collected and validated data • 500-1000 rows • 10,000 rows on a big project • But digital data – from CMS or Clinical Data Warehouses can give us MUCH bigger data • > 100M rows easily, often > 50GB – does not fit in an email… • This does not always work well in R
being paid off by pharma • But a typical “pharma drug talk” pays ~ $2K • Talk about a new drug or device, while audience eats dinner • On weeknights Mon-Thursday • Most academic places no longer allow this • How do the million-dollar-docs do this? $2K * 500 talks? • Are people really giving 500 pharma drug talks per calendar year? • When do they actually do their main job? • Do they ever go home for dinner? Do they travel constantly? • How is this actually possible? (only 208 weekday [M-Th] dinner talk slots per year)? • Something seems fishy here….
publishes granular data on every payment from pharma/device companies to physicians • Added other prescribers (NPs, PAs) in 2021 • Around 6GB, 11-12M rows, 75 variables per year
GB of RAM • Total data on CMS website from 2013-2021 is 94 GB • Format, # of variables changed in 2016, so will ignore 2013-15 • R works on datasets in memory (RAM)
(2016) • 11 million rows, 75 variables • Only 6.4 GB • Should work, might be a little slow… • readr::read_csv() is 2-3x faster than read.csv() – let’s use read_csv() • Using read_csv() – 2873.7 seconds ~ 49 minutes – not good • Now I have 2 problems • Speed • RAM capacity
• data.table::fread() on 2014 data – 93.3 seconds • MUCH better • 30x speed improvement! • Option 2 – the vroom() function from {vroom} • vroom::vroom() on 2014 data – 14.3 min • Better than read_csv() • 3.5x speed improvement – but slower than {data.table} • Works well with dplyr wrangling
Syntax takes some time to master • The {dtplyr} package is a good back-end work- around if you are familiar with dplyr verbs • But it does not address the bigger-than-RAM data problem (nor does {vroom})
Disk • Easy to get a big disk – Terabytes now • Used to be slow (physical platters) – now SSD, much faster • Though 16TB SSD is still pretty pricey ~ $1800 • Need “scratch disk” space for writing intermediate data • Standard strategy of SAS • Data in RAM • Was much faster than disc – still faster, but not as dramatic with SSD drives • Limited to gigabytes, not terabytes • Standard vs biggest Mac configuration – 8 GB vs 128 GB • With big data, can often have insufficient RAM • Standard strategy of R
~ $5-10 per GB • But M1 Mac mini can only address 16GB • Would need a new computer… C’mon, just buy a new computer… I've got a tiny System 76 Linux system with 12 cores and 32GB RAM that would probably work Not today… though it is tempting. And the datasets just keep getting bigger…
of the Apache Arrow project • Relies on the Arrow C++ library • Uses a standardized columnar memory format , organized for efficient analytic operations on modern hardware • Enables zero-copy data sharing between R and Python • A cross-language development platform for in-memory data • Available in C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby, and Rust.
routines to maximize their efficiency when scanning and iterating over large chunks of data”. • The contiguous columnar layout enables vectorization using the latest SIMD (Single Instruction, Multiple Data) operations included in modern processors. • Like parallel processing with multiple cores, but at a micro (vector) level The SIMD instruction set is a feature available in Pentium+ Intel, AMD, and Apple Silicon chips
rows, 6.4 GB, 2016 data Approach Seconds Pure data.table 0.3 seconds data.table with {dtplyr} translation 1.5 seconds Arrow with dplyr verbs 4.7 seconds Vroom with dplyr verbs Way too long to measure Currently supported {dplyr} verbs in Arrow filter select mutate, transmute rename, relocate arrange Use collect() before group_by() or summarize() or other dplyr verbs • {data.table} is freaky fast • {dtplyr} translated {data.table} is almost as fast • {arrow} is in the same ballpark, though slower • Everyday {dplyr} is MUCH slower for big data
used (unmodified) by many languages • Collaboration the old way – collaborator has a useful Python routine • Copy data from R to Python format • Run Python routine • Copy results back to R format • With {arrow} – multilingual with less friction • Insert a Python chunk into Rmd (or Qmd) • Run routine – Python can read R results in arrow format • R can read Python results in arrow format, no copying of data
this? • Arrow 6.0+ can analyze and process multi-file, larger-than-memory datasets • {disk.frame} soft-deprecated in favor of {arrow} • You can manipulate and analyze Arrow data with dplyr verbs • Not clear if you can {arrow} x {data.table} ?? • [TODO: test with dtplyr, is speed affected?]
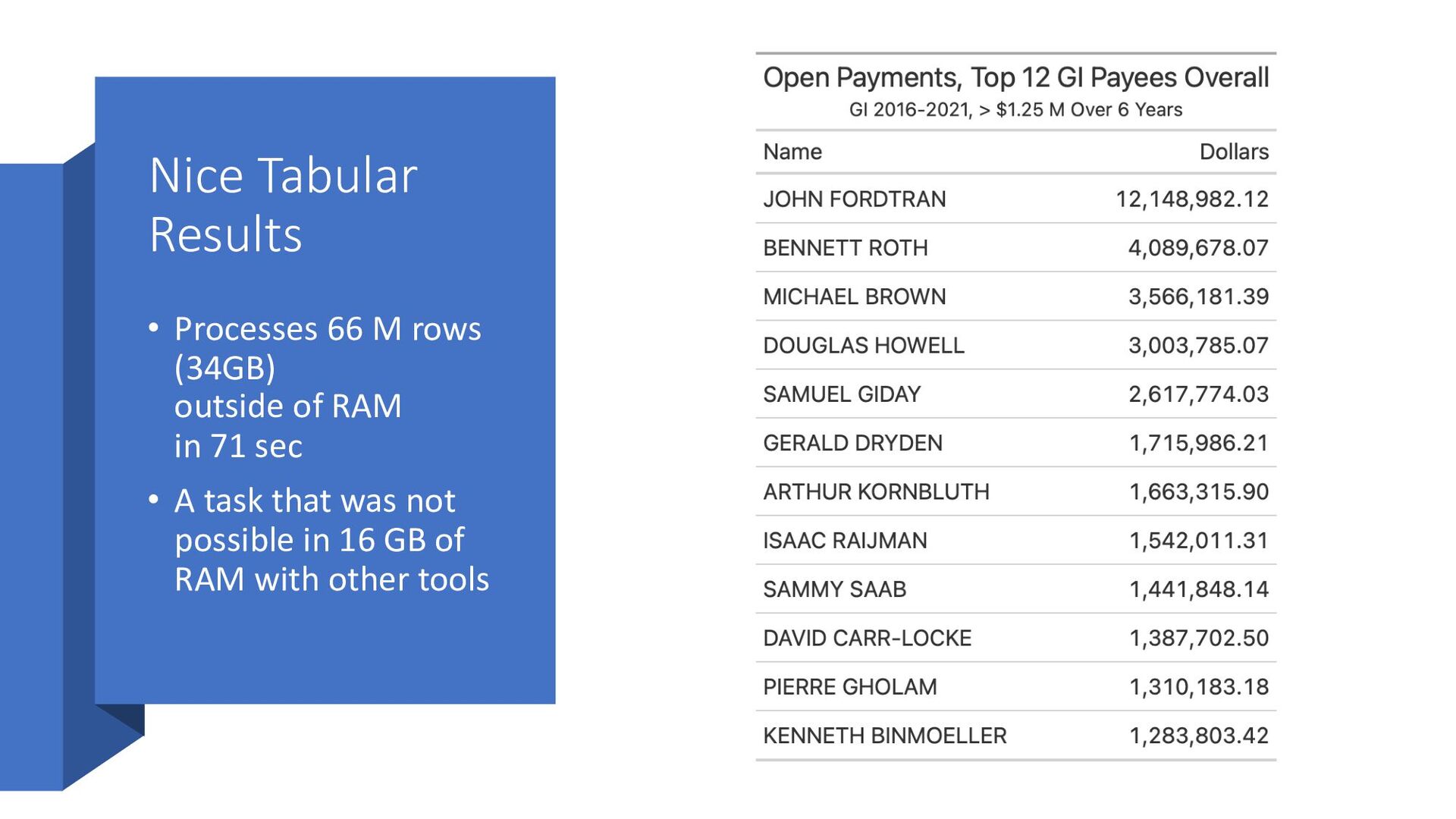
create a dataset on disk • All 6 data files in one folder (data_years) dataset <- arrow::open_dataset("data_years", format = 'csv’) |> arrow::to_duckdb() • Data stored as columnar (arrow) • Then stored as database on disk Year GB 2016 6.4 2017 6.3 2018 6.0 2019 5.7 2020 3.1 2021 6.3 Total 33.8 GB >> 16 GB of RAM
embeddable on-the-fly database (like SQLite) • No databasse setup required – just load the {duckdb} library and go • DuckDB is an OLAP database – Online Analytical Processing • Columnar structure, organized by field/variable • Designed to make complex queries fast >> making data lookup tables fast (OLTP) • Takes advantage of SIMD (single instruction, multiple data) instruction set to achieve speed-up with modern CPUs
interactive queries • Columnar structure • Keeps data for each variable together • Takes advantage of SIMD (Single Instruction Multiple Data) processing Online Transactional Processing • Optimized for fast lookup • Row structure
{dplyr} back-end • Can write code with many (not all) dplyr verbs • Translated into arrow with duckDB • Partitions data into RAM-sized chunks • Runs calculations on each partition • Can wrangle – here for a descriptive data summary • This produces no result (yet) ds_all %>% filter(Physician_Specialty == "Gastroenterology") |> group_by(Physician_First_Name, Physician_Last_Name) |> summarize(total_usd = sum(Total_Amount_of_Payment_US Dollars))
"Gastroenterology") |> collect() |> group_by(Physician_First_Name, Physician_Last_Name) |> summarize(total_usd = sum(Total_Amount_of_Payment_USDo llars)) • Add the collect() function to the end of your dplyr verbs to collect the results • This is the only visible indication of what is going on • Disk database partitioning and analysis is largely abstracted away, and auto-magically happens under the hood with {arrow} and {duckdb}
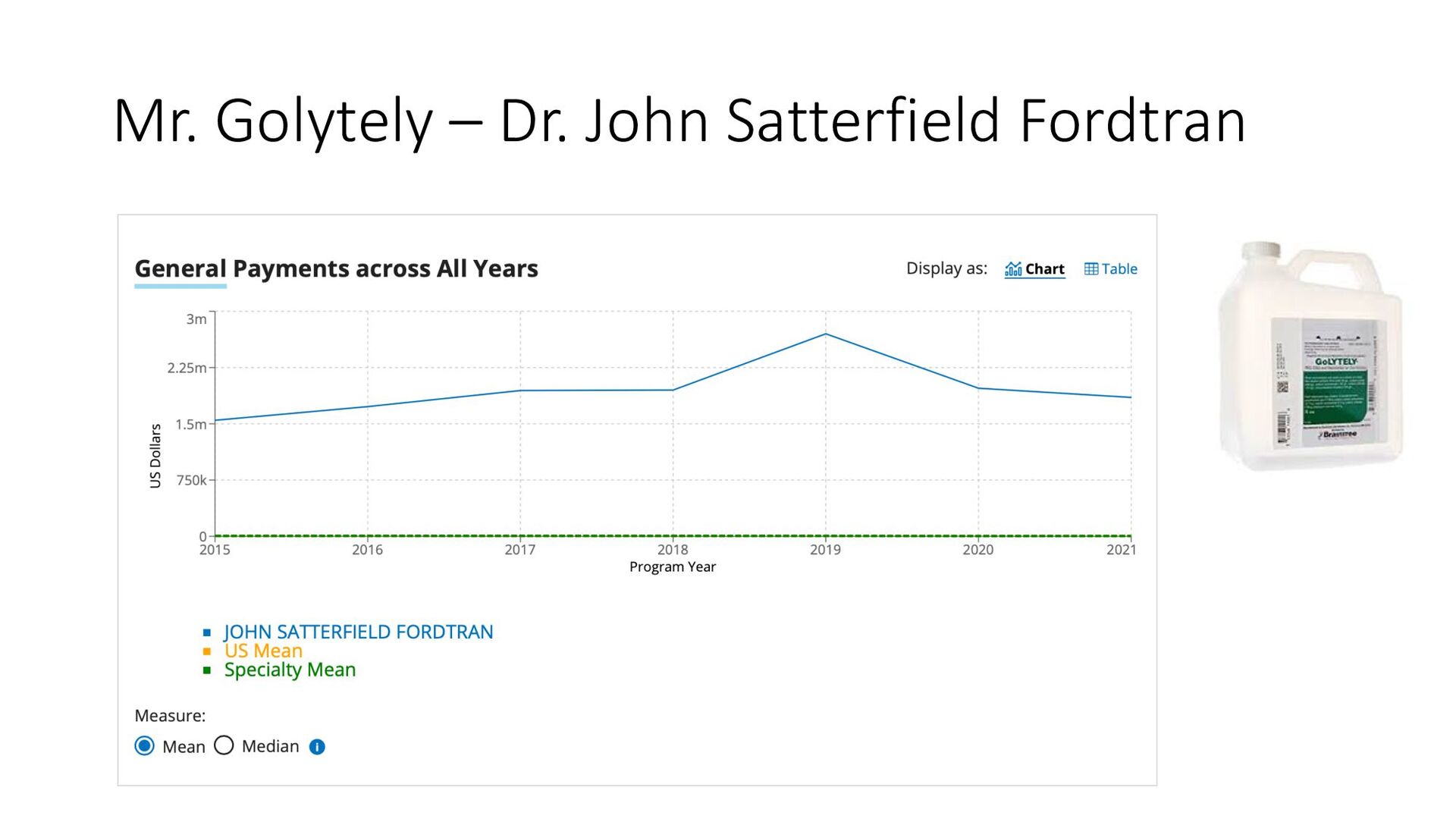
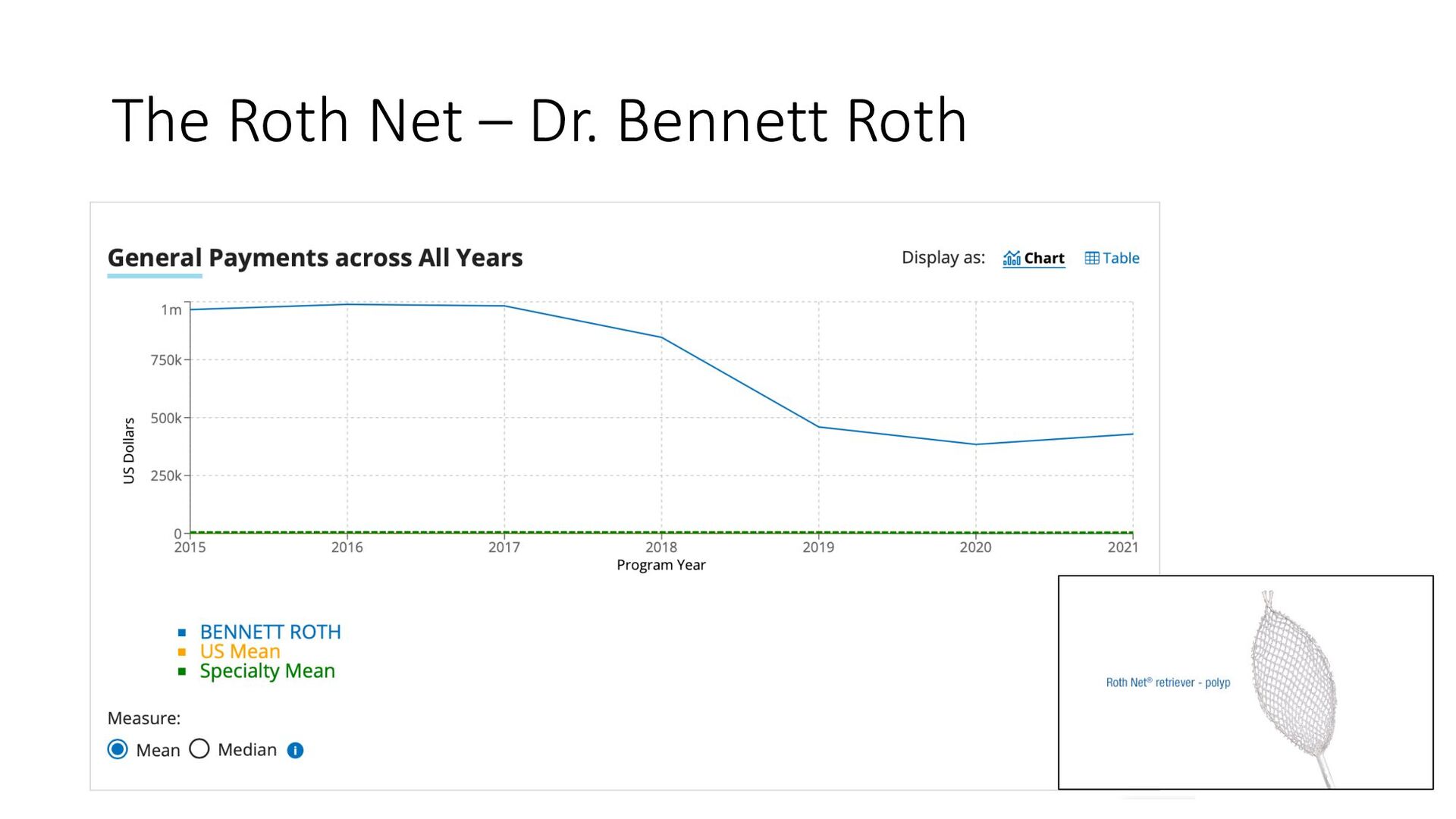
year? • No, nearly all of the top 50 in payments were from royalties from patents • #1 Greater than $1M per year in royalties for John Fordtran • #2 – royalties for Bennett Roth $500K - $1M per year Back to the Question
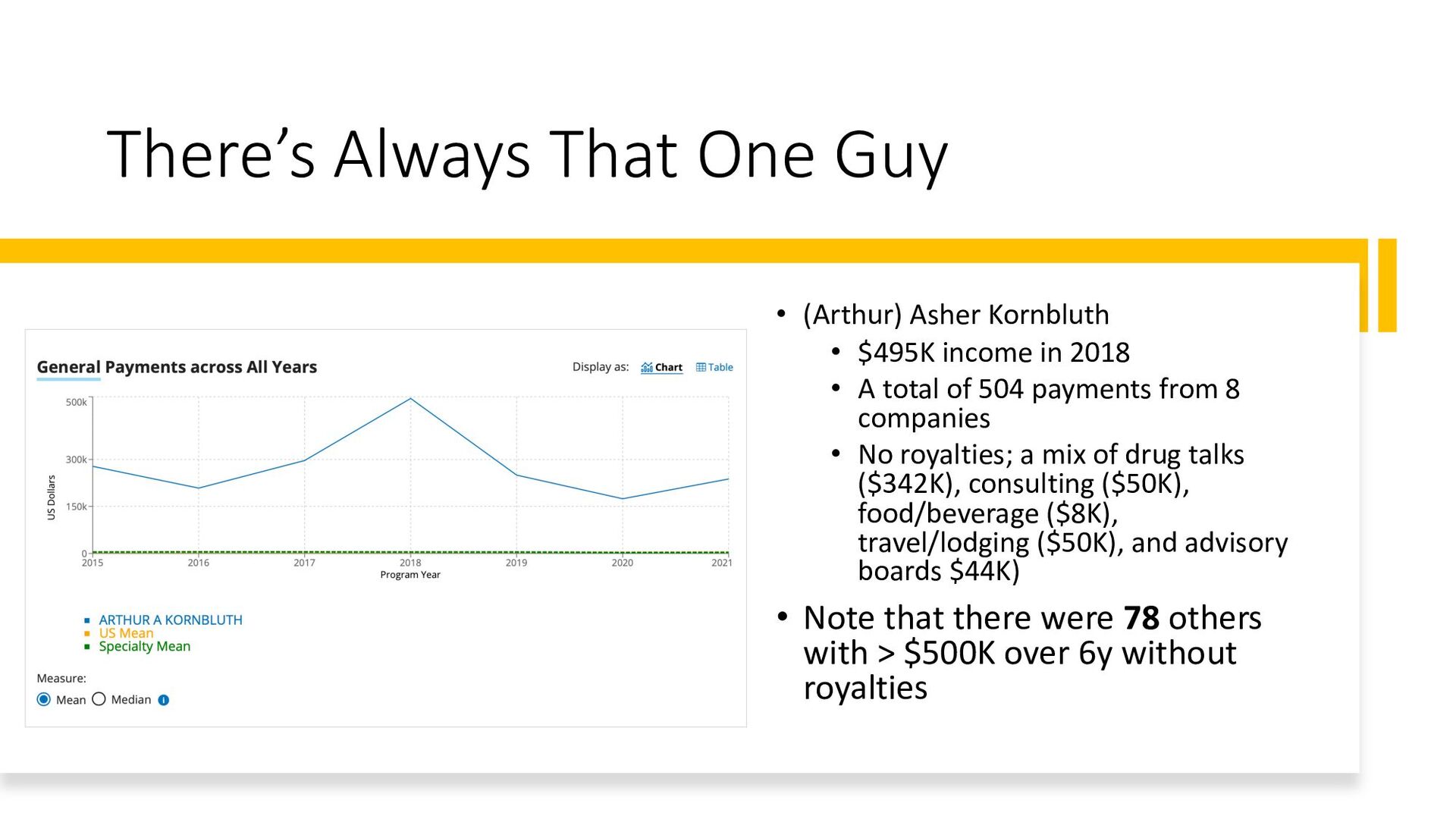
$495K income in 2018 • A total of 504 payments from 8 companies • No royalties; a mix of drug talks ($342K), consulting ($50K), food/beverage ($8K), travel/lodging ($50K), and advisory boards $44K) • Note that there were 78 others with > $500K over 6y without royalties
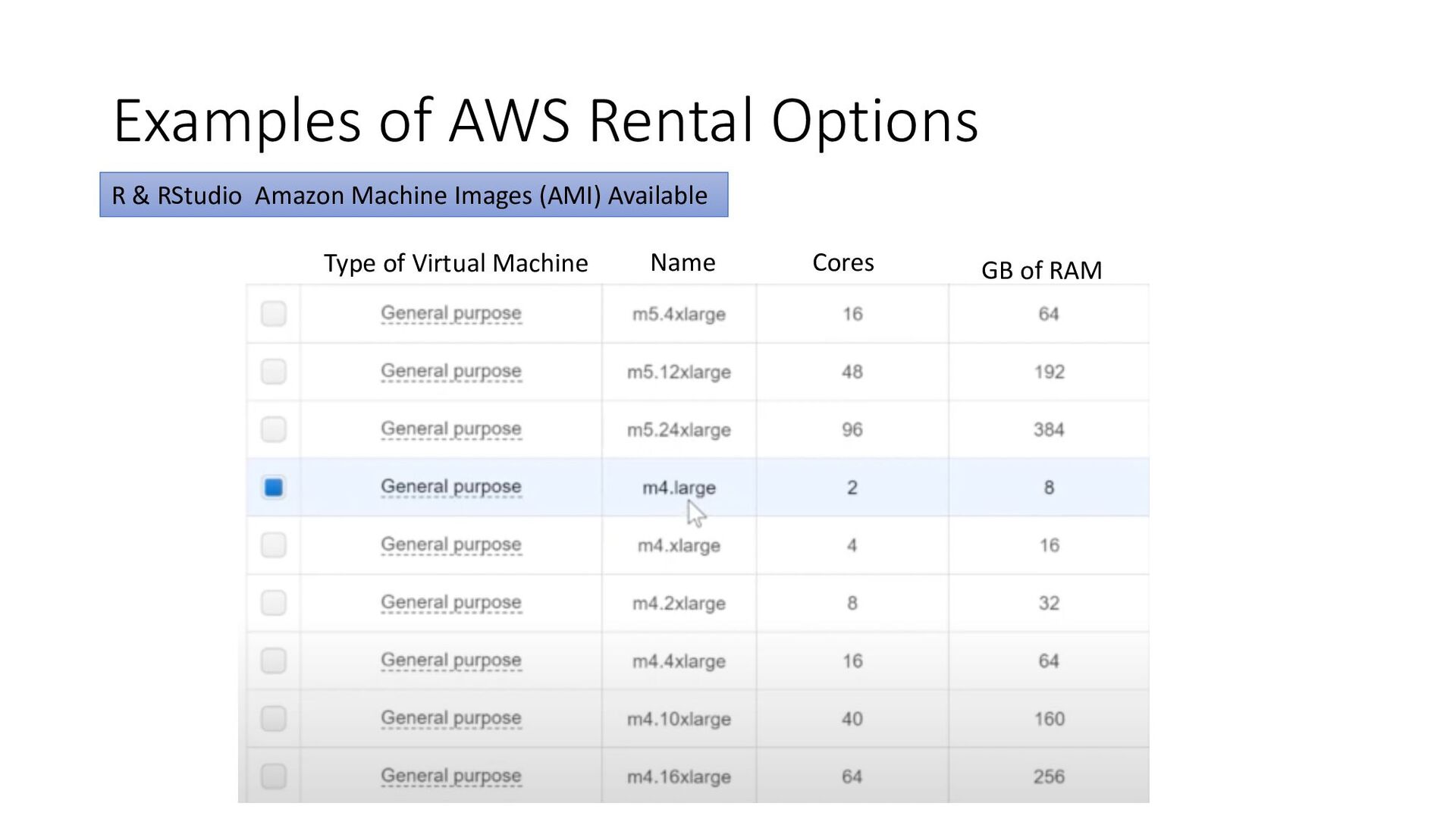
you seem to always end up trying to keep up with bigger and bigger data • Rent some RAM (short-term) in the Cloud • If you have access to a local (often University) cluster • Or an Amazon Web Services S3, Google, or Azure instance • Walk through of RStudio in AWS in this video playlist • https://www.youtube.com/playlist?list=PL0hSJrxggIQoer5TwgW6qWHnVJfqzcX3l • Key videos for RStudio – 12 and 13 in the playlist
faster than the base read.csv() • But it gets slooow with 10M+ rows of data • Faster options for reading in big data • {vroom} vroom() • {data.table} fread() • {arrow} read_csv_arrow() • Faster options for wrangling big data • {data.table} • {dtplyr} (front-end for data.table} • {arrow} with dplyr back-end (only for arrow data structures)
owned bragging rights for years with data on disk • “Only SAS can process bigger-than-RAM datasets!” • Now with {arrow} and {duckdb}, R can do this also in 4 easy steps: 1. Read in as arrow-structured data, with read_csv_arrow() or with arrow::open_dataset() for multiple files in a folder 2. Convert your data to a duckDB dataset on disk with to_duckdb() 3. Wrangle as usual with {dplyr} syntax (most verbs) 4. Remember to collect() your results!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}