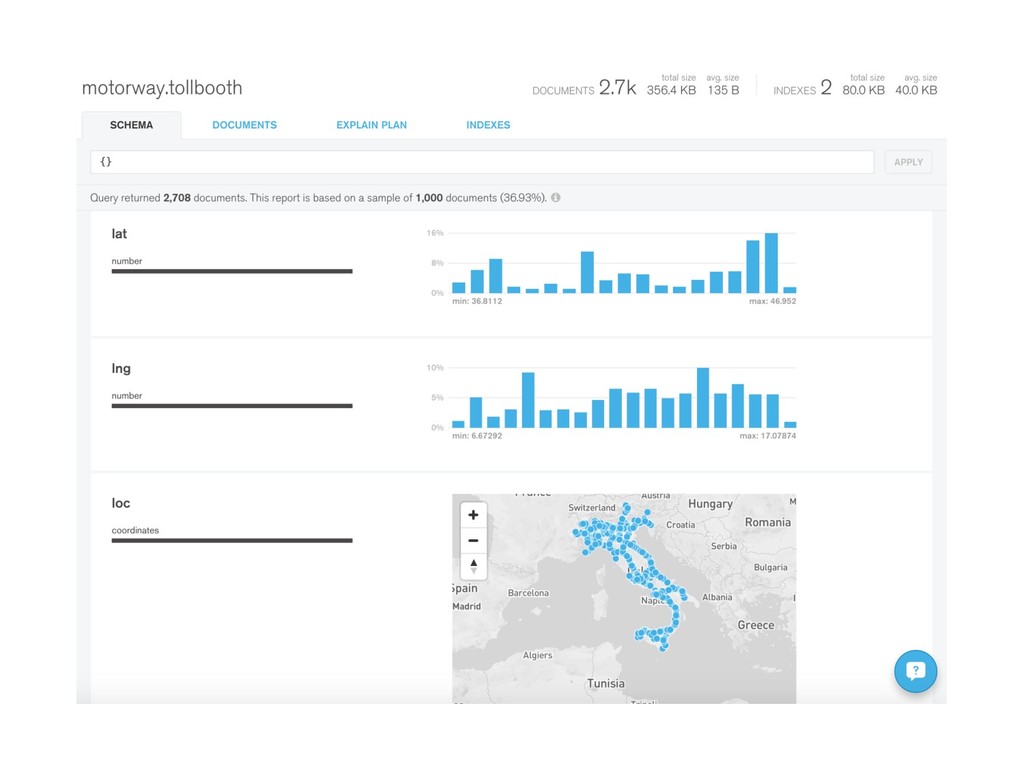{kind=link}
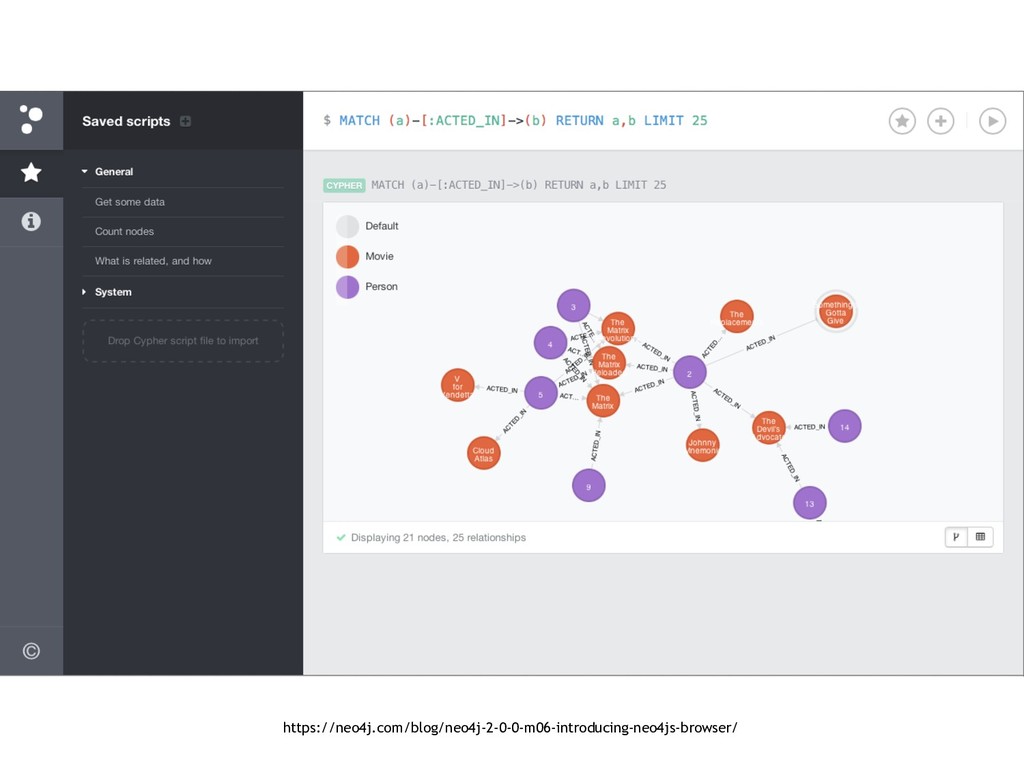{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] @hendorf Thank you! Q & A](https://files.speakerdeck.com/presentations/bdb38e07769b4b4aad1bd0359c1a6e47/slide_67.jpg){kind=link}
{kind=link}