@KubeCon + CloudNative Con North America 2025
Launch reliability is crucial for applications on Kubernetes that frequently restart. However, applications often struggle to achieve optimal performance immediately after starting, failing to handle the load and experiencing startup failures. This lack of launch reliability can result in service downtime during rollouts and make the horizontal pod autoscaler ineffective. To prevent these issues, it's essential to tune the application and apply various practices within manifests.
This session will cover best practices for maximizing the launch reliability of applications on Kubernetes, including application tuning, appropriate resource allocation, health check settings, and techniques for automated warm-up. Additionally, he will explore the practical use of Kubernetes' recent feature, in-place pod resize, particularly for CPU bursting at startup. By the end of the session, you will gain actionable insights to enhance application stability and achieve flexible scaling.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
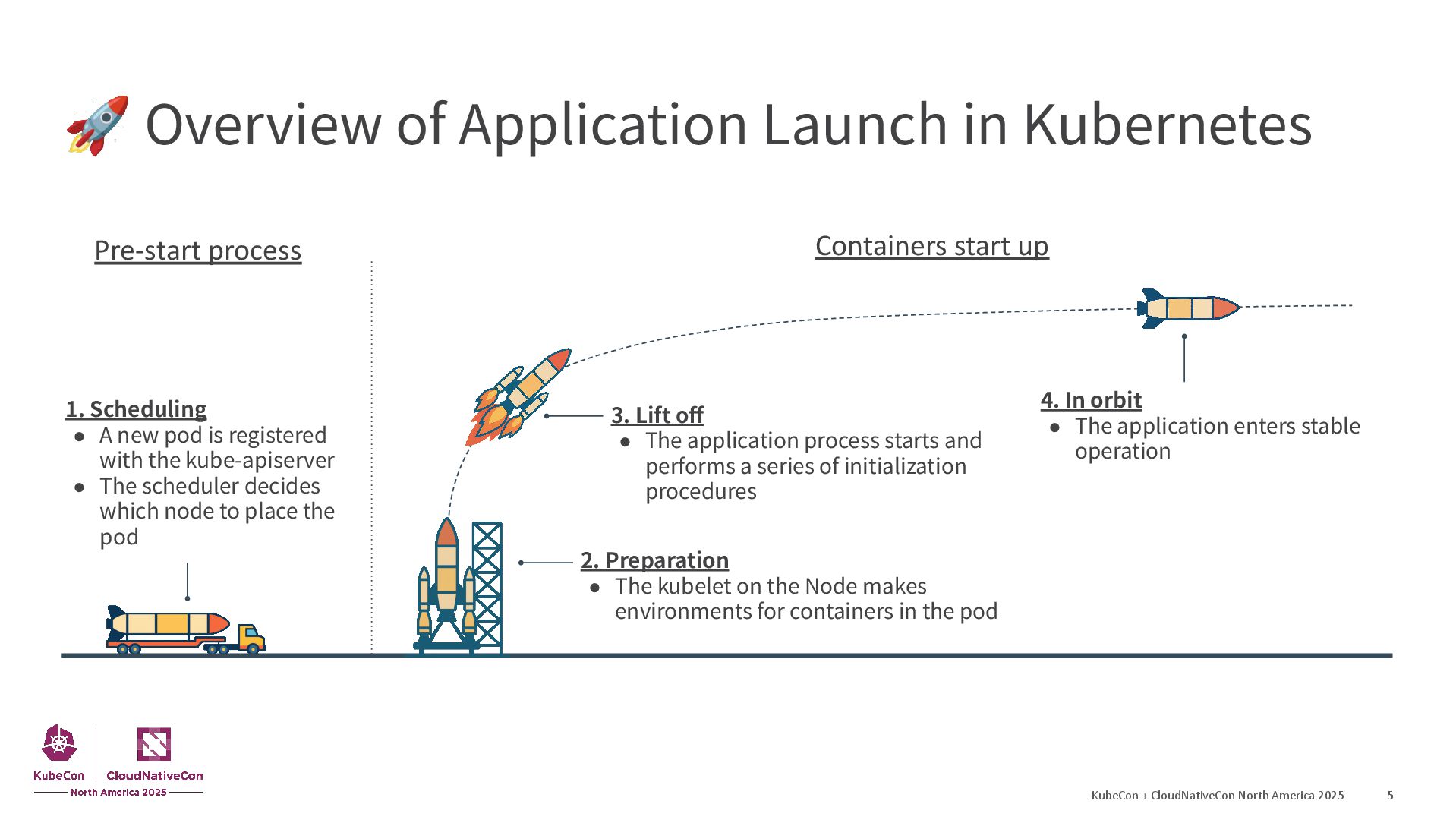{kind=link}
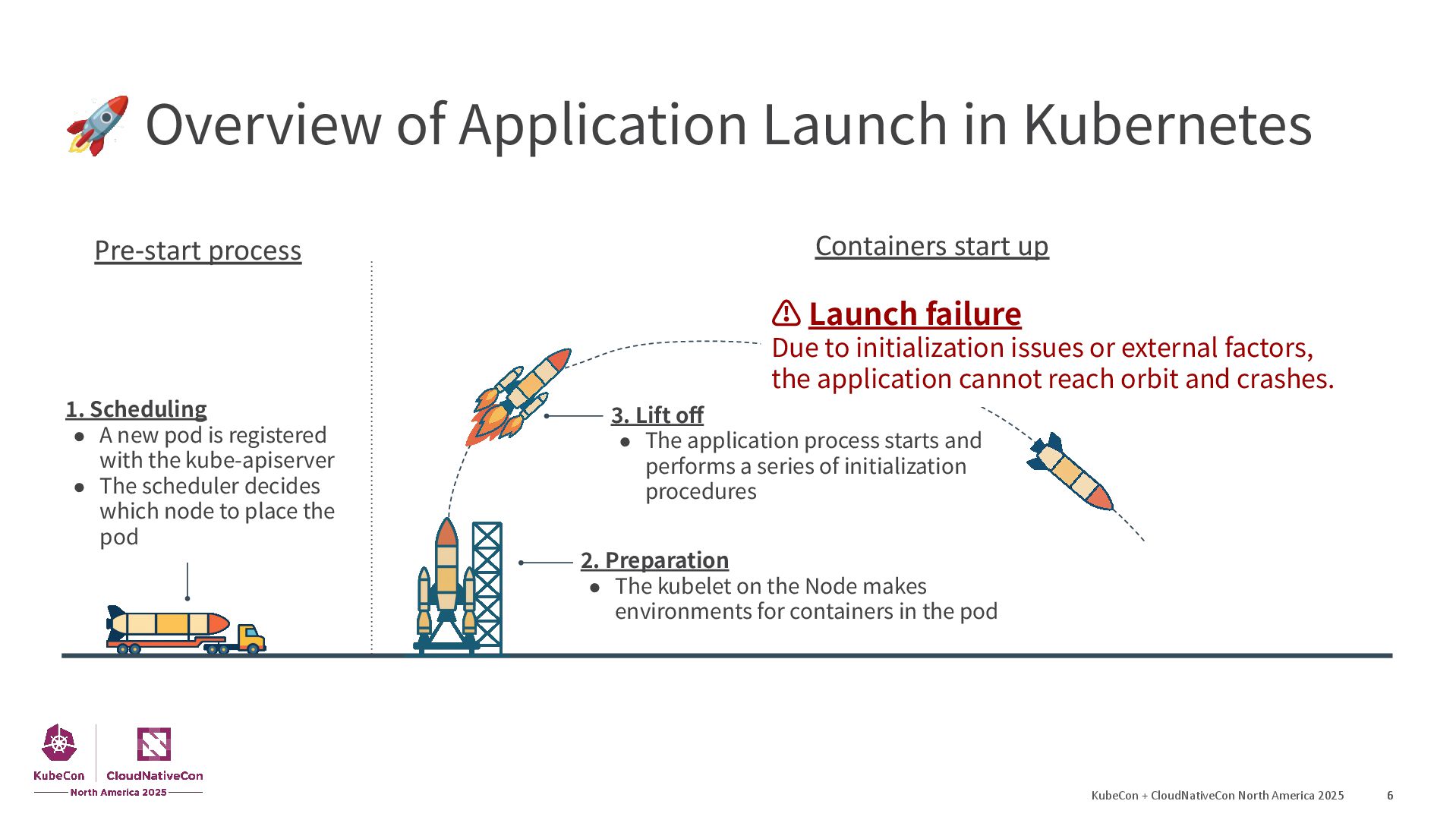{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
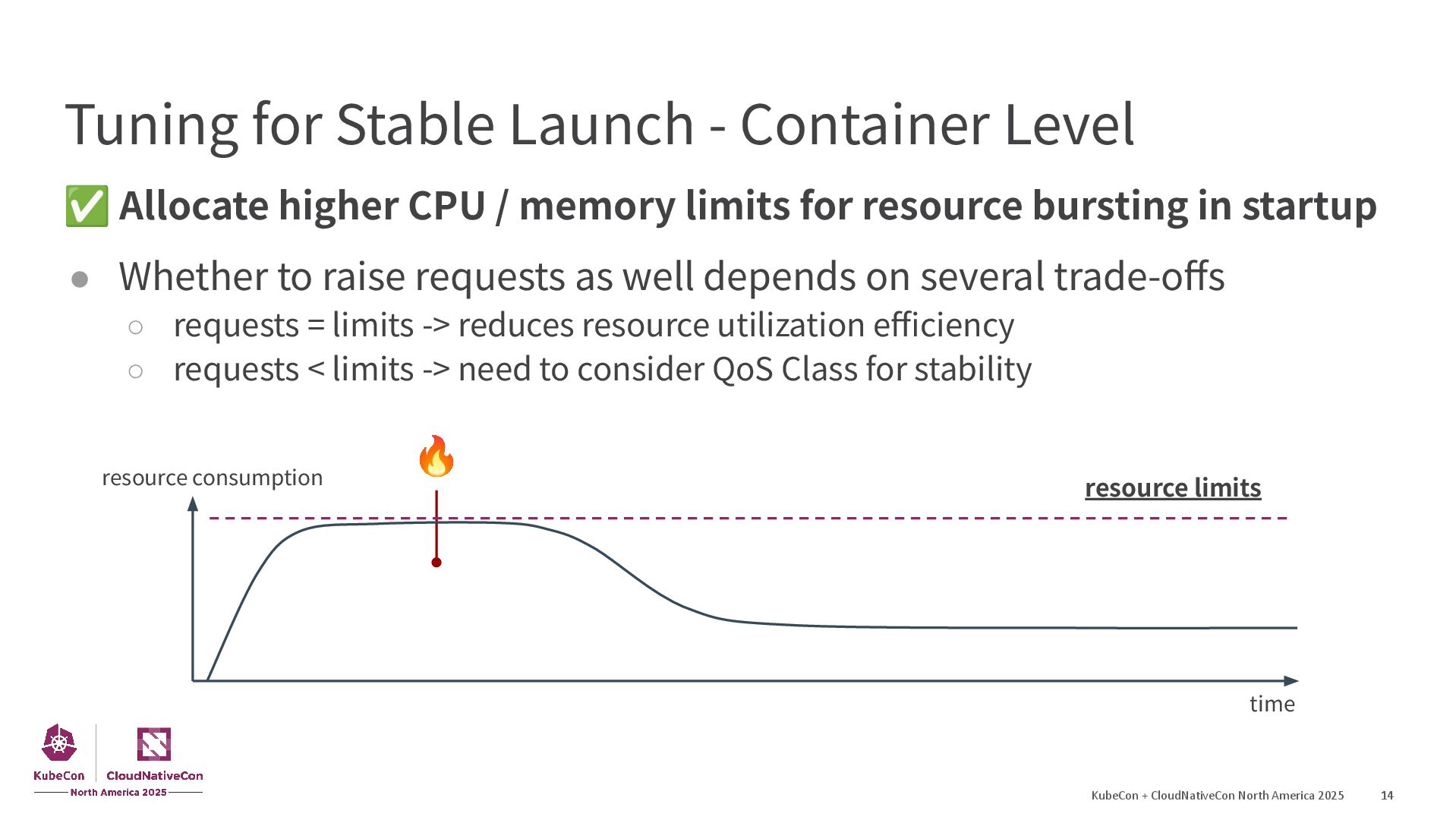{kind=link}
{kind=link}
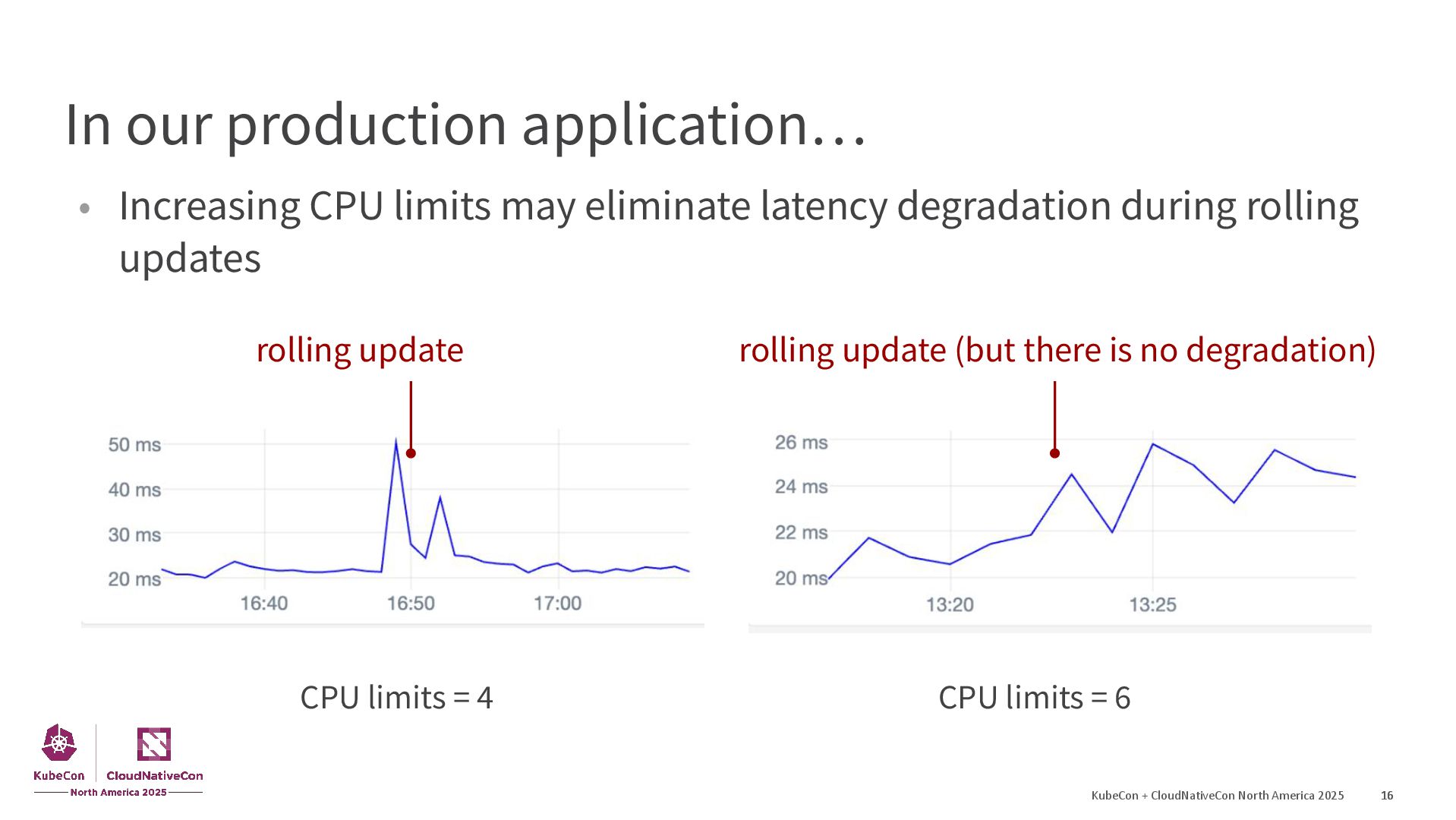{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
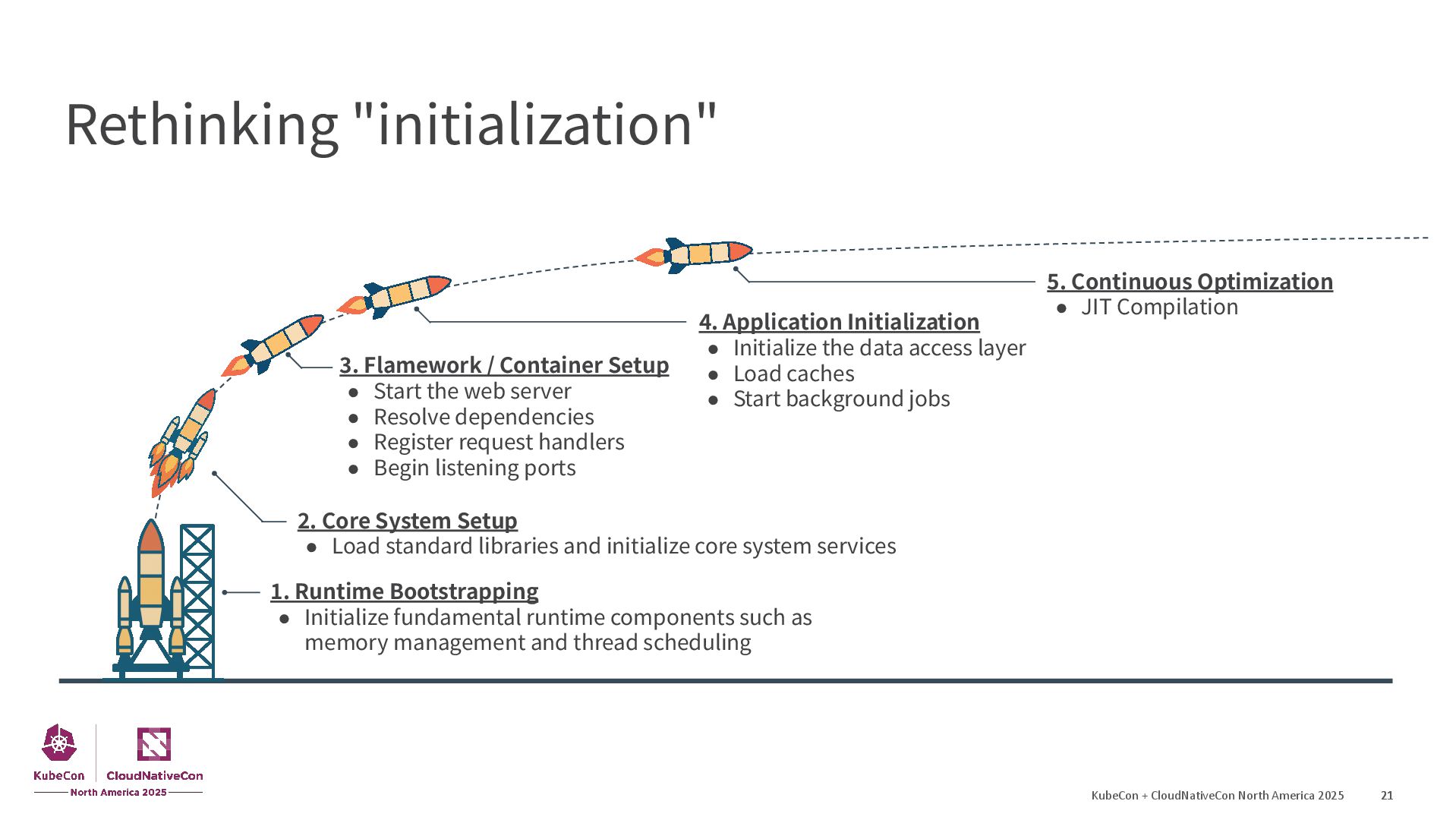{kind=link}
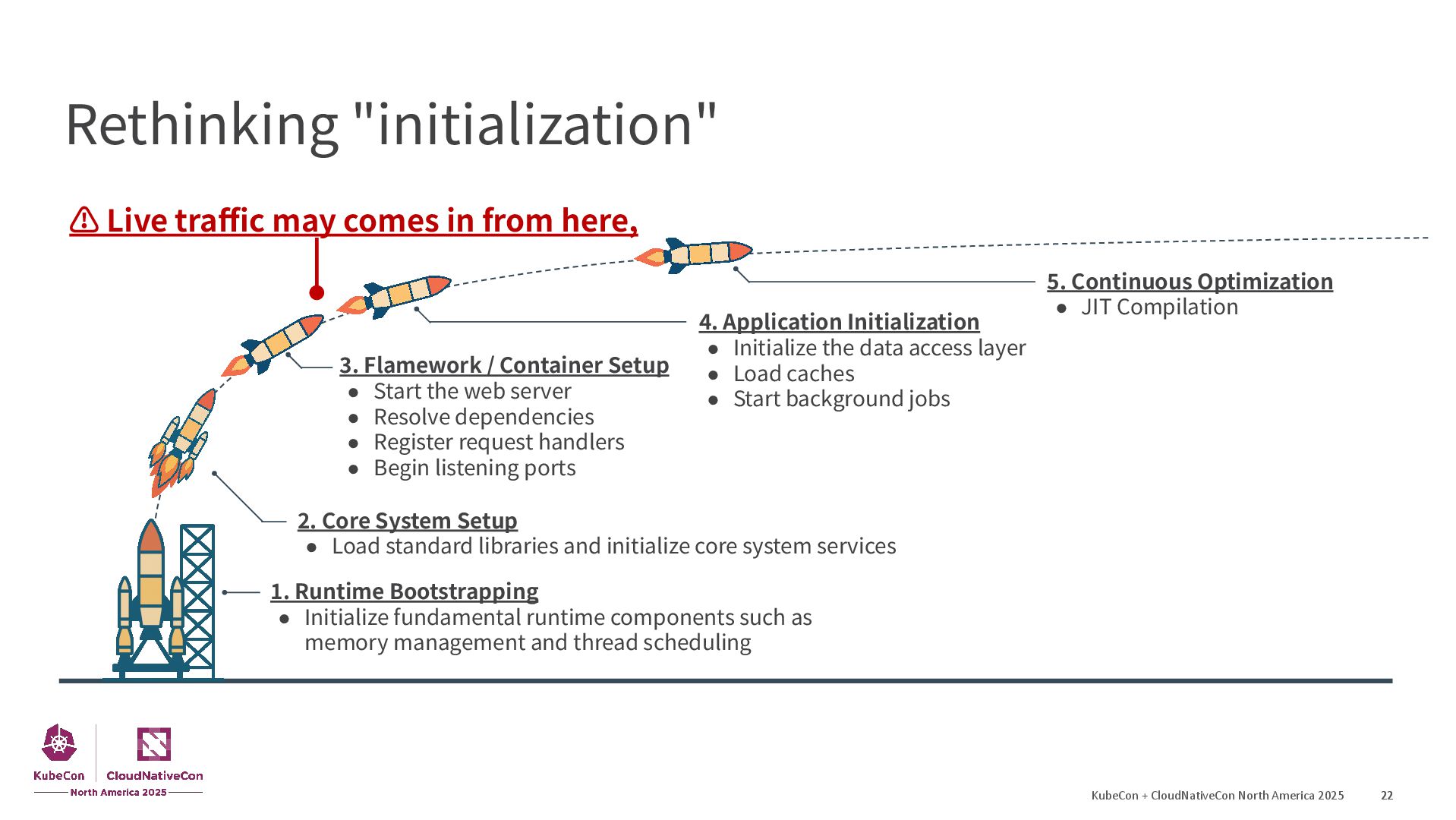{kind=link}
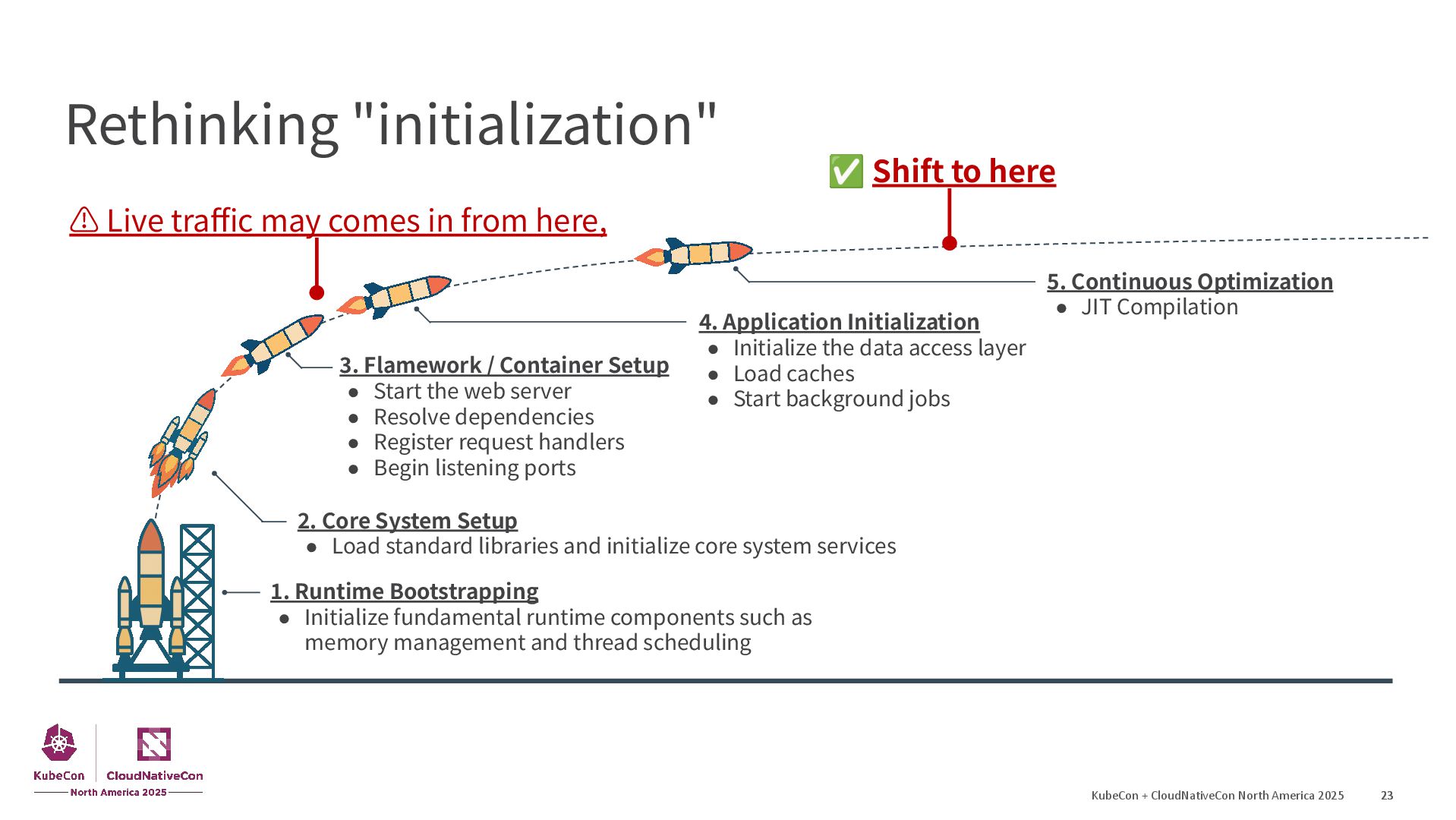{kind=link}
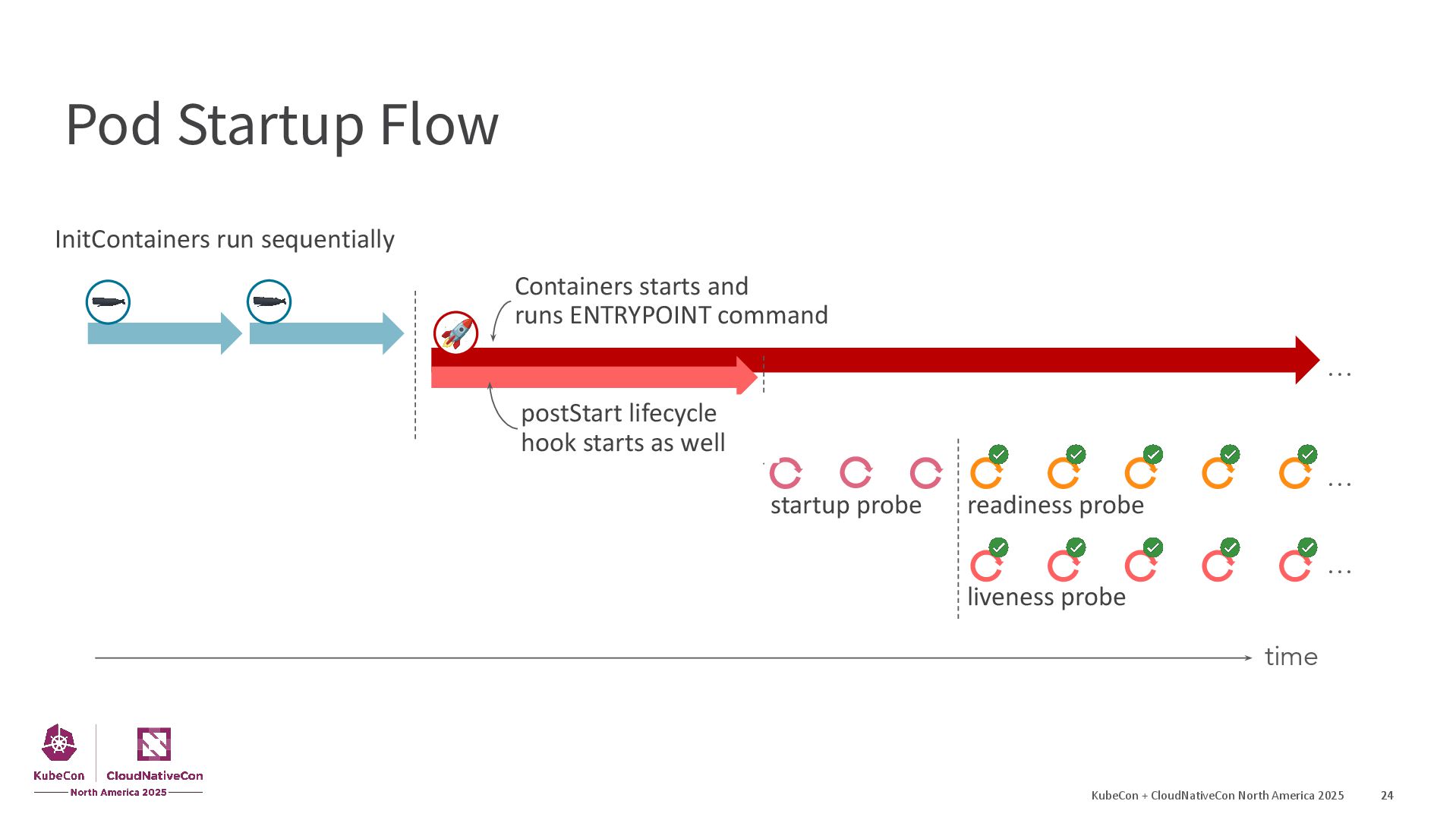{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}