Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Improving Language Understanding by Generative ...
Search
himura467
August 16, 2024
Research
0
81
Improving Language Understanding by Generative Pre-Training
ChatGPT の中身について研究室内で勉強会をした際に発表した資料です!
himura467
August 16, 2024
Tweet
Share
More Decks by himura467
See All by himura467
基盤モデルのアーキテクチャを改造してみよう - 時系列基盤モデルのマルチモーダル拡張事例の紹介 -
himura
1
920
Python アプリケーションの裏側とその機序 -WSGI, ASGI 編-
himura
0
76
人生における期待効用の最大化について考える
himura
0
110
CA_kube-scheduler
himura
0
15
Other Decks in Research
See All in Research
説明可能な機械学習と数理最適化
kelicht
2
830
一般道の交通量減少と速度低下についての全国分析と熊本市におけるケーススタディ(20251122 土木計画学研究発表会)
trafficbrain
0
120
大規模言語モデルにおけるData-Centric AIと合成データの活用 / Data-Centric AI and Synthetic Data in Large Language Models
tsurubee
1
470
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
130
[Devfest Incheon 2025] 모두를 위한 친절한 언어모델(LLM) 학습 가이드
beomi
2
1.4k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
65
35k
When Learned Data Structures Meet Computer Vision
matsui_528
1
2.1k
LLM-Assisted Semantic Guidance for Sparsely Annotated Remote Sensing Object Detection
satai
3
320
SREのためのテレメトリー技術の探究 / Telemetry for SRE
yuukit
13
2.8k
[IBIS 2025] 深層基盤モデルのための強化学習 驚きから理論にもとづく納得へ
akifumi_wachi
19
9.3k
Tiaccoon: Unified Access Control with Multiple Transports in Container Networks
hiroyaonoe
0
390
20年前に50代だった人たちの今
hysmrk
0
120
Featured
See All Featured
Practical Orchestrator
shlominoach
190
11k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.4k
Leo the Paperboy
mayatellez
3
1.3k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
150
Designing for Timeless Needs
cassininazir
0
120
Build The Right Thing And Hit Your Dates
maggiecrowley
38
3k
Getting science done with accelerated Python computing platforms
jacobtomlinson
1
96
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
KATA
mclloyd
PRO
33
15k
Marketing to machines
jonoalderson
1
4.5k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.8k
Transcript
Improving Language Understanding by Generative Pre-Training Alec Radford, Karthik Narasimhan,
Tim Salimans, Ilya Sutskever 設楽朗人 1/10
従来のAIによる自然言語理解と課題 自然言語理解(NLP) ・様々なタスクに対応する必要がある - Textual Retailing - Question Answering -
Semantic Similarity Assessment - Document Classification ・大量の Labeled な Dataset が必要 これは手作業であり、しんどい ・学習モデルを調整するために、最適化されていない heuristic な” 秘伝のタレ”が必要 2/10
自然言語理解AIに求められている要素 ・様々なタスクに汎用的に通用する ・学習のためのラベリングの負担が少ない 従来の手作業でのラベリングのコストを削減 ・学習モデルの細かい調整というタスクが必要ない 学習モデルのパラメータ調整の大部分を 人間がやる必要がないように 3/10
本稿の手法による自然言語理解 本稿の目標: 様々なタスクに汎用的に通用するモデル作成 提案する手法: Unlabeled なコーパスと手作業でターゲットタスクに特化させた学習 例のみを学習対象とする。 これらは同じ領域(Domain)の文章である必要はない。 学習の手順: 1.
Unlabeled Data に対して言語モデリングを行い初期パラメータを 決定 2. 学習例を用いてターゲットタスクに適合させる 4/10
事前学習 Train フェーズ: Unlabeled な Corpus を Byte Pair Encoding(BPE)
という手法で tokenize し、以下で与えられる尤度を最大化する。 ※Θ は学習モデルのパラメータ, k は window size Predict フェーズ: 右の計算により 予測を出力 5/10
Transformer Transformer Block の処理 ・Multi-headed self-attention layer 予測すべきトークン以降のトー クンの情報を隠した状態でトー クンを予測できるよう学習
・Feed forward layer 実験時は活性化関数として GELU 関数を用いている ・最適化アルゴリズム 実験時は ADAM を使用している Ref: [1] 6/10 [1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need, 2017.
Supervised fine-tuning 7/10 タスクに合わせたファインチューニングを行いながら言語モデ ル自体の学習も並行して実行することで、汎化性能の向上と収 束の高速化を実現 ファインチューニングの目標としては上記の L3 を最大化すること ・L2
は各タスク毎のファインチューニングを行う尤度関数 ・L1 は事前学習における尤度関数 ・λ でそれらの割合を設定する
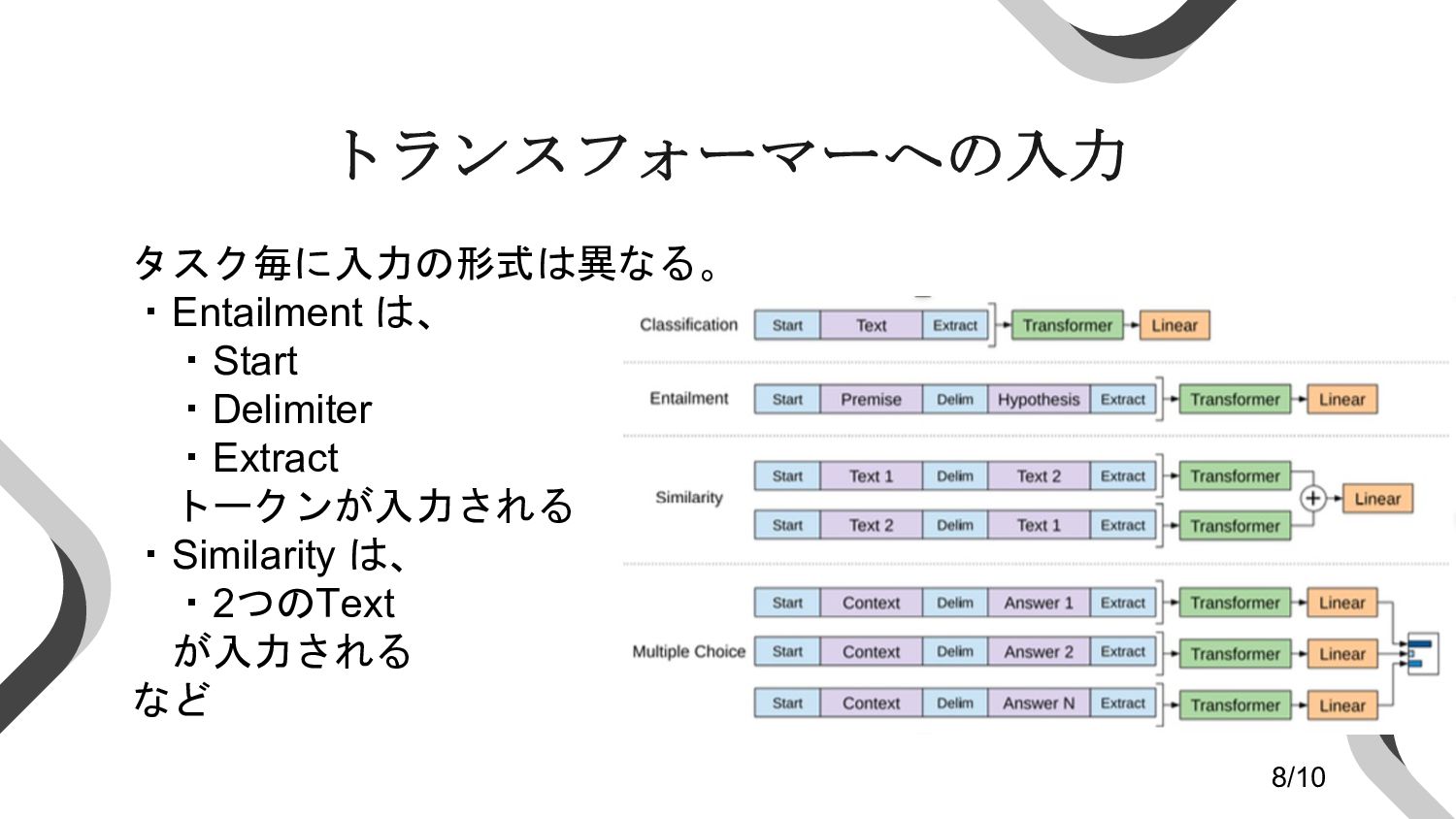
トランスフォーマーへの入力 タスク毎に入力の形式は異なる。 ・Entailment は、 ・Start ・Delimiter ・Extract トークンが入力される ・Similarity は、
・2つのText が入力される など 8/10
本稿の手法による成果 自然言語理解(NLP)のタスクとして挙げた - Textual Retailing - Question Answering - Semantic
Similarity Assessment - Document Classification を含む12タスクのうち、9タスクで従来の最高記録を更新した。 Zero-shot(未知の Domain に対する振る舞い)についても 有用な言語知識を有していることを実証した。 9/10
まとめ 10/10 ・AI の自然言語理解のための学習手法を提案 ・様々なタスクに汎用的に通用する ・学習のためのラベリングの負担が少ない ・学習モデルの細かい調整というタスクが必要ない - 事前学習 -
Transformer - Fine-Tuning - トランスフォーマーへの入力 ・本稿の手法の成果 ・各タスクに汎用的に高水準の結果 ・Zero-shot に対しても有用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}