The medicaldata package is an R package for teaching medical data analysis in R with patient level data from clinical trials, cohort studies, and case-control studies.
relevant examples motivating • These datasets illustrate data challenges they may face • There are a few medical datasets in R packages, but widely scattered • Many datasets are poorly documented, hard to understand • Quite bare-bones • It is really convenient to have datasets wrapped in one package • Easier for students and for instructors • Can re-use datasets across teaching concepts. • {medicaldata} is focused on patient-level research data, which complements the system-level data in {NHSRdatasets}
trial on the HMS Salisbury by James Lind • 1948 MRC streptomycin for tuberculosis trial • Five other RCTs • Sulindac for polyps, indomethacin for post-ERCP pancreatitis, others • Six Cohort & Case-Control studies • COVID testing, esophageal cancer case-control, CMV after BMT, others • Two pharmacokinetic studies • Indomethacin and Theophylline
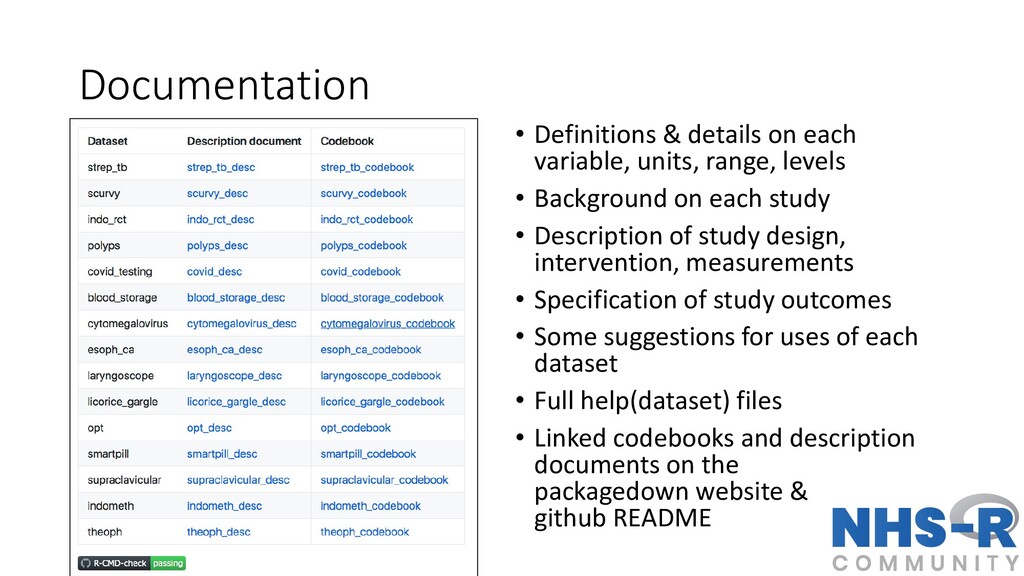
levels • Background on each study • Description of study design, intervention, measurements • Specification of study outcomes • Some suggestions for uses of each dataset • Full help(dataset) files • Linked codebooks and description documents on the packagedown website & github README
add examples as issues • Used strep_tb dataset to teach table construction with {gtsummary} • Attach code (reprex) • Used scurvy dataset for categorical scatterplots of outcomes • Attach code (reprex) • Used the indo_rct dataset to make a covariate forest plot • Attach code (reprex) • Used theoph dataset for GAM modeling • Attach code (reprex) I would like to turn your examples Into vignettes Avishai Tsur: https://avishaitsur.netlify.app/posts/2021-09-04- reproducing-the-results-of-an-rct/
medical datasets? • Randomized controlled trials • Cohort studies • Case-control studies • Must be of reasonable size (5MB limit on CRAN) • Must be anonymized • Fake names, fake study IDs are helpful • Need a reasonable level of documentation/codebook/a publication I am adding several from Frank Harrell for the January 2022 release
data that need pivot_longer() • Untidy medical data that need help from {tidyr} • Separate, unite • Separate_rows • Nest, unnest • Fill, complete, replace_na • Color-coded medical data that need {tidyxl} • Multiheaded medical data that need {unheadr} • Messy medical data that need {unpivotr} • Feel free to donate some untidy messes/examples! Likely for the July 2022 release
people who send a DM • Include your snail mail address Sender (your name and address) 123 Data Street Medical Center City, State, Country, Postal code On Twitter @ibddoctor Important – must be in one of 180 allowed countries: https://bit.ly/3vtPWnf Roughly corresponds to FIFA membership
16 August, 2021 • You can now install.packages(“medicaldata”) • Plan for updates ~ q6m (gradual changes to dev version) • Thanks for your feedback and github issues!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}